Linux shell编程学习笔记35:seq

0 前言
在使用 for 循环语句时,我们经常使用到序列。比如:
for i in 1 2 3 4 5 6 7 8 9 10; do echo "$i * 2 = $(expr $i \* 2)"; done
其中的 1 2 3 4 5 6 7 8 9 10;就是一个整数序列 。
为了方便我们使用数字序列,Linux提供了seq命令,这个命令是取自单词sequence的前3个字母。比如:
for i in $(seq 1 10) ; do
更多信息请回顾:
Linux shell编程学习笔记17:for循环语句-CSDN博客 https://blog.csdn.net/Purpleendurer/article/details/134102934?spm=1001.2014.3001.5501
https://blog.csdn.net/Purpleendurer/article/details/134102934?spm=1001.2014.3001.5501
其实,seq命令的用途和使用环境很广阔。现在我们就来探究一下。
1 seq命令的格式、功能
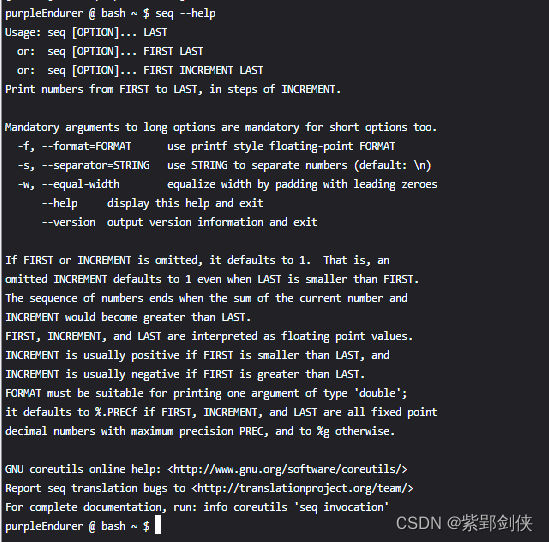
我们可以使用命令 seq --help 来查看seq命令的帮助信息:
purpleEndurer @ bash ~ $ seq --help
Usage: seq [OPTION]... LAST
or: seq [OPTION]... FIRST LAST
or: seq [OPTION]... FIRST INCREMENT LAST
Print numbers from FIRST to LAST, in steps of INCREMENT.Mandatory arguments to long options are mandatory for short options too.
-f, --format=FORMAT use printf style floating-point FORMAT
-s, --separator=STRING use STRING to separate numbers (default: \n)
-w, --equal-width equalize width by padding with leading zeroes
--help display this help and exit
--version output version information and exitIf FIRST or INCREMENT is omitted, it defaults to 1. That is, an
omitted INCREMENT defaults to 1 even when LAST is smaller than FIRST.
The sequence of numbers ends when the sum of the current number and
INCREMENT would become greater than LAST.
FIRST, INCREMENT, and LAST are interpreted as floating point values.
INCREMENT is usually positive if FIRST is smaller than LAST, and
INCREMENT is usually negative if FIRST is greater than LAST.
