【YOLO系列】 YOLOv3论文思想详解
前言
以下内容仅为个人在学习人工智能中所记录的笔记,先将目标识别算法yolo系列的整理出来分享给大家,供大家学习参考。
本文未对论文逐句逐段翻译,而是阅读全文后,总结出的YOLO V3论文的思路与实现路径。
若文中内容有误,希望大家批评指正。
资料下载:
YOLOV3论文下载地址:YOLOv3:An Incremental Improvement
项目地址:YOLO V3
回顾:
YOLO V1:【YOLO系列】YOLO V1论文思想详解
YOLO V2:【YOLO系列】YOLO V2论文思想详解
一、YOLO V3思想
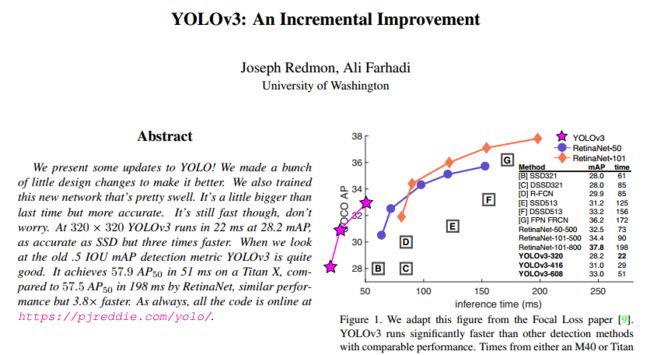
首先,用一张导图来看看YOLO V3到底干了啥

其次,从文章题目YOLOv3:An incremental improvement可以看出,YOLOV3只是做了一些渐进的改进。具体来讲也就导图上面几件事:
(1)网络:YOLOV3训练了一个稍微大一点的网络(Darknet-53, YOLOV2用的Darknet-19),使整个模型的精度更高了。虽然网络更大,但是速度并没有降低,在320 × 320时,YOLOv3在28.2 mAP下只需要22毫秒,比SSD快三倍,而且准确度一样;
(2)bounding box:YOLOV3虽然沿用了YOLOV2的方法,但是在V3中,用了logistic regression计算了每个bbox的目标得分,根据这个得分作为是否计入损失的标准,提高了整个算法的准确率和实时性能。
(3)特征提取:YOLOV3使用FPN结构,在网络的最后一层采用了上采样的方法与相应尺寸的特征图做了融合,增强了特征提取,提高了小目标检测的性能。
二、YOLO V3改进
1、Bounding box prediction
在YOLOv3中,沿用了YOLOV2提出的预测方法,通过尺寸聚类确定anchor box。对于每个bbox,YOLOv3网络预测了4个坐标偏移(tx,ty,tw,th),这4个偏移量使得bbox的中心点在图像上的位置与其在特征图上的位置相对应。同时,YOLOv3还为每个bbox预测了一个目标得分,通过logistic回归计算得出。
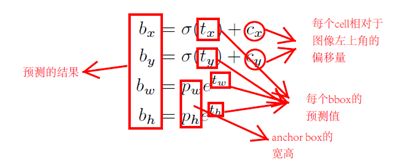
在训练期间,YOLOv3使用平方和误差(sum of squared error loss)作为损失函数,通过梯度下降算法更新网络参数。
YOLOV3中,利用logistics regression对每个bbox进行了评分 ,也就是计算生成的bbox与ground truth框的IOU值,若IOU值大于设定的阈值,则得分为1,即认为生成的bbox框里有物体,那么该bbox就不会参与损失传递(这里大家可能会想:万一框里的物体与真实标签不符,那这种损失不就没考虑了吗?不急,这个问题作者后面解决了,我们接着舞)。
目标得分为1的情况是:
1.某个bbox与ground truth的重合度比其他bbox都高;
2.某个bbox与ground truth的重合度不是最大的,但是超过某个阈值(YOLOV3中阈值为0.5)。
