ML Design Patterns——Transfer Learning
Simply put
Imagine you're trying to learn a new language. Traditional methods might involve tedious drills and memorization. But wouldn't it be easier if you could leverage your knowledge of another language you already know? That's the essence of transfer learning in the world of Machine Learning (ML).
Think of ML models like students. In supervised learning, they diligently study labeled data (think flashcards) to learn to classify or predict things. But training these models from scratch can be time-consuming and data-hungry, especially for complex tasks.
This is where transfer learning shines. Just like using your existing language skills to pick up a new one, transfer learning leverages knowledge from a pre-trained model ("a language professor") to tackle a new task ("speaking a new language").
Here's how it works:
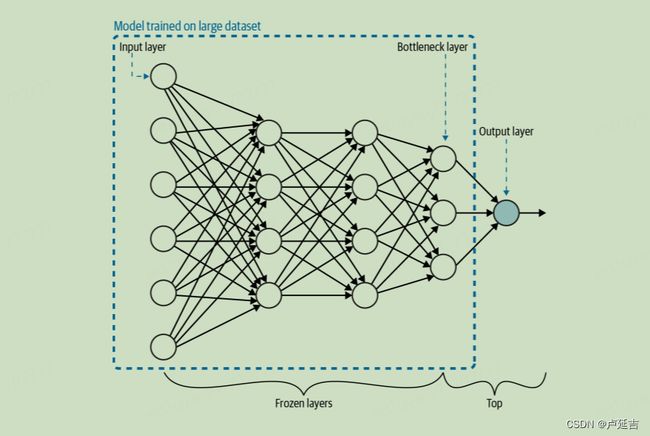
- Pre-trained Model: We have a model already trained on a massive dataset like classifying cats and dogs in images. This model has extracted valuable features and learned general representations (think grammar and vocabulary) about images.
- Fine-tuning: We take this pre-trained model and "fine-tune" it by adjusting its parameters (think tweaks to accent and pronunciation) to the new task, say, classifying different species of birds. We only train the final layers specific to the new task, leaving the earlier layers (the "core knowledge") untouched.
The benefits are obvious:
- Faster training: Pre-trained models already have a head start, reducing training time and data requirements.
- Better performance: Transfer learning can even improve accuracy, especially for small datasets where training a model from scratch would be challenging.
- Versatility: This approach can be applied to various tasks, from image and text classification to natural language processing and even robotics.
Here are some real-world examples:
- Medical diagnosis: Transfer learning can help analyze medical images like X-rays faster and more accurately, even with limited data.
- Self-driving cars: Pre-trained models can help autonomous vehicles recognize objects and navigate roads, building on existing knowledge of traffic signs and lane markings.
- Customer service chatbots: By leveraging pre-trained language models, chatbots can understand different user queries and provide better responses.
So, transfer learning is like that helpful classmate who shares their study notes and insights. It's a powerful technique that makes ML models smarter, faster, and more efficient, accelerating the pace of innovation in various fields.
Remember, this is just a starting point. There's a whole world of exciting research and applications in transfer learning waiting to be explored. So, keep learning, keep asking questions, and keep leveraging existing knowledge to build even more remarkable ML models!
Fine-tuning
In transfer learning, replacing the final layers of a pre-trained model with your own prediction task is often referred to as fine-tuning. It's a powerful technique that leverages the pre-trained model's general knowledge and adapts it to your specific problem.
Here's how it works:
- Pre-trained model: You start with a model that has already been trained on a large dataset for a related task. This model has already learned general features and patterns that can be useful for your task as well.
- Freeze pre-trained layers: The initial layers of the pre-trained model are "frozen" meaning their weights are not updated during training. This helps to preserve the general knowledge that the model has already learned.
- Add new layers: You add new layers on top of the frozen pre-trained layers. These new layers are specific to your own prediction task and will learn to represent the features and relationships that are unique to your data.
- Fine-tune new layers: The new layers are then trained on your own dataset. This fine-tuning process adjusts the weights in the new layers to optimize the model's performance on your specific task.
The advantages of fine-tuning include:
- Faster training: By leveraging the pre-trained model's existing knowledge, you can often achieve good performance on your task with less training data than you would need if you were training a model from scratch.
