Hadoop_HDFS实践 (一)=>(架构、Shell相关操作、API、NN/2NN工作原理、DataNode工作机制等)
目录
- Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (一)
-
- 一、Hadoop_HDFS
-
- 1、概述、背景、优缺点
-
- 1.1、概述
- 1.2、架构
- 1.3、优缺点
- 1.4、块大小
- 2、HDFS的Shell相关操作(开发重点)
-
- 2.1、DFSShell
- 2.2、DFSAdmin
- 3、HDFS的客户端API
-
- 3.1、如果想在windwo上配置hadoop运行条件(不是安装Hadoop)
- 3.2、配置remote server
- 3.3、创建一个maven porject
-
- 1)配置阿里云镜像**settings.xml**
- 2)配置依赖
- 3)创建HdfsClient类进行测试
- 4、HDFS的读写流程
- 5、NN && 2NNN内部的工作原理
-
- 5.1、NN && 2NNN工作机制
- 5.2、Fsimage和Edits的解析
-
- 1)`oiv`查看Fsimage文件
- 2)`oev`查看Edits文件
- 5.3、CheckPoint的时间设置(企业中基本上不会作此修改,一般都会搭建NameNode高可用)
-
- 1)默认检查时间一个小时,在`hdfs-default.xml`文件中默认设置
- 2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次
- 6、DataNode工作机制
-
- 6.1、工作机制
- 6.2、数据完整性采用crc32校验
-
- 1)我们可以运行测试,进行下载数据,校验位选择false,即可以生成.crc校验文件。
- 2)`.crc`文件可以使用`notepad++`打开
- 3)校验数据完整性
- 6.3、DataNode掉线**时限参数**设置
-
- 1)TimeOut = 2\*5min + 10\*3s=10min.30s
- 2)恢复掉线的DataNode
- 二、Hadoop_MapReduce
- 三、Hadoop_Yarn
-
- 参考
Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (一)
- 前要:Hadoop3.3.1完全分布式部署请参考此文章:Hadoop3.3.1完全分布式部署
一、Hadoop_HDFS
1、概述、背景、优缺点
1.1、概述
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。HDFS 有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS 放宽了(relax)POSIX 的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。HDFS 开始是为开源的 apache 项目 nutch 的基础结构而创建,HDFS 是 hadoop 项目的一部分,而 hadoop 又是 lucene 的一部分。
1.2、架构
Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。

运行在HDFS上的应用具有很大的数据集。HDFS上的一个典型文件大小一般都在G字节至T字节。因此,HDFS被调节以支持大文件存储。它应该能提供整体上高的数据传输带宽,能在一个集群里扩展到数百个节点。一个单一的HDFS实例应该能支撑数以千万计的文件。
1.3、优缺点
优点:
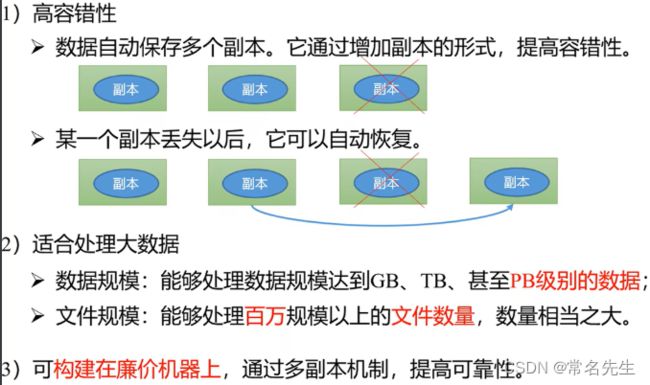
缺点:

1.4、块大小
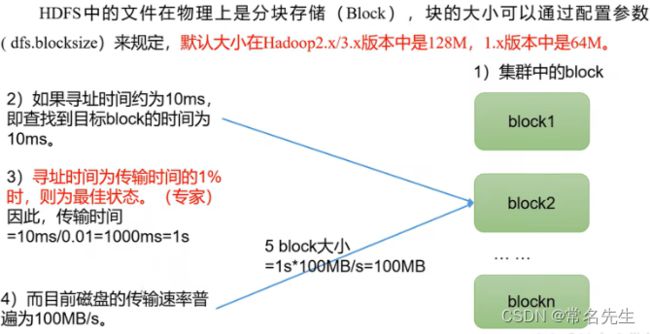
为什么块不能蛇者太小或是过大?
