pytorch文本分类(一):文本预处理
pytorch文本分类(一):文本预处理
本文为自己在鲸训练营答题总结,作业练习都在和鲸社区数据分析协作平台 ModelWhale 上。
学习任务原链接在这里
相关数据链接:https://pan.baidu.com/s/1iwE3LdRv3uAkGGI2fF9BjA?pwd=ro0v
提取码:ro0v
–来自百度网盘超级会员V4的分享
目录
- pytorch文本分类(一):文本预处理
-
- 1. 中&英文分词:
-
- 中英文分词有3点不同:
- 分词的方法主要分为 3 类:
- 2. 文本数字化:
-
- 2.1.1 词袋模型
- 2.1.2 TF-IDF
- 2.2.1 词向量
- 2.2.2 Word2Vec
- 3. 作业
-
- 作业1.
- 作业2.
- 作业3.
- STEP2: 将结果保存为 csv 文件
- 4.作业参考答案
-
- 作业1
- 作业2
- 作业3
1. 中&英文分词:
文本都是一些「非结构化数据」,需要先将这些数据转化为「结构化数据」,结构化数据就可以转化为数学问题以方便机器计算,而分词就是转化的第一步。分词就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作。
中英文分词有3点不同:
- 分词方式不同,中文更难。英文有天然的空格作为分隔符,但是中文没有。
- 英文单词有多种形态,需要词性还原和词干提取;而中文里虽然没有多种形态,但是一词多意的情况非常多,导致很容易出现歧义
- 中文分词需要考虑粒度问题,粒度越大,表达的意思就越准确,但是也会导致召回比较少。所以中文需要不同的场景和要求选择不同的粒度。
分词的方法主要分为 3 类:
基于词典匹配的分词方式
优点:速度快、成本低
缺点:适应性不强,不同领域效果差异大
基本思想是基于词典匹配,将待分词的中文文本根据一定规则切分和调整,然后跟词典中的词语进行匹配,匹配成功则按照词典的词分词,匹配失败通过调整或者重新选择,如此反复循环即可。代表方法有基于正向最大匹配和基于逆向最大匹配及双向匹配法。
基于统计的分词方法
优点:适应性较强
缺点:成本较高,速度较慢
这类目前常用的是算法是HMM、CRF、SVM、深度学习等算法,比如stanford、Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
基于深度学习
优点:准确率高、适应性强
缺点:成本高,速度慢
例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。
中文分词工具 下面排名根据 GitHub 上的 star 数排名:
Hanlp
Stanford 分词
ansj 分词器
哈工大 LTP
KCWS分词器
jieba
IK
清华大学THULAC
ICTCLAS
英文分词工具
Keras
Spacy
Gensim
NLTK
#除了页面运行键,ctrl+enter也可以直接运行cell哦
#中文分词样例代码
import jieba
import re
content = "一位布里斯托机器人实验室的机器人专家设计让机器人将名为‘人机者’的人类替身救出险境"
content = re.sub(r'[^\u4e00-\u9fa5]', '', content)
result = '/'.join(jieba.cut(content))
print(result.split("/"))
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\CHENGY~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.569 seconds.
Prefix dict has been built successfully.
['一位', '布里斯托', '机器人', '实验室', '的', '机器人', '专家', '设计', '让', '机器人', '将', '名为', '人机', '者', '的', '人类', '替身', '救出', '险境']
import nltk
import re
import jieba
from nltk import data
nltk.download(download_dir='./data/nltk_data/') # 本地初次使用nltk 需要调用。将打开一个交互界面(一个新窗口),选择要下载的特定软件包。也可以把需要的文件复制到指定路径
data.path.append('./data/nltk_data/') # 初次使用nltk 需要调用
content = "A roboticist at the Bristol Robotics Laboratory programmed a robot to save human proxies called 'H-bots' from danger."
