ES的同义词、扩展词、停止词热更新方案
最近要实现的一些功能需要让ES的同义词、扩展词、停止词能够热更新,达到让搜索更精确的目的。在网上看了很多相关的博客,现在热更新的方案已经实施成功,现在来总结一下。
ES版本:5.5.2
IK分词器版本:5.5.2
扩展词、停止词
我的ES使用的中文分词器是IK分词器,IK分词器支持一种热更新的方案,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新。
同义词
同义词的配置,Elasticsearch自带了一个synonym同义词插件,但是该插件只能使用文件或在分析器中静态地配置同义词,如果需要添加或修改,需要修改配置文件和重启,使用方式不够友好,我需要的是热更新。
基于以上的现有的方案,再加上我参考了两篇博客,决定采用这样的方案:
(1)修改ik分词器源码,然后手动支持从mysql中每隔一定时间,自动加载新的词库
(2)修改一款别人自研的一个可动态维护同义词的插件,也是同样的从mysql中每隔一定时间,自动加载新的词库
(3)在项目中对相应的文档用定时任务进行重建文档操作,因为热更新的词对旧文档无效。
附上两位的博客地址:
Elasticsearch之IK分词器热更新
一个简易的Elasticsearch动态同义词插件
万分感谢两位~
好了,下面进入正题
一、扩展词、停止词
1.下载IK分词器的源码
进入github,找到对应版本的ik分词器,下载源码,我这里是5.5.2版本的ES,所以我下载5.5.2版本的IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/tree/v5.5.2
这是一个maven工程,下载下来后直接导入到eclipse中进行改造
2.修改源码
先看一下下载下来的源码的文件目录
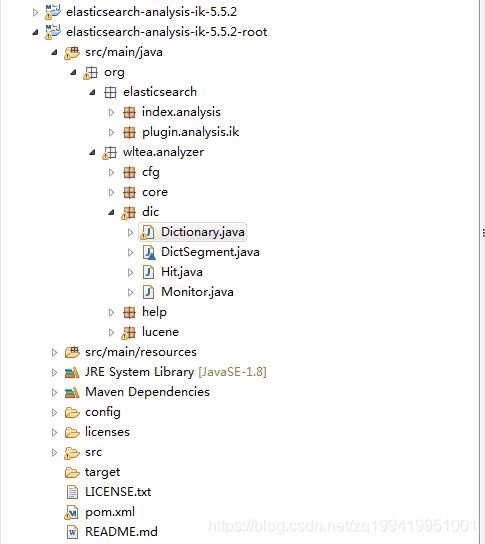
这个-root后缀的项目就是我刚下载下来的ik的源码,这个源码上面的那个项目是我修改过后的源码。
由于我们是要动词库,所以我们直奔dic目录,找到Dictionary类,先看看它这个是怎么加载词典的。
看看他的构造函数:
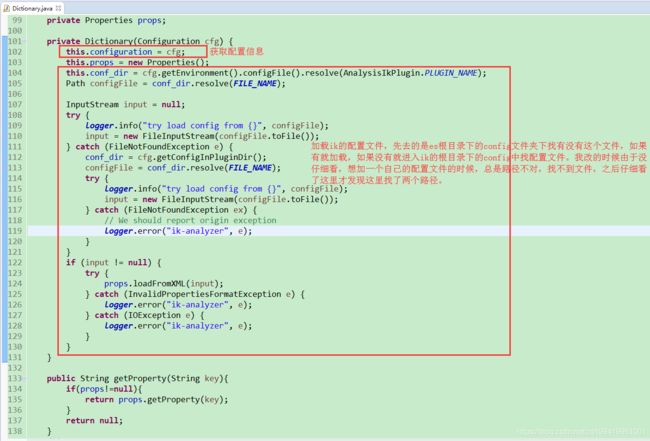
initial方法:
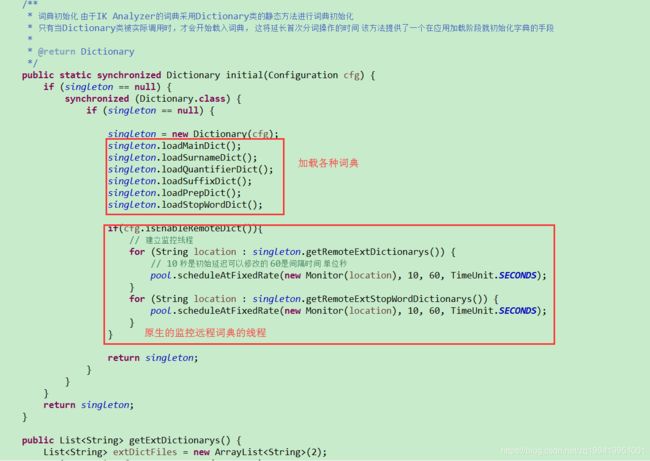
根据上面原博主的思路,是在这个Dictionnary类中,写两个方法,用jdbc去mysql中分别查询扩展词和停止词,然后放到对应的词典中。然后再这个初始化的方法中,像原生的代码那样也调用一下这两个方法。再建立一个监控线程,定时去加载扩展词和停止词。
我在原博主的的基础上,把配置的数据库的属性初始化的时候封装到Dictionnary类中的一个属性中,包括加载的sql和监控线程隔多久进行一次扫描。这样方便进行配置。
(1)、先在Dictionnary类定义两个自己要的属性
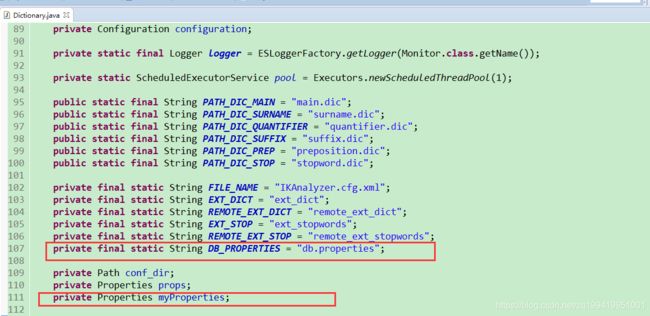
DB_PROPERTIES属性是我们自己建的属性文件的文件名字
myProperties属性是用来把读取到的属性文件里的属性装起来
(2)、在config目录下创建db.properties文件

(3)、在构造方法中读取db.properties,并提供几个获取属性的方法
private Dictionary(Configuration cfg) {
this.configuration = cfg;
this.props = new Properties();
this.myProperties = new Properties();
this.conf_dir = cfg.getEnvironment().configFile().resolve(AnalysisIkPlugin.PLUGIN_NAME);
Path configFile = conf_dir.resolve(FILE_NAME);
Path myFile = cfg.getConfigInPluginDir().resolve(DB_PROPERTIES);
logger.info("加载属性文件db.properties的路径:" + myFile);
InputStream input = null;
InputStream myInput = null;
File file = myFile.toFile();
logger.info("file文件:" + file);
try {
myInput = new FileInputStream(file);
} catch (FileNotFoundException e1) {
logger.error("db.properties未找到", e1);
}
try {
logger.info("try load config from {}", configFile);
input = new FileInputStream(configFile.toFile());
} catch (FileNotFoundException e) {
conf_dir = cfg.getConfigInPluginDir();
configFile = conf_dir.resolve(FILE_NAME);
try {
logger.info("try load config from {}", configFile);
input = new FileInputStream(configFile.toFile());
} catch (FileNotFoundException ex) {
// We should report origin exception
logger.error("ik-analyzer", e);
}
}
if (input != null) {
try {
props.loadFromXML(input);
} catch (InvalidPropertiesFormatException e) {
logger.error("ik-analyzer", e);
} catch (IOException e) {
logger.error("ik-analyzer", e);
}
}
try {
myProperties.load(myInput);
} catch (IOException e) {
logger.error("加载db.properties文件失败!", e);
}
}获取几个属性的方法
private String getUrl() {
