GNN 图解未来: 揭秘图神经网络的无限可能
GNN 图解未来: 揭秘图神经网络的无限可能
- 概述
- 神经网络的发展 & 图数据的应用
- GNN 基础
-
- 图的基本结构
- 图的分类
-
- 无向图
- 有向图
- 加权图
- 非加权图
- 节点表示
- 邻接矩阵
- 聚合函数
- GNN 是如何工作的
-
- 消息传递机制
- 原始 GNN
- GCN
- GAT
- 信息传递的应用
- 代码实现
-
- Sage
概述
在当今快速发展的人工智能领域, 图神经网络 (Graph Neural Network, GNN) 是一个令人兴奋的热点. GNN 是一种专为处理图结构数据设计的神经网络, 能够捕捉负责数据之间的关系和模式. 不同于传统升级网络主要处理规则化的数据 (如图像和文本). GNN 专注于图像数据, 这种数据表示了许多显示世界的系统结构, 如社交网络, 粪污分子结构, 甚至交通网络. GNN 的核心优势在于能够利用节点之间的关系, 提取深层次的信息, 从而为各种复杂任务提供强大的预测和分析能力.
神经网络的发展 & 图数据的应用
神经网络 (Artificial Neural Network, ANN) 的概念早在上世纪就已经出现, 但直到近些年, 随着计算能力的大幅提升和大数据时代的到来. 这一概念才得到了广泛的应用和快速发展. 传统的神经网络: 如卷积神经网络 (CNN) 和循环神经网络 (RNN) 在图像识别, 语音处理等领域取得了巨大成功. 然而, 这些网络才处理图像数据时面临挑战, 因为他们的输入必须具有固定的形状和大小.
GNN (Graph Neural Network) 的出现, 为处理费欧几里得 (non–Euclidean) 数据, 图数据, 开辟了新的路径. 图数据的复杂性在于他们包含的节点和边的动态关系, 这些关系不能被传统神经网络有效捕捉. GNN 通过在图的节点 (Node) 间传递消息, 学习节点的表征 (Representation), 有效的解决了这一问题. GNN 不仅在理论上是一个重大图片, 在实际应用中也展现出来巨大的潜力, 如在药物发现, 欺诈检测, 只能推荐系统等领域的应用.
GNN 基础
图的基本结构
小白先带大家来了解一下图神经网络中的图 (Graph) 的概念. 图 (Graph) 是由节点 (Vertices) 和边 (Edges) 组层的数据结构, 用于表示事物之间的关系.节点 (Node) 通常代表实体, 而百年则表示这些实体之间的连接或关系.
举今年 CCF BDCI “基于书籍文本属性与链接关系的类别预测信息收集” 比赛的例子, 每个书籍的描述就是节点 (Node), 相关书籍的 Node Id 就是边 (Edges):
- Node: Description: Wanting to make a birthday cake, a youngster asks various animals to provide the ingredients, and they do . . . The soft watercolor illustrations are warm and gently humorous . . . A charming addition to preschool story times.School Library Journal; Title: It’s My Birthday
- Edges: [7443, 9866, 12078, 12378, 13024, 13468, 13521, 14695, 15205, 15841, 16722, 18956, 19205, 20815, 21500, 22031, 22284, 23822, 23946, 25754, 27481, 27491, 27501, 27530, 27536, 28952, 29293, 32828, 33246, 33340, 34003, 39727, 40295, 40718, 47738, 48028, 48346, 52737, 54480, 55346, 56405, 57710, 58097, 58458, 60747, 62435, 65020, 68169, 68189, 69421, 69437, 74057, 75638]
图的分类
图根据方向和权重两大类:
- 方向: 无向图 (Undirected Graph) 和有向图 (Directed Graph)
- 无向图 (Undirected Graph): 边没有方向
- 有向图 (Directed Graph): 边有明确方向
- 权重: 加权图 (Weighted Graph) 和 非加权图 (Unweighted Graph)
- 加权图 (Weighted Graph): 根据边加权
- 非加权图 (Unweighted Graph): 不根据边加权
无向图
无向图 (Undirected Graph) 其中的边 (Edge) 没有方向, 即图中的每一条百年都表示两个节点之间的双向关系. 在无向图中, 边是对称的, 即吐过节点 A 与节点 B 通过一条边相连, 那么节点 B 也与节点 A 通过一条边连接.
