Pandas数据分析
分析前操作
我们使用read读取数据集时,可以先通过info 方法了解不同字段的条目数量,数据类型,是否缺失及内存占用情况

案例:找到小成本高口碑电影 思路:从最大的N个值中选取最小值
movie2.nlargest(100,'imdb_score') # 用nlargest方法,选出imdb_score分数最高的100个
如果想从前100分数最高的中挑出预算最小的五部:
movie2.nlargest(100,'imdb_score').nsmallest(5,'budget')找到每年imdb评分最高的电影:
movie.groupby('title_year')['imdb_score'].max()
# 通过分组将每年的数据放一块,再把相同年份的imdb_score聚合max
通过排序筛选评分最高的:
movie2:DataFrame = movie[['movie_title','title_year','imdb_score']]
movie2.sort_values('title_year',ascending=False)
# 针对某一列/几列值对整个df进行排序
movie3 = movie2.sort_values(['title_year','imdb_score'],ascending=[False,True])drop_duplicates方法是Pandas库中函数,用于删除DataFrame中的重复行。默认情况下,它会考虑所有列,如果只想根据某些列删除重复项,可以将这些列名作为参数传递给subset参数
movie3.drop_duplicates(subset='title_year',keep='last')
# drop_duplicate方法的keep参数用于指定在删除重复行时保留哪个重复项
# 'first'(默认):保留第一个出现的重复项,删除后续重复项。
# 'last':保留最后一个出现的重复项,删除之前重复项。
# False:删除所有重复项数据连接(concatenation)
连接是指把某行或某列追加到数据中
数据被分成了多份可以使用连接把数据拼接起来
把计算的结果追加到现有数据集,可以使用连接
import pandas as pd
df1 = pd.read_csv('data/concat_1.csv')
df2 = pd.read_csv('data/concat_2.csv')
df3 = pd.read_csv('data/concat_3.csv') 
我们可以使用concat方法将三个数据集加载到一个数据集,列名相同的直接连接到下边
在使用concat连接数据时,涉及到了参数join(join = 'inner',join = 'outer')
pd.concat([df1,df2,df3],ignore_index=True) 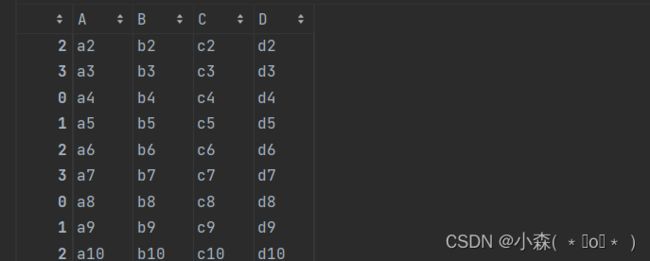
也可以使用concat函数添加列,与添加行的方法类似,需要多传一个axis参数 axis的默认值是index 按行添加

向DataFrame添加一列,不需要调用函数,通过dataframe['列名'] = ['值'] 即可
通过dataframe['列名'] = Series对象 这种方式添加一列
数据连接 merge
数据库中可以依据共有数据把两个或者多个数据表组合起来,即join操作
DataFrame 也可以实现类似数据库的join操作,Pandas可以通过pd.join命令组合数据,也可以通过pd.merge命令组合数据,merge更灵活,如果想依据行索引来合并DataFrame可以考虑使用join函数
how = ’left‘ 对应SQL中的 left outer 保留左侧表中的所有key
how = ’right‘ 对应SQL中的 right outer 保留右侧表中的所有key
how = 'outer' 对应SQL中的 full outer 保留左右两侧侧表中的所有key
how = 'inner' 对应SQL中的 inner 只保留左右两侧都有的key
genres_track= genres.merge(tracks[['TrackId','Name','GenreId','Milliseconds']],on='GenreId',how='outer')concat:
Pandas函数 可以垂直和水平地连接两个或多个pandas对象 只用索引对齐 默认是外连接(也可以设为内连接)
merge:
DataFrame方法 只能水平连接两个DataFrame对象 对齐是靠被调用的DataFrame的列或行索引和另一个DataFrame的列或行索引 默认是内连接(也可以设为左连接、外连接、右连接)