JavaWeb(5)——XML & Tomcat
目录
前置工作
创建一个javaweb5的Moudle模块
XML
什么是 xml?
xml 语法
xml入门
创建一个xml文件,来描述图书信息
xml 注释
元素(标签)
xml 属性
xml语法规则
XML命名空间(名称空间)
(回顾)URI、URL、URN的区别
XML命名空间示例
xml 解析技术介绍
dom4j 解析技术(重点)
Dom4j 类库的目录认识
Dom4j 类库的使用
编辑
使用测试类前的前置工作
解析xml文件,转换成java的Document对象
遍历标签,获取所有标签中的内容(重点)
Tomcat
JavaWeb 的概念
什么是请求和响应及两者关系
Web 资源的分类
Web资源通讯的三大要素
WEB服务器概念
软件架构
常见WEB服务器
Tomcat 服务器和 Servlet 版本的对应关系
Tomcat 的使用
Tomcat安装流程
Tomcat启动常见错误
Tomcat目录结构
Tomcat目录下部署Web工程两种方法
(方法一)部署Web工程到Tomcat的webapps目录下
(方法二)编写配置文件,用户访问URL时地址会被改成磁盘地址
(补充)File协议、Tomcat的ROOT工程访问与默认index.html
在浏览器网址输入File协议
Tomcat的ROOT工程访问与默认index.html
IDEA 中动态 web 工程的操作
IDEA 整合 Tomcat 服务器
IDEA 中如何创建动态 web 工程
Web 工程的目录介绍
(重要)在IDEA中给动态 web 工程添加额外 jar 包到类库的清晰讲解
(补充)"指定这个类库的jar包要给哪个模块使用"中,Scope在何种情况下要设置为provided,以及和scope设置为compile的区别
(重要)在 IDEA 中部署web工程到 Tomcat 上运行的详细讲解
热部署说明
前置工作
创建一个javaweb5的Moudle模块
说明:用idea的该方法创建web更快捷高效
XML
什么是 xml?
- xml 是可扩展的标记性语言。
- xml 的主要作用有:
- 用来保存少量数据,而且这些数据具有自我描述性(可以自定义标签,没有像HTML一样有严格限制)
- 它还可以做为项目(Maven项目描述项目的Pom.xml)或者模块的配置文件(springMVC.xml)
- 还可以做为网络传输数据的格式(但现在 JSON 为主)。
xml 语法
- 文档声明
- 元素(标签)
- xml 属性
- xml 注释
- 文本区域(CDATA 区)
xml入门
说明:通过案例认识XML语法
创建一个xml文件,来描述图书信息
java编程思想
华仔
9.9
葵花宝典
班长
5.5
浏览器也可以打开xml文件

xml 注释
- html 和 XML 注释 一样 :

元素(标签)
- XML元素是指从便签开始到标签结束的部分
- 元素可以包含其他元素、文本、及元素文本混合物。
- 元素可以拥有属性
- 格式:
- 单标签:<标签名 属性=”值” 属性=”值” ...... />
例如: - 双标签:< 标签名 属性=”值” 属性=”值” ......>文本数据或子标签标签名>
例如:java编程思想
- 单标签:<标签名 属性=”值” 属性=”值” ...... />
- 元素命名规则:
- 名称可以含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不建议以字符 “xml”(或者 XML、Xml)开始 (它是可以的)
- 名称不能包含空格,有空格就是属性了

xml 属性
-
xml 的标签属性和 html 的标签属性是非常类似的,属性通常提供不属于数据组成部分的信息,但是 属性可以提供元素的额外信息
-
用法:在标签上可以书写属性:
-
一个标签上可以书写多个属性。 每个属性的值必须使用 “引号” 引起来(id属性也不例外),属性值与属性值用“逗号”隔开,属性与属性之间用空格隔开。 书写的规则 和标签的书写规则一致。
-
xml语法规则
- 所有 XML 元素都须有关闭标签(也就是闭合)
-
XML 标签对大小写敏感,但是HTML却不会对大小写敏感
-
XML 必须正确地嵌套
-
XML 文档必须有根元素
-
根元素就是顶级元素,
-
没有父标签的元素,叫顶级元素。
- 根元素是没有父标签的顶级元素,而且是唯一一个才行。

-
-
XML 的属性值须加引号(强调)
-
XML 中的特殊字符
-
> ==> >
-
< ==> <
-
-
文本区域(CDATA 区)
-
CDATA 语法可以告诉 xml 解析器,我 CDATA 里的文本内容,只是纯文本,不需要 xml 语法解析
-
CDATA 格式:
-
XML命名空间(名称空间)
-
在HTML同理(可以看完下面在做参考)
测试文件上传和下载 下载1.jpg -
认识结构(参考下面的xml代码),其中:
beans是该xml文件的根元素、也因为声明了命名空间变成了一个包容体、xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 是其中一个显性命名空间声明、xsi是前缀名、
"http://www.w3.org/2001/XMLSchema-instance"是一个"某个URI"、xmlns="http://www.springframework.org/schema/beans"是一个默认命名空间(他没有前缀名和冒号)、 -
XML命名空间的作用就是为了解决XML词汇的同名冲突和区分识别,值得注意的是:名称空间只存在逻辑意义,无法真正实现对URI的引用
-
命名空间一般声明在根元素(例如
、 等),命名空间声明将名称前缀和URI关联起来,被声明命名空间的元素被称为包容体(Container)。命名空间和前缀关系的关联关系在包容体的范围内有效 -
命名空间声明的两种方式(隐形和显性):
-
显式名称空间声明:xmlns : 前缀名A = "某个URI"
声明命名空间的包容体里的元素使用时:<前缀名A:子元素 属性a="???"> -
默认名称空间声明:xmlns = "某个UI" (他没有前缀名)
声明命名空间的包容体里的元素使用时:<子元素 属性a="???">
- 命名空间声明注意事项:
- 声明的双引号里面必须是一个URI(忘记URL和URI区别可以参考这篇文章),确保唯一性
- XML严格区分大小写,这点要和HTML区分,前缀名也不例外。
- 前缀名尽量采用英文缩写并且不推荐使用中文
- 尽量避免同名前缀而不同URI,因为容易误导用户
- 尽量只在根元素声明默认名称空间。若默认名称空间声明在非根元素,则容易被用户误解或忽略成没有名称空间的元素。所以,非根元素尽量不使用默认名称空间声明(推荐使用显式名称空间声明)
(回顾)URI、URL、URN的区别
- URI——统一资源标识符,却没有说明自己是怎么标识的。因此可以把它看做是一个大的集合,根据特定的标识方式给他划分不同的子集,既有根据定位方式标识的URL——统一资源定位符,又有根据命名方式标识的URN——统一资源命名。
- URL:根据定位方式,URL是URI最主要的体现方式,例如“http://www.aaa.com/images/cat.jpg”来找到指定主机里面的指定图片。通过案例发现URL和资源关系十分密切,如果双方一有变化就会导致双方失联
- URN:通过命名方式,例如使用一个独一无二的字符串“sdaklflsdf”来表示独一无二的“cat.jpg”图片文件,但是前提是要有一个解析器来解析这个字符串指向哪一个资源及该资源最新的位置是什么。但这个工作量非常巨大,看似十分完美,实际成本很高。因此这就是URL是URI最主要的体现方式的原因,也可以看做URI≈URL
- 用生活例子举例:我在购物商城下单选择地址时,如果使用URL,就需要我手动操作来选择具体的快递驿站或者丰巢柜作为收件地址。而URN则会解析我手机的定位系统,然后自动帮我选择我就近的快递驿站或者丰巢柜作为收件地址
XML命名空间示例
- A部门用得XML文件
<资料> <设备 编号="联想6515b"> <生产商>联想集团 <地址>北京市中关村127号 - B部门使用的XML文件
<资料> <设备 编号="中联F001"> <生产商>中联重科 <地址>湖南省长沙市新开铺113号 - 整合A、B部门使用的XML文件
<资料 xmlns:IT="http://www.lenovo.com" xmlns:建筑="myURN:中联"> <设备 IT:编号="联想6515b" 建筑:编号="中联F001">
xml 解析技术介绍
- xml 可扩展的标记语言。不管是 html 文件还是 xml 文件它们都是标记型文档,都可以使用 w3c 组织制定的 dom 技术来解析。因此document 对象表示的是整个文档(可以是 html 文档,也可以是 xml 文档)。参考下图结构

- 早期 JDK 为我们提供了两种 xml 解析技术 DOM 和 Sax 简介(已经过时,但我们需要知道这两种技术)
- dom 解析技术:是 W3C 组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。 Java 对 dom 技术解析标记也做了实现。
- sun公司解析技术:sun 公司在 JDK5 版本对 dom 解析技术进行升级:SAX( Simple API for XML ) SAX 解析,它跟 W3C 制定的解析不太一样。它是以类似事件机制通过回调告诉用户当前正在解析的内容。 它是一行一行的读取 xml 文件进行解析的。不会创建大量的 dom 对象。 所以它在解析 xml 的时候,在内存的使用上。和性能上。都优于 Dom 解析。
- 第三方解析:
- jdom 在 dom 基础上进行了封装
- dom4j 又对 jdom 进行了封装。这个 Dom4j 它是第三方的解析技术。我们需要使用第三方给我们提供好的类库才可以解析 xml 文件。
- pull 主要用在 Android 手机开发,是在跟 sax 非常类似都是事件机制解析 xml 文件。
dom4j 解析技术(重点)
- 由于 dom4j 它不是 sun 公司的技术,而属于第三方公司的技术,我们需要使用 dom4j 就需要到 dom4j 官网下载 dom4j 的 jar 包
- 这里有下好的dom4j-1.6.1.zip:https://download.csdn.net/download/zjr_java/86401024
Dom4j 类库的目录认识
dom4j 第三方类库学习文档doc

dom4j 第三方类库lib目录
- lib目录下是使用dom4j需要依赖的其他第三方库
dom4j 第三方类库src目录
- src 是第三方类库的源码目录
Dom4j 类库的使用
目的:解析xml文件,转换成java的Document对象进行操作
步骤:
- 先加载 xml 文件创建 Document 对象
- 通过 Document 对象拿到根元素对象
- 通过根元素.elelemts(标签名); 可以返回一个集合,这个集合里放着。所有你指定的标签名的元素对象
- 找到你想要修改、删除的子元素,进行相应在的操作
- 保存到硬盘上
在dom4j 第三方类库获取jar包,并拷贝到lib目录下