举个栗子:
- 社交网络: 在 Facebook 或 Instagram 等社交网络, 如果两个人是好友, A 是 B 的好友, B 也是 A 的好友, 这种关系是相互的. 在这种情况下, 无向图可以表示用户之间的好友关系
- 电力网络: 在电力分配系统中, 电力可以再两个连接点之间双向流动. 这种系统可以用无向图来表示, 其中节点代表分配电, 边代表电力线路
有向图
有向图 (Directed Graph) 中的边友明确的方向, 表示从一个节点 (Node) 到另一个节点的单向关系. 在有向图中, 如果节点 A 指向节点 B, 不意味着节点B 也只想节点 A.
举个栗子:
- 互联网: 互联网是一个巨大的有向图, 其中每个网页是一个节点, 每个超链接是一个指向另一个网页的有向边. 这种结构是谷歌等搜索引擎算法的基础
- 交通系统: 在城市的道路网络中, 某些接到可能是单向的. 这种情况下, 有向图可以用来表示街道 (Node) 和道路 (Edge) 之间的关系. 其中边的方向代表了可行驶的方向
加权图
权重 (Weight) 可以代表数据强度, 成本, 距离, 或其他任何量化的度量.
加权图的例子:
- 航线网络: 每个机场是一个节点 (Node), 每条航线是一个边 (Edge). 这个变可以被赋予一个权重, 比如航班的持续时间或距离
- 社交媒体影响力: 在社交媒体分析中, 节点可以是用户, 边可以代表用户键的关注关系, 权重可以表示影响力或交互频率
非加权图
- 族谱: 在族谱中, 每个成员都是一个节点 (Node), 而家族中的关系, 如父子, 姐妹等, 是边 (Edge). 族谱中的关系不涉及任何权重
- 课程: 在课程图中每个课程是一个节点 (Node), 如果某个课程是另一个课程的先修课程, 这两个课程之间机会存在一条边 (Edge)
节点表示
在 GNN 中, 节点 (Node) 表示是对途中每个节点特征或属性的数学表达. 这些表示可以是简单的, 手动编码的特征. 栗如 Facebook 中的年龄, 职业和兴趣爱好. 也可以是相对复杂, 通过深度学习模型得到的嵌入 (Embedding), 栗如 CCF BDCI “基于书籍文本属性与链接关系的类别预测信息收集” 比赛中的数据描述 (使用 Bert 进行嵌入). 折现嵌入是高纬空间中的向量, 能够捕捉节点之间的复杂关系和特性.
邻接矩阵
邻接矩阵 (Adjacency Matrix) 是一种表示图中所有节点连接的关系的矩阵. 在这个矩阵中. 行和列代表途中的节点, 而每个元素表示节点间是否存在边 (Edges). 如果节点 I 和 节点 J 之间友连接, 则矩阵的 (i, j) 位置被标记为 1 (或表示边的权重), 否则为 0. 这种表示方式为 GNN 提供了图结构的重要信息.
聚合函数
聚合函数 (Aggregation Functions) 用于更新节点 (Node) 的表示. 通过结合一个节点的特征与其邻居 (Neighbor) 的特征来实现. 在每个训练步骤中, GNN 将根据聚合函数手机和组合邻居节点的信息, 然后用这些聚合后的信息来更新当前节点的表示.
举个栗子: Facebook 中, 假设我们要预测一个用户的兴趣. 聚合函数可能会收集该用户朋友的兴趣, 然后将这些聚合后的信息与用户自己的特征结合, 以更好的预测用户的兴趣.
在 GNN 中, 选择合适的聚合函数对于有效的学习图结构和节点间的复杂关系至关重要. 常用的聚合函数包括求和, 平均和最大值, 每种方法都有其特定的应用场景和优势.
GNN 是如何工作的
GNN 的核心思想是通过一个可优化的转变过程在图结构 (Graph) 上进行高效的信息处理, 将图的属性向量转化为根据表现力的形式, 同时保持图的结构不变.
消息传递机制
GNN 中的消息传递机制可以简单理解为节点之间的信息交换过程. 在这个过程中, 每个节点收和汇总来自邻居节点 (Neighbor Node) 的信息, 然后更新自己的状态. 这个信息汇总和更新过程通过特定的函数来实现
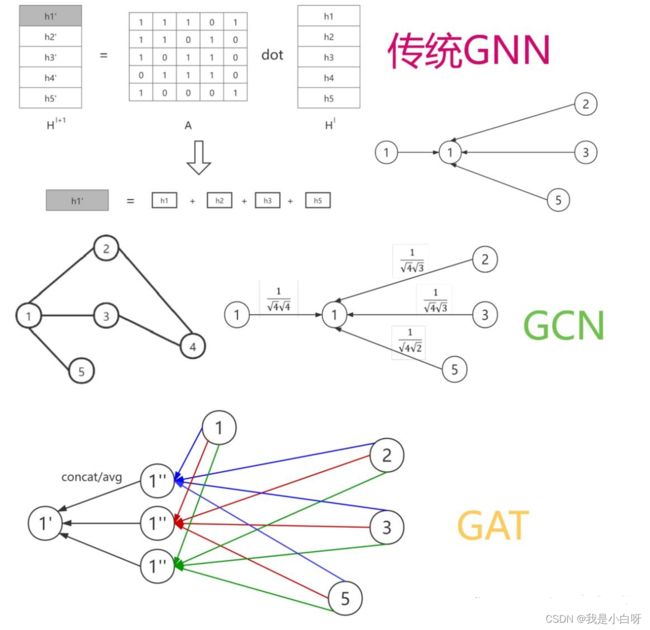
原始 GNN
最初的 GNN 使用的是简单的求和 (SUM) 传递机制, 即在模型中, 节点的状态是其所有邻居状态的简单求和.

