Java零基础——Elasticsearch篇
1.Elasticsearch简介
Elasticsearch是一个基于Lucene的一个开源的分布式、RESTful 风格的搜索和数据分析引擎。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
2.Lucene 核心库(红黑二叉树)
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。
为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 编写,内部采用 Lucene 做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene 做了一层封装,它提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。

3.和solr对比

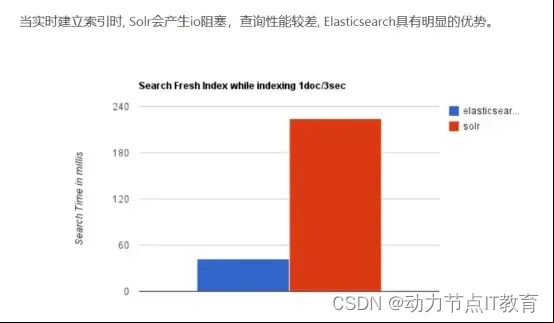


ElasticSearch 对比 Solr 总结
-
es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢
-
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
-
Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
-
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana,head等友好支撑,分词插件
-
Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用(之前);
ES建立索引快(即查询慢),即实时性查询快,用于推特 新浪等搜索。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
- Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。 (现在es也比较火)
4.倒排索引(重点)
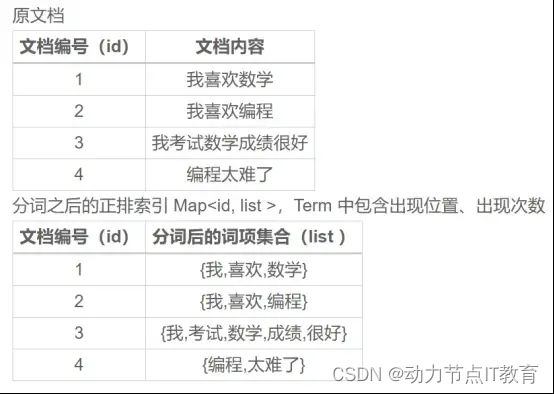
正排索引根据id 找到对应的一组数据 (B+tree 聚簇索引)
非聚簇索引:给一个字段建立索引,查询的时候 根据这个字段查到这行数据对应的id
回表 再根据id 去查 聚簇索引 从而拿到一行数据
4.1 正排索引
4.2 倒排索引
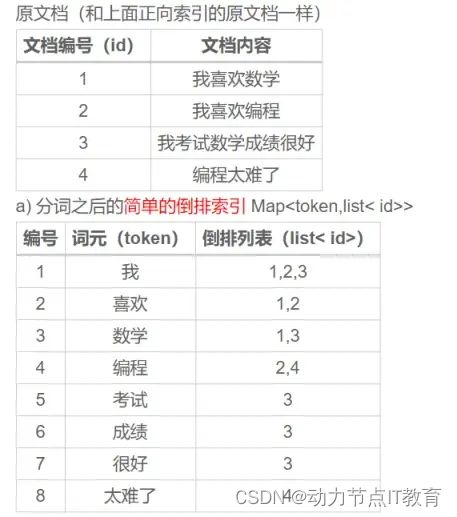
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的 Term 列表。
5.分词
就是按照一定的规则,将一句话分成组合的单词,按照国人喜欢来进行的
海上生明月 - 如何分成 ----->海上 | 生 | 明月
我想要个女朋友 ---- > 我|想要|要个|女朋友|朋友
6.模拟一个倒排索引
原理步骤:
-
将数据存入mysql之前,对其进行分词
-
讲分词和存入后得到的id,存放在数据结构中Map
-
查询时先分词,然后从index中拿到Set ids
-
再根据ids 查询mysql,从而得到结果,这样借助了mysql的B+tree索引,提高性能
6.1 创建boot项目选择依赖