将jar包添加到自定义的名为"dom4j.1.6.1"类库中
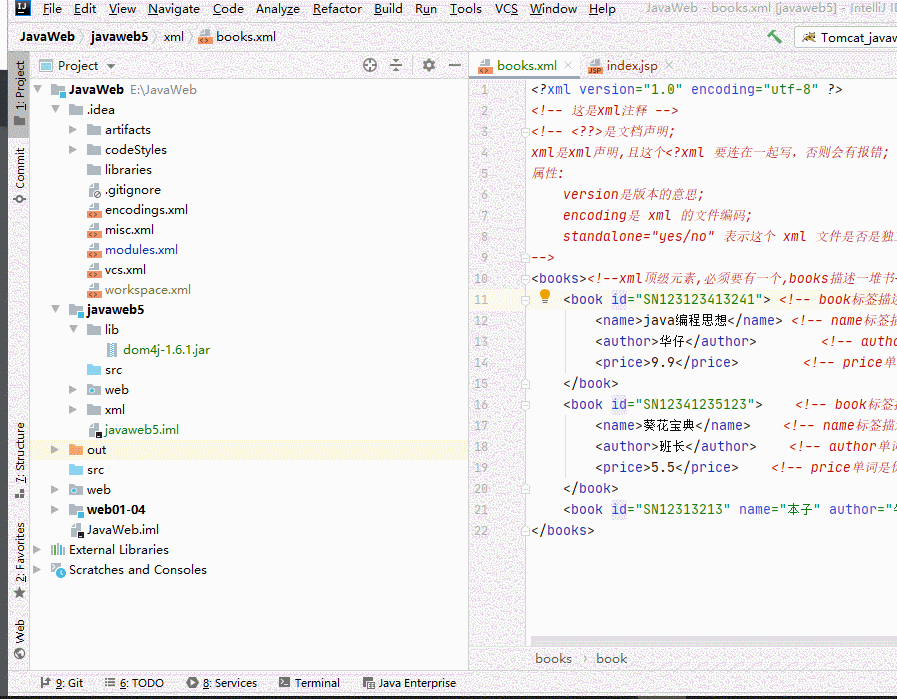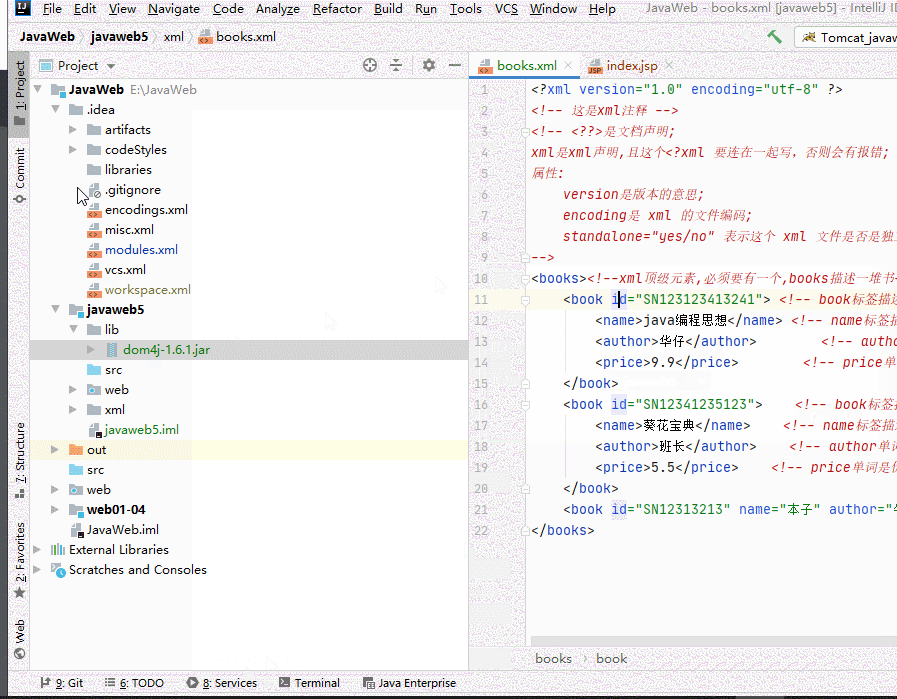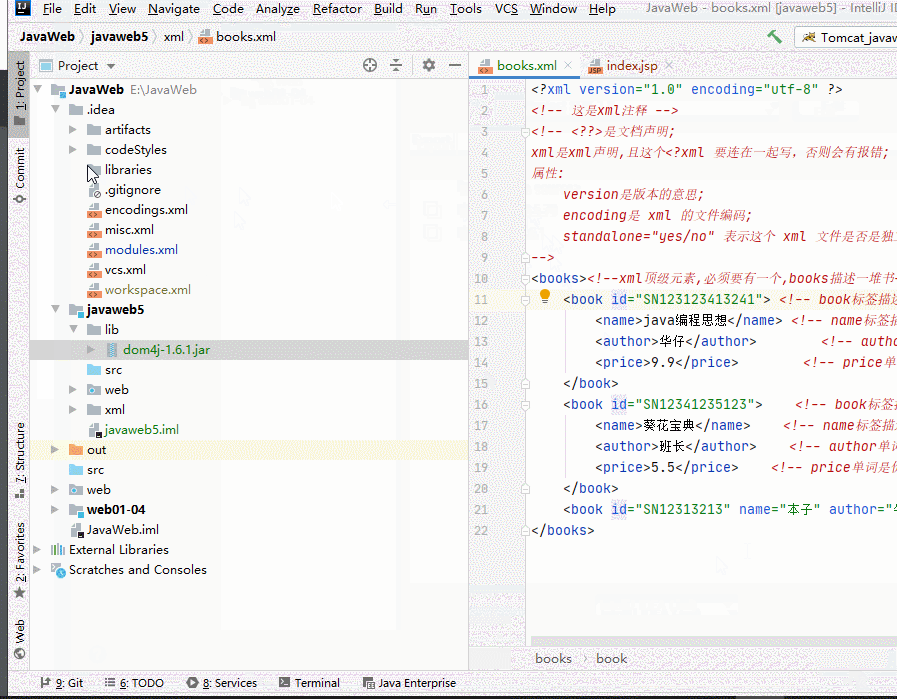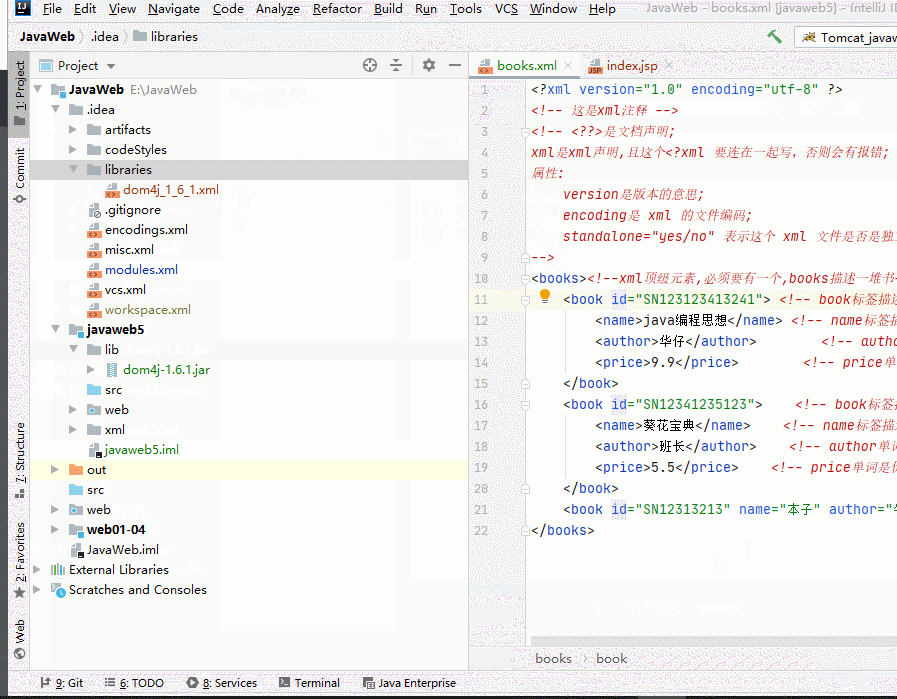
使用测试类前的前置工作
http://t.csdn.cn/ONPJ2
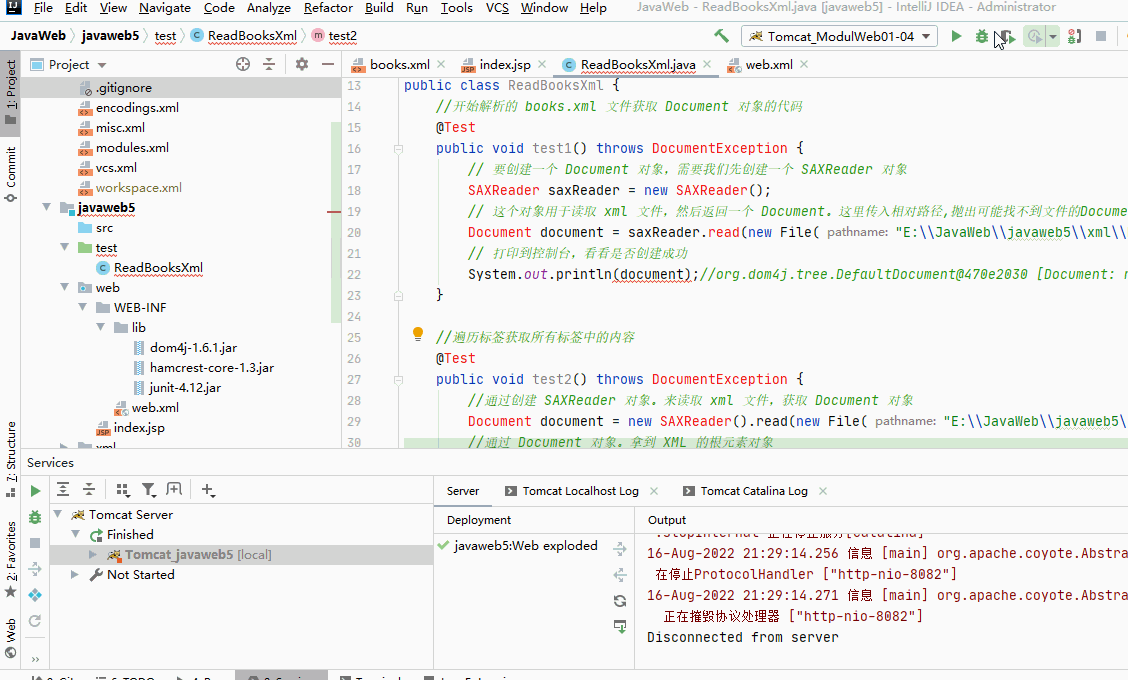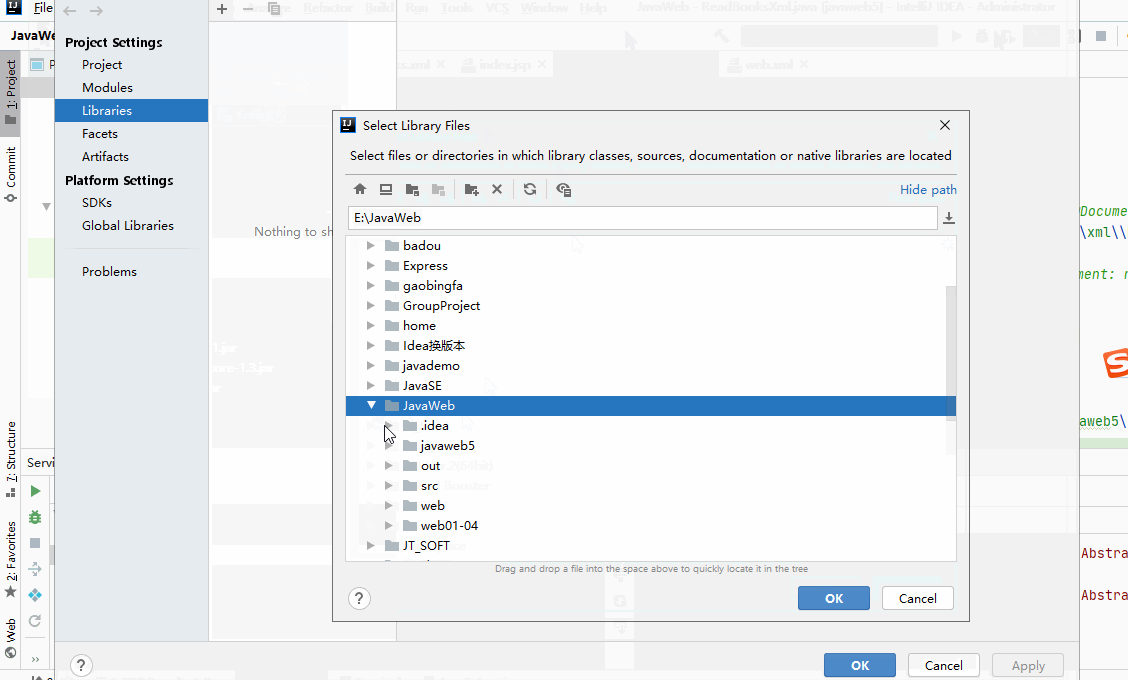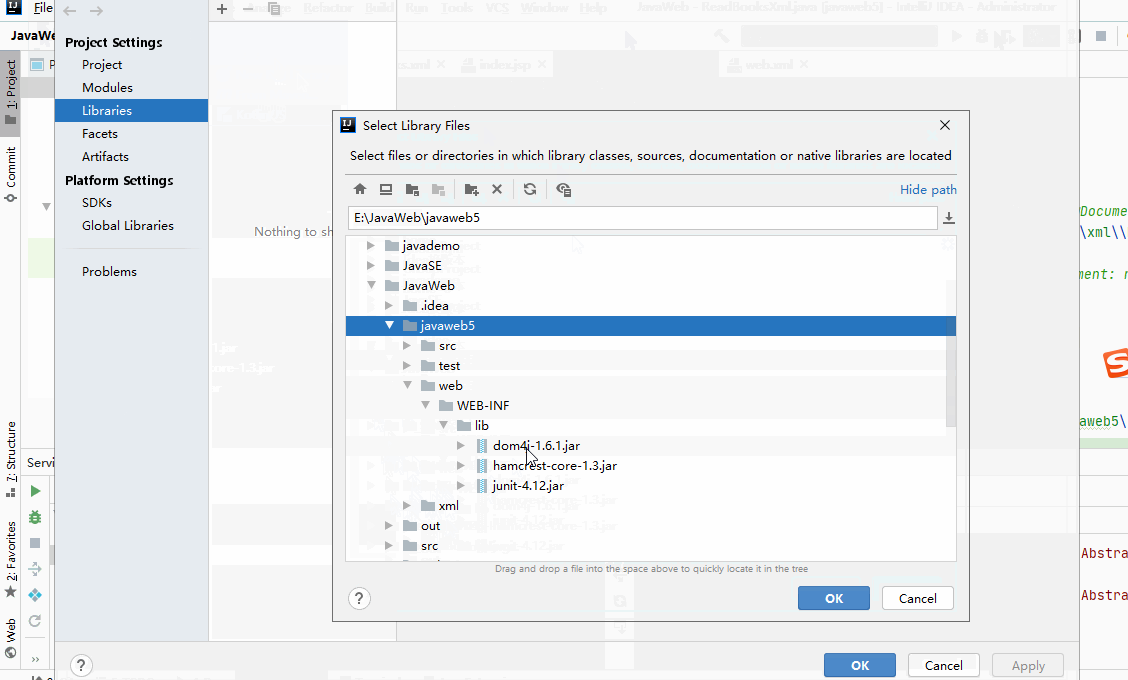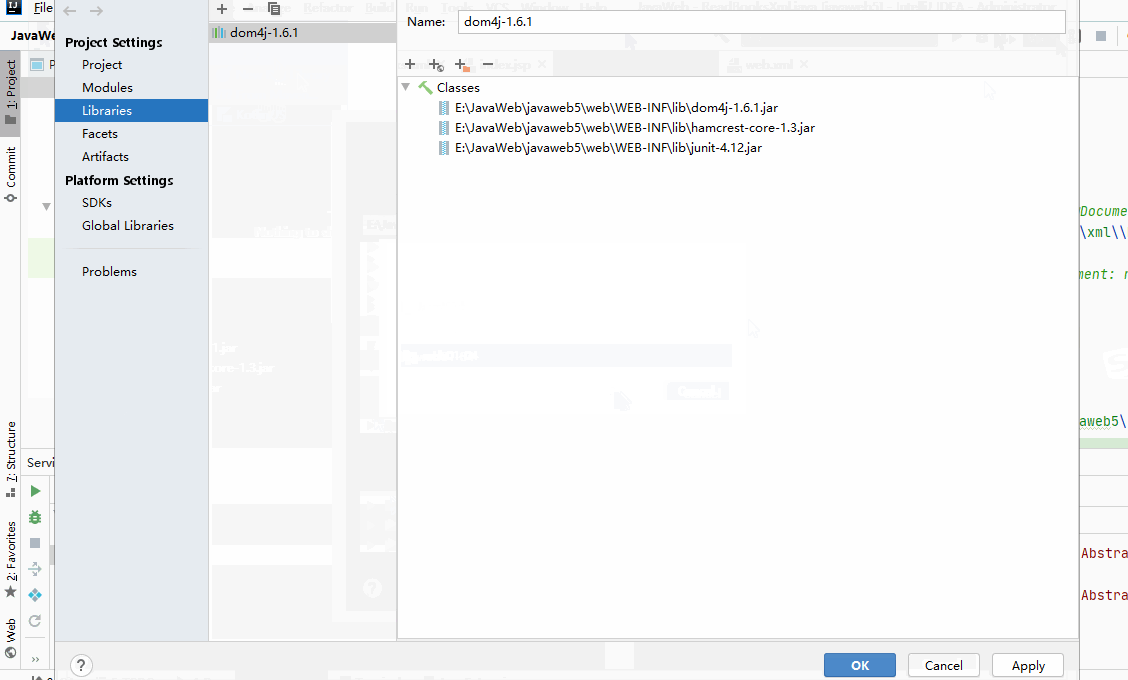
解析xml文件,转换成java的Document对象
开始解析的 books.xml 文件获取 Document 对象的代码
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.File;
/**本类是用dom4j获解析的 books.xml 文件获取 Document 对象的代码*/
public class ReadBooksXml {
@Test
public void test1() throws DocumentException {
// 要创建一个 Document 对象,需要我们先创建一个 SAXReader 对象
SAXReader saxReader = new SAXReader();
// 这个对象用于读取 xml 文件,然后返回一个 Document。这里传入相对路径,抛出可能找不到文件的DocumentException异常
Document document = saxReader.read(new File("E:\\JavaWeb\\javaweb5\\xml\\books.xml"));
// 打印到控制台,看看是否创建成功
System.out.println(document);//org.dom4j.tree.DefaultDocument@470e2030 [Document: name file:///E:/JavaWeb/javaweb5/xml/books.xml]
}
}
遍历标签,获取所有标签中的内容(重点)
步骤:
- 通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象(上面演示过了)
- 通过 Document 对象。拿到 XML 的根元素对象 第三步,通过根元素对象。获取所有的 book 标签对象
- 遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,再通过 getText() 方法拿到起始标签和结束标签之间的文本内容
代码演示
//遍历标签获取所有标签中的内容
@Test
public void test2() throws DocumentException {
//通过创建 SAXReader 对象。来读取 xml 文件,获取 Document 对象
Document document = new SAXReader().read(new File("E:\\JavaWeb\\javaweb5\\xml\\books.xml"));
//通过 Document 对象。拿到 XML 的根元素对象
Element rootElement = document.getRootElement();
System.out.println(rootElement.asXML());//public abstract String asXML()将当前元素转换成为 String 对象
System.out.println("------------------------------------");
/*
java编程思想
华仔
9.9
葵花宝典
班长
5.5
*/
//通过根元素对象。获取所有的 book 标签对象
List books = rootElement.elements("book");//Element.elements(标签名)它可以拿到当前元素下的指定的子元素的集合
//遍历每个 book 标签对象。然后获取到 book 标签对象内的每一个元素,
//方法1:
for(Element book : books) {
System.out.println(book.asXML());
}
System.out.println("------------------------------------");
/*
java编程思想
华仔
9.9
葵花宝典
班长
5.5
Tomcat
JavaWeb 的概念
- JavaWeb 是指,所有通过 Java 语言编写可以通过浏览器访问的程序的总称,叫 JavaWeb。
- JavaWeb 是基于请求和响应来开发的。
什么是请求和响应及两者关系
- 请求是指客户端给服务器发送数据,叫请求 Request。
- 响应是指服务器给客户端回传数据,叫响应 Response。
- 请求和响应是成对出现的,有请求就有响应
- 前置回顾:我们之前在HTML中的表单就发送过请求action,但是再JS代码中都设置了return阻止了默认行为,也就是向指定地址发送请求,等待发送地址的响应。
Web 资源的分类
- 静态资源:所有用户访问后,得到的结果都是一样的,称之为静态资源。只要静态资源才能被服务器解析
- 如:html、css、js、jpg......
- 动态资源:用户访问相同的资源得到的结果是不一样的,称之为动态资源。动态资源被访问后先转换成静态资源,然后再返回给浏览器解析。
- 如:serverlet/jsp、php、asp......
Web资源通讯的三大要素
- ip:127.0.0.1
- 端口:8080
- 协议:TCP(三次握手四次挥手)、UDP(客户端只管发不管服务端是否接收)
结构:
- URL:
-
在互联网中每个资源(html、css、js、img、png、video)都有一个唯一地址去标识该资源。
-
在互联网中每个资源(html、css、js、img、png、video)都有一个唯一地址去标识该资源。
-
URL全称Uniform Resource Locator(统一资源定位符)
-
协议://主机名:端口号/资源地址#片段名?参数列表
-
-
HTTP:
-
HTTP全称 Hypertext Transefer Protocol 超文本传输协议。
-
浏览器和服务器之间进行数据交互的协议。
-
详细可查看:
http://t.csdn.cn/feleF
http://t.csdn.cn/Ew3zs
WEB服务器概念
- 安装了服务器软件的计算机
- 服务器软件可以接收用户的请求,处理请求,做出响应
- web软件服务器也可以接收用户的请求,处理请求,做出响应。并且web服务器软件中,可以部署web项目,用户通过浏览器可以访问这些项目
软件架构
- C/S:客户端和服务端 例如:QQ、360......
- B/S:浏览器和服务端 例如:京东商城、新浪微博
常见WEB服务器
- Tomcat:由 Apache 组织提供的一种 Web 服务器,提供对 jsp 和 Servlet 的支持。它是一种轻量级的 javaWeb 容器(服务器),也是当前应用最广的 JavaWeb 服务器(免费)。
- Jboss:是一个遵从 JavaEE 规范的、开放源代码的、纯 Java 的 EJB 服务器,它支持所有的 JavaEE 规范(免费)。
- GlassFish: 由 Oracle 公司开发的一款 JavaWeb 服务器,是一款强健的商业服务器,达到产品级质量(应用很少)。
- Resin:是 CAUCHO 公司的产品,是一个非常流行的服务器,对 servlet 和 JSP 提供了良好的支持, 性能也比较优良,resin 自身采用 JAVA 语言开发(收费,应用比较多)。
- WebLogic:是 Oracle 公司的产品,是目前应用最广泛的 Web 服务器,支持 JavaEE 规范, 而且不断的完善以适应新的开发要求,适合大型项目(收费,用的不多,适合大公司)。
Tomcat 服务器和 Servlet 版本的对应关系