FORMAT must be suitable for printing one argument of type 'double';
it defaults to %.PRECf if FIRST, INCREMENT, and LAST are all fixed point
decimal numbers with maximum precision PREC, and to %g otherwise.GNU coreutils online help:
Report seq translation bugs to
For complete documentation, run: info coreutils 'seq invocation'
purpleEndurer @ bash ~ $
1.1 seq 命令的格式
seq [选项]... [序列起始数] [步长] 序列结尾数
1.1.1 参数:
- 序列起始数:可以是0、正整数 或 负整数,未指定时默认为1
- 序列结尾数:可以是0、正整数 或 负整数
- 步长 :可以是 正整数 或 负整数,未指定时默认为1
1.1.2 选项:
| 选项 | 说明 | 备注 |
|---|---|---|
| -f格式字符串 -f 格式字符串 -f=格式字符串 --format=FORMAT |
使用printf命令中的格式字符串来格式化输出,默认为%g 数字位数不足部分默认是空格 不能与 -w 或 --equal-width 同时使用 |
format |
| -s分隔字符串 -s 分隔字符串 -s=分隔字符串 --separator 分隔字符串 --separator=分隔字符串 |
使用指定的字符串作为数字间的分隔符(默认字符串是:\n) 指定作分隔符的字符串可以是空字符串,也可以1位字符,或者多位字符 |
separator |
| -w --equal-width |
通过用前导零填充来均衡宽度 不能与 -f 或 --format 同时使用 |
width |
| --help | 显示帮助信息并退出 | help |
| --version | 输出版本信息并退出 | version |
1.2 seq命令的功能
生成以超始数开始,逐一加上步长,直到结尾数的数列并以指定的格式输出。
2 seq 命令用法实例
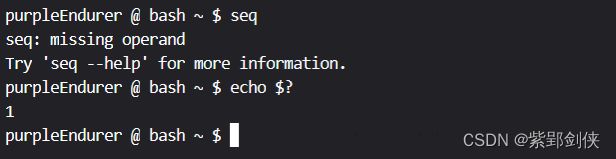
2.1 seq不带参数会报错,返加值为1
purpleEndurer @ bash ~ $ seq
seq: missing operand
Try 'seq --help' for more information.
purpleEndurer @ bash ~ $ echo $?
1
purpleEndurer @ bash ~ $
2.2 生成递增序列
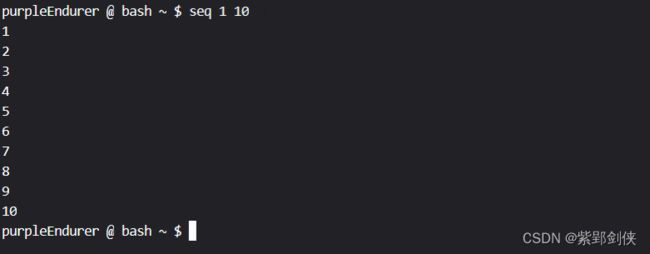
例 2.2 生成从1开始,步长为1,到10为止的序列
完整的命令是:seq 1 1 10
purpleEndurer @ bash ~ $ seq 1 1 10
1
2
3
4
5
6
7
8
9
10
purpleEndurer @ bash ~ $