6.2 引入分词的依赖
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
6.3 修改启动类,注入结巴分词器
/**
* 往IOC容器中入住结巴分词组件
*
* @return
*/
@Bean
public JiebaSegmenter jiebaSegmenter() {
return new JiebaSegmenter();
}
6.4 测试分词
@Autowired
public JiebaSegmenter jiebaSegmenter;
@Test
void testJieBa() {
String words = "华为 HUAWEI P40 Pro 麒麟990 5G SoC芯片 5000万超感知徕卡四摄 50倍数字变焦 8GB+256GB零度白全网通5G手机";
// 使用结巴分词,对字符串进行分词,分词类型为搜索类型
List<SegToken> tokens = jiebaSegmenter.process(words, JiebaSegmenter.SegMode.INDEX);
// 遍历,拿到SegToken对象中的word属性,打印结果
tokens.stream()
.map(token -> token.word)
.collect(Collectors.toList())
.forEach(System.out::println);
}
6.5 使用商品搜索案例来展示倒排索引结构
6.5.1 新建Goods类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Goods {
/**
* 商品的id
*/
private Integer goodsId;
/**
* 商品的名称(主要分词和检索字段)
*/
private String goodsName;
/**
* 商品的价格
*/
private Double goodsPrice;
}
6.5.2 模拟数据库,新建DBUtil类
public class DBUtil {
/**
* 模拟数据库,key=id,value=商品对象
* 这里也可以使用List来模拟
*/
public static Map<Integer, Goods> db = new HashMap<>();
/**
* 插入数据库
*
* @param goods
*/
public static void insert(Goods goods) {
db.put(goods.getGoodsId(), goods);
}
/**
* 根据id得到商品
*
* @param id
* @return
*/
public static Goods getGoodsById(Integer id) {
return db.get(id);
}
/**
* 根据ids查询商品集合
*
* @param ids
* @return
*/
public static List<Goods> getGoodsByIds(Set<Integer> ids) {
if (CollectionUtils.isEmpty(ids)) {
return Collections.emptyList();
}
List<Goods> goods = new ArrayList<>(ids.size() * 2);
// 循环ids
ids.forEach(id -> {
// 从数据库拿到数据
Goods g = db.get(id);
if (!ObjectUtils.isEmpty(g)) {
goods.add(g);
}
});
return goods;
}
}
6.5.3 创建倒排索引的数据结构
public class InvertedIndex {
/**
* 倒排索引 key = 分词,value= ids
*/
public static Map<String, Set<Integer>> index = new HashMap<>();
}
6.5.4 创建GoodsService接口
public interface GoodsService {
/**
* 添加商品的方法
*
* @param goods
*/
void addGoods(Goods goods);
/**
* 根据商品名称查询
*
* @param name
* @return
*/
List<Goods> findGoodsByName(String name);
/**
* 根据关键字查询
*
* @param keywords
* @return
*/
List<Goods> findGoodsByKeywords(String keywords);
}
6.5.5 创建GoodsServiceImpl实现类
@Service
public class GoodsServiceImpl implements GoodsService {
@Autowired
private JiebaSegmenter jiebaSegmenter;
/**
* 添加商品的方法
* 1.先对商品名称进行分词,拿到了List tokens
* 2.将商品插入数据库 拿到商品id
* 3.将tokens和id放入倒排索引中index
*
* @param goods
*/
@Override
public void addGoods(Goods goods) {
// 分词
List<String> keywords = fenci(goods.getGoodsName());
// 插入数据库
DBUtil.insert(goods);
// 保存到倒排索引中
saveToInvertedIndex(keywords, goods.getGoodsId());
}
/**
* 保存到倒排索引的方法
*
* @param keywords
* @param goodsId
*/
private void saveToInvertedIndex(List<String> keywords, Integer goodsId) {
// 拿到索引
Map<String, Set<Integer>> index = InvertedIndex.index;
// 循环分词集合
keywords.forEach(keyword -> {
Set<Integer> ids = index.get(keyword);
if (CollectionUtils.isEmpty(ids)) {
// 如果之前没有这个词 就添加进去
HashSet<Integer> newIds = new HashSet<>(2);
newIds.add(goodsId);
index.put(keyword, newIds);
} else {
// 说明之前有这个分词 我们记录id
ids.add(goodsId);
}
});
}
/**
* 分词的方法
*
* @param goodsName
* @return
*/
private List<String> fenci(String goodsName) {
List<SegToken> tokens = jiebaSegmenter.process(goodsName, JiebaSegmenter.SegMode.SEARCH);
return tokens.stream()
.map(token -> token.word)
.collect(Collectors.toList());
}
/**
* 根据商品名称查询
*
* @param name
* @return
*/
@Override
public List<Goods> findGoodsByName(String name) {
// 查询倒排索引中 是否有这个词
Map<String, Set<Integer>> index = InvertedIndex.index;
Set<Integer> ids = index.get(name);
if (CollectionUtils.isEmpty(ids)) {
// 查询数据库 模糊匹配去
} else {
// 说明分词有 根据ids 查询数据库
return DBUtil.getGoodsByIds(ids);
}
return Collections.emptyList();
}
/**
* 根据关键字查询
*
* @param keywords
* @return
*/
@Override
public List<Goods> findGoodsByKeywords(String keywords) {
// 进来先把关键字分词一下
List<String> tokens = fenci(keywords);
// 拿到倒排索引
Map<String, Set<Integer>> index = InvertedIndex.index;
Set<Integer> realIds = new HashSet<>();
// 循环分词集合 查询倒排索引
tokens.forEach(token -> {
Set<Integer> ids = index.get(token);
if (!CollectionUtils.isEmpty(ids)) {
// 如果局部的ids不为空,就添加到总的ids里面去
realIds.addAll(ids);
}
});
// 查询数据库
return DBUtil.getGoodsByIds(realIds);
}
}
6.5.6 编写测试类
@Autowired
public GoodsService goodsService;
/**
* 测试我们自己写的倒排索引
*
* @throws Exception
*/
@Test
public void testMyIndex() throws Exception {
// 造数据
Goods goods = new Goods(1, "苹果手机", 10.00);
Goods goods1 = new Goods(2, "华为手机", 11.00);
Goods goods2 = new Goods(3, "红米手机", 5.00);
Goods goods3 = new Goods(4, "联想手机", 6.00);
goodsService.addGoods(goods);
goodsService.addGoods(goods1);
goodsService.addGoods(goods2);
goodsService.addGoods(goods3);
// 查询
goodsService.findGoodsByName("苹果手机").forEach(System.out::println);
System.out.println("--------------------------------------------");
goodsService.findGoodsByKeywords("苹果手机").forEach(System.out::println);
}
7.Elasticsearch安装
下载地址 https://www.elastic.co/cn/downloads/past-releases#elasticsearch
echo 3 > /proc/sys/vm/drop_caches