content = re.sub('[^\w ]','',content) # 匹配非字母、数字、下划线、空格。等价于 [^A-Za-z0-9_ ]
print(content)
print(nltk.word_tokenize(content)) # 英文句子分词
print(nltk.pos_tag(nltk.word_tokenize(content))) # 对分完词的结果进行词性标注
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
A roboticist at the Bristol Robotics Laboratory programmed a robot to save human proxies called Hbots from danger
['A', 'roboticist', 'at', 'the', 'Bristol', 'Robotics', 'Laboratory', 'programmed', 'a', 'robot', 'to', 'save', 'human', 'proxies', 'called', 'Hbots', 'from', 'danger']
[('A', 'DT'), ('roboticist', 'NN'), ('at', 'IN'), ('the', 'DT'), ('Bristol', 'NNP'), ('Robotics', 'NNPS'), ('Laboratory', 'NNP'), ('programmed', 'VBD'), ('a', 'DT'), ('robot', 'NN'), ('to', 'TO'), ('save', 'VB'), ('human', 'JJ'), ('proxies', 'NNS'), ('called', 'VBN'), ('Hbots', 'NNP'), ('from', 'IN'), ('danger', 'NN')]
2. 文本数字化:
获得以词为单位的数据,但是要使文字能被机器理解,还需要将文本数字化,一般有两个解决方案:传统的向量空间模型和词向量技术。
传统向量空间模型是要将一行文本转化为一个向量,典型技术有词袋模型、TF-IDF(词频逆文档频率)模型。词向量技术是将一个词表示为一个低维度、稠密的向量,能使的语义上相近的词向量距离相近,典型技术有word2vec和GloVe(该训练营只讲word2vec)。
2.1.1 词袋模型
词袋模型就是要想把多个词组成的一段话转换为一个向量。首先需要给词进行编码。给单词编码一般采用one-hot编码(独热编码),其思想就是给每个不同的单词一个唯一对应的编码。
比如,“一位布里斯托机器人实验室的机器人专家”可以看成由“一位”、“布里斯托”、“机器人”、“实验室”、“的”、“专家”这6个词组成的序列。
“一位”编码为 [1,0,0,0,0,0],“布里斯托”编码为 [0,1,0,0,0,0],“机器人”编码为 [0,0,1,0,0,0],“实验室”编码为 [0,0,0,1,0,0],“的”编码为 [0,0,0,0,1,0],“专家”编码为 [0,0,0,0,0,1]。单词编码已完成,接下来考虑向量化行文本,即用一个n维的向量表示一段话,向量中的n个位置表示该编码的单词在文本中的权重。
“一位布里斯托机器人实验室的机器人专家”可以向量化为 [1,1,2,1,1,1]。在这段话中,“机器人”出现了两次,并且“机器人”的编码为 [0,0,1,0,0,0]。以上向量化文本的方式就是词袋模型,向量中每个位置的值为该编码对应的词在这段话中出现的次数。
import sys
from sklearn.feature_extraction.text import CountVectorizer
texts = ["doctor patient family","doctor family family","patient hospital", 'hospital'] # 输入列表元素,即代表一个文章的字符串
cv = CountVectorizer() # 创建词袋数据结构
cv_fit = cv.fit_transform(texts)
print(cv.get_feature_names_out()) #列表形式呈现文章生成的词典,和鲸线上需要使用get_feature_names()
print(cv.vocabulary_) #字典形式呈现,key:词,value:词id
print("token计数矩阵:\n",cv_fit.toarray()) #.toarray() 将结果转化为稀疏矩阵 一行对应着一句话,一列对应一个词,列index对应词id
['doctor' 'family' 'hospital' 'patient']
{'doctor': 0, 'patient': 3, 'family': 1, 'hospital': 2}
token计数矩阵:
[[1 1 0 1]
[1 2 0 0]
[0 0 1 1]
[0 0 1 0]]
2.1.2 TF-IDF
TF-IDF模型和词袋模型思想一样,只是向量的值不同。向量中的值为该位置对应的词在文本中的权重,词袋模型认为文本中出现次数多的词权重大,故值就是词在文本中出现的次数。但是单单由词频来决定词在文章中的重要程度是不太准确的,因为有些词在文本中出现频率高但无实际意义,比如“是”,“的”,“等等”等常见词。因此会使用TF-IDF来避免常用词出现频繁的问题。
