基于adaboost算法在网络不良照片识别中的方法研究
摘 要:
随着科技时代的进步,互联网技术在计算机的广泛使用的给人提供便利的同时,也萌发了很多危害。人像检测技术开始于上世纪60-70时代,经过几十年的研究与应用,已经慢慢完善。但时代的进步让识别技术的要求愈来愈高,检测敏感照片是一项重要识别类工作,所以关于这种技术和理论不断地被人们所关注,渐渐成为研究热点。本文针对不良照片中的感兴趣区域的检测提出了一些新方法,改进训练弱分类器的权值方法,高效率的分辨出不良照片,督促互联网的绿色发展。
本论文研究的问题是关于Adaboost 算法的在不良照片中的检测,但关于识别与检测有许多客观的非人为的干扰因素存在,现在我们需要的是在存在众多干扰的情况下仍然有一个检测水平高,速度快的算法。这也一直是研究人员努力的方向。所以在此基础上,提出来了Adaboost算法下Haar特征用于检测色情图片。新的算法不仅可以迅速,又可以利用这种特征排除多余的干扰因素,促进了工作的顺利进展。
关键词:不良照片;敏感信息识别;人脸检测;AdaBoost;新特征;特征抽取;误检率;
Abstract:
With the rapid development of Internet technology and the progress of society, the Internet brings convenience and speed to the people, but at the same time, it also sprouts many hazards. Portrait detection technology began in the 60-70 era of the last century. After decades of research and application, it has been gradually improved. However, with the development of the times, the requirement of recognition technology is getting higher and higher. Detecting sensitive photos is an important recognition work. Therefore, people pay more attention to this technology and theory, and gradually become a research hotspot. In this paper, we propose some new methods to detect regions of interest in bad photos, improve the weight method of training weak classifiers, distinguish bad photos efficiently, and urge the green development of the Internet.
The problem of this paper is about the detection of Adaboost algorithm in bad photos, but there are many objective and non-human interference factors in recognition and detection. What we need now is a high-level and fast detection algorithm in the presence of many interference. This has always been the direction of researchers’efforts.So on this basis, Haar feature is proposed under Adaboost algorithm to detect pornographic images. The new algorithm not only can quickly, but also can use this feature to eliminate unnecessary interference factors, which promotes the smooth progress of the work.
Key words:Bad photos;Sensitive Photo Recognition;Face detection; Adaboost;New features;Feature extraction;Noise factor;
目 录
摘要…I
ABSTRACT…II
目录…IV
第一章 绪论…7
1.1 研究背景和意义…7
1.2 研究现状…8
1.3 主要研究内容与方法…9
