Python深入:stevedore简介
stevedore是用来实现动态加载代码的开源模块。它是在OpenStack中用来加载插件的公共模块。可以独立于OpenStack而安装使用:https://pypi.python.org/pypi/stevedore/
stevedore使用setuptools的entry points来定义并加载插件。entry point引用的是定义在模块中的对象,比如类、函数、实例等,只要在import模块时能够被创建的对象都可以。
一:插件的名字和命名空间
一般来讲,entry point的名字是公开的,用户可见的,经常出现在配置文件中。而命名空间,也就是entry point组名却是一种实现细节,一般是面向开发者而非最终用户的。可以用Python的包名作为entry point命名空间,以保证唯一性,但这不是必须的。
entry points的主要特征就是,它可以是独立注册的,也就是说插件的开发和安装可以完全独立于使用它的应用,只要开发者和使用者在命名空间和API上达成一致即可。
命名空间被用来搜索entry points。entry points的名字在给定的发布包中必须是唯一的,但在一个命名空间中可以不唯一。也就是说,同一个发布包内不允许出现同名的entry point,但是如果是两个独立的发布包,却可以使用完全相同的entrypoint组名和entry point名来注册插件。
二:插件的使用方式
在stevedore中,有三种使用插件的方式:Drivers、Hooks、Extensions
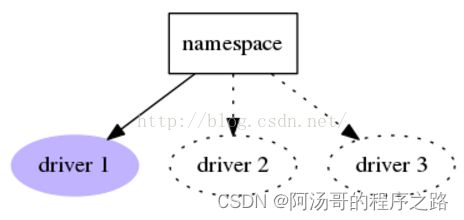
1:Drivers
一个名字对应一个entry point。使用时根据插件的命名空间和名字,定位到单独的插件:
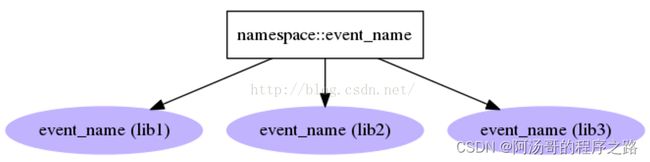
2:Hooks
一个名字对应多个entry point。允许同一个命名空间中的插件具有相同的名字,根据给定的命名空间和名字,加载该名字对应的多个插件:
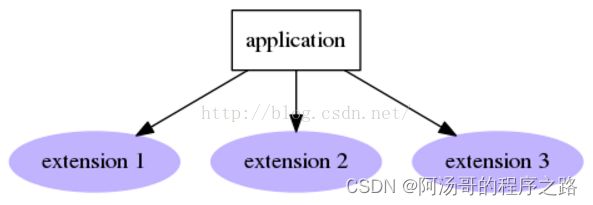
3:Extensions
多个名字,多个entry point。给定命名空间,加载该命名空间中所有的插件,当然也允许同一个命名空间中的插件具有相同的名字
三:定义并注册插件
在经过了大量的试验和总结教训之后,发现定义API最简单的方式是遵循下面的步骤:
a:使用abc模块,创建一个抽象基类来定义插件API的行为;虽然开发者无需继承一个基类,但是这种方式自有它的好处;
b:通过继承基类并实现必要的方法来创建插件
c:为每个API定义一个命名空间。可以将应用或者库的名字,以及API的名字结合起来,这种方式通俗易懂,如 “cliff.formatters”或“ceilometer.pollsters.compute”。
本节例子中创建的插件,用来对数据进行格式化输出,每个格式化方法接受一个字典作为输入,然后按照一定的规则产生要输出的字符串。格式化类可以有一个最大输出宽度的参数。
1:首先定义一个基类,其中的API需要由插件来实现
# example/pluginbase.py
import abc
import six
@six.add_metaclass(abc.ABCMeta)
class FormatterBase(object):
"""Base class for example plugin used in the tutorial."""
def __init__(self, max_width=60):
self.max_width = max_width
@abc.abstractmethod
def format(self, data):
"""Format the data and return unicode text.
:param data: A dictionary with string keys and simple types as
values.
:type data: dict(str:?)
:returns: Iterable producing the formatted text.
"""
2:定义插件1
开始定义具体的插件类,这些类需要实现format方法。下面是一个简单的插件,它产生的输出都在一行上。
# example/simple.py
import pluginbase
class Simple(pluginbase.FormatterBase):
"""A very basic formatter.
"""
def format(self, data):
"""Format the data and return unicode text.
:param data: A dictionary with string keys and simple types as
values.
:type data: dict(str:?)