TF(词频 - term frequency):指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。

IDF(逆向文件频率 - inverse document frequency):包含指定词语的文档越少,IDF越大。指定词语的IDF,由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到,即:
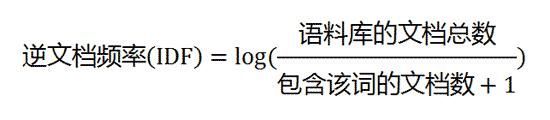
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
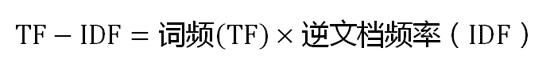
总结一下,向量空间模型可以将一行文本转换为一个向量,常见的有词袋模型和TF-IDF模型,他们的核心思想是将词编码为唯一不同的数字,向量中的值为该位置对应的词在文本中的权重。
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
dataset = [ 'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?' ]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(dataset)
print("get words list ",vectorizer.get_feature_names_out())
print("get sentense shape ",X.shape)
data = {
'word':vectorizer.get_feature_names_out(),
'tf-idf':X.toarray().sum(axis = 0).tolist()
}
df = pd.DataFrame(data)
# df
df_sorted = df.sort_values(by = 'tf-idf',ascending = False)
df_sorted
get words list ['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
get sentense shape (4, 9)
| word | tf-idf | |
|---|---|---|
| 1 | document | 1.627206 |
| 3 | is | 1.316363 |
| 6 | the | 1.316363 |
| 8 | this | 1.316363 |
| 2 | first | 1.160572 |
| 5 | second | 0.538648 |
| 0 | and | 0.511849 |
| 4 | one | 0.511849 |
| 7 | third | 0.511849 |
“tf-idf”:X.toarray().sum(axis = 0).tolist() '在你的代码中是这样做的:
-
’ X.toarray() ‘:将’ TfidfVectorizer ‘的输出稀疏矩阵’ X '转换为密集矩阵(或常规NumPy数组)。该数组的每一行对应于数据集中的一个文档,每一列对应于词汇表中的一个唯一单词。
-
’ .sum(axis=0) ':对数组各列的值求和。由于每一列表示一个唯一的单词,因此该操作将对所有文档中每个单词的TF-IDF分数求和。轴参数设置为0指定求和是逐列的。
3.’ .tolist() ':将结果数组(其中包含每个单词的TF-IDF分数总和)转换为列表。然后在DataFrame的关键字“tf-idf”下使用该列表。
这个过程实际上是计算数据集中所有文档中每个单词的TF-IDF总分。分数越高,考虑到它的频率和唯一性,这个词在文档中越重要或频繁。
X.toarray()
array([[0. , 0.46979139, 0.58028582, 0.38408524, 0. ,
0. , 0.38408524, 0. , 0.38408524],
[0. , 0.6876236 , 0. , 0.28108867, 0. ,
0.53864762, 0.28108867, 0. , 0.28108867],
[0.51184851, 0. , 0. , 0.26710379, 0.51184851,
0. , 0.26710379, 0.51184851, 0.26710379],
[0. , 0.46979139, 0.58028582, 0.38408524, 0. ,
0. , 0.38408524, 0. , 0.38408524]])
2.2.1 词向量
词向量(Word Embedding),是来自词汇表的单词或短语被映射到实数的向量。 从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。举个例子,比如把"food" 转为词向量 [0.0255, 0.0254, 0.0249, … , 0.0282]
2.2.2 Word2Vec