String url = myProperties.getProperty("url");
return url;
}
private String getUser() {
String user = myProperties.getProperty("user");
return user;
}
private String getPassword() {
String password = myProperties.getProperty("password");
return password;
}
private int getInterval() {
Integer interval = Integer.valueOf(myProperties.getProperty("interval"));
return interval;
}
private String getExtWordSql() {
String extWordSql = myProperties.getProperty("extWordSql");
return extWordSql;
}
private String getStopWordSql() {
String stopWordSql = myProperties.getProperty("stopWordSql");
return stopWordSql;
}(3)、写两个从数据库中读取扩展词和停止词的方法,再写一个重新加载扩展词和停止词的方法给监控线程去调用
private void loadMySQLExtDict() {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
logger.info("query ext dict from mysql, " + getUrl());
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(getUrl(), getUser(), getPassword());
stmt = conn.createStatement();
String extWordSql = getExtWordSql();
if(!StringUtils.isNullOrEmpty(extWordSql)){
rs = stmt.executeQuery(extWordSql);
while (rs.next()) {
String theWord = rs.getString("main_keyword");
logger.info("main_keyword ext word from mysql: " + theWord);
_MainDict.fillSegment(theWord.trim().toCharArray());
}
}
} catch (Exception e) {
logger.error("erorr", e);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
}
}
private void loadMySQLStopDict() {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
logger.info("query stop dict from mysql, " + getUrl());
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(getUrl(), getUser(), getPassword());
stmt = conn.createStatement();
String stopWordSql = getStopWordSql();
if(!StringUtils.isNullOrEmpty(stopWordSql)){
rs = stmt.executeQuery(stopWordSql);
while (rs.next()) {
String theWord = rs.getString("main_keyword");
logger.info("main_keyword stop word from mysql: " + theWord);
_StopWords.fillSegment(theWord.trim().toCharArray());
}
}
} catch (Exception e) {
logger.error("erorr", e);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
}
}
public void reLoadMySqlDict() {
logger.info("重新加载远程词典...");
// 新开一个实例加载词典,减少加载过程对当前词典使用的影响
Dictionary tmpDict = new Dictionary(configuration);
tmpDict.configuration = getSingleton().configuration;
tmpDict.loadMainDict();
tmpDict.loadStopWordDict();
tmpDict.loadMySQLExtDict();
tmpDict.loadMySQLStopDict();
_MainDict = tmpDict._MainDict;
_StopWords = tmpDict._StopWords;
logger.info("重新加载远程词典完毕...");
}(4)、代码到这里差不多就改完了,但是由于我的ES原来本来已经有了一个IK分词器插件,我并不想把之前的IK分词器插件替换掉,怕影响到以前的业务,所以我还需要把这个修改了源码过后的IK分词器取个别的名字。
进入pom.xml中修改插件名字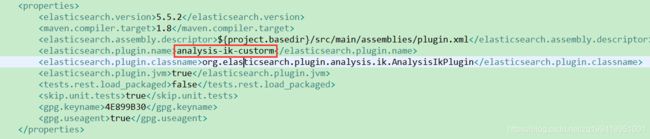
修改org.elasticsearch.plugin.analysis.ik.AnalysisIkPlugin类
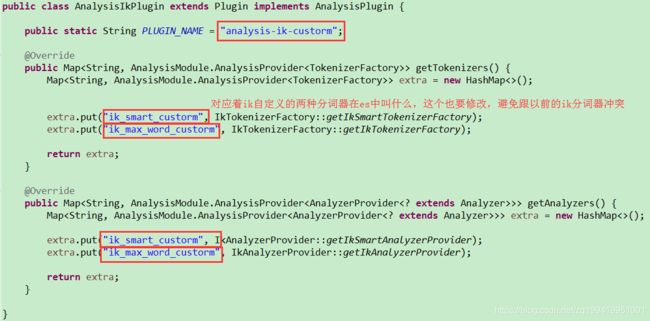
(5)、由于我们使用了mysql来做这个词典加载,项目中使用到了mysql连接,所以要把mysql驱动包配置到plugin.xml文件中,否则打出来的包中没有mysql的驱动包,到时候会报错。加一行配置

(6)、接下来,mvn clean package打包代码,然后找到 target\releases\elasticsearch-analysis-ik-5.5.2.zip