2、Class prediction
在YOLOv3中,Class Prediction是指对输入图像中每个检测到的目标进行分类预测。在分类预测的训练过程中,YOLOv3采用的损失函数是二分类交叉熵(binary cross-entropy)损失函数。
与传统的目标检测方法不同,YOLOv3将目标检测任务转换为单次前向传递的回归问题,即将目标检测任务转换为对每个bbox进行分类和位置回归。因此,在YOLOv3中,Class Prediction是指对每个bbox进行分类预测。
在训练过程中,YOLOv3通过计算每个bbox与ground truth的IoU值来确定最优解,即保留IoU值大于阈值的bbox。当IOU值大于阈值时,虽然忽略了该预测框的位置损失,但是在对其进行分类预测时,如果框里的物体与真实标签不符时,在这里就会计入分类损失来传递。这也就是上面所说的得分为1的框,只是代表了框里有物体,但是对不对,还要做一次判断。
具体来说,YOLOv3中的Class Prediction对于每个类别,都使用了一个独立的logistic分类器,而不是softmax。而在训练的过程中,采用了二分类交叉熵来计算类别预测的损失。
3、Prediction across scales
在YOLOv3中,Prediction Across Scales是一种多尺度预测机制,也称为跨尺度预测。这种机制可以帮助YOLOv3更好地检测不同尺度的目标,从而提高目标检测的精度。
具体来说,YOLOv3采用了类似于特征金字塔网络(Feature Pyramid Networks,FPN)的结构,通过在不同尺度的特征图上进行预测,实现了多尺度预测。FPN是一种自底向上的网络结构,通过在不同尺度的特征图上进行预测,可以检测不同大小的目标。
在YOLOv3中,Prediction Across Scales的实现方式是:在网络的最后一层添加多个尺度的检测头,每个检测头负责预测不同尺度的目标。这些检测头是通过在不同尺度的特征图上进行上采样和下采样得到的。通过这种方式,YOLOv3可以在不同尺度的特征图上进行预测,并且可以检测不同大小的目标。
另外,YOLOv3还采用了anchor box机制,即预先定义了一组不同大小和宽高比的矩形框,用于在特征图上进行预测。这些矩形框的大小和宽高比是通过聚类算法得到的,可以适应不同尺度和形状的目标。
在文中,作者选择了9种不同Anchor Box来对3种不同的尺度进行预测,如果输入为416×416,那么预测的尺寸与Anchor Box参数分别如下:
| 输入尺寸 |
缩放比例 |
输出特征图尺度 |
Anchor Box数量 |
Anchor Box宽高 |
| (416,416) |
8 |
(52,52) |
9 |
(10,13),(16,30),(33,23) |
| 16 |
(26,26) |
(30,61),(62,45),(59,119) |
||
| 32 |
(13,13) |
(116,90),(156,198),(373,326) |
上表可以看出,较大的Anchor Box通常用来预测较小的特征图,而较小的Anchor Box通常用来预测较大的特征图,这是为何呢?