GCN
GCN (Graph Convolutional Network), 图卷积网络, 引入了节点度 (Node Degree) 的概念. 在消息传递时考虑节点的连接数 (度). 在 GCN 中, 节点的更新不仅取决于邻居的状态, 还跟邻居的数量 (Node Degree) 有关. 这意味着, 如果一个节点有更多的邻居, 那么每个邻居的影响就会被相应地减少.

GAT
GAT (Graphic Attention Network), 图注意力网络, GAT 进一步发展了 GCN 的思想, 通过引入注意力机制来动态地分配不同邻居的重要性. 在 GAT 中, 不是所有邻居都被平等对待. 模型会学习分配不同的权重给不同的邻居, 这取决于邻居对当前节点的相对重要性.
信息传递的应用
在这些不同的消息传递机制下, GNN 能够有效地捕捉图节点间的复杂关系. 通过这种方式, GNN 可以用于多种任务, 如节点分类, 图分类, 链接预测等. 这些任务中, GNN 首先通过消息传递学习到图中节点的有效表示, 然后这些表示可以被用于后续的分类或回归任务.
代码实现
Sage
"""
@Module Name: sage.py
@Author: CSDN@我是小白呀
@Date: December 1, 2023
Description:
sage.py
"""
import pickle
import pandas as pd
import torch
import torch.nn.functional as F
from torch_geometric.data import Data, DataLoader
from torch_geometric.nn import SAGEConv
from tqdm import tqdm
# 超参数
EPOCHS = 500
BATCH_SIZE = 16
LEARNING_RATE = 1e-4 # 学习率
best_valid_loss = float('inf')
patience = 200 # 早停的耐心值
epochs_no_improve = 0 # 跟踪没有改善的 epoch 数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("是否使用 GPU 加速:", device)
def load_data():
# 加载数据
data = pickle.load(open('../../gnn_data/data.pkl', 'rb'))
X_text = data['X_text']
X_edges = data['X_edges']
y = data['y']
train = pd.read_csv('../../data/train.csv')
test = pd.read_csv('../../data/test.csv')
train_id = train['node_id'].tolist()
test_id = test['node_id'].tolist()
valid = pd.read_csv('../../gnn_data/valid.csv', sep='\t')
valid = valid.sort_values(by='node_id')
valid_id = valid['node_id'].tolist()
print('valid 长度:', len(valid_id))
# valid["label"] = pd.get_dummies(valid["label"]).to_numpy().tolist()
valid["label"] = pd.get_dummies(pd.Categorical(valid['label'], categories=list(range(24)) )).to_numpy().tolist()
valid_y = torch.tensor(valid['label'].tolist(), dtype=torch.long) # Convert to tensor
valid_y = valid_y.to(device)
return X_text, X_edges, y, train_id, test_id, valid_id, valid_y
X_text, X_edges, y, train_id, test_id, valid_id, valid_y = load_data()
# 读取处理好的 bert embeddings
def load_embeddings(embeddings_file):
if torch.cuda.is_available():
# 如果使用GPU,确保在加载时将数据放到GPU上
embeddings = torch.load(embeddings_file)
else:
# 如果只使用CPU
embeddings = torch.load(embeddings_file, map_location=torch.device('cpu'))
return embeddings
# 使用示例
embeddings_file = "../../gnn_data/embedding/bert_large_dual_embeddings_custom.pt" # 这是您保存嵌入的文件名
data_embeddings = load_embeddings(embeddings_file)
print(data_embeddings.size(1))
# 创建图数据
data = Data(x=data_embeddings, edge_index=torch.tensor(X_edges, dtype=torch.long).t().contiguous(), y=torch.tensor(y, dtype=torch.long))
train_mask = torch.zeros(data.num_nodes, dtype=torch.bool)
train_mask[train_id] = True # 前61500个节点用于训练
valid_mask = torch.zeros(data.num_nodes, dtype=torch.bool)
valid_mask[valid_id] = True # 500 个节点用于验证
test_mask = torch.zeros(data.num_nodes, dtype=torch.bool)
test_mask[test_id] = True # 后15375个节点用于测试
# DataLoader
data_loader = DataLoader([data], batch_size=BATCH_SIZE, shuffle=False)
class GraphSAGE(torch.nn.Module):
def __init__(self, hidden_channels, dropout_rate=0.5):
super(GraphSAGE, self).__init__()
self.conv1 = SAGEConv(2048, hidden_channels) # 第一层SAGE卷积
self.conv2 = SAGEConv(hidden_channels, 24) # 第二层SAGE卷积