(7)、解压缩该文件到es的plugin目录下,为了避免跟之前的ik文件夹重复,最好先在别的地方解压,然后给文件夹重新命名,再复制到plugin目录下。
二、同义词
1.下载原博主上传到github的源码
https://github.com/ginobefun/elasticsearch-dynamic-synonym
1.1目录结构

1.2实现方式
引用原博主自己写的:
DynamicSynonymTokenFilter
- DynamicSynonymTokenFilter参考了SynonymTokenFilter的方式,但又予以简化,使用一个HashMap来保存同义词之间的转换关系;
- DynamicSynonymTokenFilter只支持Solr synonyms,同时也支持expand和ignore_case参数的配置;
- DynamicSynonymTokenFilter通过数据库来管理同义词的配置,并轮询数据库(通过version字段判断是否存在规则变化)实现同义词的动态管理;
1.3源码
1.3.1 DynamicSynonymTokenFilterFactory
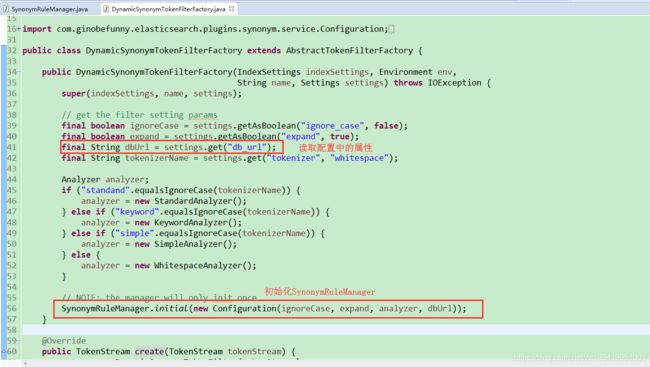
1.3.2 SynonymRuleManager初始化方法
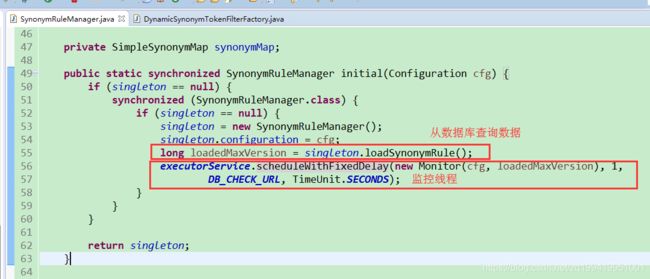
loadSynonymRule()方法就是去数据库查询相应的数据,原博主提供的有一个表结构来存同义词,每一组同义词按照相应的格式就好,ES支持两种格式,一种xxxx,xxxx,xxxx,英文逗号分隔,一种xxxx,xxxx,xxxx => xxxx格式,选择其中一种就好,源码都有做判断的。
监控线程就是重新加载数据,创建一个临时的SynonymRuleManager,加载完了数据,然后再把map赋值给原本的那个synonymMap,防止加载同义词的时候影响插件工作。跟上面IK加载扩展词什么的是一个意思。
2.修改源码
2.1需要改动的地方
- 由于我们本身的业务已经有了自己的词库表,所以不能用源码提供的表以及sql,我需要按照自己的逻辑查出数据,然后按照格式放入synonymMap中。
- 源码用到的db_url是通过ES的settings配置进行加载的,我为了和ik那样统一一下,所以我需要改变加载方式,同样的创建一个db.properties文件来存放要加载的属性,顺便把sql也提取出来,源码是在代码里把sql写死的。
2.2修改Configuration,添加几个我自己需要的属性
public class Configuration {
private final boolean ignoreCase;
private final boolean expand;
private final int interval;
private final String dbUrl;
private final String user;
private final String password;
private final String sql;
private final Analyzer analyzer;
public final static String DB_PROPERTIES = "db.properties";
public Configuration(boolean ignoreCase, boolean expand,int interval, Analyzer analyzer, String dbUrl,String user,String password,String sql) {
this.ignoreCase = ignoreCase;
this.expand = expand;
this.interval = interval;
this.analyzer = analyzer;
this.dbUrl = dbUrl;
this.user = user;
this.password = password;
this.sql = sql;
}
public Analyzer getAnalyzer() {
return analyzer;
}
public boolean isIgnoreCase() {
return ignoreCase;
}
public boolean isExpand() {
return expand;
}
public String getDBUrl() {
return dbUrl;
}
public int getInterval(){
return interval;
}
public String getUser(){
return user;
}
public String getPassword(){
return password;
}
public String getSql() {
return sql;
}
}2.3 在项目目录下新建config文件夹,创建db.properties文件,修改 DynamicSynonymTokenFilterFactory,加载db.properties文件
public class DynamicSynonymTokenFilterFactory extends AbstractTokenFilterFactory {
public DynamicSynonymTokenFilterFactory(IndexSettings indexSettings, Environment env, String name,
Settings settings) throws IOException {
super(indexSettings, name, settings);
// get the filter setting params
final boolean ignoreCase = settings.getAsBoolean("ignore_case", false);
final boolean expand = settings.getAsBoolean("expand", true);
File file = PathUtils
.get(new File(DynamicSynonymPlugin.class.getProtectionDomain().getCodeSource().getLocation().getPath())
.getParent(), "config")