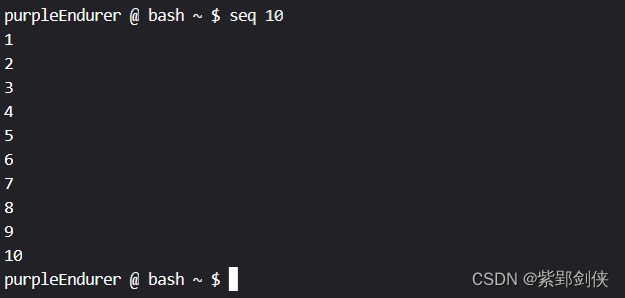
由于seq的 步长未指定时默认为1,所以我们可以将命令中代表步长的第二个1省略,从而简写为:seq 1 10
purpleEndurer @ bash ~ $ seq 1 10
1
2
3
4
5
6
7
8
9
10
purpleEndurer @ bash ~ $
由于seq的 序列起始数未指定时默认为1,所以我们可以将命令中的第一个1省略,进一步简写为:seq 10
purpleEndurer @ bash ~ $ seq 10
1
2
3
4
5
6
7
8
9
10
purpleEndurer @ bash ~ $
2.3 生成递减序列
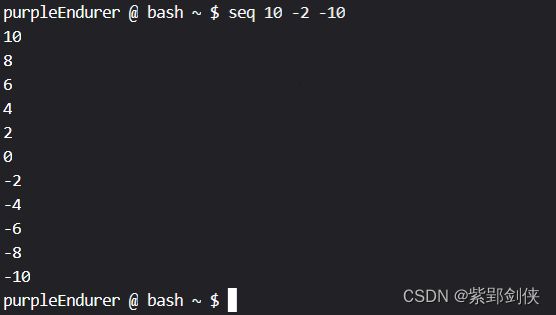
例 2.3 生成从10开始,步长为-2,到-10为止的序列
完整的命令是:seq 10 -2 -10
purpleEndurer @ bash ~ $ seq 10 -2 -10
10
8
6
4
2
0
-2
-4
-6
-8
-10
purpleEndurer @ bash ~ $
2.4 指定格式字符串
2.4.1 系统默认为%g
purpleEndurer @ bash ~ $ seq -f '%g' 10 -2 -10
10
8
6
4
2
0
-2
-4
-6
-8
-10
purpleEndurer @ bash ~ $
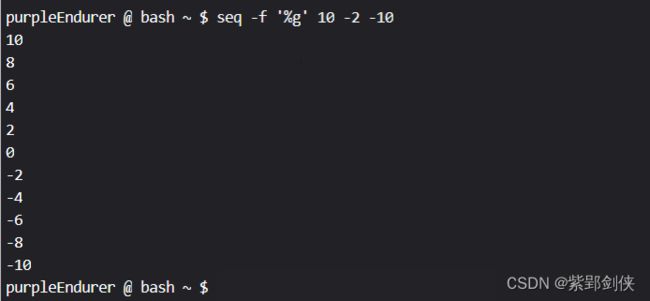
可以看到,当我们指定格式字符串为%g时,显示结果与不指定是一样的。
2.4.2 自定义格式字符串
例如我们指定以>开头,宽度为5来显示
以下命令均可以实现:
- seq -f=">%5g" 10 -2 -10
- seq -f">%5g" 10 -2 -10
- seq -f ">%5g" 10 -2 -10
- seq --format=">%5g" 10 -2 -10
- seq --format ">%5g" 10 -2 -10
purpleEndurer @ bash ~ $ seq -f '>%5g' 10 -2 -10
> 10
> 8
> 6
> 4
> 2
> 0
> -2
> -4
> -6
> -8
> -10
purpleEndurer @ bash ~ $ seq -f ">%5g" 10 -2 -10
> 10
> 8
> 6
> 4
> 2
> 0
> -2
> -4
> -6
> -8
> -10
purpleEndurer @ bash ~ $ seq --format=">%5g" 10 -2 -10
> 10
> 8
> 6
> 4
> 2
> 0
> -2
> -4
> -6
> -8
> -10
purpleEndurer @ bash ~ $ seq --format ">%5g" 10 -2 -10
> 10
> 8
> 6
> 4
> 2
> 0
> -2
> -4
> -6
> -8
> -10
purpleEndurer @ bash ~ $
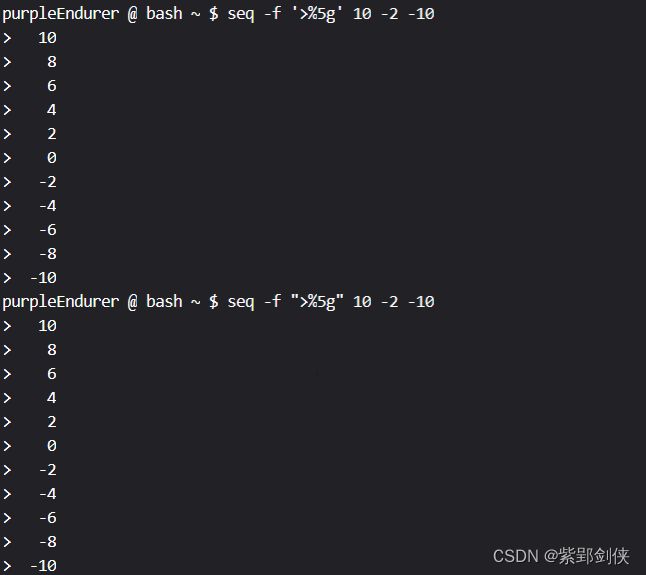