这是因为在较大的特征图中,有更多的空间分辨率,也就是能获得更多的信息,能更好地定位小的对象;随着卷积网络(下采样)的进行,获得的特征图就越来越模糊,但较小的特征图覆盖了更大的感受野,因此适合检测大的对象。
通过这种方式,YOLOv3在不同尺度的特征图上得到了一个N×N×[3×(4+1+80)]的tensor来进行预测:
“N×N”为特征图大小
“3”为每个特征图对应的不同Anchor Box的尺寸
“4”为bbox的offset
“1”代表是否为物体
“80”代表类别(COCO数据集)
总的来说,Prediction Across Scales通过在不同尺度的特征图上进行预测,实现了多尺度预测,提高了目标检测的精度,尤其是对于小目标的检测效果更佳。
4、Feature extractor
在YOLOv3中,Feature Extractor是用于特征提取的网络结构,它采用了Darknet-53作为特征提取器。Darknet-53是一个深度为53层的卷积神经网络,包含连续的1×1和3×3的卷积层,没有使用池化层(步长为2的卷积层代替),并采用了残差结构。这种网络结构可以加强算法对小目标检测的精确度,丰富特征的多样性,并避免了信息丢失。
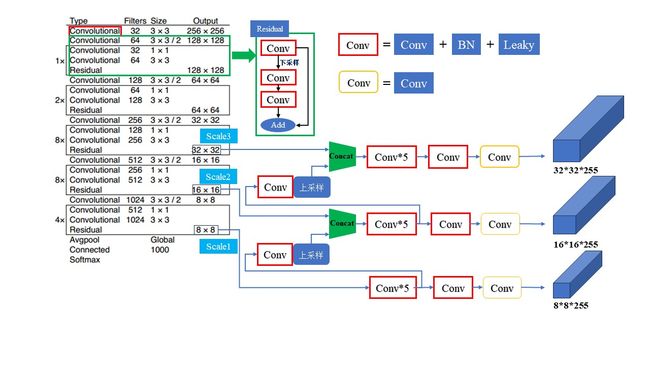
与YOLOv2使用的Darknet-19相比,Darknet-53更加强大,而且比ResNet-101或ResNet-152高效。它没有使用全连接层,最后的全连接层只是用于分类任务。同时,YOLOv3采用了类似FPN的结构,通过在不同尺度的特征图上进行预测,实现了多尺度预测,提高了目标检测的精度。
三、YOLO V3优缺点
1、优点
(1)速度快:在Titan X GPU上的速度是45 fps,加速版的YOLO差不多是150fps。
(2)精度高:YOLO V3在解决小物体检测问题上表现较好,聚类得到Bbox的先验,选择9个簇以及3个尺度,将这9个簇均匀的分布在这3个尺度上。
(3)多尺度预测:YOLO V3采用了类似FPN的结构,对网络的最后一层进行上采样和下采样,使得网络可以在不同尺度的特征图上进行预测,可以提高对不同大小目标的检测能力。
更好的主干网络:YOLO V3采用了Darknet-53作为特征提取器,相比YOLOv2使用的Darknet-19更加强大。
2、缺点
(1)对于密集的或者小尺度的目标检测效果不好。
(2)对于遮挡的目标或者背景复杂的场景,检测效果不够准确。
四、总结
YOLOv3是一种目标检测算法,它采用了Darknet-53作为基础网络,借鉴了ResNet中的残差块的设计,在某些层之间添加了“跳层连接”。它还采用了逻辑回归取代softmax进行分类,使用了多尺度特征图进行检测,以及在预测阶段采用了非最大值抑制(NMS)算法进行筛选。
相比其他目标检测算法,YOLOv3在速度和精度之间取得了很好的平衡,尤其在小物体检测方面表现突出。然而,YOLOv3也存在一些缺点,如对于密集的或者小尺度的目标检测效果不好,以及对于遮挡的目标或者背景复杂的场景,检测效果不够准确。
五、YOLO系列对比
| Type |
YOLO V1 |
YOLO V2 |
YOLO V3 |
| 网络结构 |
借鉴了GoogleNet的思想,24个卷积层+2层全连接层 |
Darknet-19 |
Darknet-53 |
| 损失函数 |
均方差损失(sum-squared error loss) |
Softmax loss |
Logistic loss |
| Anchor Box |
无Anchor Box |
提出聚类的方法生成Anchor Box,但未使用,还是采用了预设的方式确定先验框的尺寸 |
聚类生成Anchor Box |
| 特征提取 |
-- |
Passthrough layer |
采用了类似FPN的结构,进行多尺度特征提取 |
| FPS |
45 FPS |
-- |
在Titan X GPU上的速度是45 fps,加速版的YOLO差不多是150fps。 |
| mAP |
63.4 |
在VOC2007数据集上,以67FPS的速度可达到76.8mAP; 以40FPS的速度可达到78.6mAP。 |
55左右 |
下一篇,我会分享一下YOLO V3的代码,再见诶瑞巴蒂~