1.Docker拉取镜像,我们选7.15.2版本,因为springboot的2.6.3版指定的是这个版本
docker pull elasticsearch:7.15.2
- 运行镜像
docker run -d --name elasticsearch --net=host -p 9200:9200 -p 9300:9300 -e “discovery.type=single-node” -e ES_JAVA_OPTS=“-Xms256m -Xmx256m” elasticsearch:7.15.2
- 试访问 ip:9200

- 意外
错误:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144],你最少需要262144的内存
运行:sysctl -w vm.max_map_count=262144
重启容器就ok 了
8.Elasticsearch目录学习
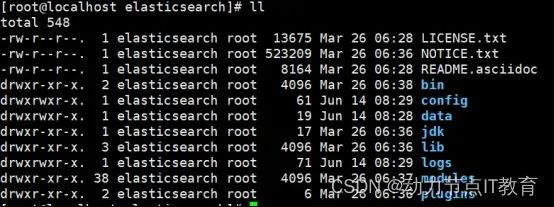
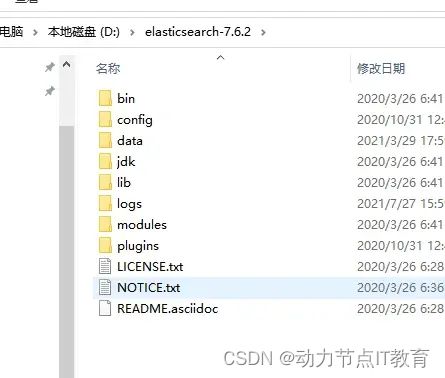
bin:启动脚本
config:
elasticsearch.yml,ES的集群信息、对外端口、内存锁定、数据目录、跨域访问等属性的配置
jvm.options,ES使用Java写的,此文件用于设置JVM相关参数,如最大堆、最小堆
log4j2.properties,ES使用log4j作为其日志框架
data:数据存放目录(索引数据)
plugins: ES的可扩展插件存放目录,如可以将ik中文分词插件放入此目录,ES启动时会自动加载
9.Elasticsearch可视化插件的安装
9.1 谷歌插件方式