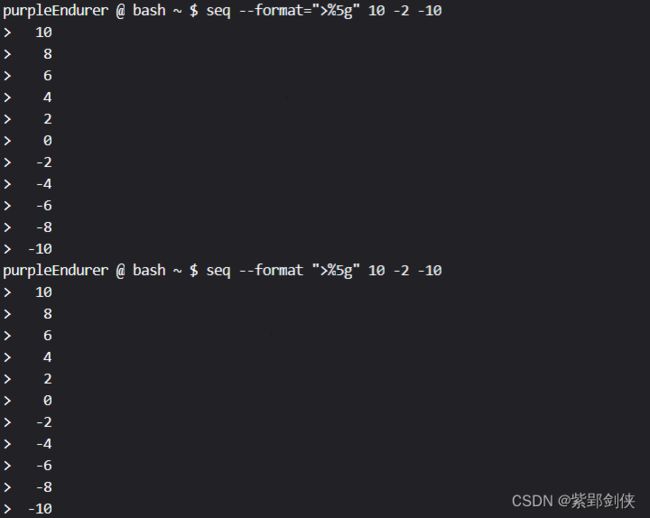
可以看到,seq命令默认是用空格来补位,如果我们想用0来补位,可以使用命令:
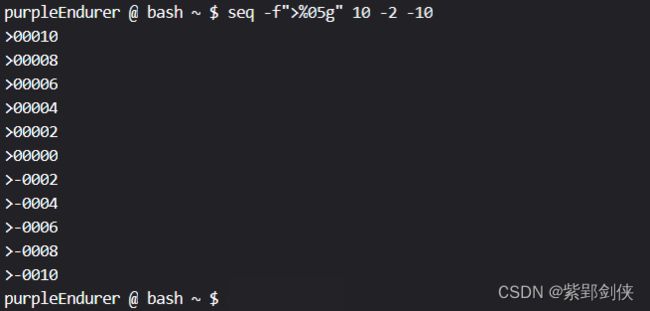
seq -f">%05g" 10 -2 -10
purpleEndurer @ bash ~ $ seq -f">%05g" 10 -2 -10
>00010
>00008
>00006
>00004
>00002
>00000
>-0002
>-0004
>-0006
>-0008
>-0010
purpleEndurer @ bash ~ $
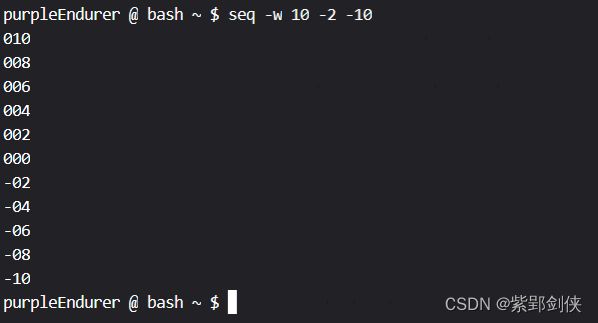
2.5 使用-w选项平衡宽度(不足时用0填充)
purpleEndurer @ bash ~ $ seq -w 10 -2 -10
010
008
006
004
002
000
-02
-04
-06
-08
-10
purpleEndurer @ bash ~ $
虽然 -w 和 -f"%5g"都是以0来填充空位的,但是对比二者的显示结果,可以发现二者存在一定的区别:
- -w是以生成的序列中位数最长的位数(包括负号-)为最大位数
例如在命令 seq -w 10 -2 -10 中,生成的序列中 位数最长的是-10,即3位数,所以生成序列均为3位数。
- -f选项可以直接指定位数
例如在命令 seq -f">%05g" 10 -2 -10 中,生成的序列中 位数最长的是-10,即3位数,但由于我们指定宽度为5,所以显示的序列均为5位数。
2.6 指定序列分隔符
seq命令默认序列分隔符为换行符\n,我们可能使用-s或--separator指定其它分隔符,指定的分隔符字符串可以是空字符串,也可以1位字符,或者多位字符。
例如,生成从10开始,步长为-2,到-10为止的序列,以两个冒号作为分隔符
使用命令都可以实现:
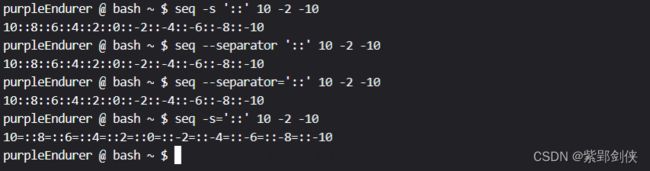
- seq -s '::' 10 -2 -10
- seq -s'::' 10 -2 -10
- seq -s='::' 10 -2 -10
- seq --separator '::' 10 -2 -10
- seq --separator='::' 10 -2 -10
purpleEndurer @ bash ~ $ seq -s '::' 10 -2 -10
10::8::6::4::2::0::-2::-4::-6::-8::-10
purpleEndurer @ bash ~ $ seq --separator '::' 10 -2 -10
10::8::6::4::2::0::-2::-4::-6::-8::-10
purpleEndurer @ bash ~ $ seq --separator='::' 10 -2 -10
10::8::6::4::2::0::-2::-4::-6::-8::-10
purpleEndurer @ bash ~ $ seq -s='::' 10 -2 -10