- 1)HDFS的块设置太小,会增加寻址时间,程序会一直在找块的开始位置。
- 2)HDFS的块设置太大,从磁盘传输数据会明显大于定位这个块开始位置所需的时间。导致程序在处理这个块数据的时,会非常的慢
- 总结:HDFS块的大小设置注意取决于磁盘的传输速率
配置所在位置
vim $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
<property>
<name>dfs.blocksizename>
<value>134217728value>
<description>
The default block size for new files, in bytes.
You can use the following suffix (case insensitive):
k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.),
Or provide complete size in bytes (such as 134217728 for 128 MB).
description>
property>
2、HDFS的Shell相关操作(开发重点)
hadoop fs 和hdfs dfs命令时一样的
2.1、DFSShell
| 动作 | 命令 |
|---|---|
| 查看所有命令 | bin/hadoop fs |
-cat 查看名为 /foodir/myfile.txt 的文件内容 |
bin/hadoop dfs -cat /foodir/myfile.txt |
-mkdir 创建文件夹 |
hadoop fs -mkdir /leotest |
-moveFromLocal 从本地剪切到HDFS |
hadoop fs -moveFromLocal ./test1.txt /leotest |
-copyFromLocal 从本地文件系统中拷贝到HDFS |
hadoop fs -copyFromLocal ./test2.txt /leotest |
-put从本地文件系统中拷贝到HDFS他,生产环境更习惯用-put(等同于copyFromLocal) |
hadoop fs -put./test3.txt /leotest |
-appendToFile 追加一个文件到已经存在的文件末尾 |
hadoop fs -appendToFile ./test4.txt /leotest/test3.txt |
-copyToLocal 从HDFS拷贝文件到本地 |
hadoop fs -copyToLocal /leotest/test1.txt ./test1-1.txt |
-get从HDFS拷贝文件到本地,生产环境更习惯用 -get(等同于copyToLocal) |
hadoop fs -get /leotest/test1.txt ./test1-1.txt |
-ls 显示目录信息 |
hadoop fs -ls /leotest |
-cat 显示文件内容 |
hadoop fs -cat /leotest/test1.txt |
-cp 从HDFS的一个路径拷贝到HDFS的另一个路径 |
hadoop fs -cp /leotest/test1.txt /leotest2 |
-mv 在HDFS目录中移动文件 |
hadoop fs -mv /leotest/test2.txt /leotest2 |
-chgrp/-chmod/-chown/ 修改文件所属权限 |
hadoop fs -chmod +x /leotest2/test2.txt |
-tail 显示一个文件的末尾1kb的数据 |
hadoop fs -tail /leotest2/test2.txt |
-rm 删除文件或文件夹 |
hadoop fs -rm /leotest2/test2.txt |
-rm -r 递归删除目录及目录里的内容 |
hadoop fs -rm -r /leotest2 |
-du 统计文件夹的大小信息 |
hadoop fs -du -s -h /leotest hadoop fs -du -h /leotest |
-setrep 设置HDFS中文件的副本数量这里设置的副本数只记录在NameNode的元数据中, 是否真的会生成这么多副本依赖于DataNode的数量。 目前只有三个DataNode(那最多就只有三个副本), 只有节点数增加到5个,副本数才会增加到5。 |
hadoop fs -setrep 5 /leotest/test1.txt |
2.2、DFSAdmin
DFSAdmin 命令用来管理HDFS集群。这些命令只有HDSF的管理员才能使用。下面是一些动作/命令的示例:
| 动作 | 命令 |
|---|---|
| 将集群置于安全模式 | bin/hadoop dfsadmin -safemode enter |
| 显示Datanode列表 | bin/hadoop dfsadmin -report |
| 使Datanode节点 datanodename退役 | bin/hadoop dfsadmin -decommission datanodename |
3、HDFS的客户端API
前要:对HDFS进行增删改查操作
3.1、如果想在windwo上配置hadoop运行条件(不是安装Hadoop)
1)下载 hadoop3.3.1包
把bin目录复制到没有中文的路径下,并配置环境变量
2)windows下使用hadoop需要的工具winutils.exe和hadoop.dll:可以选择这两个下载(windwow版本最新只有3.2.2)
把这两个文件放到放入hadoop bin 目录下,双击winutils即可:
然后把bin目录加入环境变量即可
3.2、配置remote server
idea配置remote服务器
设置idea字体大小快捷键, 右键设置Add Mouse Shortcut即可:
3.3、创建一个maven porject
整体结构
1)配置阿里云镜像settings.xml
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>C:\Users\leojiang\.m2\repositorylocalRepository>
<mirrors>
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>ukid>
<mirrorOf>centralmirrorOf>
<name>Human Readable Name for this Mirror.name>
<url>http://uk.maven.org/maven2/url>
mirror>
<mirror>
<id>CNid>
<name>OSChina Centralname>
