GraphSAGE 到底在训练什么? 图上的Mini-Batch 是怎么训练的 ?
1. 一个端到端的 同构图 全图训练(Cora数据集)GraphSAGE模型 节点分类代码:
再次重申下什么是全图训练:
全图(使用所有的节点和边的特征)上的训练只需要使用上面定义的模型进行前向传播计算,并通过在训练节点上比较预测和真实标签来计算损失,从而完成后向传播。
'''
DGL 为 GraphSAGE 实现了2种训练:full-graph 和 mini-batch :
下面这个代码就是 full-graph 的 GraphSAGE 的 Cora 数据集的训练:
https://github.com/dmlc/dgl/blob/master/examples/pytorch/graphsage/train_full.py
'''
# https://github.com/dmlc/dgl/blob/master/examples/pytorch/graphsage/train_full.py
import argparse
import dgl
import dgl.nn as dglnn
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl import AddSelfLoop
from dgl.data import CiteseerGraphDataset, CoraGraphDataset, PubmedGraphDataset
from dgl.nn.pytorch import SAGEConv
class SAGE(nn.Module):
def __init__(self, in_size, hid_size, out_size):
super().__init__()
self.layers = nn.ModuleList()
# two-layer GraphSAGE-mean
self.layers.append(SAGEConv(in_size, hid_size, "gcn"))
self.layers.append(SAGEConv(hid_size, out_size, "gcn"))
self.dropout = nn.Dropout(0.5)
def forward(self, graph, x):
h = self.dropout(x)
for l, layer in enumerate(self.layers):
h = layer(graph, h)
if l != len(self.layers) - 1:
h = F.relu(h)
h = self.dropout(h)
return h
def evaluate(g, features, labels, mask, model):
model.eval() # model.eval() 是模型的方法之一,它将模型设置为评估模式。
# 在评估模式下,模型会做一些调整,例如关闭 Dropout 和 Batch Normalization 层的随机性,以保持一致的输出。
# 这样可以确保评估过程的稳定性和可重复性。
with torch.no_grad(): # with torch.no_grad() 是一个上下文管理器,用于指定在该上下文中不需要计算梯度。
# 这样做可以节省内存,并且可以加快代码的执行速度。
logits = model(g, features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
def train(g, features, labels, masks, model):
# define train/val samples, loss function and optimizer
train_mask, val_mask = masks
loss_fcn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, weight_decay=5e-4)
# training loop
for epoch in range(200):
model.train()
logits = model(g, features)
loss = loss_fcn(logits[train_mask], labels[train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = evaluate(g, features, labels, val_mask, model)
print(
"Epoch {:05d} | Loss {:.4f} | Accuracy {:.4f} ".format(
epoch, loss.item(), acc
)
)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="GraphSAGE")
parser.add_argument(
"--dataset",
type=str,
default="cora",
help="Dataset name ('cora', 'citeseer', 'pubmed')",
)
parser.add_argument(
"--dt",
type=str,
default="float",
help="data type(float, bfloat16)",
)
args = parser.parse_args()
print(f"Training with DGL built-in GraphSage module")
# load and preprocess dataset
transform = (
AddSelfLoop()
) # by default, it will first remove self-loops to prevent duplication
if args.dataset == "cora":
data = CoraGraphDataset(transform=transform)
elif args.dataset == "citeseer":
data = CiteseerGraphDataset(transform=transform)
elif args.dataset == "pubmed":
data = PubmedGraphDataset(transform=transform)
else:
raise ValueError("Unknown dataset: {}".format(args.dataset))
g = data[0]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
g = g.int().to(device)
features = g.ndata["feat"]
labels = g.ndata["label"]
masks = g.ndata["train_mask"], g.ndata["val_mask"]
# create GraphSAGE model
in_size = features.shape[1]
out_size = data.num_classes
model = SAGE(in_size, 16, out_size).to(device)
# convert model and graph to bfloat16 if needed
if args.dt == "bfloat16":
g = dgl.to_bfloat16(g)
features = features.to(dtype=torch.bfloat16)
model = model.to(dtype=torch.bfloat16)
# model training
print("Training...")