- 当前企业常用的版本 7.*、8.*
- Servlet 程序从 2.5 版本是现在世面使用最多的版本(xml 配置)
到了 Servlet3.0 之后。就是注解版本的 Servlet 使用。 - 以 2.5 版本为主线讲解 Servlet 程序。
Tomcat 的使用
Tomcat安装流程
- 前提是安装好JDK,因为jsp转换成servlet后需要编译,所以需要jdk
- 当有请求时,tomcat会自动将jsp里面的java程序部分提取出来,调用jdk将java程序编译成class,然后再执行这个class.你可以到tomcat的work目录下看看,你可以找到从jsp里面提取出来的java程序, ***_jsp.java,也有编译后的class文件, ***_jsp.class。
所以,如果不装JDK,jsp程序就无法编译。 - 但Tomcat 6.0以后已经不需要jdk了
-
Tomcat 5.5及以前的版本,我们都必须安装JDK,因为Tomcat Jasper需要使用JDK去编译jsp(翻译后的java文件),Tomcat 6的jasper在新的版本已经做了重新的设计。
-
以下是tomcat 6官方文档的一句话:
Tomcat 6.0 uses the Eclipse JDT Java compiler for compiling JSP pages. This means you no longer need to have the complete Java Development Kit (JDK) to run Tomcat, but a Java Runtime Environment (JRE) is sufficient. The Eclipse JDT Java compiler is bundled with the binary Tomcat distributions. Tomcat can also be configured to use the compiler from the JDK to compile JSPs, or any other Java compiler supported
by Apache Ant. -
也就是说,以后在生产机上安装tomcat的时候,不再需要去安装一个JDK了,只需要安装一个JRE就可以!原来的tomcat 5.0跟tomcat 5.5都需要JDK的支持!
-