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。本质上,word2vec属于一种DNN深度神经网络,主要在NLP领域里,学习词语的泛化向量表示,做更好的语义理解
Word2Vec通过Embedding层将one-hot Encoder转化为低维度的连续值(稠密向量),并且其中意思相近的词将被映射到向量空间中相近的位置。Word2Vec有两类训练法:CBOW和Skip-Gram
而如果是拿一个词语的上下文语境作为输入,来预测这个词语本身,则是「CBOW 模型」
论文:《Efficient Estimation of Word Representations in Vector Space》
如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做「Skip-gram 模型」
论文:《Distributed Representations of Words and Phrases and their Compositionality》
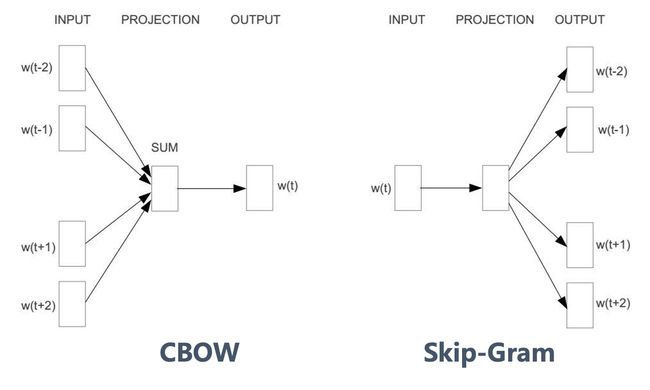
该训练营仅讲解Skip-Gram的模型:
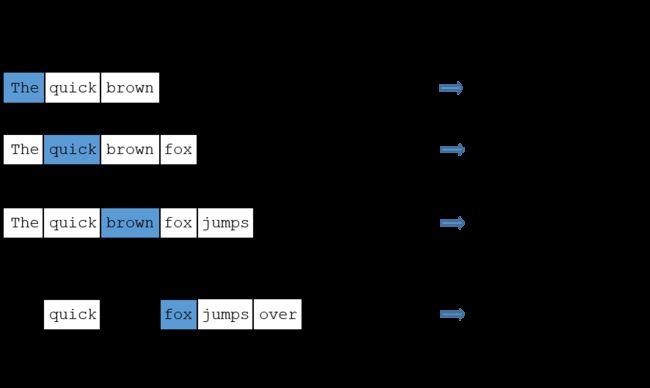
假如有一个句子“The quick brown fox jumps over the lazy dog” ,首先选句子中间的一个词作为输入词,例如选取“fox”作为input word;有了input word以后,再定义一个叫做skip_window的参数,它代表着从当前输入词的左边和右边选取词的数量。最终获得滑动窗口中的词(包括input word在内)就是 [‘quick’, ’ brown’,‘fox’,’ jumps’, ’ over’],即选取左input word左侧2个词和右侧2个词进入窗口。另一个参数叫num_skips,它代表着从整个窗口中选取多少个不同的词作为output word,如图所示。
Skip-Gram模型的input word 和output word都是one-hot编码向量,最终模型的输出是一个概率分布。这个概率代表着词典中的每个词是output word的可能性。第二步中在设置skip_window和num_skips都为2的情况下获得了四组训练数据。假如先拿一组数据 (‘fox’, ‘jumps’) 来训练神经网络,那么模型通过学习这个训练样本,会告诉词汇表中每个单词是“jumps”的概率大小。模型输出的概率代表着词典中每个词有多大可能性跟input word同时出现。
#word2Vec样例代码
import re
import jieba
import time
import sys
from gensim.models import word2vec
import gensim
# 设置路径
sentencePath = './data/活着.txt' #输入文件路径
seg_resultPath = './model/文本分类示例二/seg_result.txt' #分词文件保存路径
modelPath = './model/文本分类示例二/hz_model' #模型文件保存路径
def segment(sentencePath,seg_resultPath):
start = time.time()
with open(sentencePath, 'r', encoding='utf-8') as file:
content = file.read()
content = re.sub(r'[^\u4e00-\u9fa5]',' ',content)
result = ' '.join(jieba.cut(content))
with open(seg_resultPath,'w+',encoding = 'utf-8') as file:
file.write(' '.join(result.split()))
cost = time.time() - start
print(f"Segment cost:{cost:.4f}")
def train_model(seg_resultPath,modelPath):
start = time.time()
sentencePath = seg_resultPath
sentence = word2vec.LineSentence(sentencePath)
model = word2vec.Word2Vec(sentences = sentence,
vector_size = 128,
window = 5,
negative = 6,
epochs = 1000)
model.save(modelPath)
cost = time.time() - start
print(f'Word2Vec model training cost:{cost:.4f}\n')
segment(sentencePath,seg_resultPath) # 分词操作
train_model(seg_resultPath,modelPath) # 训练模型
model = word2vec.Word2Vec.load(modelPath) # 模型加载