.toAbsolutePath().resolve(Configuration.DB_PROPERTIES).toFile();
final Properties dbProperties = new Properties();
logger.info("加载DynamicSynonym sql properties file" + file);
try {
dbProperties.load(new FileReader(file));
} catch (IOException e) {
logger.info("加载数据库属性文件" + Configuration.DB_PROPERTIES + "失败!");
e.printStackTrace();
}
final String tokenizerName = settings.get("tokenizer", "whitespace");
Analyzer analyzer;
if ("standand".equalsIgnoreCase(tokenizerName)) {
analyzer = new StandardAnalyzer();
} else if ("keyword".equalsIgnoreCase(tokenizerName)) {
analyzer = new KeywordAnalyzer();
} else if ("simple".equalsIgnoreCase(tokenizerName)) {
analyzer = new SimpleAnalyzer();
} else {
analyzer = new WhitespaceAnalyzer();
}
// NOTE: the manager will only init once
SynonymRuleManager
.initial(new Configuration(ignoreCase, expand, Integer.valueOf(dbProperties.getProperty("interval")),
analyzer, dbProperties.getProperty("url"), dbProperties.getProperty("user"),
dbProperties.getProperty("password"), dbProperties.getProperty("sql")));
}
@Override
public TokenStream create(TokenStream tokenStream) {
return new DynamicSynonymTokenFilter(tokenStream);
}
}
2.4 JDBCUtils新建一个我自己的查询数据库的方法querySynonymAiLikenessKeywords()
public static List querySynonymAiLikenessKeywords(String dbUrl,String user,String password,String sql) throws Exception {
List list = new ArrayList();
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(dbUrl,user,password);
stmt = conn.createStatement();
// String sql = "SELECT main_keyword,likeness_keywords FROM ai_keyword WHERE keyword_type = 1 AND is_delete = 1";
if(!StringUtils.isNullOrEmpty(sql)){
rs = stmt.executeQuery(sql);
while (rs.next()) {
String likenessKeywords = rs.getString("likeness_keywords");
if(!StringUtils.isNullOrEmpty(likenessKeywords)){
String keywordAndlikenessKeywords = likenessKeywords + rs.getString("main_keyword");
list.add(keywordAndlikenessKeywords);
}
}
}
} finally {
closeQuietly(conn, stmt, rs);
}
return list;
} 2.5 修改SynonymRuleManager.loadSynonymRule()方法和reloadSynonymRule()方法
private void loadSynonymRule() {
// 回头修改一下,不需要返回值,只需要把数据查询出来就可以了
try {
List synonymRuleList = JDBCUtils.querySynonymAiLikenessKeywords(configuration.getDBUrl(),configuration.getUser(),configuration.getPassword(),configuration.getSql());
this.synonymMap = new SimpleSynonymMap(this.configuration);
for (String rule : synonymRuleList) {
this.synonymMap.addRule(rule);
}
LOGGER.info("Load {} synonym rule succeed!", synonymRuleList.size());
} catch (Exception e) {
LOGGER.error("Load synonym rule failed!", e);
//throw new RuntimeException(e);
}
}
public void reloadSynonymRule() {
// 也需要修改,把数据放到单例的manager中
LOGGER.info("Start to reload synonym rule...");
try {
SynonymRuleManager tmpManager = new SynonymRuleManager();
tmpManager.configuration = getSingleton().configuration;