train(g, features, labels, masks, model)
# test the model
print("Testing...")
acc = evaluate(g, features, labels, g.ndata["test_mask"], model)
print("Test accuracy {:.4f}".format(acc))2. GraphSAGE的实现 : SAGEConv 类:
我们先来介绍一下DGL对GraphSAGE这个模型的实现:SAGEConv() 在三方库的下述位置:
![]()
补充:
SAGEConv 类中实现了foeward()这个函数,可能是因为 nn.Module这个父类要求子类继承时必须事先这个父类以明确该模型在这一层会经过什么样的处理:
(1)对比 GCN 和 GraphSAGE 两个模型的方法:
1. 模型架构:GCN 和 GraphSAGE 的架构有所不同。GCN 是一种基于卷积神经网络思想的图神经网络,其基本思路是通过卷积操作来计算节点特征。而 GraphSAGE 则是一种基于采样池化的图神经网络,其基本思路是通过对邻居节点进行采样池化来计算节点特征。
2. 节点采样方式:GCN 和 GraphSAGE 的节点采样方式也有所不同。GCN 采用固定的邻居采样方式,即每个节点的邻居节点数量是相同的。而 GraphSAGE 使用一种自适应的邻居采样方式,即每个节点的邻居节点数量可以根据节点的度数进行动态调整。
3. 计算效率:GCN 和 GraphSAGE 的计算效率也有所不同。由于 GCN 需要计算全局的邻居特征,因此在处理大规模的图数据时会面临较大的计算和存储压力。而 GraphSAGE 可以通过采样池化的方式来减少计算量,从而提高计算效率。
4. 可扩展性:GCN 和 GraphSAGE 的可扩展性也有所不同。由于 GCN 需要计算全局的邻居特征,因此其在处理大规模图数据时会面临存储和内存限制的挑战。而 GraphSAGE 采用了采样池化的方式来减少计算量,从而可以更好地处理大规模图数据。
5. 应用场景:最后,GCN 和 GraphSAGE 的应用场景也有所不同。GCN 更适用于那些节点特征依赖于其邻居节点特征的任务,例如社交网络中的节点分类、链接预测等。而 GraphSAGE 更适合于那些需要处理大规模图数据的任务,例如推荐系统中的商品推荐、广告投放等。
(2) 解释一下dropout层:
dropout层原来是在其他的神经网络学习领域使用,用于消减过平滑,但是,GCN首次将dropout层引入图神经网络的学习里,用来减少过拟合。
那 dropout 层在GraphSAGE 中是怎么实现的呢?
dropout操作的主要思想是,在训练过程中以指定的概率丢弃随机选择的输入特征,并按比例缩放保留的特征。这样可以减少特征之间的依赖关系,同时由于 每次迭代训来时都会有 不同的 特征被丢弃,这使得训练操作可以看作是模型在不同的子集上训练,从而提高了模型的鲁棒性。
具体来说,假设我们有一个输入特征矩阵X,其形状为(batch_size, num_features)。dropout操作会 按照指定的概率 p ,从输入特征矩阵中随机选择一些元素并将它们的值置为0,然后将剩下的特征元素值除以 (1-p) 进行缩放,以保持输入特征的期望值不变。
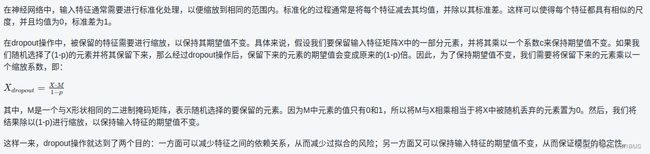
这个过程可以看作是对输入特征进行掩码,其中被掩码为0的元素被称为被丢弃的特征。通过随机地丢弃一部分特征,dropout操作迫使模型不能过度依赖任何一个特征,从而减少了特征之间的共适应性(co-adaptation),提高了模型的泛化能力。
在训练过程中,dropout层会随机选择要被丢弃的特征,而在测试过程中,dropout层通常会关闭,所有的输入特征都会被保留下来并按比例缩放,以便获得稳定的预测结果。
==》在DGL 对 GraphSAGE的实现中,通过 ` self.dropout = nn.Dropout(0.5) ` 将 p 置为 0.5
3. DGL 实现的 端到端的 随机批次训练 示例 GraphSAGE 实现
https://github.com/dmlc/dgl/blob/master/examples/pytorch/graphsage/node_classification.py