- Improved accuracy: Fine-tuning can often lead to better accuracy than training a model from scratch, especially if your task is related to the task that the pre-trained model was trained on.
- Reduced development time: By using a pre-trained model, you can save time and effort compared to developing a model from scratch.
Overall, fine-tuning is a powerful technique that can be used to make machine learning models more efficient and effective. It's a key component of transfer learning and is widely used in a variety of applications, including image recognition, natural language processing, and speech recognition.
Implementing transfer learning
1. Define your task and data:
- Task: What are you trying to achieve? Image classification, sentiment analysis, question answering? Clearly define your target task and its objectives.
- Data: What data do you have available? Is it relevant to the pre-trained model you'll use? Ensure your data format aligns with the chosen model's expectations.
2. Choose a pre-trained model:
- Task relevance: Select a model pre-trained on a task similar to yours. Image models for image tasks, language models for NLP tasks, etc.
- Performance and availability: Consider the model's accuracy, training requirements, and available implementations. Popular options include ResNet for image recognition, BERT for NLP, etc.
3. Prepare your data and model:
- Data preprocessing: Clean, pre-process, and format your data according to the chosen model's input requirements (image resizing, text tokenization, etc.).
- Model loading and freezing: Load the pre-trained model's architecture and freeze the relevant layers (usually earlier layers) to preserve their learned features.
4. Add new layers and define loss function:
- New layers: Design and add new layers relevant to your specific task on top of the frozen pre-trained model. These layers will specialize in your task's specifics.
- Loss function: Choose a loss function appropriate for your task (cross-entropy for classification, mean squared error for regression, etc.).
5. Train and fine-tune your model:
- Training procedure: Choose an optimizer (Adam, SGD), learning rate, and training settings specific to your task and data.
- Fine-tuning: Train only the new layers added on top of the frozen pre-trained model, allowing the pre-trained knowledge to guide initial learning.
6. Evaluate and refine:
- Validation dataset: Monitor performance on a separate validation dataset to avoid overfitting.
- Fine-tuning adjustments: Analyze results and potentially adjust training parameters, hyperparameters, or even the new layers' designs.
Remember, these are broad steps, and specific details will vary depending on your chosen model, task, and data. However, this breakdown should provide a solid foundation for thinking through the transfer learning implementation process step-by-step.
Bottleneck layer
A bottleneck layer, also known as a constriction layer, is a layer in a neural network with fewer neurons than the layers before or after it. This creates a "neck" in the network where information must be compressed to pass through.
Here's why bottleneck layers are used:
- Reduce computational complexity: By lowering the number of neurons, bottleneck layers can significantly reduce the number of calculations needed during training and inference. This is particularly beneficial for large networks with millions of parameters.
- Promote feature extraction: The compression forces the network to learn more efficient representations of the input data. This can lead to improved performance on tasks like image recognition and language understanding.
- Regularization: The limited capacity of the bottleneck layer can act as a form of regularization, preventing the network from overfitting to the training data.
Bottleneck layers are commonly found in:
- Convolutional neural networks (CNNs): Especially architectures like Inception and ResNet, where bottleneck layers help control the number of feature maps without sacrificing accuracy.
- Autoencoders: The bottleneck layer represents the compressed code of the input data, essential for learning efficient representations.
- Recurrent neural networks (RNNs): Bottlecaps can be used within LSTM cells to control the memory size and computational cost.
Pre-trained embeddings
Pre-trained embeddings are pre-trained representations of words or sentences learned from large datasets of text or code. These embeddings capture semantic relationships between words, often encoded in dense vectors.
Using pre-trained embeddings offers several advantages:
- Improve model performance: By injecting pre-trained knowledge into your model, you can achieve better results in tasks like classification, sentiment analysis, and question answering, even with limited training data.
- Reduce training time: Learning embeddings from scratch can be time-consuming. Using pre-trained ones can significantly accelerate the training process of your model.
- Handle out-of-vocabulary words: Some pre-trained embeddings offer ways to handle words not seen during their training, making them more versatile for real-world applications.
Popular pre-trained embedding models include:
- Word2Vec: Learns word vectors based on co-occurrence in text.
- GloVe: Captures semantic relationships based on global word occurrences.
- ELMo: Contextual embeddings that consider word dependence in sentences.
- BERT: Powerful contextual embeddings trained on massive amounts of text data.