List synonymRuleList = JDBCUtils.querySynonymAiLikenessKeywords(configuration.getDBUrl(),configuration.getUser(),configuration.getPassword(),configuration.getSql());
SimpleSynonymMap tempSynonymMap = new SimpleSynonymMap(tmpManager.configuration);
for (String rule : synonymRuleList) {
tempSynonymMap.addRule(rule);
}
this.synonymMap = tempSynonymMap;
LOGGER.info("Succeed to reload {} synonym rule!", synonymRuleList.size());
} catch (Throwable t) {
LOGGER.error("Failed to reload synonym rule!", t);
}
} 2.6 修改Monitor.run()方法,直接调用SynonymRuleManager.reloadSynonymRule()就好了
public class Monitor implements Runnable {
@Override
public void run() {
// 线程任务,直接调用reloadSynonymRule
SynonymRuleManager.getSingleton().reloadSynonymRule();
}
}这样就基本上可以了,接下来打包mvn clean package,打包之前别忘了,这个插件也用了mysql,跟上文一样需要到plugin.xml中去修改配置,这里我就不贴图了。打包完成后找到target/releases/下的.zip包,在ES的plugin包下新建一个文件夹,把zip包解压到该目录。到此为止两个插件修改完毕,看看plugin目录:

三、配置
由于同义词过滤器需要配置,Elasticsearch自带的同义词过滤器在分析器配置的话配置如下:
{
"index" : {
"analysis" : {
"analyzer" : {
"synonym_analyzer" : {
"tokenizer" : "whitespace",
"filter" : ["my_synonym"]
}
},
"filter" : {
"my_synonym" : {
"type" : "synonym",
"expand": true,
"ignore_case": true,
"synonyms_path" : "analysis/synonym.txt"
"synonyms" : ["阿迪, 阿迪达斯, adidasi => Adidas","Nike, 耐克, naike"]
}
}
}
}
}所以,想要使用上两个插件就需要对文档进行设置,设置它的analyzer和filter。
由于使用的ES版本问题,5.5.2版本已经不支持在elasticsearch.yml中进行,所以只能通过restfulAPI进行配置
在ES中新建一个文档,通过URL进行设置
PUT ES访问地址:9200/新建的文档/
{
"settings": {
"analysis": {
"analyzer": {
// 自定义一个analyzer
"ik_max_word_synonym": {
// filter用我们自定义的filter
"filter": [
"my_synonym"
],
"tokenizer": "ik_max_word_custom",// 我们修改后的ik分词器的名字
"type": "custom"
}
},
"filter": {
// 自定义一个filter
"my_synonym": {
"expand": true,
"ignore_case": true,
"tokenizer": "ik_max_word_custom",// 这个filter的tokenizer也用修改后的ik
"type": "dynamic-synonym"// 类型是我们修改后的插件
}
}
}
}
}设置成功后
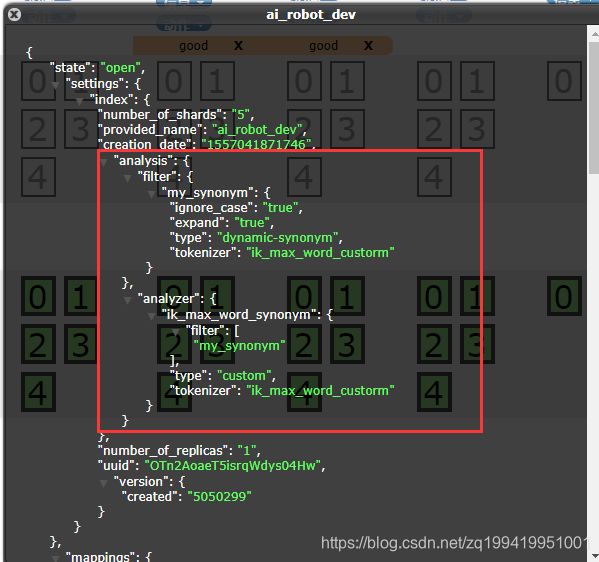
这时候就可以使用了。
接下来还有几个问题:
(1)如果每新建一个文档,要用到这样配置的时候,都这么手动配置太麻烦了,而且几套环境,每一个都去配置,这样不太友好。
(2)重建文档问题,新加入词库的词语对于旧的文档不生效,所以需要有一个定时任务去定时重建文档。
所以接下来我就在项目中把这些实现了一下
项目是一个springboot项目,最开始使用ES的时候,为了图方便,使用的是elasticsearch spring data jpa ,用repository来操作的ES。现在要对settings进行设置,所以我想使用elasticsearchTemplate来进行设置,但是当用elasticsearchTemplate的时候就导致实体类上的注解@Field中配置的映射关系什么的都不生效了。之后网上找了一下才发现,当使用TransportClient客户端的时候会导致那个映射关系失效的。那就索性就不让jpa帮我生成文档了,生成文档的这一步由我自己来操作。

就直接设置@Document注解中的属性createIndex的值为false。
顺便提一下,由于几套环境用的是同一个ES,所以我做了一下动态indexName的操作,通过配置文件来加载索引名字。
首先在配置文件application.properties中设置一个属性
![]()
然后建立一个配置类
EsIndexNameConfig
@Component("esIndexNameConfig")
public class EsIndexNameConfig {
@Value("${ai_robot}")
private String aiRobotindexName;
public String getAiRobotindexName() {
return aiRobotindexName;
}
public void setAiRobotindexName(String aiRobotindexName) {
this.aiRobotindexName = aiRobotindexName;
}
}设置一个成员变量,让这个成员变量加载application.properties中的属性
之后在@Document中用 #{esIndexNameConfig.aiRobotindexName}就能取到indexName了。