- 当有请求时,tomcat会自动将jsp里面的java程序部分提取出来,调用jdk将java程序编译成class,然后再执行这个class.你可以到tomcat的work目录下看看,你可以找到从jsp里面提取出来的java程序, ***_jsp.java,也有编译后的class文件, ***_jsp.class。
-
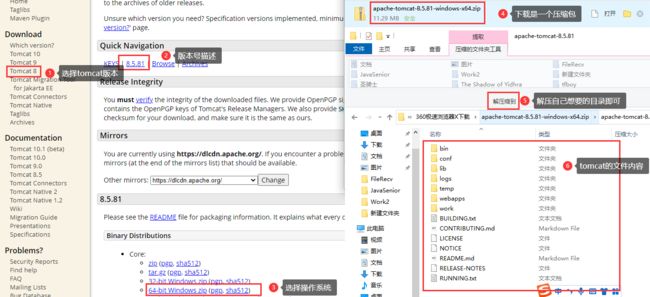
Tomcat服务器下载、安装、配置环境变量教程
-
进入Apache Tomcat® - Welcome!选择合适的版本下载
-
启动Tomcat中文乱码修复
-
找到Tomcat安装目录下的
conf文件夹的logging.properties文件,用记事本打开它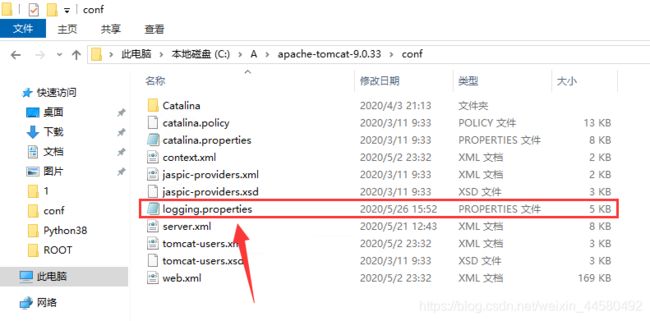
-
将
UTF-8编码方式修改为GBK编码,并保存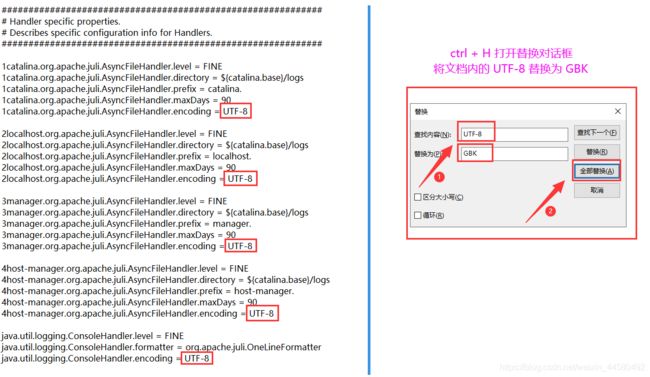
-
-
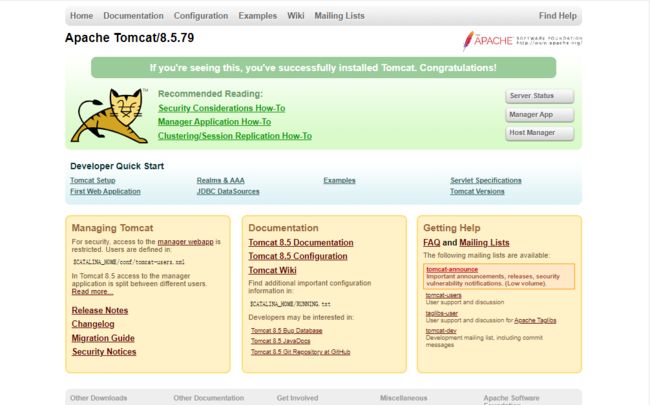
打开bin目录,找到startup.bat双击运行就可以了,不要关闭命令提示符窗口


-
浏览器输入http://localhost:8080,出现该页面就是成功tomcatWeb服务器启动成功
-
打开bin目录,找到startdown.bat双击运行就可以停止tomcat服务器
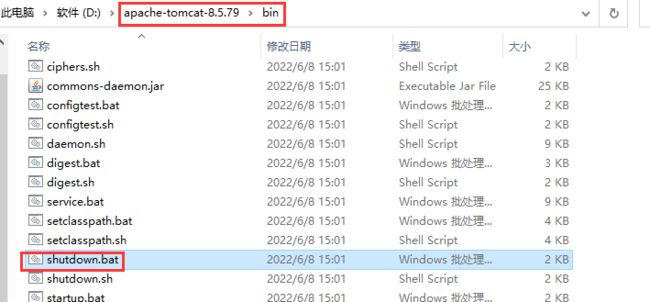
-
Tomcat启动常见错误
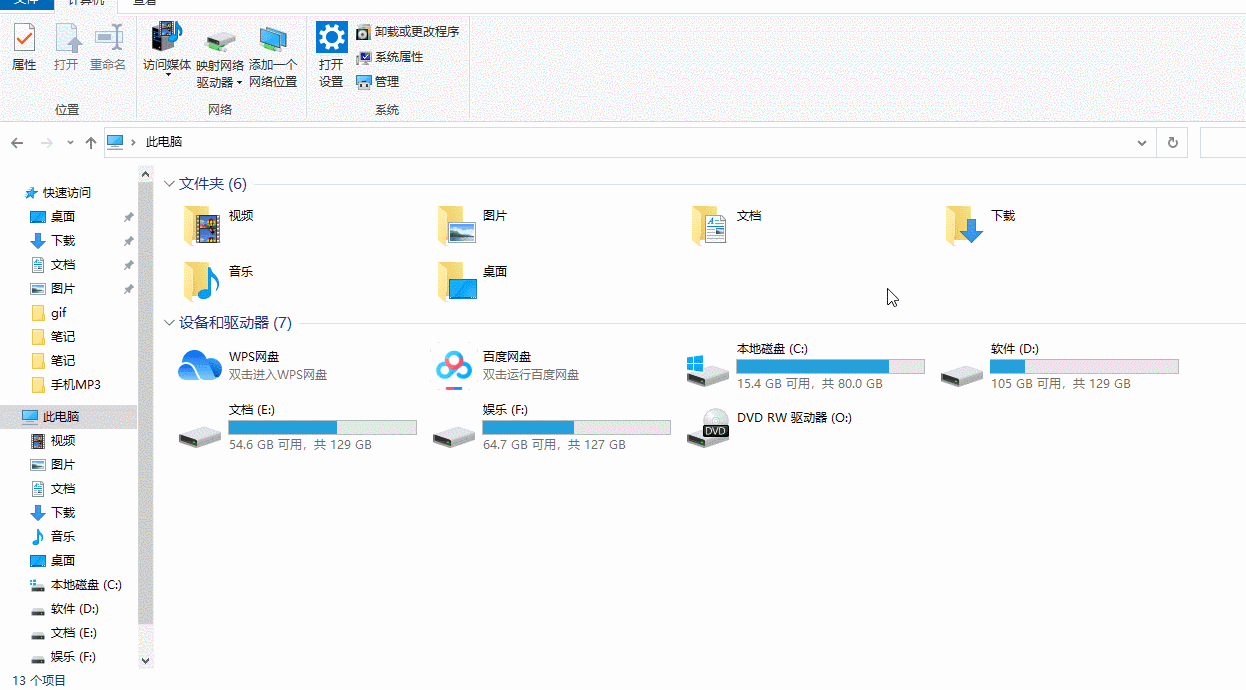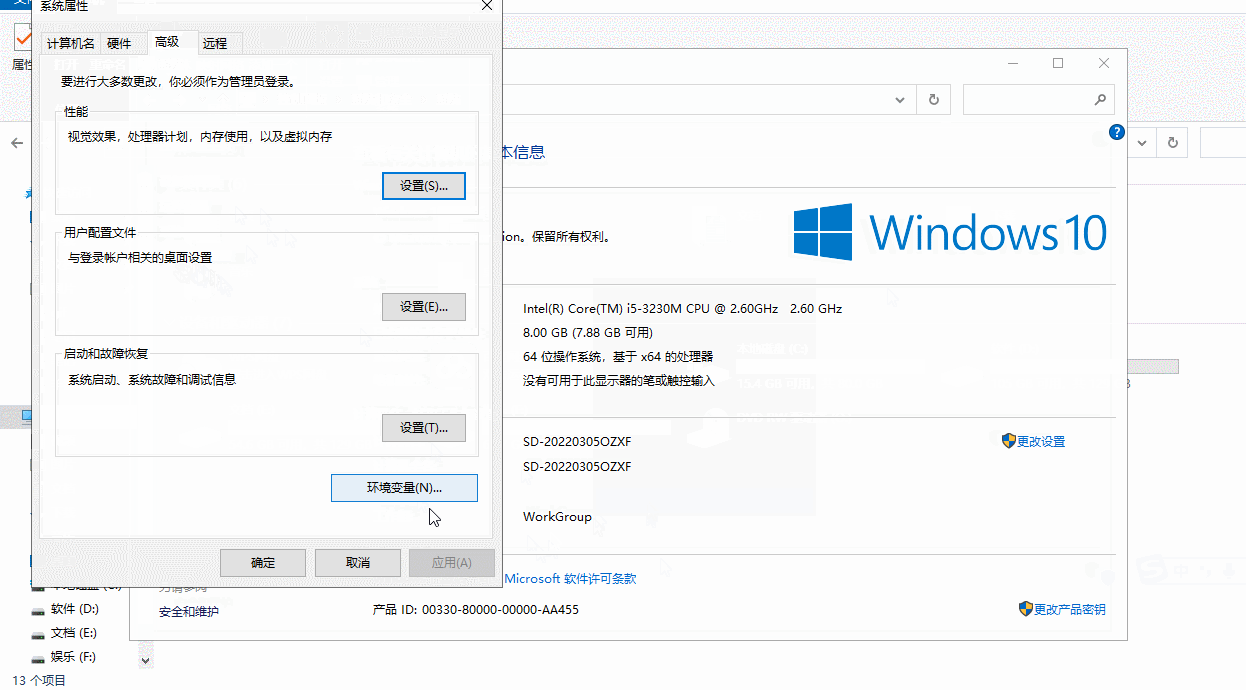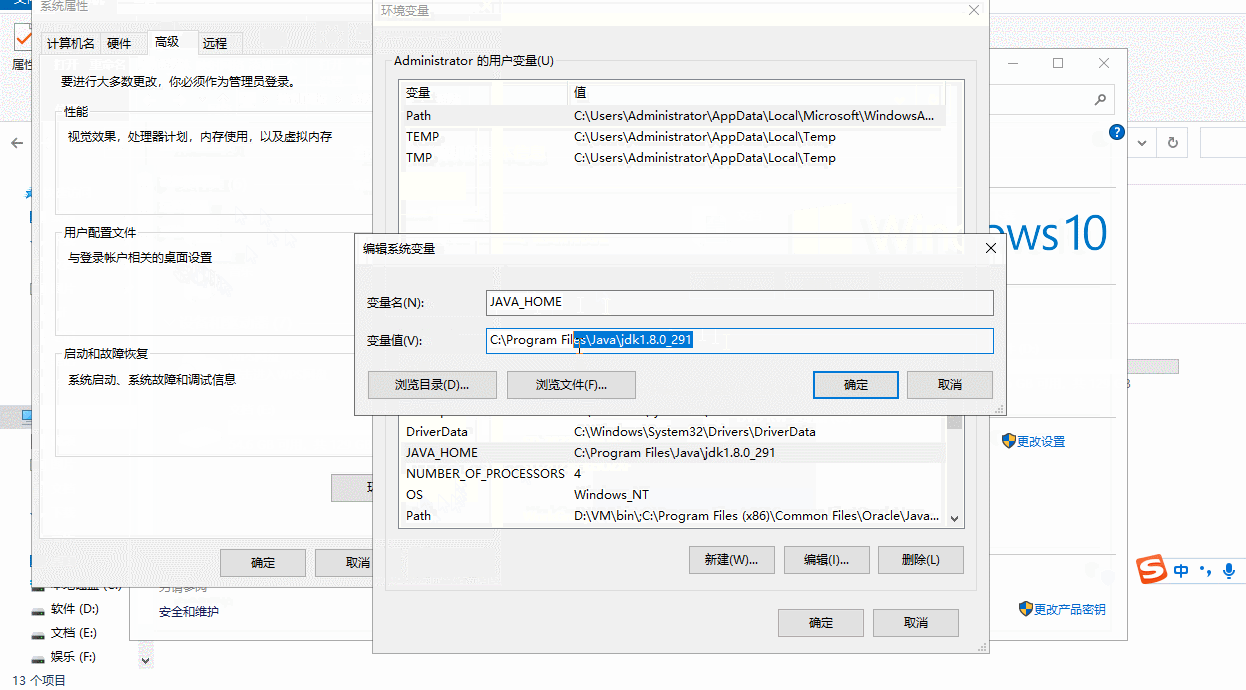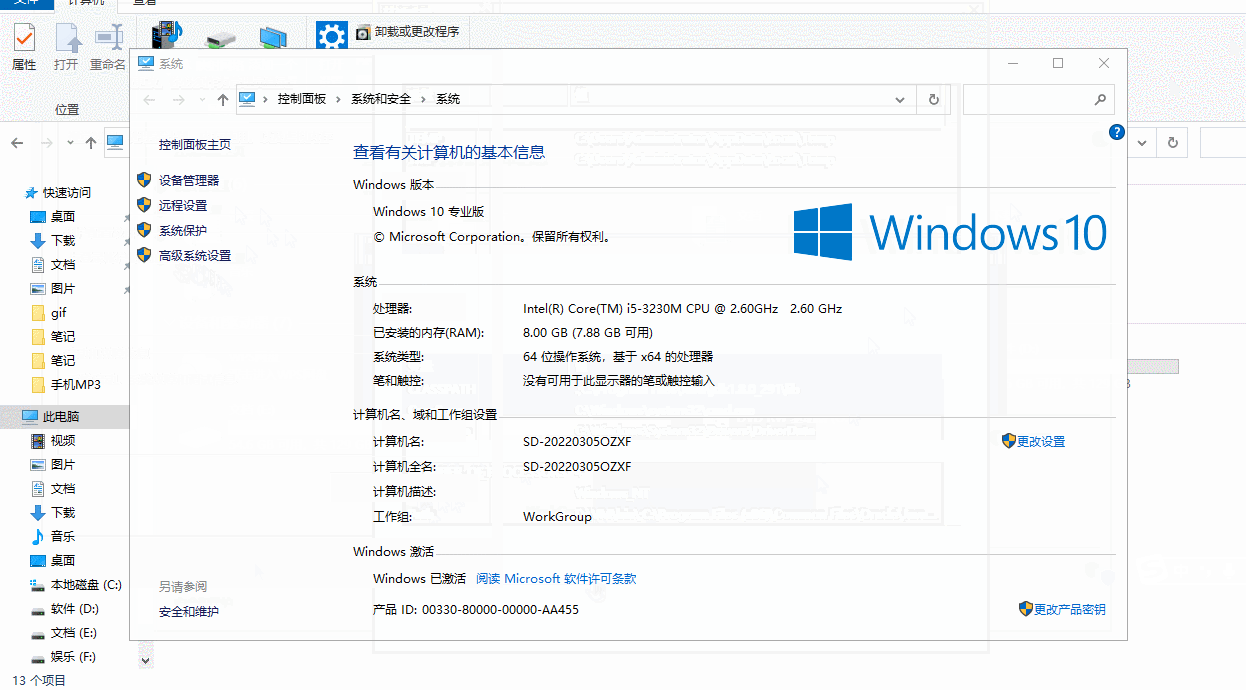
- 配置 JAVA_HOME 环境变量错误
- 问题:这种启动失败的现象是双击 startup.bat 文件,就会出现一个小黑窗口一闪而来
- 方法:正确匹配JAVA_HOME到JDK目录
- Tomcat 的意外停止
- 一旦关闭了小黑窗口Tomcat服务器就会被关闭