<url>http://maven.oschina.net/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
<mirror>
<id>nexusid>
<name>internal nexus repositoryname>
<url>http://repo.maven.apache.org/maven2url>
<mirrorOf>centralmirrorOf>
mirror>
mirrors>
settings>
2)配置依赖
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.leohdfsgroupId>
<artifactId>HDFSClientartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13version>
<scope>compilescope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.30version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.3.4version>
dependency>
dependencies>
project>
配置日志格式
src/main/resources/log4j.properties
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.RollingFileAppender
#log4j.appender.logfile.File=${myweb.root}/WEB-INF/log/myweb.log
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
src/main/resources/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
configuration>
3)创建HdfsClient类进行测试
创建包名com.leo.hdfs
创建类:HdfsClient
package com.leo.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
/**
* 客户端代码常用套路
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
* HDFS zookeeper
*/
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 连接的集群地址
URI uri = new URI("hdfs://hadoop1:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
// 配置副本数
configuration.set("dfs.replication", "2");
// 用户
String user = "root";
// 1 获取客户端对象
fs = FileSystem.get(uri, configuration, user);
}
@After
public void close() throws IOException {
// 3 关闭资源
fs.close();
}
// 创建一个目录
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
// 2 创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan"));
}
// 上传
/**
* 参数优先级
* hdfs-default.xml => hdfs-site.xml => resources下的配置文件 =》代码里的配置
*
* @throws IOException
*/
@Test
public void testPut() throws IOException {
// 参数:参数一:表示删除元数据; 参数二:是否运行覆盖;参数惨:元数据路径;参数四:目的地路径
fs.copyFromLocalFile(false, false, new Path("C:\\Leojiang\\leojiangDocument\\Hadoop\\tmp-testFile\\sunwukong.txt"), new Path("/xiyou/huaguoshan/"));
}
// 文件下载
@Test
public void testGet() throws IOException {
// 参数:参数一:源文件是否删除;参数二:源文件的路径;参数三:目标地址路径win;参数四:是否进行本地校验
fs.copyToLocalFile(false, new Path("/xiyou/huaguoshan/sunwukong.txt"), new Path("C:\\Leojiang\\leojiangDocument\\Hadoop\\tmp-testFile\\"), true);
}
// 文件删除
@Test
public void tesRm() throws IOException {
// 参数:参数一:要删除的路径:参数2:是否递归删除
// 删除文件
// fs.delete(new Path("/xiyou/huaguoshan/sunwukong.txt"),false);
// 删除空目录
// fs.delete(new Path("/xiyou/huaguoshan/"),false);
// 删除非空目录
fs.delete(new Path("/xiyou/huaguoshan/"), true);
}
// 文件更名和移动
@Test
public void testMv() throws IOException {
// 1、源路径;2、目标路径
// fs.rename(new Path("/leotest/test1.txt"), new Path("/leotest/test2.txt"));
// 移动文件并更名
// fs.rename(new Path("/leotest/test2.txt"),new Path("/tests.txt"));
// 目录的更名
fs.rename(new Path("/leotest"), new Path("/leoteste"));
}
// 获取文件详情
@Test
public void fileDetails() throws IOException {
// 获取所有文件信息
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
// 遍历