好的,接下来继续手动生成文档settings和mapping
1.建立接口类EsSettingsMap
由于考虑到以后可能还有其他文档需要自定义settings的Map,所以弄一个通用的接口类,以后再有新增的文档,就只需要实现这个接口就可以加载了。
/**
* 如果需要把一个映射到es的实体类实现动态加载setting和mapping需要实现此接口,需要把实体类的@Document注解中的属性createIndex = false
* EsIndexSettingAndMappingInit类会加载实现类getSettingsMap()方法返回的settingsMap和实体类上@Field注解配置的mapping
* @author zhangch 2019-05-05
*/
public interface EsSettingsMap {
/**
* 获取一段settings配置,例如:
* {
"settings": {
"analysis": {
"analyzer": {
"ik_max_word_synonym": {
"filter": [
"my_synonym"
],
"tokenizer": "ik_max_word",
"type": "custom"
}
},
"filter": {
"my_synonym": {
"expand": true,
"ignore_case": true,
"tokenizer": "ik_max_word",
"type": "dynamic-synonym"
}
}
}
}
}
这段配置需要的map:
Map ik_max_word_synonym = new HashMap<>(3);
ik_max_word_synonym.put("filter", new String[]{"my_synonym"});
ik_max_word_synonym.put("tokenizer", "ik_max_word_custorm");
ik_max_word_synonym.put("type", "custom");
Map analyzer = new HashMap<>(1);
analyzer.put("ik_max_word_synonym", ik_max_word_synonym);
Map my_synonym = new HashMap<>(4);
my_synonym.put("expand", true);
my_synonym.put("ignore_case", true);
my_synonym.put("tokenizer", "ik_max_word_custorm");
my_synonym.put("type", "dynamic-synonym");
Map filter = new HashMap<>(1);
filter.put("my_synonym", my_synonym);
Map analysis = new HashMap<>(2);
analysis.put("analyzer", analyzer);
analysis.put("filter", filter);
Map settings = new HashMap<>(1);
settings.put("analysis", analysis);
* @return settings;
*/
Map getSettingsMap();
Class getOperatorClass();
}
2.实现接口
/**
* @ClassName: AiRobotEsSettingsMap
* @Description: 实体类AiRobotPo映射的es文档自定义的settings
* @author: zhangch
* @date: 2019年5月5日 下午5:55:37
*/
public class AiRobotEsSettingsMap implements EsSettingsMap {
@Override
public Map getSettingsMap() {
/**
* {
"settings": {
"analysis": {
"analyzer": {
"ik_max_word_synonym": {
"filter": [
"my_synonym"
],
"tokenizer": "ik_max_word_custorm",
"type": "custom"
}
},
"filter": {
"my_synonym": {
"expand": true,
"ignore_case": true,
"tokenizer": "ik_max_word_custorm",
"type": "dynamic-synonym"
}
}
}
}
}
*/
Map ik_max_word_synonym = new HashMap<>(3);
ik_max_word_synonym.put("filter", new String[]{"my_synonym"});
ik_max_word_synonym.put("tokenizer", "ik_max_word_custorm");
ik_max_word_synonym.put("type", "custom");
Map analyzer = new HashMap<>(1);
analyzer.put("ik_max_word_synonym", ik_max_word_synonym);
Map my_synonym = new HashMap<>(4);
my_synonym.put("expand", true);
my_synonym.put("ignore_case", true);
my_synonym.put("tokenizer", "ik_max_word_custorm");
my_synonym.put("type", "dynamic-synonym");
Map filter = new HashMap<>(1);
filter.put("my_synonym", my_synonym);
Map analysis = new HashMap<>(2);
analysis.put("analyzer", analyzer);
analysis.put("filter", filter);
Map settings = new HashMap<>(1);
settings.put("analysis", analysis);
return settings;
}
@Override