print('最接近"有庆"的10个词:',model.wv.most_similar(['有庆']),"\n") # 模型预测
print('最接近"家珍"的10个词:',model.wv.most_similar(['家珍']),"\n") # 模型预测
print('最接近"凤霞"的10个词:',model.wv.most_similar(['凤霞']),"\n") # 模型预测
print('最接近"春生"的10个词:',model.wv.most_similar(['春生']),"\n") # 模型预测
print('最接近"队长"的10个词:',model.wv.most_similar(['队长']),"\n") # 模型预测
print('“羊”和“有庆”的相似度: ',model.wv.similarity('羊','有庆')) #模型预测
Segment cost:0.4405
Word2Vec model training cost:24.4852
最接近"有庆"的10个词: [('我', 0.3501419723033905), ('家珍', 0.33131909370422363), ('苦根', 0.30046358704566956), ('她', 0.29538682103157043), ('娘', 0.2875792384147644), ('少爷', 0.26959922909736633), ('靠', 0.25112184882164), ('割草', 0.24350577592849731), ('他', 0.2415328025817871), ('姐姐', 0.24014891684055328)]
最接近"家珍"的10个词: [('她', 0.6086612939834595), ('我', 0.5713991522789001), ('凤霞', 0.5442803502082825), ('有庆', 0.33131903409957886), ('我娘', 0.313992977142334), ('你', 0.28814253211021423), ('他', 0.22906069457530975), ('我爹', 0.224403515458107), ('队长', 0.221879243850708), ('我们', 0.22088675200939178)]
最接近"凤霞"的10个词: [('家珍', 0.5442803502082825), ('她', 0.4954013228416443), ('我', 0.3354301154613495), ('我娘', 0.2721143364906311), ('爹', 0.25166550278663635), ('疼爱', 0.25079578161239624), ('苦根', 0.24274788796901703), ('总算', 0.23821619153022766), ('高兴', 0.22154293954372406), ('二喜', 0.21926093101501465)]
最接近"春生"的10个词: [('老全', 0.3486226201057434), ('回过头来', 0.2793214023113251), ('医生', 0.2742064595222473), ('队长', 0.2544247508049011), ('还好', 0.25063449144363403), ('送到', 0.2464037388563156), ('刘', 0.23972104489803314), ('把手', 0.23557773232460022), ('我娘', 0.23484957218170166), ('他', 0.2280159592628479)]
最接近"队长"的10个词: [('我们', 0.30412834882736206), ('王先生', 0.2949385344982147), ('新郎', 0.292287677526474), ('大伙', 0.26672911643981934), ('畜生', 0.2657456398010254), ('全', 0.2590039074420929), ('春生', 0.2544247508049011), ('连长', 0.24045266211032867), ('标语', 0.2385277897119522), ('茶', 0.23525692522525787)]
“羊”和“有庆”的相似度: 0.1907835
# 读取函数示例,直接用pandas读取所以没有用到
"""
with open('address', 'r') as file:
# 创建CSV读取器对象
reader = csv.reader(file)
# 遍历每一行数据
for row in reader:
text.append(row[n])
"""
"\nwith open('address', 'r') as file: \n # 创建CSV读取器对象 \n reader = csv.reader(file) \n\n # 遍历每一行数据 \n for row in reader: \n text.append(row[n])\n"
3. 作业
作业1.