9.2 Docker镜像方式安装(和9.1选择一个玩)

docker run --name eshead -p 9100:9100 -d mobz/elasticsearch-head:5
9.3 解决跨域问题

1.进入elasticsearch容器
docker exec -it elasticsearch bash
2.进入配置文件
cd /usr/share/elasticsearch/config
- 修改elasticsearch.yml配置文件,
vi elasticsearch.yml
- 结尾添加
http.cors.enabled: true
http.cors.allow-origin: “*”
- 重启elasticsearch后访问即可
docker restart elasticsearch
10.IK分词的安装【重点】**
Ik分词在es 里面也是插件的形式安装的
10.1 没有ik分词的时候

10.2 IK分词安装(方式一受网速影响)
- 找对应的ES版本的IK分词
https://github.com/medcl/elasticsearch-analysis-ik/releases
-
进入容器 docker exec -it elasticsearch bash
-
进入这个目录 /usr/share/elasticsearch/bin
-
执行命令 install 后面的连接就是从上面找到的对应的版本下载链接
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.15.2/elasticsearch-analysis-ik-7.15.2.zip
- 下载完成

10.3 IK分词安装(方式二推荐)
-
找对应的ES版本的IK分词 https://github.com/medcl/elasticsearch-analysis-ik/releases
-
下载到windows上
-
将zip文件拷贝到linux上
-
docker cp linux的路径 elasticsearch:/usr/share/elasticsearch/plugins

-
进容器后解压,注意名字unzip elasticsearch-analysis-ik-7.15.2.zip -d ./ik/
-
删掉zip文件 elasticsearch-analysis-ik-7.15.2.zip
10.4 重启ES测试
docker restart elasticsearch
Ik分词的两种方式:
ik_smart:分词的粒度较小,也叫智能分词
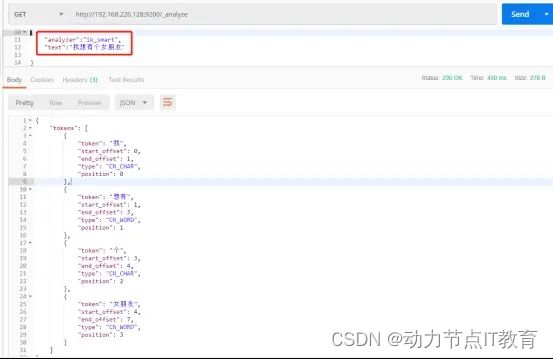
ik_max_word:分词的粒度较大,也叫最大力度分词

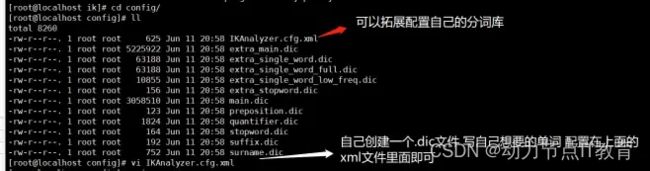
10.5 自定义分词【了解】
进入容器
11.Elasticsearch核心概念【重点】
一个json串 叫文档 es又被叫文档性数据库
11.1 结构说明

11.2 索引库(indices)
把数据写入elasticsearch 时,会在里面建立索引,索引库里面存储索引,一个index 对应一个database
11.3 文档(document)
就是一条数据,一般使用json 表示,和数据库对比,就是一行数据,在java 里面就是一个一个对象
11.4 字段(field)
一个对象的属性,对应数据库就是一列
11.5 节点
一台运行elasticsearch的服务器,被称为一个节点
11.6 集群
多个节点组成一个集群
11.7 分片
一个索引可以存储在多个主分片上,有负载均衡的作用,还有从分片是主分片的一个副本
11.8 副本
一份数据可以有多个副本,做数据冗余(安全),一般放在从分片里面

