机器学习入门二(无监督学习中的聚类算法)
目录
1.前言
2.聚类算法简介
3.K-Means聚类
3.1算法实现
3.2算法实战
4.密度聚类DBSCAN
4.1算法介绍
4.2DBSCAN实战 (还是鸢尾花数据集不过是datasets里的)
5.小结
1.前言
上一篇文章我们已经知道了无监督学习中分为两个大类别,分别是聚类和降维。今天作者要带着大家较为详细的学习无监督学习中的聚类算法。
2.聚类算法简介
何为聚类呢?“物以类聚,人以群分”,当人们面对很多事物的时候,会潜意识的将他们分门别类的看待,对事物的分类是我们无时无刻在做的事情。例如,在高中学的生物中,为了研究生物的演变过程和关系,生物学家们根据生物的不同特征,将生物归为不同的界、门、纲、目、科、属、种中。早期人们知识主观性的凭借戒烟和专业知识进行定性分类,很少利用数学方法进行定量分析,从而导致了许多分类带有主观性。然而,由于十五的复杂性和信息量的爆炸式增加,通过一定的数学方法进行定量分析成为了科学发展的一大趋势,其中聚类分析就是一种针对特征进行定量无监督学习分类的方法。
怎么聚类呢?其实聚类还是比较简单的。其实就是将若干个个体,按照某种标准分成若干个簇(这里的簇就相当于一个类别),并且希望簇内存样本尽可能的相似,而簇与簇之间要尽量不相似。就如图下面的图所示,圆形分为一个簇,五角星分为一个簇,矩形分为一个簇。

这里要强调说明一下,上图只是一个简单的说明什么是聚类,但并不是说明每个聚类算法的结果相同,上图大家会默认为只有一种结果,实际在操作的过程中,在相同的数据集下,当我们使用不同的聚类算法时,产生的聚类结果其实是各不相同的。
因为聚类分析在分为不同的簇时,不需要提前知道每个数据类别标签,所以整个聚类过程时无监督的。
因为能力有限,本文作者将只会带领大家学习K-均值聚类;基于密度划分的高密度连通区域算法(DBSCAN)。
3.K-Means聚类
3.1算法实现
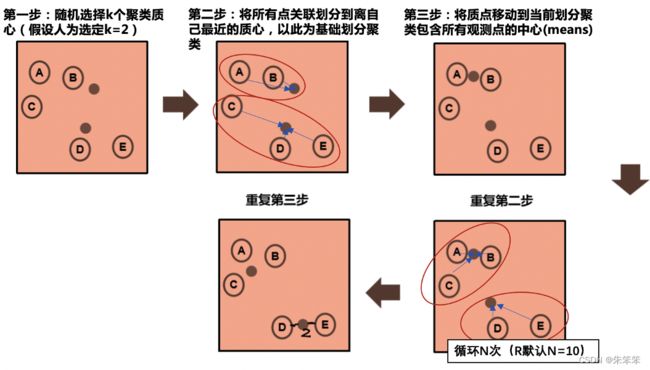
1.选择初始质心,最简单的方法就是从我们的数据集中选取K个样本作为初始质心。初始化完成后,K-Means聚类由2,3两个多次循环组成。
2.将样本分配给距离最近的质心。
3.将不同质心分配到底的样本求均值,从而创造新的质心。然后计算新老质心之间的差距。重复2,3直至质心偏移小于阈值或者质心不再移动。
3.2算法实战
实际上我们在实战的时候需要确定的参数只有k
这次我们采用的鸢尾花数据集,注意iris 这个数据集可以直接在scikit-learn这个库里面load。
然后我们需要导入的库有
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from mpl_toolkits import mplot3d
plt.rcParams['font.sans-serif'] = ['SimHei']接着我们要读取上面的csv数据然后做预处理,并且设置聚类器然后训练并将训练结果写入df对象中方便后续的可视化处理。
df = pd.read_csv("iris.csv") #作者的数据集和ipynb文件是放在同一目录下的所以可以直接写名字,路径因人而异
#读取数据 显示还是一列的哦
data1 = df["Sepal.Length"]
data2 = df["Sepal.Width"]
data3 = df["Petal.Length"]
#将数据变成list形式
data1 = np.array(data1)
data2 = np.array(data2)
data3 = np.array(data3)
#整理数据变为3维向量的形式便于我们传入
