Android FrameWork ---- Binder驱动源码分析
对于进程间通信,Linux有很多实现的方式,像管道、信号量、共享内存、Socket等,那么为什么Android要使用Binder而不使用传统的IPC,钟爱Binder自然有其中的原因,从本节开始,分析Android Framework层原理
Binder机制的底层原理
-
- 1 Binder是什么?
- 2 相对于传统IPC Binder的优势在哪?
- 3 Binder如何完成了1次拷贝?
- 3.1 内存的划分
- 3.2 虚拟内存
- 3.3 mmap的原理
- 4 Binder驱动源码分析
- 4.1 binder_init
- 4.2 binder_open
- 4.3 binder_mmap
- 4.3 binder_ioctl
- 5 Zygote进程启动
1 Binder是什么?
Binder作为Android进程间通信的机制,可以看做是一个驱动,因为本身也是一个Java类,Binder.java : IBinder
那么在Android中,常见的进程间通信有哪些?例如系统类的:打电话、闹钟等;自己创建的:像WebView、视频播放、音频播放、大图浏览等
那么进程间通信的优势在哪?
· 内存
Android 虚拟机 会给每个进程分配内存,如果是单一进程,像WebView,或者大图浏览会占用进程的很多内存,严重的时候还是会出现OOM,因此如果采用多进程的方式,那么虚拟机会给每个进程都分配内存,能够避免出现内存不足的情况
· 风险隔离
如果是单个进程,某个模块出现问题,那么就会导致整个app崩溃;如果采用多进程的方式,其中某个进程崩溃,主app不会受到影响。
2 相对于传统IPC Binder的优势在哪?
· 性能
相对于传统IPC的两次拷贝,Binder是拷贝数据是1次拷贝,性能低于共享内存,但是高于传统的IPC
· 安全性
传统的IPC方式没法获取进程的UID(UID是android系统对每个APP赋予的唯一标识,可以用它做权限验证),都依赖上层协议,无法通过UID来验证,只是通过PID并不安全;
Binder是系统能够分配给进程UID,可以通过UID来鉴权,更安全;
而且Binder支持实名服务和匿名服务:实名服务指的是系统服务,通过getSystemService获取的服务;匿名服务是自己创建的服务,例如继承Service
3 Binder如何完成了1次拷贝?
通过了解Binder驱动的原理,就能知道Binder实现数据1次拷贝的原理
3.1 内存的划分
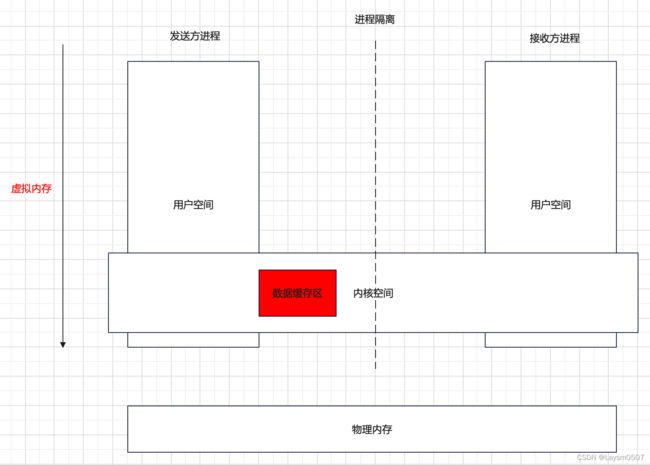
我画的这幅图中,可以看到进程内存的划分,每个进程之间用户空间内存是隔离的,而内核空间是共享的,因此在传统的IPC数据通信时,是在用户空间发起方 copy_from_user 将数据拷贝到内核空间数据缓存区,然后数据缓存区 copy_to_user 将数据拷贝到数据接受方
虚拟内存:Android进程都是运行在自己进程的虚拟内存空间,操作也只能在虚拟内存中完成;例如32位的操作系统,最大虚拟内存空间为4G,其中内核空间 1G ,用户空间 3G,但是并不是所有的内存空间都能为app进程所用。
物理内存:内存条,RAM,就可以看做是物理内存,速度很快,其中虚拟内存可以看做是物理内存的代理 / 映射
3.2 虚拟内存
因为Android的进程都是运行在虚拟内存,因此所有的操作都是在虚拟内存中完成。虚拟内存分为用户空间 和 内核空间,其中内核空间用来管理所有的系统资源,像读写磁盘文件、分配收回内存、读取接口数据等,用户空间的作用是发起请求,通过系统调用,让内核空间完成这些事情
因此在用户空间,是不用能直接操作文件的!
那么举个例子,往磁盘中写数据的流程是这样的:
1 用户空间调用IO流的write方法,告诉内核空间数据的起始地址以及长度;
2 内核 copy_from_user 将数据拷贝到数据缓存区;
3 通过系统调用,将数据拷贝到磁盘,完成文件的写入
这也是2次拷贝的过程
3.3 mmap的原理
上面讲到了传统IPC的2次拷贝,进程之前通过内核空间二次拷贝数据,完成进程间的通信;Binder能做到1次拷贝,就是通过mmap实现内存映射,接收方和内核空间共享一块物理内存,因为操作文件只能在内核空间完成,必须要将数据从用户空间拷贝到内核空间,这1次拷贝少不了!
mmap就是人为地将一块虚拟内存空间跟磁盘对象(物理内存)绑定,只要数据在这块物理内存中,那么用户空间就能感知到直接获取数据

