mysql mha高可用
一、前言
在原本的一主两从数据库架构中,是没有高可用功能的,当主库挂了时不会自动将剩下的从从升级为主库,只能等待主库恢复才能使用,或者手动切换,但是手动切换后需要更改后端服务中的数据库地址信息,在此情况下,需要引入mha服务来实现一主两从数据库的高可用,mha服务可以在主库挂掉时,自动从剩下的从库中选举出一个主库,再将剩下的从库变更为新主库的从库,该mha也有缺点,只能一次性使用,当发生了一次主从切换后,mha manage服务就会挂掉,挂掉的主库信息也会从mha manage配置文件中剔除,当原主库恢复后,需要手动将原主库更改为新主库的从库,再将信息写入mha manage的配置文件中,再启动mha manage,这样下次主从发生故障时mha manage才会再次发挥作用
mha对mysql高可用的实现原理,在主从的每个节点,以及mha manage节点部署mha node服务收集每个节点的信息发送到mha manage,当主节点发生故障时,mha manage节点会及时监控到,mha manage会首先检查每个从节点的健康状态,没问题就会在剩下的从节点中选举出新的主节点,然后对剩下的从节点进行主从配置并将从节点更改为只读,这样就完成了主从节点的故障切换
二、构架
| ip | 服务 | |
| 10.1.60.113 | mysql、mha node | |
| 10.1.60.114 | mysql、mha node | |
| 10.1.60.115 | mysql、mha node | |
| 10.1.60.22 | mha manage、mha node |
三、部署
需要提前部署好一主两从架构的mysql
参考:mysql一主两从读写分离搭建_mysql 一主两从搭建-CSDN博客
在github上下载mha node和mha manage安装包
mha manage
参考: Release mha4mysql-manager-0.58 · yoshinorim/mha4mysql-manager · GitHub
mha node
参考:https://github.com/yoshinorim/mha4mysql-node/releases/tag/v0.58
所有节点安装mha依赖
yum install epel-release --nogpgcheck -y
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker perl-CPAN在所有主机中创建存放mha安装包目录
mkdit /opt/mha && cd /opt/mha
将mha node安装包放到所有节点的mha目录下,mha manage安装包只放到mha manage目录下
先在所有节点安装mha node服务
tar -zxvf mha4mysql-node-0.58.tar.gz && ls

cd mha4mysql-node-0.58
perl Makefile.PL
make && make install
mha node服务安装完成后在mha manage节点安装mha manage服务
tar -zxvf mha4mysql-manager-0.58.tar.gz && ls

cd mha4mysql-manager-0.58
perl Makefile.PL
make && make install
在所有mysql节点创建软连接
ln -s /usr/local/mysql/bin/mysql /usr/sbin/
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/sbin/
配置所有节点互相免密登陆
#113节点执行
ssh-keygen #一直按回车键即可
ssh-copy-id 10.1.60.114
ssh-copy-id 10.1.60.115
ssh-copy-id 10.1.60.22
#114节点执行
ssh-keygen #一直按回车键即可
ssh-copy-id 10.1.60.113
ssh-copy-id 10.1.60.115
ssh-copy-id 10.1.60.22
#115节点执行
ssh-keygen #一直按回车键即可
ssh-copy-id 10.1.60.114
ssh-copy-id 10.1.60.113
ssh-copy-id 10.1.60.22
#22节点执行
ssh-keygen #一直按回车键即可
ssh-copy-id 10.1.60.114
ssh-copy-id 10.1.60.115
ssh-copy-id 10.1.60.113在mha manage上执行以下拷贝文件命令
cp -rp /opt/mha/mha4mysql-manager-0.58/samples/scripts/send_report /usr/local/bin
ls /opt/mha/mha4mysql-manager-0.58/samples/scripts

script目录下有四个文件解释
master_ip_failover:发生故障时自动切换VIP的管理脚本
master_ip_online_change:在线切换vip 的管理脚本
power_manager:故障发生后关闭主机的脚本
send_report:故障切换后发送报警邮件的脚本
我的mysql架构中使用了proxysql读写分离组件,有集成主从故障切换的功能,所以不需要vip,就只拷贝了发送告警的脚本
在mysql主从配置的主库中创建以下用于监控的用户
mysql -u root -p
grant all privileges on *.* to 'mha'@'%' identified by '12345678'
flush privileges;
在mha manage节点中拷贝配置文件
mkdir /etc/masterha
cp /opt/mha/mha4mysql-manager-0.58/samples/conf/app1.cnf /etc/masterha
编辑配置文件
vi /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log #mha manage日志
manager_workdir=/var/log/masterha/app1 #mha manage工作目录
master_binlog_dir=/var/lib/mysql/ #主库保存binlog的位置,这里的路径要与主库里配置的binlog的路径一致,以便MHA能找到
user=mha #监控用户
password=12345678 #监控用户密码
ping_interval=1 #设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover
remote_workdir=/tmp #远端mysql在发生切换时binlog的保存位置
repl_password=12345678 # 主从复制密码
repl_user=deploy # 主从复制用户
report_script=/usr/local/bin/send_report #设置发生故障切换后发送的报警的脚本
ssh_user=root #设置ssh的登录用户名
[server1] #发生故障切换后会删除对应故障的地址项配置
hostname=10.1.60.113 #myqsl地址
port=3306 #myqsl端口
[server2]
hostname=10.1.60.114
port=3306
[server3]
hostname=10.1.60.115
port=3306配置故障切换告警
vi /usr/local/bin/send_report
my $smtp='smtp.qq.com'; # smtp服务器
my $mail_from='[email protected]'; # 发件箱
my $mail_user='123456'; # 用户名 QQ号
my $mail_pass='iozjqgxcvasdwlbffb'; # 授权码
my $mail_to=['[email protected]']; # 收件箱执行mha脚本检查各节点ssh连接状态
masterha_check_ssh --conf=/etc/masterha/app1.cnf
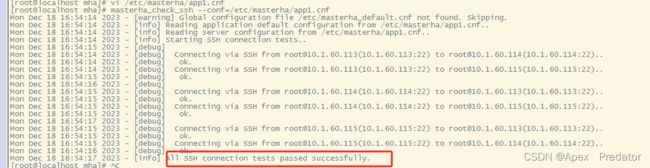
检查数据库主从架构状态
masterha_check_repl --conf=/etc/masterha/app1.cnf
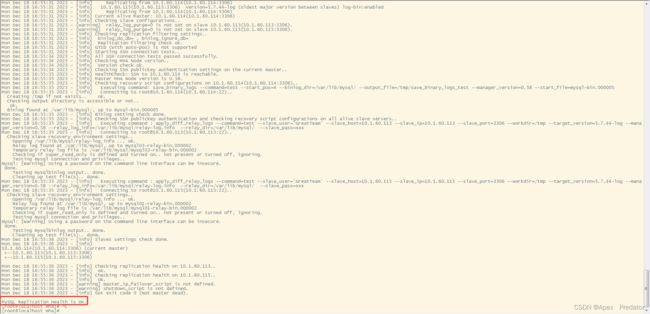
启动mha manage服务
nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/masterha/app1/manager.log 2>&1 &tail -f /var/log/masterha/app1/manager.log
ps -ef|grep manage

至此mha搭建完成,现在是当mha发生主从故障切换时需要手动重新配置mha manage服务,重新在配置文件中新增故障的主节点信息,再重新启动mha manage服务