但是,由于ogb这个数据集实在是太大了(1.x G),我选择替内存&显存不足娃子行道,用Cora数据集重写一下:
原因如下&下图:
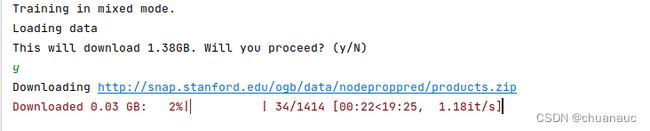
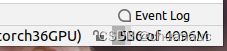
首先是这个数据集真的很大,其次是,这个源代码的模型是3层,众所周知,GNN层数越深越会导致训练的子图越大,涉及的节点就越多。然后再配合上3层的GraphSAGE卷积层计算,好家伙,生怕我的显存够用是吧。我将minibatch参数已经设置为1了,使用default推荐的训练模式"mixed"依旧会把报个错误:“Process finished with exit code 137 (interrupted by signal 9: SIGKILL)” 原因也很简单,因为训练过程超出我的显存容量了(我的显存4G)。不得以,我只能修改:首先是将训练模式由原来的"mixed"改成"cpu"因为cpu的主存至少比GPU的大一点把。第二个截图就是我batchsize=12设置下,训练模式设置为cpu的贮存占用量。即使我都这样设置了,在test数据集的时候又超出了我的CPU主存,然后报错,我,,,,,,,

(1)先上代码:
这个就是GraphSAGE_minibatch在训练什么的代码(test_idx那里没处理,改一下就好了)
import argparse
import dgl
import dgl.nn as dglnn
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics.functional as MF
import tqdm
from dgl.data import AsNodePredDataset
from dgl.dataloading import (
DataLoader,
MultiLayerFullNeighborSampler,
NeighborSampler,
)
# 完整的内置采样方法清单,用户可以参考 https://docs.dgl.ai/api/python/dgl.dataloading.html#api-dataloading-neighbor-sampling
from ogb.nodeproppred import DglNodePropPredDataset
from dgl import AddSelfLoop
from dgl.data import CiteseerGraphDataset, CoraGraphDataset, PubmedGraphDataset
class SAGE(nn.Module):
def __init__(self, in_size, hid_size, out_size):
super().__init__()
self.layers = nn.ModuleList()
# three-layer GraphSAGE-mean
self.layers.append(dglnn.SAGEConv(in_size, hid_size, "mean"))
self.layers.append(dglnn.SAGEConv(hid_size, hid_size, "mean"))
self.layers.append(dglnn.SAGEConv(hid_size, out_size, "mean"))
self.dropout = nn.Dropout(0.5)
self.hid_size = hid_size
self.out_size = out_size
def forward(self, blocks, x):
print("执行forward:")
h = x
for l, (layer, block) in enumerate(zip(self.layers, blocks)):
h = layer(block, h)
if l != len(self.layers) - 1:
h = F.relu(h)
h = self.dropout(h)
return h
def inference(self, g, device, batch_size):
"""Conduct layer-wise inference to get all the node embeddings."""