"""
for name, value in sorted(data.items()):
line = '{name} = {value}\n'.format(
name=name,
value=value,
)
yield line
3:注册插件1
本例中,使用” stevedoretest.formatter”作entry points的命名空间,也就是entry points组名,源码树如下:
setup.py
example/
__init__.py
pluginbase.py
simple.py
该发布包的setup.py内容如下:
from setuptools import setup, find_packages
setup(
name='stevedoretest1',
version='1.0',
packages=find_packages(),
entry_points={
'stevedoretest.formatter': [
'simple = example.simple:Simple',
'plain = example.simple:Simple',
],
},
)
每个entry point都以” name = module:importable ”的形式进行注册,name就是插件的名字,module就是python模块,importable就是模块中可引用的对象。
这里注册了两个插件,simple和plain,这两个插件所引用的Python对象是一样的,都是example.simple:Simple类,因此plain只是simple的别名而已。
定义好setup.py之后,运行python setup.py install即可安装该发布包。安装成功后,在该发布的egg目录中存在文件entry_points.txt,其内容如下:
[stevedoretest.formatter]
plain = example.simple:Simple
simple = example.simple:Simple
运行时,pkg_resources在所有已安装包的entry_points.txt中寻找插件,因此不要手动编辑该文件。
4:定义插件2
使用entry points创建插件的好处之一就是,可以为一个应用独立的开发不同的插件。因此可以在另外一个发布包中定义第二个插件:
#example2/fields.py
import textwrap
from example import pluginbase
class FieldList(pluginbase.FormatterBase):
"""Format values as a reStructuredText field list.
For example::
: name1 : value
: name2 : value
: name3 : a long value
will be wrapped with
a hanging indent
"""
def format(self, data):
"""Format the data and return unicode text.
:param data: A dictionary with string keys and simple types as
values.
:type data: dict(str:?)
"""
for name, value in sorted(data.items()):
full_text = ': {name} : {value}'.format(
name=name,
value=value,
)
wrapped_text = textwrap.fill(
full_text,
initial_indent='',
subsequent_indent=' ',
width=self.max_width,
)
yield wrapped_text + '\n'
5:注册插件2
插件2的源码树如下:
setup.py
example2/
__init__.py
fields.py
在setup.py中,同样要使用”stevedoretest.formatter”作为entry points组名,该发布包的setup.py内容如下:
from setuptools import setup, find_packages
setup(
name='stevedoretest2',
version='1.0',
packages=find_packages(),
entry_points={
'stevedoretest.formatter': [
'fields = example2.fields:FieldList'
],
},
)
这里注册了插件fields,它引用的是example2.fields:FieldList类。定义好setup.py之后,运行python setup.py install即可安装该发布包。在该发布的entry_points.txt文件内容如下:
[stevedoretest.formatter]
fields = example2.fields:FieldList
四:加载插件
1:Drivers加载
最常见的使用插件的方式是作为单独的驱动来使用,这种场景中,可以有多种插件,但只需要加载和调用其中的一个,这种情况下,可以使用stevedore的DriverManager 类。下面就是一个使用该类的例子:
from __future__ import print_function
import argparse
from stevedore import driver
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'format',
nargs='?',
default='simple',
help='the output format',
)
parser.add_argument(
'--width',
default=60,
type=int,
help='maximum output width for text',
)
parsed_args = parser.parse_args()
data = {
'a': 'A',
'b': 'B',
'long': 'word ' * 80,
}
mgr = driver.DriverManager(
namespace='stevedoretest.formatter',
name=parsed_args.format,
invoke_on_load=True,
invoke_args=(parsed_args.width,),
)
for chunk in mgr.driver.format(data):
print(chunk, end='')
其中的parser主要用来解析命令行参数的,该脚本接受三个参数,一个是format,也就是要使用的插件名字,这里默认是simple;另一个参数是–width,是插件方法可能会用到的参数,这里默认是60,该脚本还可以通过–help参数打印帮助信息:
# python load_as_driver.py --help
usage: load_as_driver.py [-h] [--width WIDTH] [format]
positional arguments:
format the output format
optional arguments:
-h, --help show this help message and exit
--width WIDTH maximum output width for text
在该脚本中,driver.DriverManager以插件的命名空间以及插件名来寻找插件,也就是entry points组名和entry points本身的名字。也就是希望通过组名和entry point本身的名字来唯一定位一个插件,但是因为相同的entry points组中可以有同名的entry point,所以,对于DriverManager来说,如果通过entry points组名和entry points本身的名字找到了多个注册的插件,则会报错。比如本例中,如果在”stevedoretest.formatter”中,有多个发布模块注册了名为”simiple”的entry point,则执行该脚本时就会报错:
RuntimeError: Multiple 'stevedoretest.formatter' drivers found: example.simple:Simple,example2.fields:FieldList
因invoke_on_load为True,所以在加载该插件的时候就会调用它,这里插件引用的是一个类,所以加载插件的时候,就会实例化该类。invoke_args会以位置参数的形式,传递给该类的初始化方法,也就是用来设置输出的宽度。
当创建了一个manager之后,就已经创建好了某个具体插件类的实例。该实例的引用被关联到了manager的driver属性上,因此可以通过driver调用该实例的方法了:
for chunk in mgr.driver.format(data):
print(chunk, end='')
运行该脚本,传入不同的参数,可以得到不同的输出格式:
# python load_as_driver.py
a = A
b = B
long = word word ... word
# python load_as_driver.py plain
a = A