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("======" + fileStatus.getPath());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
// 判断是文件夹还是文件
@Test
public void testFile() throws IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus) {
if (status.isFile()) {
System.out.println("文件" + status.getPath().getName());
}else {
System.out.println("目录" + status.getPath());
}
}
}
}
4、HDFS的读写流程

5、NN && 2NNN内部的工作原理
5.1、NN && 2NNN工作机制
-
默认一小时触发CheckPoint
-
Edits操作次数达到100万条,也会触发CheckPoit
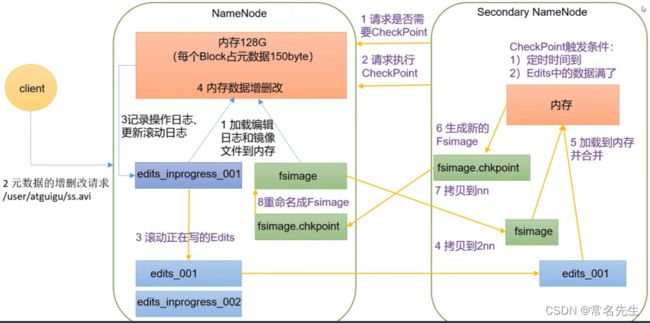
NameNode 格式化之后将会在目录$HADOOP_HOME/data/dfs/name/current中生成如下文件
fsimage_000000000000000
fsimage_000000000000000.md5
seen_txid
VERSION
1、Fsimage文件:HDFS文件系统元数据的一个永久性检查点,其中包括HDFS文件系统所有的目录和文件inode的序列化信息。
2、Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
3、seen_txid文件保存的是一个数字,就是最后一个edits_的数字。
4、每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
5.2、Fsimage和Edits的解析
1)oiv查看Fsimage文件
# 查看对应的命令
$ hdfs
oev apply the offline edits viewer to an edits file
oiv apply the offline fsimage viewer to an fsimage
用法:
# 用法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件的输出路径
# eg:
$ hdfs oiv -p XML -i fsimage_…… -o /……/fsimage.xml
2)oev查看Edits文件
基本用法:
# 用法
hdfs oev -p 文件类型 -i 镜像文件 -o 转换后文件的输出路径
# eg:
$ hdfs oev -p XML -i edits_000000000000000_…… -o /……/edits.xml
5.3、CheckPoint的时间设置(企业中基本上不会作此修改,一般都会搭建NameNode高可用)
1)默认检查时间一个小时,在hdfs-default.xml文件中默认设置
vim $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>3600svalue>
<description>
The number of seconds between two periodic checkpoints.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.If no time unit is specified then seconds
is assumed.
description>
property>
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次
<property>
<name>dfs.namenode.checkpoint.txnsname>
<value>1000000value>
<description>The Secondary NameNode or CheckpointNode will create a checkpoint
of the namespace every 'dfs.namenode.checkpoint.txns' transactions, regardless
of whether 'dfs.namenode.checkpoint.period' has expired.
description>
property>
<property>
<name>dfs.namenode.checkpoint.check.periodname>
<value>60svalue>
<description>The SecondaryNameNode and CheckpointNode will poll the NameNode
every 'dfs.namenode.checkpoint.check.period' seconds to query the number
of uncheckpointed transactions. Support multiple time unit suffix(case insensitive),
as described in dfs.heartbeat.interval.If no time unit is specified then
seconds is assumed.
description>
property>
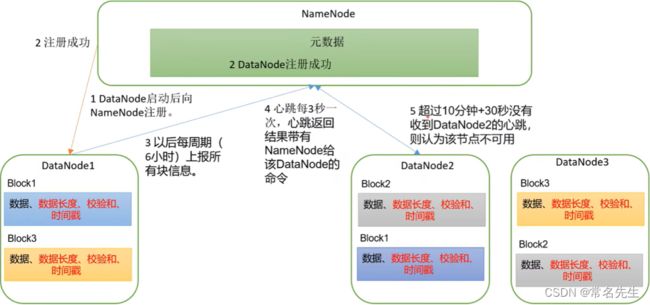
6、DataNode工作机制
6.1、工作机制
# 数据存储位置
cd $HADOOP_HOME/data/dfs/data/current/BP-……/current/finalized/subdir0/subdir0
DataNode启动后向NameNode注册通过后,默认6个小时向NameNode上报块的信息
vim $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
# DN扫描自己节点块信息列表的时间,默认6小时
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value>
<description>Interval in seconds for Datanode to scan data directories and
reconcile the difference between blocks in memory and on the disk.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.If no time unit is specified then seconds
is assumed.