public Class getOperatorClass() {
return QuestionPo.class;
}
}
3.建立init类,实现ApplicationRunner接口,让程序在启动的时候就初始化这个设置。逻辑是先获取到EsSettingsMap下的所有实现类,我这里实现的比较简单,默认只找跟这个接口在一个包下所有实现类,所以回头建立实现类的时候只能跟这个接口放在同一目录下。获取到所有实现类后,遍历实现类,先判断这个index在ES是否存在,如果存在就不用管了(之前已经生成过了)。如果不存在,就创建索引,把settingsMap传进去。并且putMapping()一下,这个操作是使实体类上的注解@field中配置的mapping信息生效。
/**
* 初始化es的index的setting和mapping,配置自定义filter和analyzer,并且使po上的mapping配置信息生效
*
* @author zhangch 2019-04-29
*
*/
@Component
public class EsIndexSettingAndMappingInit implements ApplicationRunner {
private Logger logger = LoggerFactory.getLogger(EsIndexSettingAndMappingInit.class);
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Override
public void run(ApplicationArguments args) throws Exception {
// 获取EsSettingsMap的所有实现类,加载他们的settings和mapping
logger.info("---------------------------初始化es的setting和mapping--------------------------------");
try {
List> allAssignedClass = ClassUtil.getAllAssignedClass(EsSettingsMap.class);
logger.info("需要加载{}个实现类", allAssignedClass.size());
for (Class c : allAssignedClass) {
try {
EsSettingsMap map = (EsSettingsMap) c.newInstance();
Map settingsMap = map.getSettingsMap();
boolean indexExists = elasticsearchTemplate.indexExists(map.getOperatorClass());
logger.info("索引{}-{}存在",
elasticsearchTemplate.getPersistentEntityFor(map.getOperatorClass()).getIndexName(),
indexExists ? "" : "不");
if (!indexExists) {
logger.info("加载settingMap:{},加载settings:{}", c.getName(), settingsMap);
elasticsearchTemplate.createIndex(map.getOperatorClass(), settingsMap);
elasticsearchTemplate.putMapping(map.getOperatorClass());
}
} catch (InstantiationException | IllegalAccessException e) {
logger.info("加载settings失败!");
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
ClassUtils的getAllAssignedClass()方法
/**
* 获取同一路径下所有子类或接口实现类
*
* @param intf
* @return
* @throws IOException
* @throws ClassNotFoundException
*/
public static List> getAllAssignedClass(Class cls) throws IOException, ClassNotFoundException {
List> classes = new ArrayList>();
for (Class c : getClasses(cls)) {
if (cls.isAssignableFrom(c) && !cls.equals(c)) {
classes.add(c);
}
}
return classes;
} 这样就实现了在项目中自己配置settings了。
接下来是 定时任务重建文档
springboot的定时任务比较简单,直接用注解就可以了
在启动类上,加上@EnableAsync和@EnableScheduling注解
第二个注解是开启定时任务开关,第一个注解是开启多线程定时任务,避免相同时间的定时任务有冲突。
建立定时任务类EsScheduled
@Component
public class EsScheduled {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
private Logger logger = LoggerFactory.getLogger(EsScheduled.class);
/**
* 重建项目中动态索引的po在es中的文档
*/
@Scheduled(cron = "0 5 0 * * *")
public void reBuildDocument() {
List> allAssignedClass = null;
try {
allAssignedClass = ClassUtil.getAllAssignedClass(EsSettingsMap.class);
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
if (allAssignedClass != null && allAssignedClass.size() > 0) {
for (Class clazz : allAssignedClass) {
EsSettingsMap map;
try {