b = B
long = word word ... word
# python load_as_driver.py fields
: a : A
: b : B
: long : word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word
# python load_as_driver.py fields --width 30
: a : A
: b : B
: long : word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word
2:Extensions加载
另一种使用插件的方式是一次性的加载多个扩展,可以有多个manager类支持这种使用模式,包括ExtensionManager,NamedExtensionManager和 EnabledExtensionManager。比如下面的代码:
import argparse
from stevedore import extension
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--width',
default=60,
type=int,
help='maximum output width for text',
)
parsed_args = parser.parse_args()
data = {
'a': 'A',
'b': 'B',
'long': 'word ' * 80,
}
mgr = extension.ExtensionManager(
namespace='stevedoretest.formatter',
invoke_on_load=True,
invoke_args=(parsed_args.width,),
)
def format_data(ext, data):
return (ext.name, ext.obj.format(data))
results = mgr.map(format_data, data)
for name, result in results:
print 'Formatter: %s'%name
for chunk in result:
print chunk
ExtensionManager和DriverManager略有不同,它不需要提前知道要加载哪个插件,它会加载所有找到的插件。
要想调用插件,需要使用map方法,需要传给map一个函数,这里就是format_data函数,针对每个扩展都会调用该函数。format_data函数有两个参数,分别是Extension实例和map的第二个参数data:
def format_data(ext, data):
return (ext.name, ext.obj.format(data))
results = mgr.map(format_data, data)
format_data的Extension参数,是stevedore中封装插件的一个类,该类的成员有:表示插件名字的name;表示由pkg_resources返回的EntryPoint实例的entry_point,表示插件本身的plugin,也就是entry_point.load()的返回值;如果invoke_on_load为True,则还有一个成员obj表示调用plugin(*args, **kwds)后返回的结果。
map函数返回一个序列,其中的每个元素就是回调函数的返回值,也就是format_data的返回值。函数format_data返回一个元组,该元组包含扩展的名字,以及调用插件的format方法后的返回值。
插件加载的顺序是未定义的,该顺序取决于找到包的顺序,以及包中元数据文件的读取顺序,如果关心插件加载的顺序的话,可以使用NamedExtensionManager.类。下面是调用该脚本的例子:
# python load_as_extension.py --width=30
Formatter: simple
a = A
b = B
long = word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word
Formatter: plain
a = A
b = B
long = word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word
Formatter: fields
: a : A
: b : B
: long : word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word word word word word
word
之所以要在map中使用回调函数,而不是直接调用插件,是因为这样做可以保持应用代码和插件之间的隔离性,这种隔离性有利于应用代码和插件API的设计。
如果map直接调用插件,则每个插件必须是可调用的,这样命名空间实际上就只能用于插件的一个方法上了。使用回调函数,则插件的API就无需在应用中匹配特定的用例。
3:Hook式加载
最后一种使用插件的方式,相当于Drivers加载和Extensions加载的结合。它允许在给定的entry points组名下有同名的entry point,这样,在给定entry points组名和entry point名的情况下,hook式加载会加载所有找到的插件。
比如这里的例子,在插件2中,注册一个同样名为”simple”的插件,修改其setup.py内如如下:
from setuptools import setup, find_packages
setup(
name='stevedoretest2',
version='1.0',
packages=find_packages(),
entry_points={
'stevedoretest.formatter': [
'fields = example2.fields:FieldList',
'simple= example2.fields:FieldList'
],
},
)
这里的”simple”插件也仅仅是”fields”插件的别名而已,它与”fields”引用的对象是一样的。重新安装插件2之后,定义使用Hook加载插件的脚本如下:
import argparse
from stevedore import hook
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'format',
nargs='?',
default='simple',
help='the output format',
)
parser.add_argument(
'--width',
default=60,
type=int,
help='maximum output width for text',
)
parsed_args = parser.parse_args()
data = {
'a': 'A',
'b': 'B',
'long': 'word ' * 80,
}
mgr = hook.HookManager(
namespace='stevedoretest.formatter',
name = parsed_args.format,
invoke_on_load=True,
invoke_args=(parsed_args.width,),
)
def format_data(ext, data):
return (ext.name, ext.obj.format(data))
results = mgr.map(format_data, data)
for name, result in results:
print 'Formatter: %s'%name
for chunk in result:
print chunk
这里使用hook.HookManager加载插件,参数与构建DriverManager 时是一样的,都是需要给定插件的namespace和name。又因为hook.HookManager继承自NamedExtensionManager,而NamedExtensionManager又继承自ExtensionManager。所以这里使用插件的方式与上例一样。下面是调用该脚本的例子:
# python load_as_hook.py
Formatter: simple
a = A
b = B
long = word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word word
Formatter: simple
: a : A
: b : B
: long : word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word
# python load_as_hook.py fields
Formatter: fields
: a : A
: b : B
: long : word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word word word word word word word word
word word word word
https://blog.csdn.net/gqtcgq/article/details/49620279