12.Elasticsearch基本使用(重点)
Elasticsearch 是基于restful风格的http应用
Restful风格就是使用http动词形式对url资源进行操作(GET,POST,PUT,DELETE…)
操作格式为:
请求类型 ip:port/索引名/_doc/文档id
{请求体}
12.1 对索引和mappings的操作(建库建表约束)
12.1.1 新增索引
PUT http://192.168.226.128:9200/student 新建一个student索引,给定几个字段约束
索引只能增删,不能修改
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"birthDay":{
"type": "date"
},
"price":{
"type": "double"
}
}
}
}
查询索引信息

查询索引的mappings信息

12.1.2 删除索引
DELETE http://192.168.226.128:9200/student
12.2 对Document的操作
12.2.1 新增数据(方便后面演示,自己多新增几条)
使用put请求新增时需要自己指定id,使用post请求新增时系统会自动生成一个id
PUT http://192.168.226.128:9200/user/_doc/1 请求解释
user: 索引名称
_doc:类型(即将剔除,官方建议全部使用_doc)
1: 文档id

从head插件里面查看数据

12.2.2 修改一个数据
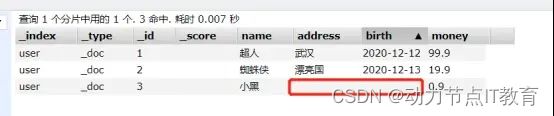
- 危险的修改,把其他的字段值都删了
PUT http://192.168.226.128:9200/user/_doc/2

- 安全的修改,其他的字段值会保留
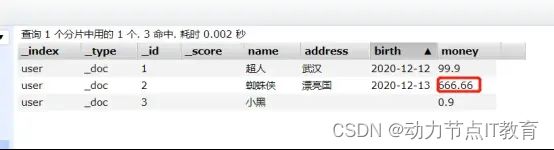
POST http://192.168.226.128:9200/user/_doc/2/_update

12.2.3 删除一个数据
DELETE http://192.168.226.128:9200/user/_doc/3


12.2.4 查询一个数据
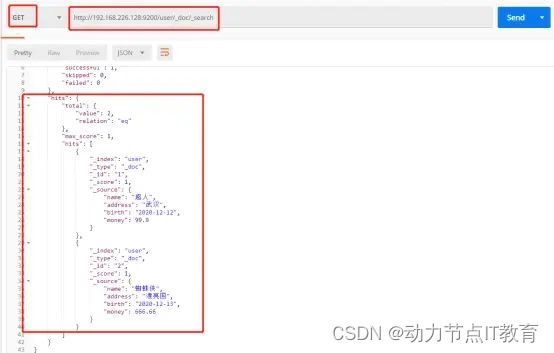
GET http://192.168.226.128:9200/user/_doc/1
12.2.5 查询全部数据
GET http://192.168.226.128:9200/user/_doc/_search
13.SpringBoot使用ES【重点】
13.1 新建项目选择依赖