- 如果Tomcat被选中服务器并不会停止
- 如果在Tomcat启动命令提示符下按了 Ctr+c 就会关闭服务器

- 一旦关闭了小黑窗口Tomcat服务器就会被关闭
- Tomcat 因为端口冲突启动失败
- 原因:别的程序(最有可能就是java程序)在占用默认8080端口
- 解决方法:
- 点击startup.bat后去logs目录下最近的查看日志是否是端口被其他程序占用
- 发现端口占用,修改Tomcat默认占用的8080端口,然后重启Tomcat服务器(补充:Mysql 默认的端口号是:3306;HTTP 协议默认的端口号是:80,例如我这里的百度就是183.232.231.172:80)
Tomcat目录结构

具体描述:

Tomcat目录下部署Web工程两种方法
(方法一)部署Web工程到Tomcat的webapps目录下
- 使用书城第一阶段内容拷贝到webapps\bookshop目录下
webapps是存放各种web项目,bookshop为其中一个web项目 - 访问 Tomcat 下的 web 工程
只需要在浏览器中输入访问地址格式如下: http://ip:port/工程名/目录下/文件名
(方法二)编写配置文件,用户访问URL时地址会被改成磁盘地址
- 类似以后要说的网关Gateway
- 找到 Tomcat 下的 conf 目录\Catalina\localhost\ 下,创建如下的配置文件(已经创建)
- abc.xml 配置文件内容如下(已经提前写好):
- 重启Tomcat服务器(已经重启)
- 在浏览器输入URL访问资源(已经输入好)
- 原理流程图