map = (EsSettingsMap) clazz.newInstance();
boolean indexExists = elasticsearchTemplate.indexExists(map.getOperatorClass());
String indexName = elasticsearchTemplate.getPersistentEntityFor(map.getOperatorClass())
.getIndexName();
logger.info("索引 {} - {} 存在", indexName, indexExists ? "" : "不");
if (indexExists) {
UpdateByQueryRequestBuilder updateByQuery = UpdateByQueryAction.INSTANCE
.newRequestBuilder(elasticsearchTemplate.getClient());
updateByQuery.source(indexName).abortOnVersionConflict(false);
BulkByScrollResponse response = updateByQuery.get();
long updated = response.getUpdated();
logger.info("更新 {} 中的文档 {} 条", indexName, updated);
}
} catch (InstantiationException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
}
}
逻辑也不复杂,也是遍历实现类,看看索引是否存在,如果存在就更新index中的所有记录。我设置的是每天零点过5分扫描。
好了,这样的话整体的方案已经实现了,通过修改ik分词器的源码和以为博主自己写的插件的源码,然后跟项目搭配,实现同义词、扩展词、停止词的热更新并尽量保证词库更新后的效果。
看看测试效果吧
我数据库中的表结构是这样的
CREATE TABLE `ai_keyword` (
`keyword_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '关键词id',
`mid` int(11) DEFAULT NULL COMMENT '企业id',
`eid` int(11) DEFAULT NULL COMMENT '业务员id',
`keyword_type` int(2) NOT NULL COMMENT '关键词类型 1--标准词 2--专有名词 3--停止词',
`main_keyword` varchar(20) NOT NULL COMMENT '标准词',
`likeness_keywords` varchar(255) DEFAULT NULL COMMENT '相似词数组(专有名词和停止词无此项)',
`is_delete` int(2) DEFAULT '1' COMMENT '是否删除 0--已删除 1--未删除',
`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`delete_time` timestamp NULL DEFAULT NULL COMMENT '删除时间',
`standby1` varchar(255) DEFAULT NULL COMMENT '备用字段1',
`standby2` varchar(255) DEFAULT NULL COMMENT '备用字段2',
PRIMARY KEY (`keyword_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COMMENT='关键词表';添加几条数据
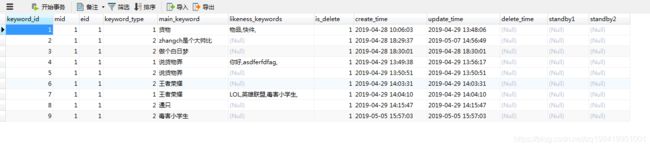
测试
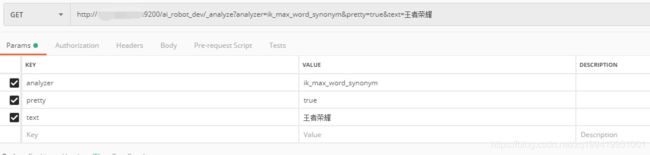
返回数据
{
"tokens": [
{
"token": "lol",
"start_offset": 0,
"end_offset": 4,
"type": "SYNONYM",
"position": 0
},
{
"token": "英雄联盟",
"start_offset": 0,
"end_offset": 4,
"type": "SYNONYM",
"position": 1
},
{
"token": "毒害小学生",
"start_offset": 0,
"end_offset": 4,
"type": "SYNONYM",
"position": 2
},
{
"token": "王者荣耀",
"start_offset": 0,
"end_offset": 4,
"type": "SYNONYM",
"position": 3
},
{
"token": "王者",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 4
},
{
"token": "荣耀",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
}
]
}可以看到,扩展词和同义词都已经生效了。
再添加一条停止词试试
先分词“你要这个干什么”

结果
{
"tokens": [
{
"token": "你",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "要",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "这个",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "干什么",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 3
},
{
"token": "干什",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 4
},
{
"token": "什么",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 5
}
]
}添加停止词“什么”
![]()
测试效果

结果中没有把“什么”这个词给分出来,证明已经被添加到停止词词库了。
好了,这就是我这些天研究的一些乱七八糟的东西的总结,希望能对看到的你有所帮助~~~