13.2 修改配置文件
spring:
elasticsearch:
uris: http://192.168.226.129:9200
13.3 测试连接ES
说明我们连接成功,下面开始操作
13.4 对索引的操作,我们直接使用实体类操作
13.4.1 新建Goods实体类
/**
* @Document是ES提供的注解 indexName:索引名称
* createIndex:启动时是否创建
* shards:分片个数
* replicas:副本个数
* refreshInterval:数据导入到索引里面,最多几秒搜索到
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Setting(shards = 2,replicas = 1,refreshInterval = "1s")
@Document(indexName = "goods_index")
public class Goods {
/**
* 商品ID
*/
@Id //默认使用keyword关键字模式,不进行分词
@Field
private Integer goodsId;
/**
* 商品名称
* analyzer:导入时使用的分词
* searchAnalyzer:搜索时使用的分词
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String goodsName;
/**
* 商品描述
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String goodsDesc;
/**
* 商品价格
*/
@Field(type = FieldType.Double)
private Double goodsPrice;
/**
* 商品的销量
*/
@Field(type = FieldType.Long)
private Long goodsSaleNum;
/**
* 商品的卖点
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String goodsBrief;
/**
* 商品的状态
*/
@Field(type = FieldType.Integer)
private Integer goodsStatus;
/**
* 商品的库存
*/
@Field(type = FieldType.Integer)
private Integer goodsStock;
/**
* 商品的标签
*/
@Field(type = FieldType.Text)
private List<String> goodsTags;
/**
* 上架的时间
* 指定时间格式化
*/
private Date goodsUpTime;
}
13.5 对文档的操作,我们熟悉的CRUD
13.5.1 创建goodsDao
@Repository
public interface GoodsDao extends ElasticsearchRepository<Goods, Integer> {
}
13.5.2 新增数据
@Autowired
private GoodsDao goodsDao;
/**
* 描述: 对document的curd
*
* @param :
* @return void
*/
@Test
public void testDocumentCurd() throws Exception {
//新增商品数据100条
ArrayList<Goods> goods = new ArrayList<>(200);
for (int i = 1; i <= 100; i++) {
goods.add(
new Goods(i,
i % 2 == 0 ? "华为电脑" + i : "联想电脑" + i,
i % 2 == 0 ? "轻薄笔记本" + i : "游戏笔记本" + i,
4999.9 + i,
999L,
i % 2 == 0 ? "华为续航强" : "联想性能强",
i % 2 == 0 ? 1 : 0,
666 + i,
i % 2 == 0 ? Arrays.asList("小巧", "轻薄", "续航") : Arrays.asList("炫酷", "畅玩", "游戏"),
new Date())
);
}
goodsDao.saveAll(goods);
}
13.5.3 修改数据(注意是危险修改)
@Test
public void testUpdate() throws Exception {
goodsDao.save(new Goods(1, "小米笔记本", null, null, null, null, null, null, null, null));
}
13.5.4 删除数据
@Test
public void testDelete() throws Exception{
goodsDao.deleteById(1);
}
13.5.5 根据id查询数据
@Test
public void testSearchById() throws Exception {
Optional<Goods> byId = goodsDao.findById(502);
System.out.println(byId.get());
}
13.5.6 查询所有数据
@Test
public void testSearchAll() throws Exception {
Iterable<Goods> all = goodsDao.findAll();
all.forEach(System.out::println);
}
14.复杂的查询操作【重点】
14.1 查询注意点
match:会通过分词器去模糊匹配 例如:华为电脑,会把包含‘华为’,‘电脑’,都查出来
matchPhrase:不分词查询,弥补了match和term
term:精确查找你的关键字,一般使用keywords的约束,使用term
rang:范围查询
match 和 rang 如果同时出现,需要组合bool查询
分页,排序是通用的查询,不需要通过bool组合使用,直接nativeSearchQueryBuilder使用
14.2 查询常用类
QueryBuilders:构造条件对象,例如matchQuery,rangeQuery,boolQuery等
NativeSearchQueryBuilder:组合条件对象,组合后使用build构建查询对象
HighlightBuilder:高亮的查询类,注意使用它的Field静态内部类
FunctionScoreQueryBuilder:权重类,注意它的FilterFunctionBuilder静态内部类
14.3 关键字,范围,分页,排序
@Test
public void testFuZaSearch() throws Exception {
//关键字,“华为” ,范围,分页,排序
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("goodsName", "华为");
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("goodsStock").from(700).to(750);
//使用bool组合这两个查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().must(matchQueryBuilder).must(rangeQueryBuilder);
//创建组合器
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
//去build()构建查询对象
NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder
.withQuery(boolQueryBuilder)
.withPageable(PageRequest.of(0, 20)) //注意范围和分页有关系,可能查出来了,但是当前分页没有
.withSort(SortBuilders.fieldSort("goodsPrice").order(SortOrder.ASC))
.build();
//使用es查询 得到结果集
SearchHits<Goods> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
searchHits.forEach(goodsSearchHit -> {
//循环结果集,答应结果
System.out.println(goodsSearchHit.getContent());
});
}
14.4 高亮查询
@Test
public void testHighlight() throws Exception {
//华为,模糊匹配
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("goodsName", "华为");
HighlightBuilder.Field goodsName = new HighlightBuilder.Field("goodsName").preTags("").postTags("");
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder
.withQuery(matchQueryBuilder)
.withHighlightFields(goodsName)
.build();
//得到结果集 我们需要手动组装高亮字段
SearchHits<Goods> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
List<Goods> goodsArrayList = new ArrayList<>();
searchHits.forEach(goodsSearchHit -> {
//得到goods对象,但是这里面额goodsName属性不是高亮的,所以要改
Goods goods = goodsSearchHit.getContent();
List<String> highlightField = goodsSearchHit.getHighlightField("goodsName");
String highlight = highlightField.get(0);
goods.setGoodsName(highlight);
goodsArrayList.add(goods);
});
System.out.println(JSON.toJSONString(goodsArrayList));
}
}
14.5 权重查询
@Test
public void testWeight() throws Exception {
//手机名称 和卖点 都有的情况下,设置权重查询
String keyWords = "华为";
//创建权重数组
FunctionScoreQueryBuilder.FilterFunctionBuilder[] functionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[2];
//设置权重
functionBuilders[0] = (new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.matchQuery("goodsName", keyWords),
ScoreFunctionBuilders.weightFactorFunction(10)//给名称设置10的权重大小
));
functionBuilders[1] = (
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.matchQuery("goodsBrief", keyWords),
ScoreFunctionBuilders.weightFactorFunction(4)//给卖点设置4的权重
));
FunctionScoreQueryBuilder functionScoreQueryBuilder = new FunctionScoreQueryBuilder(functionBuilders);
functionScoreQueryBuilder.setMinScore(2) //设置最小分数
.scoreMode(FunctionScoreQuery.ScoreMode.FIRST);//设置计分方式
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(functionScoreQueryBuilder).build();
SearchHits<Goods> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
searchHits.forEach(goodsSearchHit -> {
//循环结果集,答应结果
System.out.println(goodsSearchHit.getContent());
});
}
15.ES集群(了解)
这里使用windows方式演示集群
Linux上的集群道理一样,修改配置文件即可
可以参考https://my.oschina.net/u/4353003/blog/4333773
15.1 创建三个es节点
解压出三个来