- GIF演示
(补充)File协议、Tomcat的ROOT工程访问与默认index.html
在浏览器网址输入File协议
案例:浏览器访问 file:///E:/JavaWeb/web01-04/web/index.html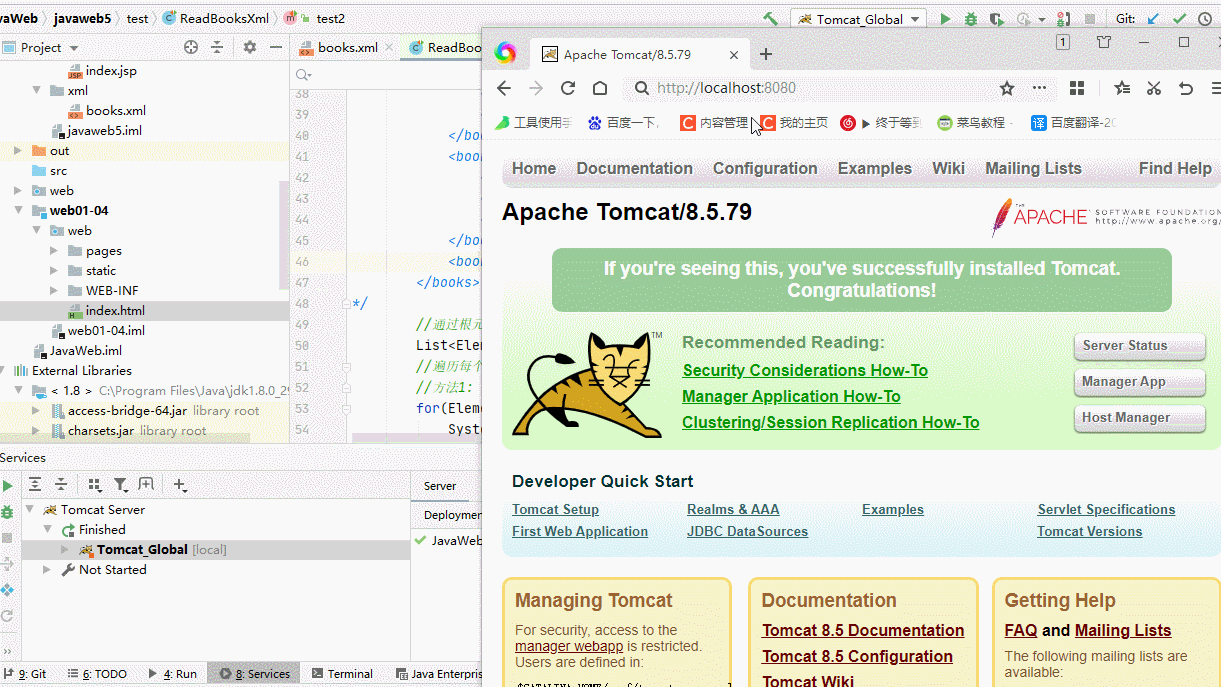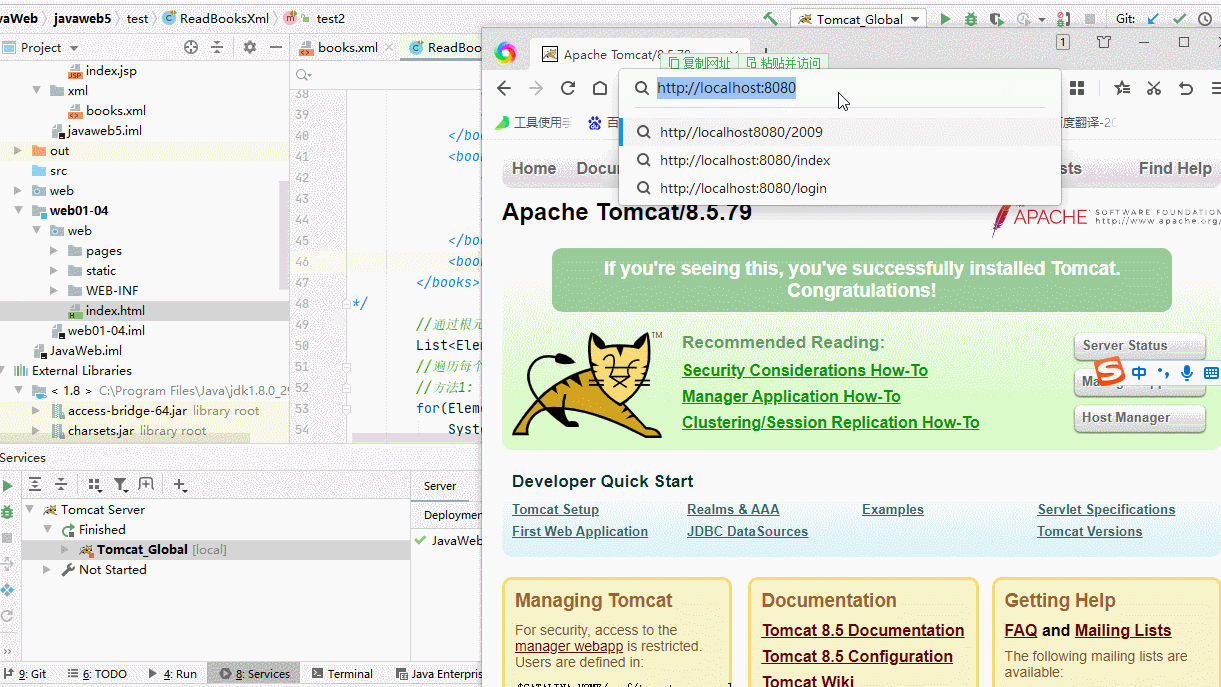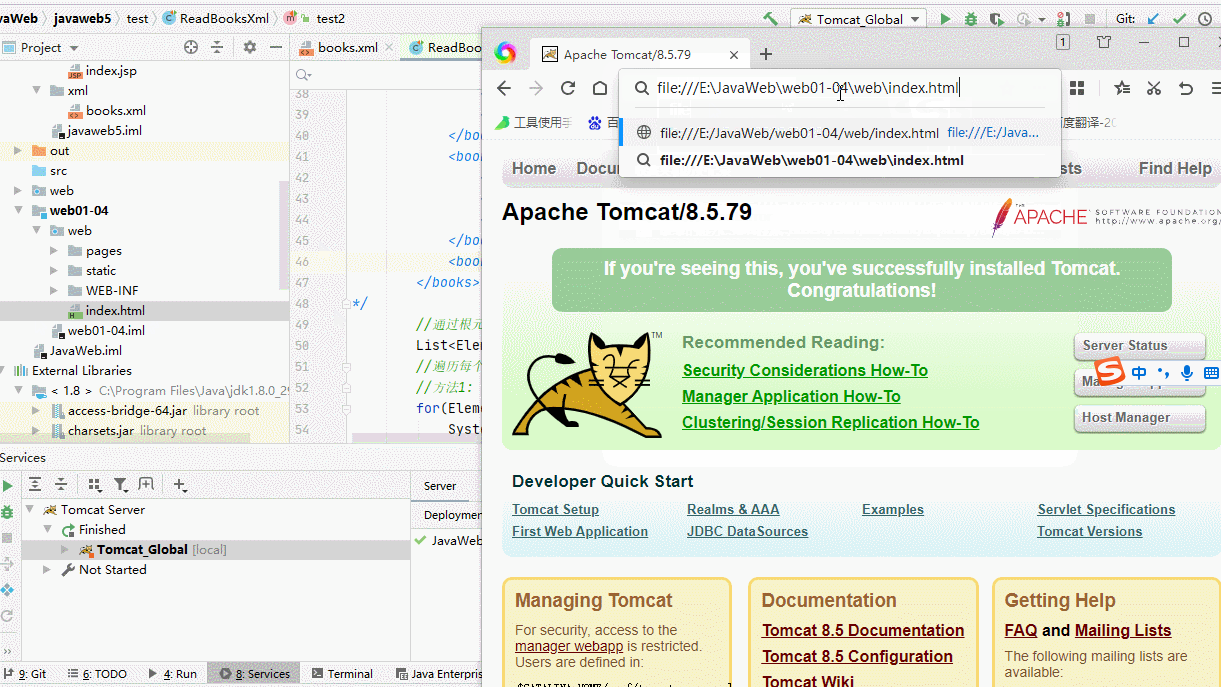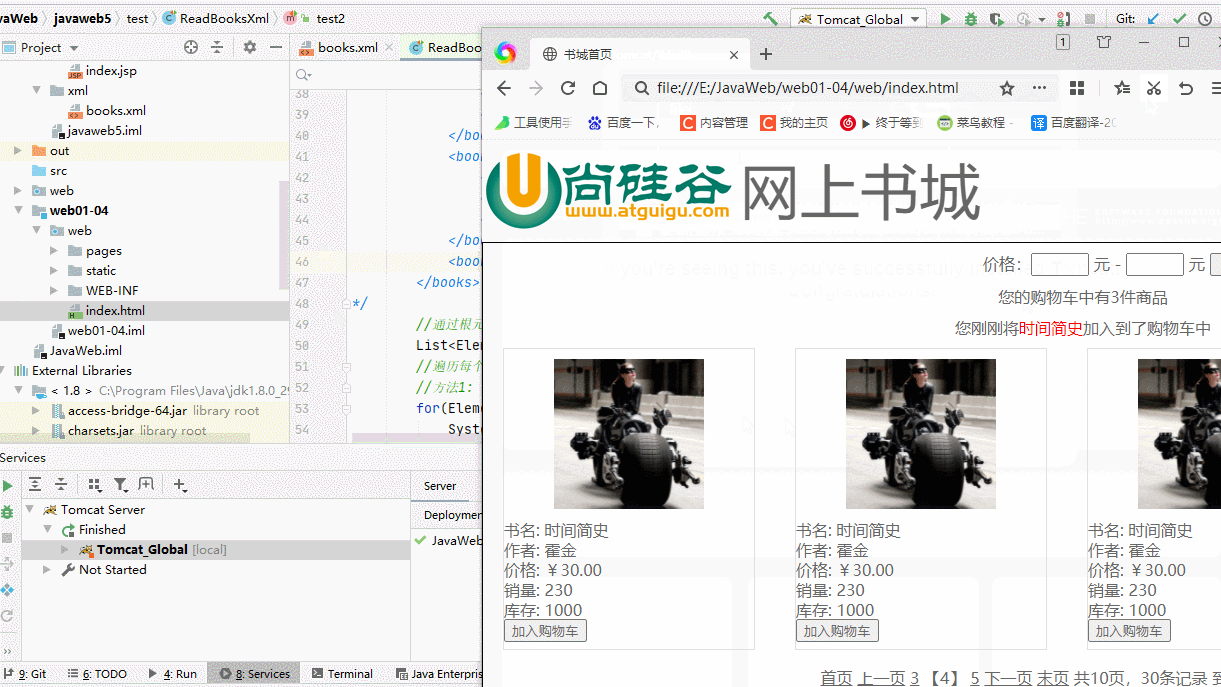
原理:通过file协议,浏览器直接读取file协议后面的磁盘路径,然后解析展示在浏览器中
Tomcat的ROOT工程访问与默认index.html
原理:
- 当我们在浏览器地址栏中输入访问地址如下:
- http://ip:port/ ====>>>> 没有工程名的时候,默认访问的是 ROOT 工程。
- 当我们在浏览器地址栏中输入的访问地址如下:
- http://ip:port/工程名/ ====>>>> 没有资源名,默认访问 index.html 页面
案例:
IDEA 中动态 web 工程的操作
IDEA 整合 Tomcat 服务器
- 操作的菜单如下:File-->Settings-->Build, Execution, Deployment-->Application Servers