</description>
</property>
# DN向NN汇报道歉解读信息的时间间隔,默认6小时
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
6.2、数据完整性采用crc32校验
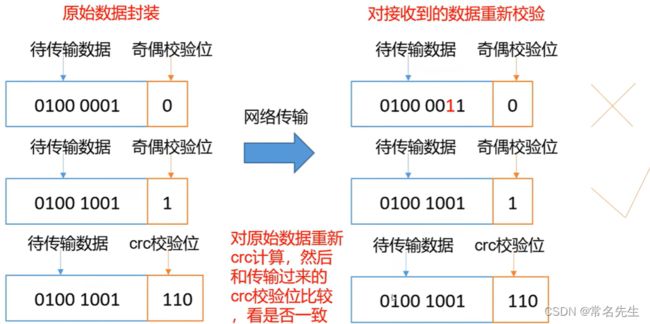
1)我们可以运行测试,进行下载数据,校验位选择false,即可以生成.crc校验文件。
// 文件下载
@Test
public void testGet() throws IOException {
// 参数:参数一:源文件是否删除;参数二:源文件的路径;参数三:目标地址路径win;参数四:是否进行本地校验
fs.copyToLocalFile(false, new Path("/tests.txt"), new Path("C:\\Leojiang\\leojiangDocument\\Hadoop\\tmp-testFile\\"), false);
}
2).crc文件可以使用notepad++打开
安装HEX-Editor重启软件。打开.crc文件使用插件–>HEX-Editor–>勾选View in HEX,就可以显示16进制数据了。

3)校验数据完整性
CRC(循环冗余校验在线计算工具)

6.3、DataNode掉线时限参数设置
生产环境可以根据自身的情况进行调整

1)TimeOut = 2*5min + 10*3s=10min.30s
vim $HADOOP_HOME/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
# 5min
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
<description>
This time decides the interval to check for expired datanodes.
With this value and dfs.heartbeat.interval, the interval of
deciding the datanode is stale or not is also calculated.
The unit of this configuration is millisecond.
</description>
</property>
# 3s
<property>
<name>dfs.heartbeat.interval</name>
<value>3s</value>
<description>
Determines datanode heartbeat interval in seconds.
Can use the following suffix (case insensitive):
ms(millis), s(sec), m(min), h(hour), d(day)
to specify the time (such as 2s, 2m, 1h, etc.).
Or provide complete number in seconds (such as 30 for 30 seconds).
If no time unit is specified then seconds is assumed.
</description>
</property>
2)恢复掉线的DataNode
在此页面可以查看所有的Datanode的详细信息(DataNode连接状态)
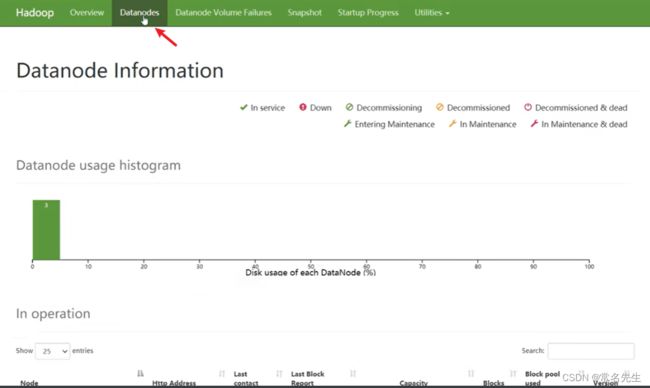
重启down掉的DataNode服务
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
二、Hadoop_MapReduce
Hadoop_MapReduce
三、Hadoop_Yarn
Hadoop_Yarn
参考
Hadoop中文参考资料
Hadoop官网
Spring Initializr
MVN Repository
视频参考地址