15.2 修改配置文件
15.2.1 Node1修改配置文件
进入elasticsearch-7.15.2-node1\config下,修改elasticsearch.yml
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: my-esCluster
# 设置节点名称,集群内节点名称必须唯一。
node.name: node1
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 索引数据存放的位置
#path.data: /opt/elasticsearch/data
# 日志文件存放的位置
#path.logs: /opt/elasticsearch/logs
# 需求锁住物理内存,是:true、否:false
#bootstrap.memory_lock: true
# 监听地址,用于访问该es
network.host: 0.0.0.0
# es对外提供的http端口,默认 9200
http.port: 9200
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9300
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.186.1:9300", "192.168.186.1:9301", "192.168.186.1:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false
15.2.2 Node2修改配置文件
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: my-esCluster
# 设置节点名称,集群内节点名称必须唯一。
node.name: node2
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 索引数据存放的位置
#path.data: /opt/elasticsearch/data
# 日志文件存放的位置
#path.logs: /opt/elasticsearch/logs
# 需求锁住物理内存,是:true、否:false
#bootstrap.memory_lock: true
# 监听地址,用于访问该es
network.host: 0.0.0.0
# es对外提供的http端口,默认 9200
http.port: 9201
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9301
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.186.1:9300", "192.168.186.1:9301", "192.168.186.1:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false
15.2.3 Node3修改配置文件
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: my-esCluster
# 设置节点名称,集群内节点名称必须唯一。
node.name: node3
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 索引数据存放的位置
#path.data: /opt/elasticsearch/data
# 日志文件存放的位置
#path.logs: /opt/elasticsearch/logs
# 需求锁住物理内存,是:true、否:false
#bootstrap.memory_lock: true
# 监听地址,用于访问该es
network.host: 0.0.0.0
# es对外提供的http端口,默认 9200
http.port: 9202
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9302
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.186.1:9300", "192.168.186.1:9301", "192.168.186.1:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false
15.3 启动es
进入bin目录下 逐个启动,三台全部双击启动,注意不要关闭黑窗口
15.4 访问查看集群信息和状态
访问查看:http://127.0.0.1:9200/_cat/nodes