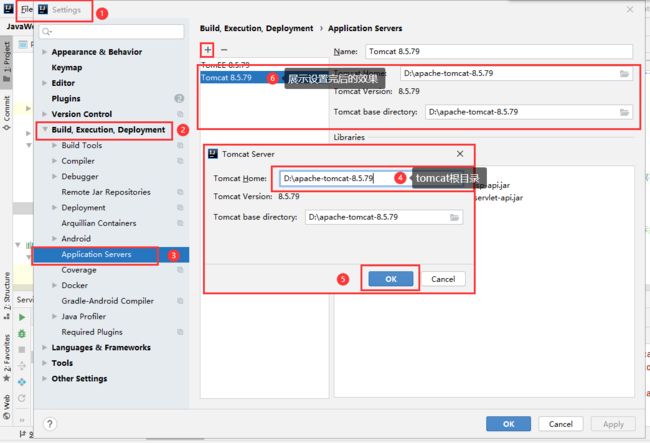
- 查看IDEA是否整合Tomcat成功
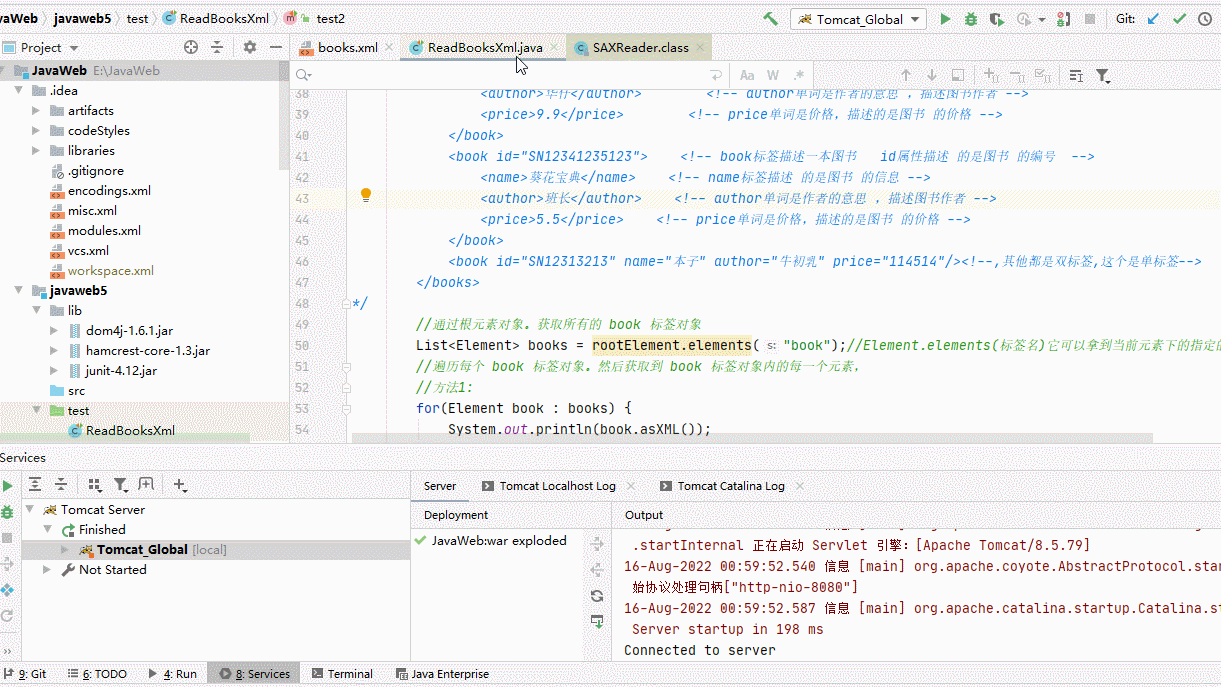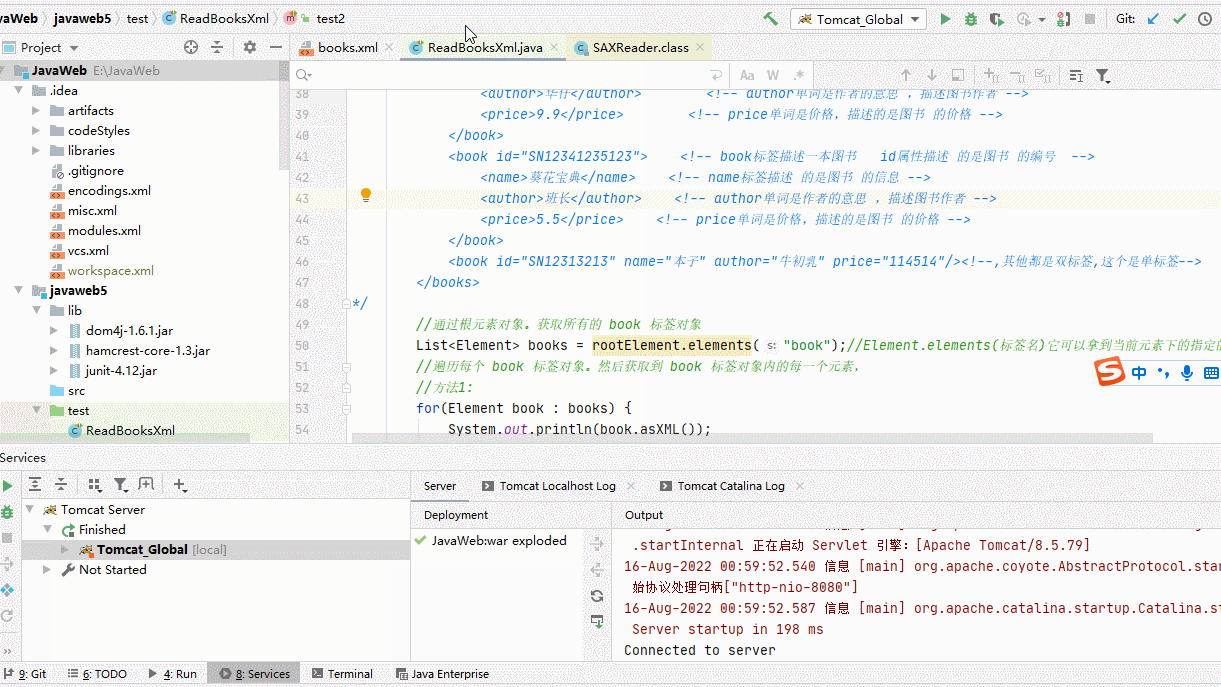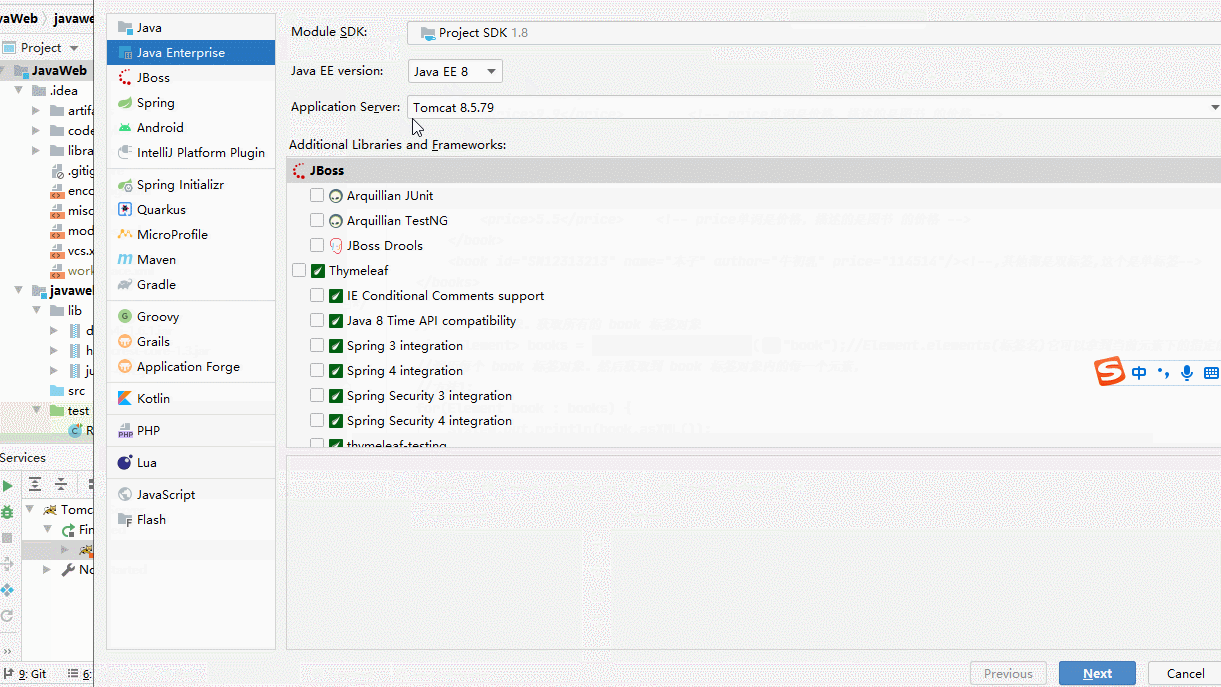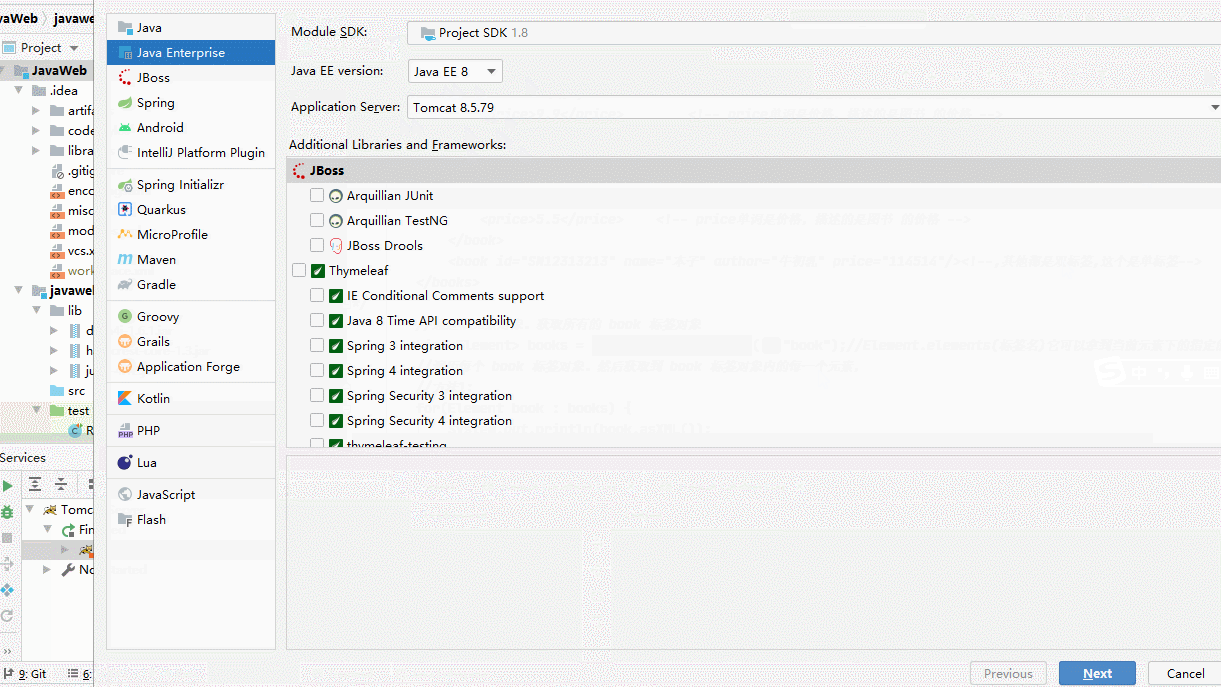
IDEA 中如何创建动态 web 工程
说明:之前已经有教程教过怎么创建了,这里开始深究
Web 工程的目录介绍
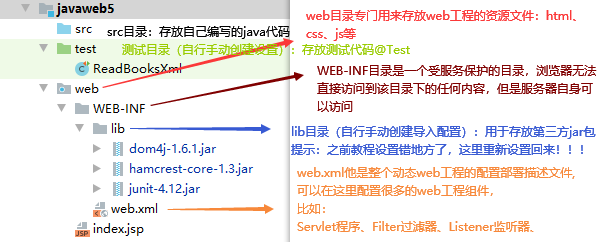
(重要)在IDEA中给动态 web 工程添加额外 jar 包到类库的清晰讲解
说明:与“将jar包添加到自定义的名为"dom4j.1.6.1"类库中”效果一样,只是该方法更加详细
- 未添加jar包前的项目是如图所示模样
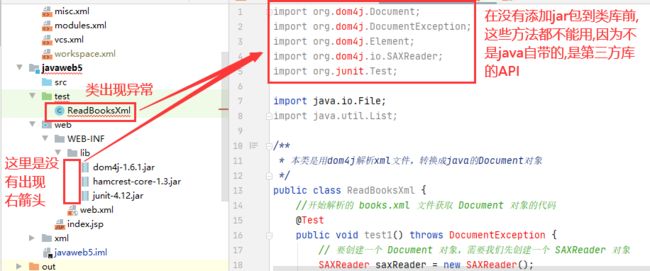
- 打开项目结构菜单界面-->添加一个自己的类库(可改名)-->找到要添加的jar包-->指定这个类库的jar包要给哪个模块使用(后面会有补充)
- 配置好自定义类库就不会报错且能正常编译,但是module需要有Artifacts 才可以部署到应用服务器中