data = np.vstack((data1,data2,data3)).T
julei = KMeans(n_clusters=3)#创造聚类器这里我们选择k=3,因为根据肘方法我们找到的转折点是k=3
julei.fit(data)#fit一下
labels = julei.labels_#fit完后给的标签
labels
#写入df对象
df["label_pred"] = labels
接着我们便有了一个给了分类的df对象。

然后我们做数据可视化。根据label_pred的数值进行区分。
ax1 = plt.subplot(projection = "3d")
plt.style.use('ggplot')
for i in range(0,150):
if df["label_pred"][i]==0:
ax1.scatter(df["Sepal.Length"][i],df["Sepal.Width"][i],df["Petal.Length"][i],color = "green")
if df["label_pred"][i]==1:
ax1.scatter(df["Sepal.Length"][i],df["Sepal.Width"][i],df["Petal.Length"][i],color = "red")
if df["label_pred"][i]==2:
ax1.scatter(df["Sepal.Length"][i],df["Sepal.Width"][i],df["Petal.Length"][i],color = "yellow")
ax1.set_xlabel("Sepal.Length")
ax1.set_ylabel("Sepal.Width")
ax1.set_zlabel("Petal.Length")
plt.show() 接着出图!!!!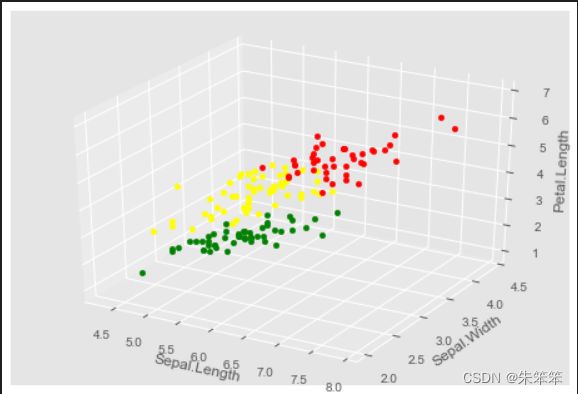
K-Means就这样被我们完成了,仔细看出的图,发现不同颜色的点聚类效果还不错。
这里有点要补充,估计很多小伙伴想问k是咋来的,其实这里我们要遍历k。
开头我们说过,先要确定一个K值,因此这里作者向大家介绍一个”肘方法“。原理呢是通过计算出不同K值下聚类结果类内误差平方和,然后根据其变化曲线分析K的取值,即利用肘方法确定K的合适值。而我们要做到就是遍历尽可能多的k看图像确定k。 代码如下:
#肘方法
kmax = 10
k = np.arange(1,kmax)
iner = []
for ii in k:
kmean = KMeans(n_clusters=ii,random_state=1)
kmean.fit(data)
iner.append(kmean.inertia_)
plt.figure(figsize=(10,6))
plt.plot(k,iner,"r-o")
plt.xlabel("聚类数目")
plt.ylabel("类内误差平方和")
plt.title("K_Means聚类")
##在图中添加一个箭头
plt.annotate("转折点",xy=(3,iner[2]),xytext=(4,iner[2]+100),arrowprops=dict(facecolor='blue',shrink=0.1))
plt.grid
plt.show()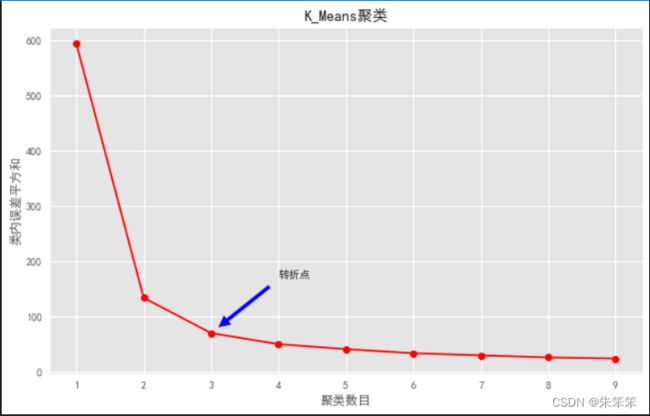
根据图片我们发现当k=3之后类内误差平方和变化非常平缓,说明K=3位较合理的取值,我叫他转折点。不过作者是写完了上面才意识到k值是需要确定的,当时随便填了个3,运气很好碰上转折点。属实有点小尴尬。各位可是要先确定k再往下做哦。