# 进行分层推理以获得所有节点的嵌入表示在图神经网络或类似的模型中,通常会使用多层神经网络来学习节点的表示,
# 每一层都会对节点的表示进行变换和更新。通过进行分层推理,可以获取所有节点在每一层的嵌入表示
feat = g.ndata["feat"]
sampler = MultiLayerFullNeighborSampler(1, prefetch_node_feats=["feat"])
dataloader = DataLoader(
g,
torch.arange(g.num_nodes()).to(g.device),
sampler,
device=device,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=0,
)
buffer_device = torch.device("cpu")
pin_memory = buffer_device != device
for l, layer in enumerate(self.layers): # 一会试试不加这个y,即,不开辟空间会有啥负面效果
y = torch.empty(
g.num_nodes(),
self.hid_size if l != len(self.layers) - 1 else self.out_size,
dtype=feat.dtype,
device=buffer_device,
pin_memory=pin_memory,
)
feat = feat.to(device)
for input_nodes, output_nodes, blocks in tqdm.tqdm(dataloader): # tqdm.tqdm() 函数 用来包装 dataloader,作用是 在命令行上 以进度条的方式 直观显示处理进度
x = feat[input_nodes]
h = layer(blocks[0], x) # len(blocks) = 1 【这是啥意思?】
if l != len(self.layers) - 1:
h = F.relu(h)
h = self.dropout(h)
# by design, our output nodes are contiguous 根据设计,我们的输出节点是连续的
y[output_nodes[0] : output_nodes[-1] + 1] = h.to(buffer_device)
feat = y
return y
def evaluate(model, graph, dataloader, num_classes):
model.eval()
ys = []
y_hats = []
for it, (input_nodes, output_nodes, blocks) in enumerate(dataloader):
with torch.no_grad():
x = blocks[0].srcdata["feat"]
ys.append(blocks[-1].dstdata["label"])
print("在Val中:")
y_hats.append(model(blocks, x))
return MF.accuracy(
torch.cat(y_hats),
torch.cat(ys),
task="multiclass",
num_classes=num_classes,
)
# def layerwise_infer(device, graph, nid, model, num_classes, batch_size): [DGL]
def layerwise_infer(device, graph, nid, model, num_classes, batch_size):
model.eval()
with torch.no_grad():
pred = model.inference(
graph, device, batch_size
) # pred in buffer_device
pred = pred[nid]
label = graph.ndata["label"][nid].to(pred.device)
return MF.accuracy(
pred, label, task="multiclass", num_classes=num_classes
)
def train(args, device, g, dataset, model, num_classes):
# create sampler & dataloader
# 构造数据集:
train_mask = g.ndata["train_mask"]
val_mask = g.ndata["val_mask"]
train_idx = torch.tensor( [i for i, x in enumerate(train_mask) if x] ) # 获取所有True元素的索引id
val_idx = torch.tensor( [i for i, x in enumerate(val_mask) if x] ) # 获取所有True元素的索引id
train_idx = train_idx.to(device)
val_idx = val_idx.to(device)
# train_idx = dataset.train_idx.to(device) [DGL]
# print("dataset.train_idx:",dataset.train_idx)
# 输出:dataset.train_idx: tensor([ 0, 1, 2, ..., 196612, 196613, 196614])
# val_idx = dataset.val_idx.to(device) [DGL]
sampler = NeighborSampler(
[10, 10, 10], # fanout for [layer-0, layer-1, layer-2]
prefetch_node_feats=["feat"],
prefetch_labels=["label"],
)
use_uva = args.mode == "mixed"
train_dataloader = DataLoader(
g,
train_idx,
sampler,
device=device,
batch_size=1024,
shuffle=True,
drop_last=False,
num_workers=0,
use_uva=use_uva,
)
val_dataloader = DataLoader(
g,
val_idx,
sampler,
device=device,
batch_size=16,
shuffle=True,
drop_last=False,
num_workers=0,
use_uva=use_uva,
)
opt = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=5e-4)
for epoch in range(1):
model.train() # model.train()是用于将模型设置为训练模式的函数调用。
# 当你使用DGL构建图神经网络时,通常需要在训练阶段和评估阶段分别设置不同的模式。
total_loss = 0
for it, (input_nodes, output_nodes, blocks) in enumerate(train_dataloader):
x = blocks[0].srcdata["feat"]
y = blocks[-1].dstdata["label"]
y_hat = model(blocks, x)
loss = F.cross_entropy(y_hat, y)
opt.zero_grad()
loss.backward()
opt.step()
total_loss += loss.item()
acc = evaluate(model, g, val_dataloader, num_classes)
print(
"Epoch {:05d} | Loss {:.4f} | Accuracy {:.4f} ".format(
epoch, total_loss / (it + 1), acc.item()
)
)
if __name__ == "__main__":
# 参数设置代码段罢了,
try :
parser = argparse.ArgumentParser()
parser.add_argument(
"--mode",
default="cpu",
choices=["cpu", "mixed", "puregpu"],
help="Training mode. 'cpu' for CPU training, 'mixed' for CPU-GPU mixed training, "
"'puregpu' for pure-GPU training.",
)
parser.add_argument(
"--dt",
type=str,
default="float",
help="data type(float, bfloat16)",
)
args = parser.parse_args()
if not torch.cuda.is_available():
args.mode = "cpu"
print(f"Training in {args.mode} mode.")
