diffusers-Image-to-image










import torch
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
pipeline = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
image = pipeline(prompt, image=init_image, strength=0.8).images[0]
make_image_grid([init_image, image], rows=1, cols=2)






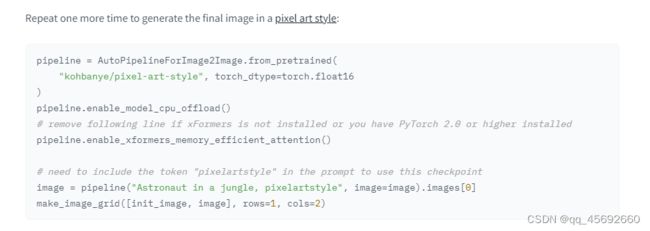
Now you can pass this generated image to the image-to-image pipeline:
pipeline = AutoPipelineForImage2Image.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True
)
pipeline.enable_model_cpu_offload()
# remove following line if xFormers is not installed or you have PyTorch 2.0 or higher installed
pipeline.enable_xformers_memory_efficient_attention()
image2image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", image=text2image).images[0]
make_image_grid([text2image, image2image], rows=1, cols=2)


有点递归套娃的样子了