-
为web项目添加Artifact的配置
说明:artifact:编译后的Java类,Web资源等的整合,用以测试、部署等工作。
某个XXXmodule要如何打包,例如 war exploded、war、jar、ear等等这种打包形式。某个module有了Artifacts就可以部署到应用服务器中了。-
提示说’Web’并不包含在任何Artifacts中,于是我们点击create Artifact去创建一个Artifact

- 点击了"Create Artifact"就为Web项目创建Artifacts,按下图配置好应用就好

-
- artifact是编译后的Java类,Web资源等的整合,因此补上漏了Library类库中的jar包整合时
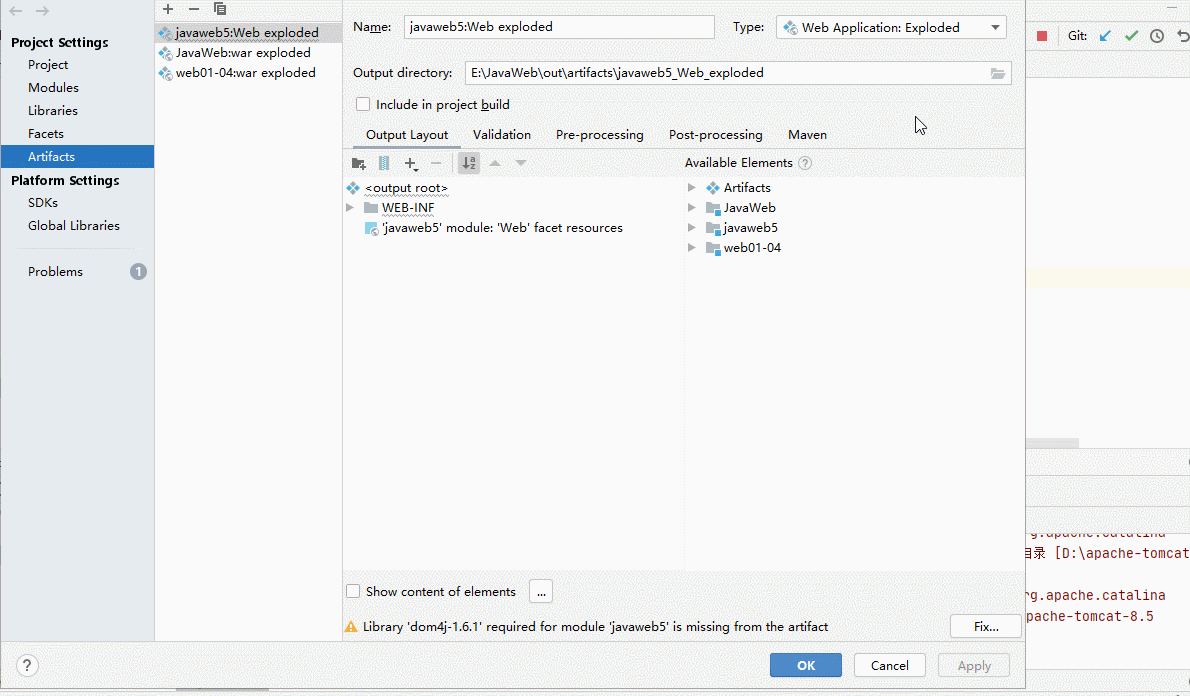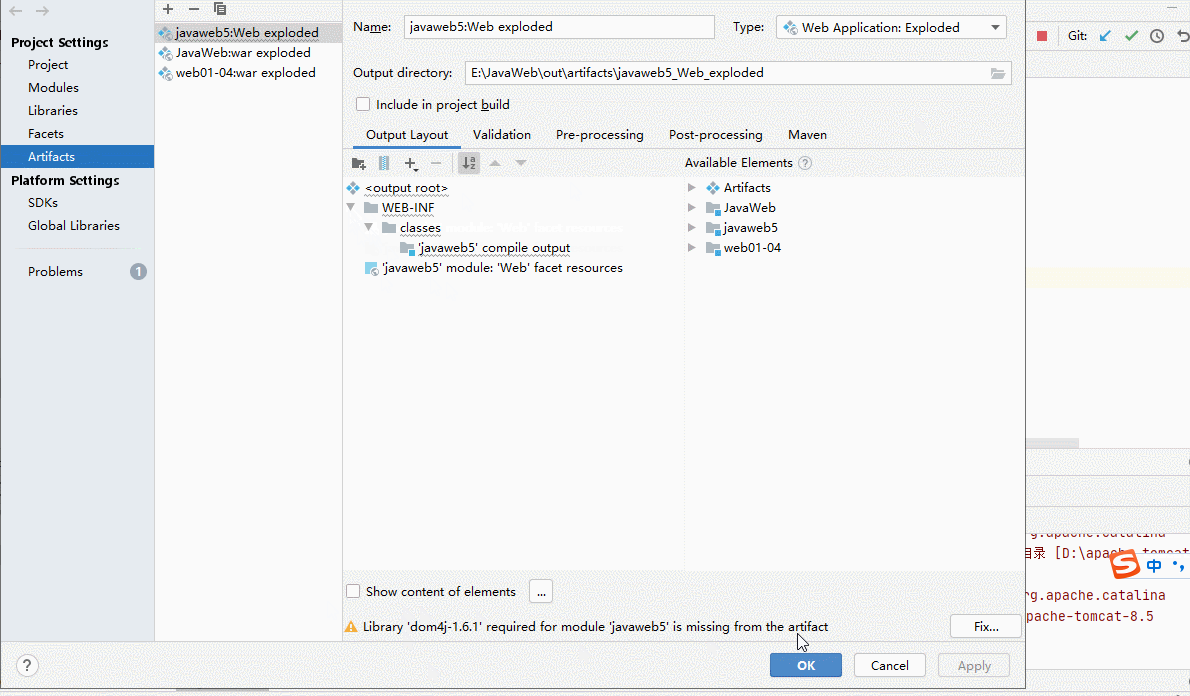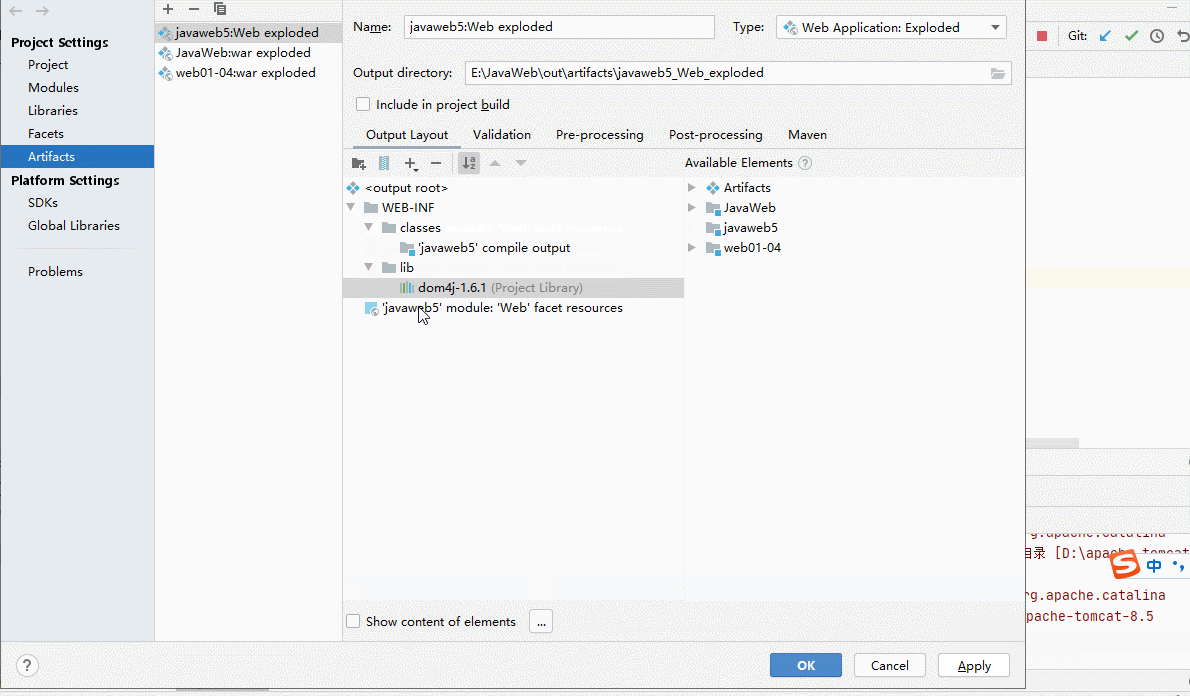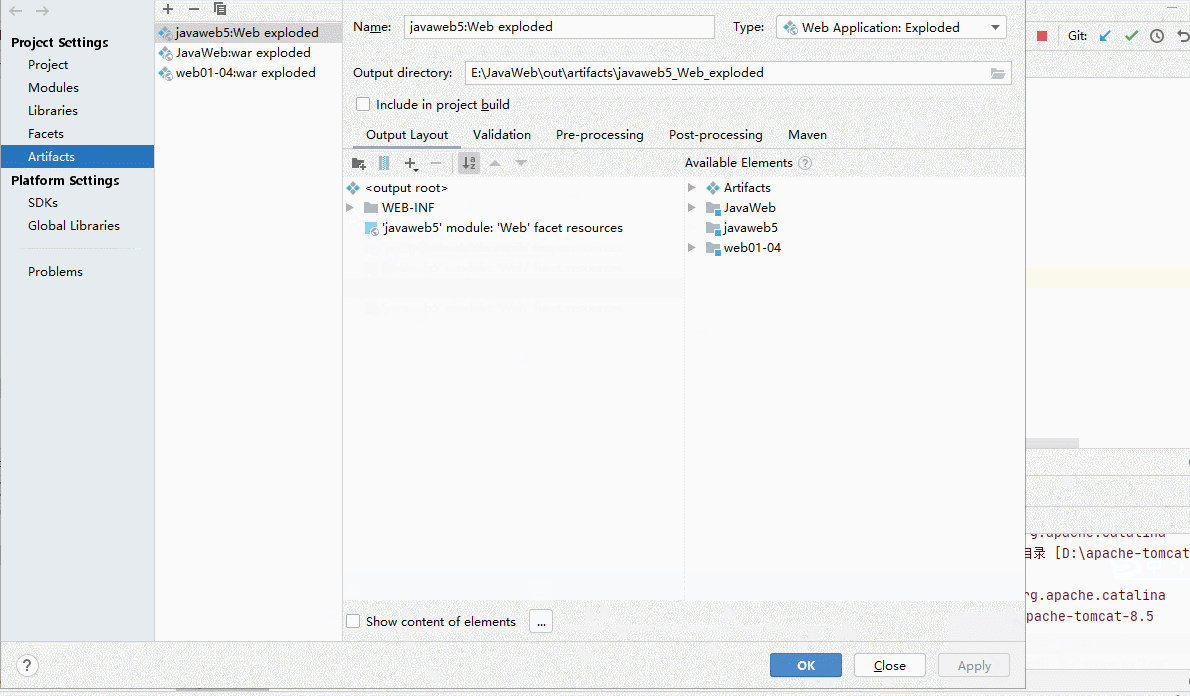
- 至此,我们就可以在 IDEA 中部署web工程到 Tomcat 上运行
(补充)"指定这个类库的jar包要给哪个模块使用"中,Scope在何种情况下要设置为provided,以及和scope设置为compile的区别
说明:该补充知识对后面的Maven中的Pom.xml作用很大

解释:
- 对于scope=compile的情况(默认scope),也就是说这个项目在编译,测试,运行阶段都需要这个artifact(模块)对应的jar包在classpath中。
- 而对于scope=provided的情况,则可以认为这个provided是目标容器已经provide(提供)这个artifact。换句话说,它只影响到编译,测试阶段。在编译测试阶段,我们需要这个artifact对应的jar包在classpath中,而在运行阶段,假定目标的容器(比如我们这里的liferay容器)已经提供了这个jar包,所以无需我们这个artifact对应的jar包了。
举例:
- 比如说,假定我们自己的项目ProjectABC 中有一个类叫C1,而这个C1中会import这个portal-impl的artifact中的类B1,那么在编译阶段,我们肯定需要这个B1,否则C1通不过编译,因为我们的scope设置为provided了,所以编译阶段起作用,所以C1正确的通过了编译。测试阶段类似,故忽略。
- 那么最后我们要吧ProjectABC部署到Liferay服务器上了,这时候,我们到
$liferay-tomcat-home\webapps\ROOT\WEB-INF\lib下发现,里面已经有了一个portal-impl.jar了,换句话说,容器已经提供了这个artifact对应的jar,所以,我们在运行阶段,这个C1类直接可以用容器提供的portal-impl.jar中的B1类,而不会出任何问题。
实际插件行为:
- 刚才我们讲述的是理论部分,现在我们看下,实际插件在运行时候,是如何来区别对待scope=compile和scope=provided的情况的。
- 做一个实验就可以很容易发现,当我们用maven install生成最终的构件包ProjectABC.war后,在其下的WEB-INF/lib中,会包含我们被标注为scope=compile的构件的jar包,而不会包含我们被标注为scope=provided的构件的jar包。这也避免了此类构件当部署到目标容器后产生包依赖冲突。
Scope有四种值,分别为:
- 首先是java有三种classpath,分别为:编译,测试,运行
- compile:默认范围,编译测试运行都有效
- provided:在编译和测试时有效
- runtime:在测试和运行时有效
- test:只在测试时有效
- system:在编译和测试时有效,与本机系统关联,可移植性差(Maven的pom.xml的
便签值)
(重要)在 IDEA 中部署web工程到 Tomcat 上运行的详细讲解
- 添加Tomcat服务器实例,建议修改 web 工程对应的 Tomcat 运行实例名称,方便后期测试管理!!!!!

- Tomcat 实例中添加要部署运行的 web 工程模块

- 修改IDEA的Tomcat配置
- 可以修改默认的工程路径

- 修改运行实例名称;Tomcat根目录;服务器启动后默认使用什么浏览器打开;服务器启动后打开什么路径;服务器启动命令(了解);热部署——服务器更新(这里默认是重启服务器,我改成了更新资源和类,后面会有详细的热部讲解);Tomcat启动所占用的服务器端口,我改成了8082;JMX也不能与其他程序冲突(了解即可)
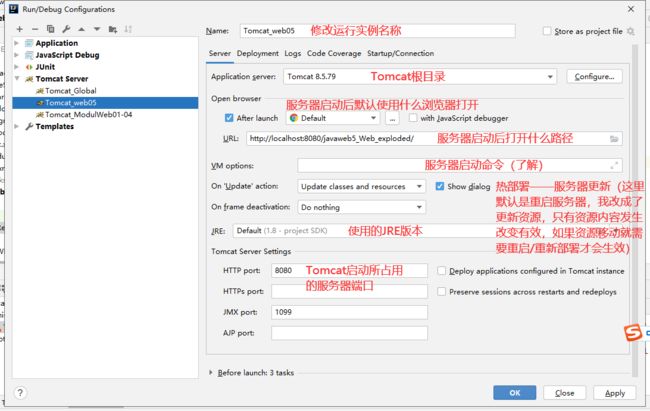
- 可以修改默认的工程路径
- 启动在 IDEA 中部署好的web工程的 Tomcat 服务器

热部署说明
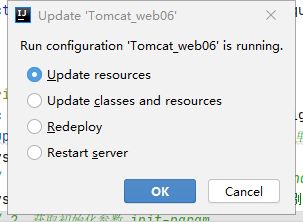
-
如果是web中的内容发生更新,那么使用 Update resources 就可以了
-
如果是java类(src目录)的内容发生,那么就使用Update classes and resources就可以了
-
文件web目录发生改变,那么就要把out目录下的artifacts目录删掉,然后再点击Redeploy部署,那么就会自动编译并且重新部署
-
文件src目录发生改变,那么就要把out目录下的production目录删掉,然后再点击Redeploy重新部署,那么就会自动编译并且重新部署
-
最方便的办法就是直接把out目录删除,然后再点击Redeploy部署,那么就会自动编译并且重新部署,但是性能较慢,因为要重新编译部署大量文件,性能很慢