将左侧文件树input文件下的geci_82079530/songdata/train.csv的歌词分词后,计算“wonderful”和“beautiful”在所有歌词(图中text下)的词总数(具体计算方式按照python的计算结果来)

# 加载数据
df = pd.read_csv('./data/songdata/train.csv',usecols=['artist','song','link','text'])
df_1 = df.copy()
# 初始化计数器
wonderful_total_count = 0
beautiful_total_count = 0
total_words_count = 0
# 逐行数据处理
for _,row in df_1.iterrows():
# 文本预处理:转换大小写,移除非字母数字字符
processed_lyrics = re.sub('[^\w\s]','',row['text'].lower())
# 分词
words = nltk.word_tokenize(processed_lyrics)
# 更新总次数
total_words_count += len(words)
# 更新特定单次的出现次数
wonderful_total_count += words.count('wonderful')
beautiful_total_count += words.count('beautiful')
# 计算频次
# wonderful_freq = wonderful_total_count / total_words_count if total_words_count else 0
# beautiful_freq = beautiful_total_count / total_words_count if total_words_count else 0
# 输出结果
print(f"Total occurences of 'wonderful':{wonderful_total_count}")
print(f"Total occurences of 'beautiful':{beautiful_total_count}")
# print(f"Frequency of 'wonderful':{wonderful_freq}")
# print(f"Frequency of 'beautiful':{beautiful_freq}")
Total occurences of 'wonderful':926
Total occurences of 'beautiful':3020
answer_1 = f'{wonderful_total_count}' #"wonderful"的词频
answer_2 = f'{beautiful_total_count}' #"beautiful"的词频
作业2.
用TF-IDF的样例代码跑[作业1]的文本,获得“wonderful”和“beautiful”在前100条歌词中词向量(取小数点后5位)
限制条件:
1.要求:去除’\n’
2.提示:- TF-IDF矩阵的每个值表示某个文档中某个特定单词的TF-IDF值,sum一下就是在所有文档中的;不用因为需要交“向量”就去除示例代码中X.toarray().sum(axis=0).tolist() 的sum()函数
import nltk
import pandas as pd
import re
# 加载数据
df = pd.read_csv('./data/songdata/train.csv',usecols=['artist','song','link','text'])
df_2 = df[:100].copy() # 取前100条数据
# 处理数据
df_2['text'] = df_2['text'].apply(lambda x: re.sub('[\n]','',x))
df_2['text'] = df_2['text'].apply(lambda x: re.sub('[^\w\s]','',x.lower()))
content_list = [x for x in df_2['text']]
# 实例化模型及处理数据
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(content_list)
print("get words list ",vectorizer.get_feature_names_out()) # 线上运行需要将函数替换为get_feature_names()
print("get sentense shape ",X.shape)
data = {'word': vectorizer.get_feature_names_out(), # 线上运行需要将函数替换为get_feature_names()
'tfidf': X.toarray().sum(axis=0).tolist()}
res_2 = pd.DataFrame(data)
res_2.sort_values(by="tfidf" , ascending=False)
res_2
get words list ['abide' 'able' 'about' ... 'yourself' 'youve' 'zoo']
get sentense shape (100, 2167)
| word | tfidf | |
|---|---|---|
| 0 | abide | 0.075570 |
| 1 | able | 0.075935 |
| 2 | about | 0.719531 |
| 3 | above | 0.173779 |
| 4 | absentminded | 0.113189 |
| ... | ... | ... |
| 2162 | youre | 2.813944 |
| 2163 | yours | 0.032744 |
| 2164 | yourself | 0.299390 |
| 2165 | youve | 0.763294 |
| 2166 | zoo | 0.035446 |
2167 rows × 2 columns
wonderful_tfidf = res_2[res_2['word']=='wonderful']['tfidf'].values[0]
beautiful_tfidf = res_2[res_2['word']=='beautiful']['tfidf'].values[0]
answer_3 = f'{wonderful_tfidf:.5f}' #"wonderful"的词向量
answer_4 = f'{beautiful_tfidf:.5f}' #"beautiful"的词向量
作业3.