也可以使用head插件查看

15.5 SpringBoot连接es集群
spring:
elasticsearch:
uris:
- http://127.0.0.1:9200
- http://127.0.0.1:9201
- http://127.0.0.1:9202
16.Es总结面试
16.1 为什么使用es (结合项目业务来说)
商城中的数据,将来会非常多,所以采用以往的模糊查询,模糊查询前置配置,会放弃索引,(%name%)导致商品查询是全表扫描,在百万级别的数据库中,效率非常低下,而我们使用ES做一个全文索引,我们将经常查询的商品的某些字段,比如说商品名,描述、价格还有id这些字段我们放入我们索引库里,可以提高查询速度。 (数据量过大,而且用户经常使用查询的场景,对用户体验很好)
16.2 es用来做什么(场景)重点
-
商品存放 (业务数据的存放) 每个商品都是一个对象
-
日志统计 (整个应用的日志非常多,都要收集起来,方便后期做日志分析,数据回溯)
-
数据分析(大数据)(只要是电商,就要和tb,jd等对比价格,做数据分析等)
你做一个电商项目 你卖鞋子 衣服 你怎么 定价 鞋子 199 599 398
你写个爬虫 定期采集tb jd的数据库 做数据比对分析 做 竞品 分析
定期的做数据采集和分析 数据采集系统 定时任务去采集别的大型电商网站的数据,进行价格分析,从而定价,后期还要做竞品分析
16.3 什么是倒排索引
通常正排索引是通过id映射到对应的数据
倒排索引是将分词建立索引,通过分词映射到id,在通过id找到数据
详见文档4.2
16.4 es的存储数据的过程
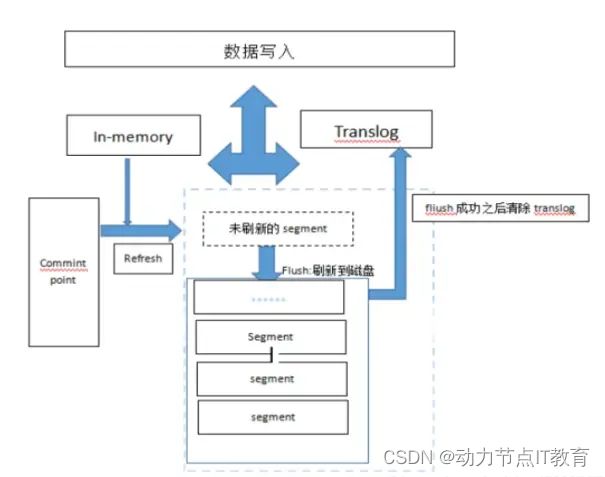
1:写入请求,分发节点。
2:数据写入同时写入内存和translog各一份,tanslog为保证数据不丢失,每 5 秒,或每次请求操作结束前,会强制刷新 translog 日志到磁盘上
3:确定数据给那个分片,refresh 刷新内存中数据到分片的segment,默认1秒刷新一次,为了提高吞吐量可以增大60s。参数refresh_interval(refresh操作使得写入文档搜索可见)
4:通过flush操作将segment刷新到磁盘中完成持久化,保存成功清除translog,新版本es的 translog 不会在 segment 落盘就删,而是会保留,默认是512MB,保留12小时。每个分片。所以分片多的话 ,要考虑 translog 会带来的额外存储开销(flush操作使得filesystem cache写入磁盘,以达到持久化的目的) (refresh之前搜索不可见)
5:segment过多会进行合并merge为大的segment,消耗大量的磁盘io和网络io (方便数据整理和磁盘优化)
16.5 es的搜索过程
1、搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
2、在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分
片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的
优先队列。
注意:在搜索的时候是会查询 Filesystem Cache 的,但是有部分数据还在 Memory
Buffer,所以搜索是接近实时的。
3、每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点(主节点),它合并
这些值到自己的优先队列中来产生一个全局排序后的结果列表。
4、接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片
提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回
文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
通俗的将就是:
每个分片先拿到id和排序值,然后整合成一个全局列表
然后通过判断找到相应的节点提交多个get请求,组装数据返回
https://javajl.yuque.com/docs/share/61000afe-fc17-4bb7-9279-63bfba5fd6cc?# 《Elasticsearch 7.x(入门)》密码:yk91