前面提到过,虚拟内存就是其所对应的物理内存的映射,当数据data,从用户空间拷贝到数据缓存区后,数据缓存区跟binder_mmap物理内存映射,其实数据是存到了共享物理内存,那么接收方用户空间跟这块物理内存也是映射关系,当物理内存存进去数据后,用户空间同样感受到了,就拿到了这块数据,这就是mmap的作用。
4 Binder驱动源码分析
从App启动,Binder是怎样被初始化的,还有就是一些细节的处理,从最底层的C++代码看Binder驱动是怎么实现的
如果大家想要看系统的源码,其实不用去下载源码,直接在在线看就行在线看系统源码,点击就可以看

4.1 binder_init
binder_init是binder的初始化操作 这里看Binder驱动的代码
# /drivers/staging/android/binder.c
static int __init binder_init(void)
{
int ret;
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
binder_debugfs_dir_entry_root = debugfs_create_dir("binder", NULL);
if (binder_debugfs_dir_entry_root)
binder_debugfs_dir_entry_proc = debugfs_create_dir("proc",
binder_debugfs_dir_entry_root);
ret = misc_register(&binder_miscdev);
……
}
return ret;
}
device_initcall(binder_init);
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "binder",
.fops = &binder_fops
};
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
}
在binder_init函数中,调用了misc_register函数,其中传入的参数binder_miscdev,定义了misc设备的名称”binder“,就是注册了一个binder设备,MISC_DYNAMIC_MINOR是动态分配的一个设备号;还有一个数据结构,binder_fops,其中包含了binder_open、binder_ioctl、binder_mmap等重要的函数,也是在这个时候完成了初始化,具体怎么完成的初始化,接着往下看
# /drivers/char/misc.c
int misc_register(struct miscdevice * misc)
{
dev_t dev;
……
misc->this_device = device_create(misc_class, misc->parent, dev,
misc, "%s", misc->name);
if (IS_ERR(misc->this_device)) {
int i = DYNAMIC_MINORS - misc->minor - 1;
if (i < DYNAMIC_MINORS && i >= 0)
clear_bit(i, misc_minors);
err = PTR_ERR(misc->this_device);
goto out;
}
/*
* Add it to the front, so that later devices can "override"
* earlier defaults
*/
list_add(&misc->list, &misc_list);
out:
mutex_unlock(&misc_mtx);
return err;
}
misc_register中调用了device_create函数,device_create就是用来创建binder misc device设备
# /drivers/base/core.c
struct device *device_create(struct class *class, struct device *parent,
dev_t devt, void *drvdata, const char *fmt, ...)
{
va_list vargs;
struct device *dev;
va_start(vargs, fmt);
dev = device_create_vargs(class, parent, devt, drvdata, fmt, vargs);
va_end(vargs);
return dev;
}
device_create_groups_vargs(struct class *class, struct device *parent,
dev_t devt, void *drvdata,
const struct attribute_group **groups,
const char *fmt, va_list args)
{
struct device *dev = NULL;
//给设置分配内存 GFP_KERNEL
dev = kzalloc(sizeof(*dev), GFP_KERNEL);
……
retval = device_add(dev);
……
}
所以binder_init的主要作用就是:
1 初始化binder misc设备
2 给设备分配内存
3 调用list_add,将misc device设备放入设备列表中misc_list
4.2 binder_open
当Android要进行进程间通信的时候,通过客户端或者服务端调用binder_open,打开Binder驱动,例如在app中,调用bindService,就是通过Framework层,JNI调用底层binder_open打开驱动
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current);
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
//将proc添加到链表中
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
return 0;
}
在binder_open中,首先给binder_proc分配内存,然后将当前进程的信息,保存到binder_proc中,然后将binder_proc添加到binder_procs表中(hlist_add_head),每个进程拥有一个binder_proc,独一份!
4.3 binder_mmap
这里就到了Binder机制的核心原理,mmap的处理,看怎么实现内存的映射关系的。
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
……
//进程的虚拟内存 不能超过4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
//在内核中,分配一块跟用户空间大小相同的一块虚拟内存
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr;
//计算偏移量
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
……
//分配物理内存
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
……
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
//异步 就是一半
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
……
}
首先明白几个变量代表的含义
vm_area_struct *vma : 用户态的虚拟内存
vm_struct *area : 内核态的虚拟内存
代码分析
1-----
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
在这里,驱动做了限制,用户态的虚拟内存,不能超过4M,应用所占用的大概有1M - 8K(异步为一半,这里是同步的标准),所以为什么Intent传递数据时,不能超过1M,就是因为Intent传递数据基于Binder机制,因此不能超过1M,这是Binder驱动定的。
2-----
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
在内核空间中,分配一块跟用户空间大小相同的虚拟内存
3-----
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
……
if (allocate == 0)
goto free_range;
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
……
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;
//内核虚拟内存与物理内存完成映射
ret = map_vm_area(&tmp_area, PAGE_KERNEL, page);
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
//用户空间与物理内存完成映射
ret = vm_insert_page(vma, user_page_addr, page[0]);
……
}
allocate == 1,意味着分配1页的物理内存(4KB),并与内核空间的虚拟内存完成映射(map_vm_area);vm_insert_page 将用户空间的虚拟内存与物理内存完成映射