except Exception as e:
print("参数解析错误:", e)
# load and preprocess dataset
print("Loading data")
# dataset = AsNodePredDataset(DglNodePropPredDataset("ogbn-products")) 【DGL】
transform = (
AddSelfLoop()
) # by default, it will first remove self-loops to prevent duplication
dataset = CoraGraphDataset(transform=transform)
g = dataset[0]
g = g.to("cuda" if args.mode == "puregpu" else "cpu")
num_classes = dataset.num_classes
device = torch.device("cpu" if args.mode == "cpu" else "cuda")
# create GraphSAGE model
in_size = g.ndata["feat"].shape[1]
out_size = dataset.num_classes
model = SAGE(in_size, 256, out_size).to(device)
# convert model and graph to bfloat16 if needed
if args.dt == "bfloat16":
g = dgl.to_bfloat16(g)
model = model.to(dtype=torch.bfloat16)
# model training
print("Training...")
train(args, device, g, dataset, model, num_classes)
# test the model
print("Testing...")
acc = layerwise_infer(
device, g, dataset.test_idx, model, num_classes, batch_size=4096
)
print("Test Accuracy {:.4f}".format(acc.item()))(2) 补充一下实现的细节:
语法知识:
1. 关于: ` self.layers = nn.ModuleList() self.layers.append(SAGEConv(XXXX) ) `
这个语法是干什么的呢?
首先说下他用在了哪里:在 DGL 对 GCN 和 GraphSAGE(SAGE类) 的两个类的实现中:一个用到了这个append()函数,一个就只是直接定义直接使用:
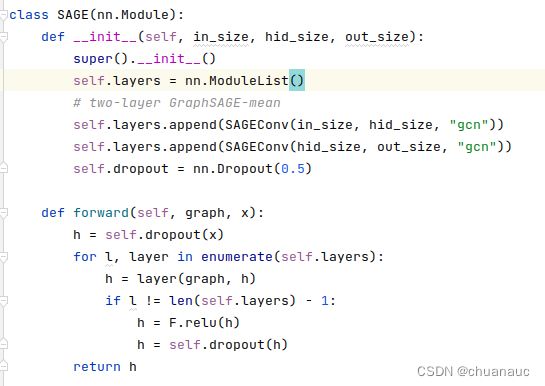
事实上:这俩的区别只是在于:layers 定义了一个 nn.ModuleList() 实例,把模型中的各个处理层 加入到列表中去,这样就可以使用for 循环来处理,比较方便,而不是像 GCN 那样每次重写,就这点区别,,,,,
2. 关于 : ' with graph.local_scope(): ' :
无论是DGL 关于 GCN 还是 GrraphSAGE 的实现都用到了这个DGL 实现的 graph.local_scope() 这个语句 :


这个语句是用来干什么的呢?
【回答】:使用graph.local_scope()确保我们对图对象进行的操作不会影响后续测试集数据的内容。
在训练阶段,我们可能需要对图进行一些操作,例如删去一些不重要的边、删去或修改部分节点的特征值等。这些操作可能是为了数据预处理、噪声过滤、特征工程等目的。通过在这些操作中使用graph.local_scope(),我们可以确保这些操作只在当前图对象的局部作用域中生效,并不会对其他图对象或全局计算图产生影响。
这样做的好处是,我们可以确保训练和测试集之间的数据内容是独立的,避免训练阶段的操作对测试阶段带来不必要的影响。这样可以保证我们在测试集上得到准确和可靠的评估结果,从而更好地评估模型的性能。