self.dropout = dropout_rate
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=self.dropout, training=self.training) # 在第一层和第二层之间添加dropout
x = self.conv2(x, edge_index)
return x
model = GraphSAGE(hidden_channels=128)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 训练模型
def train(epoch):
model.train()
total_loss = 0
total_correct = 0
total_samples = 0
# 每10个epoch初始化tqdm进度条
if (epoch + 1) % 10 == 0:
progress_bar = tqdm(data_loader, desc=f"Epoch {epoch + 1}/{EPOCHS} [Training]")
else:
progress_bar = data_loader
for data in progress_bar:
data = data.to(device)
optimizer.zero_grad()
out = model(data.x, data.edge_index)
# print(data.y[train_mask].shape)
loss = F.cross_entropy(out[train_mask], data.y[train_mask].float())
loss.backward()
optimizer.step()
total_loss += loss.item()
# 计算准确率
pred = out.argmax(dim=1) # 将模型输出转换为类别索引
true_labels = data.y[train_mask].argmax(dim=1) # 将 one-hot 编码转换为类别索引
correct = (pred[train_mask] == true_labels).sum().item() # 比较预测和真实标签
total_correct += correct
total_samples += train_mask.sum().item()
# 每10个epoch更新进度条描述
if (epoch + 1) % 10 == 0:
# 更新进度条描述
accuracy = 100.0 * total_correct / total_samples
progress_bar.set_description(f"Training Epoch {epoch+1}, Loss: {total_loss:.4f}, Accuracy: {accuracy:.2f}%")
# return total_loss / len(data_loader)
# 预测
def evaluate(data):
global best_valid_loss, epochs_no_improve # 声明为全局变量
model.eval()
total_loss = 0
total_correct = 0
total_samples = 0
with torch.no_grad():
data = data.to(device)
out = model(data.x, data.edge_index)
loss = F.cross_entropy(out[valid_mask], valid_y.float())
total_loss += loss.item()
pred = out.argmax(dim=1)
true_labels = valid_y.argmax(dim=1) # 将 one-hot 编码转换为类别索引
correct = (pred[valid_mask] == true_labels).sum().item() # 比较预测和真实标签
total_correct += correct
total_samples += valid_mask.sum().item()
# print(total_loss)
accuracy = 100.0 * total_correct / total_samples
print(f"Evaluation - Loss: {total_loss / len(data_loader):.4f}, Accuracy: {accuracy:.2f}%")
if total_loss < best_valid_loss:
test_predict = predict_test(data, test_mask)
children = pd.read_csv('../../data/Children.csv')
test_nodes = children[children['label'].isna()]
submit = pd.DataFrame({'node_id':test_nodes['node_id'].tolist(), 'label':test_predict})
submit.to_csv('sage_large.csv', index=False)
# 保存模型
torch.save(model.state_dict(), 'sage_large_best.pth')
print(f'Epoch {epoch+1}: Validation loss improved from {best_valid_loss:.4f} to {total_loss:.4f}, saving model to sage_large_best.pth')
# 更新
best_valid_loss = total_loss
epochs_no_improve = 0 # 重置早停计数器
else:
epochs_no_improve += 10
return epochs_no_improve
def predict_test(data, mask):
model.eval()
predictions = []
with torch.no_grad():
data = data.to(device)
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
masked_pred = pred[mask] # 应用 mask
predictions.extend(masked_pred.cpu().numpy())
return predictions
for epoch in range(EPOCHS):
train_loss = train(epoch)
# print(f'Epoch {epoch}, Loss: {train_loss:.4f}')
if (epoch+1) % 10 == 0:
epochs_no_improve = evaluate(data)
# print(epochs_no_improve)
# 检查是否达到早停条件
if epochs_no_improve >= patience:
print(f'Early stopping triggered after {epoch+1} epochs')
break