10=::8=::6=::4=::2=::0=::-2=::-4=::-6=::-8=::-10
purpleEndurer @ bash ~ $
我们也可以使用空字符串作为分隔符
purpleEndurer @ bash ~ $ seq --separator '' 10 -2 -10
1086420-2-4-6-8-10
purpleEndurer @ bash ~ $

3 seq 命令的类型 (is hashed?)
在
Linux shell编程学习笔记33:type 命令-CSDN博客https://blog.csdn.net/Purpleendurer/article/details/134804451?spm=1001.2014.3001.5501中,我们知道type命令 可以显示指定命令的信息,判断给出的指令是内部命令、外部命令(文件)、别名、函数、保留字 或者 不存在(找不到)。
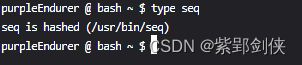
但对于seq命令,type命令显示的是 “seq is hashed (/usr/bin/seq)”
purpleEndurer @ bash ~ $ type seq
seq is hashed (/usr/bin/seq)
purpleEndurer @ bash ~ $
这是什么意思呢?
bing了一下,在bash - What does "is hashed" mean when using the type command? - Unix & Linux Stack Exchangehttps://unix.stackexchange.com/questions/251731/what-does-is-hashed-mean-when-using-the-type-command
给出的解释是:
What that means is that after finding the location of a command the first time (or when hash is invoked), its location is remembered (hashed).
翻译过来就是:
这意味着,在第一次找到命令的位置(或调用哈希时)后,会记住它的位置(散列)。
我们可以通过下面的命令序列来理解:
purpleEndurer @ bash ~ $ type seq
seq is /usr/bin/seq
purpleEndurer @ bash ~ $ seq
seq: missing operand
Try 'seq --help' for more information.
purpleEndurer @ bash ~ $ type seq
seq is hashed (/usr/bin/seq)
purpleEndurer @ bash ~ $
当我们登录系统后,还没有执行seq命令时,使用type seq命令,命令显示的信息是:seq is /usr/bin/seq
说明它是个外部命令。
当我们执行seq命令后,再使用type seq命令,命令显示的信息是:seq is hashed (/usr/bin/seq)
即此时系统已记住了seq命令的位置。