计算[作业1]中的文本,“wonderful”和“beautiful”在前1000条歌词中word2vec向量相似度(取小数点后5位)
限制条件:
1.分词方式:切割去除’\n’, 并且使用nltk包进行分词操作
2.关于word2vec.Word2Vec的参数设置(vector_size=100, window=5, min_count=5, seed=1, workers=1)
import nltk
import pandas as pd
import re
import time
from gensim.models import word2vec
import gensim
# 加载数据
df = pd.read_csv('./data/songdata/train.csv',usecols=['artist','song','link','text'])
df_3 = df[:1000].copy() # 取前1000条数据
# 处理数据
df_3['text'] = df_3['text'].apply(lambda x: re.sub('[\n]','',x))
# df_4['text'] = df_4['text'].apply(lambda x: re.sub('[^\w\s]','',x.lower())) # 此处不需要用正则表达式替换非字母数字空格制表符等,一首歌当做一句话处理
df_3['text'] = df_3['text'].apply(lambda x: x.lower())
# 分词
df_3['text'] = df_3['text'].apply(lambda x:nltk.word_tokenize(x))
# content_list = [x for x in df_4['text']]
content_list = df_3['text'].tolist()
# 设置模型保存路径
# modelPath = './model/文本分类示例二/zuoye3_model' #模型文件保存路径
# 实例化模型及训练
start = time.time()
# sentence = word2vec.LineSentence(content_list) #LineSentence 类期望一个文件路径或文件类对象,但您提供了一个列表。
model = word2vec.Word2Vec(sentences = content_list,
vector_size = 100,
window = 5,
min_count = 5,
seed=1,
workers = 1)
# model.save(modelPath)
cost = time.time()-start
print(f'Word2Vec model training cost: {cost:.4f}\n')
# 模型加载
# model = word2vec.Word2Vec.load(modelPath) #模型加载
# 模型预测
print('“wonderful”和“beautiful”的相似度: ',model.wv.similarity('wonderful','beautiful'))
Word2Vec model training cost: 0.9804
“wonderful”和“beautiful”的相似度: 0.947898
similarity = model.wv.similarity('wonderful','beautiful')
answer_5 = f'{similarity:.5f}' #"wonderful"和“beautiful”的word2vec向量相似度
STEP2: 将结果保存为 csv 文件
csv 需要有两列,列名:id、answer。其中,id列为题号,从作业1开始到作业5来表示。answer 列为各题你得出的答案选项。
import pandas as pd # 这里使用下pandas,来创建数据框
answer=[answer_1,answer_2,answer_3,answer_4,answer_5]
answer=[x.upper() for x in answer]
dic={"id":["作业"+str(i+1) for i in range(5)],"answer":answer}
df=pd.DataFrame(dic)
# df.to_csv('answer2.csv',index=False, encoding='utf-8-sig')
df
| id | answer | |
|---|---|---|
| 0 | 作业1 | 926 |
| 1 | 作业2 | 3020 |
| 2 | 作业3 | 0.17879 |
| 3 | 作业4 | 0.28434 |
| 4 | 作业5 | 0.94790 |
4.作业参考答案
作业1
将左侧文件树input文件下的geci_82079530/songdata/train.csv的歌词分词后,计算“wonderful”和“beautiful”在所有歌词(图中text下)的词总数(具体计算方式按照python的计算结果来)
题解
主要涉及内容:分词
导入库和数据
import csv
import os
# 导入分词库,照抄示例即可
import nltk
from nltk import data
data.path.append('/home/mw/input/geci_82079530/nltk_data/nltk_data/packages')
import nltk
from nltk.tokenize import word_tokenize
# 用来数数
from collections import Counter
print(os.getcwd()) # 现在的工作目录,因为之后使用的是相对路径;当然也可以使用绝对路径,就不需要这步了
text = [] # 用来存储歌词列的值
# 打开CSV文件
with open('../input/geci_82079530/songdata/train.csv', 'r') as file:
# 创建CSV读取器对象
reader = csv.reader(file) # 这里使用csv库;也可以使用pandas库,在关卡3中会介绍
# 遍历每一行数据
for row in reader:
# 获取text列的值并保存在变量中
text.append(row[4])
text = text[1:] # 去除掉第 0 行的表头
print(text[0])
print("length of the list: ", len(text))
/home/mw/project
Look at her face, it's a wonderful face
And it means something special to me
Look at the way that she smiles when she sees me
How lucky can one fellow be?
She's just my kind of girl, she makes me feel fine
Who could ever believe that she could be mine?
She's just my kind of girl, without her I'm blue
And if she ever leaves me what could I do, what could I do?