当然如果有未知标签的数据我们就可以放到这个训练好的模型里去让它帮我们聚类啦。K-Means就这样被我们学会啦,各位是不是感觉很轻松呢。
4.密度聚类DBSCAN
4.1算法介绍
DBSCAN是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类的方法不同。它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据中发现任意形状的聚类。DBSCAN的算法参数有两个一个是eps及半径,一个为min_point最小点数目。
首先要明确的概念:
核心点(Core)——该点eps圆范围内的点数大于min_point。
边界点(Border) ——该点表示在距离n处至少有一个核心。
噪声点(Noise) ——它既不是核心点也不是边界点。并且它在距离自身n的范围内有不到m个点。
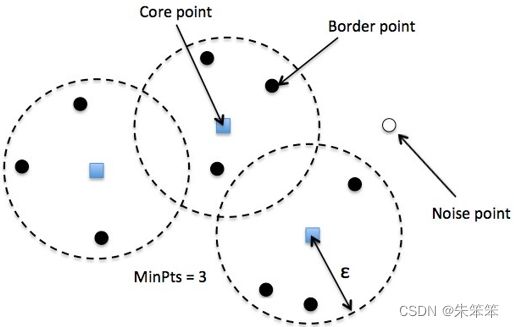
具体过程如下:
1.选取一个点,以eps为半径画一个圆,看圈内有几个临近点。如果大于min_point 则认为这是一个核心点。
2.将临近点作为核心点,放到一个集合中,然后遍历集合重复步骤1,如果该点被标为噪声点,则重标为核心点;如果没被标记过,也被标为核心点,并且以eps为半径的圆中点数大于min_point,则将这些点加入到核心点中。(这里有点绕,要读清楚哦!)
3.重复2直至完成一簇的所有点。
4.然后找到一个未被标记的点重复1,2,3再完成一簇,直至所有簇都完成。
4.2DBSCAN实战 (还是鸢尾花数据集不过是datasets里的)
#手头没数据了只能用鸢尾花数据集了
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.cluster import DBSCAN
iris = datasets.load_iris()#直接从datasets里面下载哦
X = iris.data[:,1:3] # 总共4个维度,试了2个维度的基本只能聚类成2类,不好意思xdm
dbscan = DBSCAN(eps=0.4, min_samples=8)#训练
dbscan.fit(X)
label_pred = dbscan.labels_
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == -1]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='噪声点')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show() 原来在上面已经说过了,但实际上作者在做到这里的时候效果并不是很好,只分成了两类,可能是鸢尾花数据集不太适合这个算法吧。
废话不多说出图
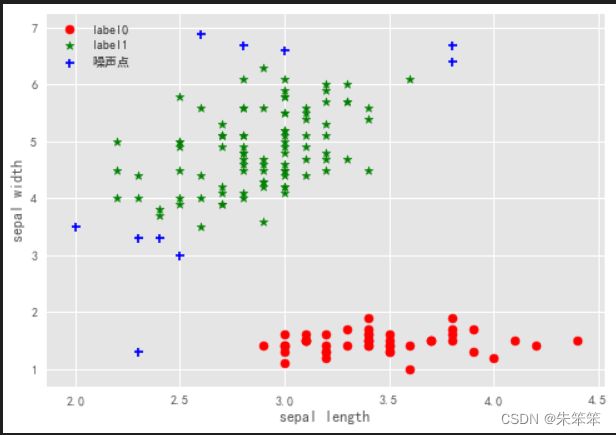
总的来说聚类还是比较简单的需要调整的参数还是比较少的,这里的eps和min_point同学们可能要多调整一下,或者写个程序遍历也行。
5.小结
今天coplilot不知道什么原因连不上了,今天的代码写的及其别扭。不过勉强帮大家梳理了DBSCAN和K-Means算法,作者也是第一次学呢。感觉机器学习还是很有意思的。而且有很多大牛帮我们写好了库,我们只用调用库调参放数据即可。如果各位读者有兴趣的话还可以看看谱聚类、模糊聚类、层次聚类。作者写作不易从下午3点肝到晚上9点希望各位能支持一下哦!以后我也会慢慢学习每一个模型给大家带来新的博客的。