看一下这个图就能明白binder_mmap的作用了
4.3 binder_ioctl
binder_ioctl主要是用来做读写操作的
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
……
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
case BINDER_SET_MAX_THREADS:
//设置ServiceManager为大管家,下一节会走到这个地方
case BINDER_SET_CONTEXT_MGR:
case BINDER_THREAD_EXIT:
case BINDER_VERSION:
……
}
从源码中可以看到,binder_ioctl只要是通过cmd命令来执行相应的操作,这里主要看下BINDER_WRITE_READ 读写操作
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
……
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
……
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
……
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
}
读写操作主要是判断write_size和read_size是否存在读写的数据,通过copy_from_user 和 copy_to_user完成数据的读写操作
5 Zygote进程启动
Binder架构图

Init进程是Android启动的第一个进程,是所有用户进程的鼻祖,通过解析 init.rc脚本,主要用来创建Zygote、ServiceManager等进程,其他用户进程通过Zygote孵化出来;
service zygote /system/bin/app_process -Xzygote /system/bin --zygote --start-system-server
class main
priority -20
user root
group root readproc reserved_disk
socket zygote stream 660 root system
onrestart write /sys/android_power/request_state wake
onrestart write /sys/power/state on
onrestart restart audioserver
onrestart restart cameraserver
onrestart restart media
onrestart restart netd
onrestart restart wificond
writepid /dev/cpuset/foreground/tasks
Zygote进程启动的入口,就是app_process中app_main.cpp的main方法
# /frameworks/base/cmds/app_process/app_main.cpp
int main(int argc, char* const argv[])
{
……
AppRuntime runtime(argv[0], computeArgBlockSize(argc, argv));
……
bool zygote = false;
bool startSystemServer = false;
bool application = false;
String8 niceName;
String8 className;
++i; // Skip unused "parent dir" argument.
while (i < argc) {
const char* arg = argv[i++];
if (strcmp(arg, "--zygote") == 0) {
zygote = true;
niceName = ZYGOTE_NICE_NAME;
} else if (strcmp(arg, "--start-system-server") == 0) {
startSystemServer = true;
} else if (strcmp(arg, "--application") == 0) {
application = true;
} else if (strncmp(arg, "--nice-name=", 12) == 0) {
niceName.setTo(arg + 12);
} else if (strncmp(arg, "--", 2) != 0) {
className.setTo(arg);
break;
} else {
--i;
break;
}
}
……
if (zygote) {
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
}
如果启动的是Zygote进程,那么就是执行AppRuntime的start方法,其中
class AppRuntime : public AndroidRuntime
AppRuntime是继承自AndroidRuntime的,也就是执行AndroidRuntime的start方法,最终会调用一个方法就是startReg,在这个方法中,会注册jni
int AndroidRuntime::startReg(JNIEnv* env)
{
……
if (register_jni_procs(gRegJNI, NELEM(gRegJNI), env) < 0) {
env->PopLocalFrame(NULL);
return -1;
}
env->PopLocalFrame(NULL);
}
在register_jni_procs方法中,会依次注册所需要的JNI对象,其中就包括Binder
static int register_jni_procs(const RegJNIRec array[], size_t count, JNIEnv* env)
{
for (size_t i = 0; i < count; i++) {
if (array[i].mProc(env) < 0) {
#ifndef NDEBUG
ALOGD("----------!!! %s failed to load\n", array[i].mName);
#endif
return -1;
}
}
return 0;
}

这里太多了,就截个图看一下
int register_android_os_Binder(JNIEnv* env)
{
if (int_register_android_os_Binder(env) < 0)
return -1;
if (int_register_android_os_BinderInternal(env) < 0)
return -1;
if (int_register_android_os_BinderProxy(env) < 0)
return -1;
……
}
其实这里主要的作用就是,实现Java层和native层册映射关系,在Java能够调用native层的方法
从Binder架构图中可以看到,JNI主要就是Framework层与Native层交互,通过native与内核层的数据读写,返回到Server端