And when we go for a walk in the park
And she holds me and squeezes my hand
We'll go on walking for hours and talking
About all the things that we plan
She's just my kind of girl, she makes me feel fine
Who could ever believe that she could be mine?
She's just my kind of girl, without her I'm blue
And if she ever leaves me what could I do, what could I do?
length of the list: 46119
分词和统计
# 分词和统计
tokens = []
target_words = ["wonderful", "beautiful"]
for lyrics in text:
tokens.extend(word_tokenize(lyrics.lower())) # 转成小写,分词,然后加入到tokens列表中
# extend用法见 [python中append()和extend()区别详解](https://zhuanlan.zhihu.com/p/342816972)
word_counts = Counter(tokens)
wonderful_count = word_counts["wonderful"]
beautiful_count = word_counts["beautiful"]
print("Count of 'wonderful':", wonderful_count)
print("Count of 'beautiful':", beautiful_count)
# answer_1 = '924' #"wonderful"的词频
# answer_2 = '3022' #"beautiful"的词频
Count of 'wonderful': 924
Count of 'beautiful': 3022
Counter举例说明
from collections import Counter
# Counting words in a sentence
sentence = "this is a test sentence this is"
word_counts = Counter(sentence.split())
print(word_counts) # Output: Counter({'this': 2, 'is': 2, 'a': 1, 'test': 1, 'sentence': 1})
print(word_counts['this']) # Output: 2
print(word_counts['not_in_sentence']) # Output: 0
Counter({'this': 2, 'is': 2, 'a': 1, 'test': 1, 'sentence': 1})
2
0
作业2
用TF-IDF的样例代码跑[作业1]的文本,获得“wonderful”和“beautiful”在前100条歌词中词向量(取小数点后5位)
题解
主要涉及内容:TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 去除'\n'
cleaned_text = [lyrics.replace('\n', '') for lyrics in text[:100]] # /n 前好像本来有空格,直接替换为空就行;text 是之前提取的歌词文本
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(cleaned_text) # 使用向量器(vectorizer)将数据集(dataset)转换为特征矩阵(feature matrix)X
# 获取词列表
feature_names = vectorizer.get_feature_names()
# 获取词向量
word_vectors = X.toarray()
# 构建DataFrame
data = {'word': feature_names, 'tfidf': word_vectors.sum(axis=0)}
df = pd.DataFrame(data)
# 筛选出'wonderful'和'beautiful'
selected_words = df[df['word'].isin(['wonderful', 'beautiful'])]
print(selected_words)
word tfidf
134 beautiful 0.292778
2078 wonderful 0.174588
这里我没有直接转题目要求的5位小数,你可以使用 round 函数完成这一操作:
rounded_num = round(num, 5)
或者不四舍五入,使用 format 函数:
format(num, '.5f')
作业3
计算[作业1]中的文本,“wonderful”和“beautiful”在前1000条歌词中word2vec向量相似度(取小数点后5位)
限制条件:
- 分词方式:切割去除’\n’, 并且使用nltk包进行分词操作
- 关于word2vec.Word2Vec的参数设置(vector_size=100, window=5, min_count=5, seed=1, workers=1)
题解
分词、去除\n
前两个作业中已经做过
import csv
import nltk
from nltk.tokenize import word_tokenize
from gensim.models import Word2Vec
# 打开CSV文件并读取前1000条歌词
text = []
with open('../input/geci_82079530/songdata/train.csv', 'r') as file:
reader = csv.reader(file)
for i, row in enumerate(reader):
if i > 0: # 跳过标题行
text.append(row[4])
if i >= 999: # 读取1000条歌词
break
# 分词
tokenized_text = [word_tokenize(lyrics.lower().replace('\n', '')) for lyrics in text]
Word2Vec
# 训练Word2Vec模型
model = Word2Vec(tokenized_text, vector_size=100, window=5, min_count=5, seed=1, workers=1)
# 计算词向量相似度
wonderful_similarity = model.wv.similarity('wonderful', 'beautiful')
# 输出结果
print("Similarity between 'wonderful' and 'beautiful':", wonderful_similarity)
Similarity between 'wonderful' and 'beautiful': 0.96725357