1.4 主要工作安排及各章节内容…10
第二章 基于AdaBoost人脸检测算法的原理与研究…11
2.1 引言…11
2.1.1 Boosting算法…11
2.1.2 AdaBoost算法及其在不良照片中的应用…11
2.2 关于AdaBoost算法原理与简述…12
2.2.1 AdaBoost算法的相关流程…12
2.2.2 Adaboost算法的计算步骤…13
2.3 矩形特征与特征值的计算…14
2.4 积分图概念与计算特征值…19
第三章 增加Haar特征后的Adaboost算法…21
3.1 引言…21
3.2 关于新特征的简述与表达方法…22
3.3 梯形特征… 22
3.4 T字形特征…23
第四章 基于增加Haar特征后实验的实现与步骤…23
4.1 人体敏感部位检测平台…23
4.1.1 实验操作…23
4.1.2 图片样本库的建立…23
4.1.3 关于敏感部位的检测分类器创建与训练…24
4.1.3.1 正样本的创建…24
4.1.3.2 负样本的创建…25
4.2 分类器的训练…25
4.3 关于检测效果与总结…27
4.4 检测实现过程…28
第五章 总结与展望…28
5.1 本文研究内容总结…28
5.2 未来工作展望…29
参考文献…30
致谢…32
第一章 绪论
近年来随着互联网的接入以及人民生活质量的不断提高,网络技术水平每天以飞跃式的速度进展,带给我们方便快捷的同时,也不断带来重重危机。不良信息在网络上愈传愈烈,涉黄涉毒涉暴信息不堪入目,为网络犯罪和思想腐朽的人偷偷开了一扇门。Internet information的传播形式随着新世纪网络的迅猛发展也在不断改变,如今吸引人的表达方式越来越多(图片、视频等)不断刺激着人的眼球,而不再是简简单单通过文字了解信息。互联网的前卫、高端以及便捷性使我们爱不释手,但也要思考如何面对其两面性。稍有不慎糟粕的内容就会乘人不注意进入大众视线,互联网上不健康内容入侵大脑,侵害人们的思想。甚至,这些内容对还未成年的人具有的吸引力和危害是不可想象的。
1.1 背景和意义
照片识别是一种图像检测技术,指在该图像中确定目标人物的位置、姿势、肤色分布的过程,人物识别作为信息处理中的一项至关重要的技术,这些年来在新技术时代中得到快速的发展。识别人像已经变成了一个重要的课题,且这种生物识别应用不断发展,对目标要求也就越来越高。在这样的发展形势下,人脸检测技术逐渐人像识别中瓜分出来,成为一项独立的技术。但单方面的技术不能很好的解决眼下多重的问题。因此,学科交叉成为新的趋势,在多方面有着重要的应用价值,这使得此类研究备受关注。具体表现为:
人脸:人脸属于柔性,模式多样,呈现不同的表情时都会使得面部的每一块皮肤发生一定的改变,哭笑等特殊表情都会使得人脸面部形状改变,并且因为人脸会发生一定角度的旋转,这使得采集到的图像与训练样本中的图像相比有差距或者会造成部分特征的丢失。所以,采用某种单一的检测方法很难准确的将众多的目标图像中把所有需要的检测的特征检测出来。姿势:人体具有随机性较强,走、跑、蹲、趴等姿势变化性强,差距大。因此图像中姿势会直接影响检测效果。
外界因素:图像在拍摄角度及外部光线的影响下,可以是正视图,也可以左视图或者是俯视图。采集设备在对图像进行采集的过程往往采集的数据可能与想要的图像产生一定的偏差。主要是因为采集的过程中会受相似轮廓,相似物质等干扰因素的影响。同时脸部可能会存在一些饰物如墨镜、口罩等。这些非必要的饰品对人脸特征的关键部位都造成了影响,进而影响了准确进行图像检测的理想化。
如今社会,在许多公共工作中,比如身份查验、人员核实、公安视频监控、通过录像挖掘犯罪真相等,识别检测任务重中之重,由于检测过程中,存在各种主观或者客观不理想因素的存在,使得在实际工作中的检测并不容易。
1.2 研究现状
识别技术出现在上世纪早期,受到研究人员的关注。模式识别对于研究生活中的某些现象或者识别与检测所需的图像中特征有着突出贡献:SVM、贝叶斯分类器以及Boosting分类等分类器具有优秀的技术基础,这些较为成熟的分类器也在科学家当中炙手可热,得到了广泛应用。然而不同的分类器针对相同的内容可能得到不同的结果,并且很难找到只针对人脸识别的分类器。早时候的人脸检测的对象多数是对于无背景或简单背景的图像,因为比较容易实现,所以在当时人脸检测相关的技术没有引起足够的重视,在研究人员的努力下,经过十几年后的人脸检测方法已经渐渐趋于成熟,并伴随如今新鲜事物事物的更新换代,人民对安全问题关注程度不断提高,个人信息安全防范意识逐渐增强,识别系统开始在日常生活的方方面面中大范围使用。然而,时代的飞速发展,对于技术水平已经远远不能满足当下的社会环境,因此探索复杂条件下的人脸检测问题的研究者越发的多了起来。
在国内关于研究人脸检测的机构有:目前在中国对人脸进行检测的研究的比较多的主要有中科院研究所、科技院研究所、自动化研究所等,同时随着犯罪侦查的需要,以及企业管理等的需要,目前研究该检测技术的研究机构也逐渐上升在国外的一些研究对得比较深入的研究所主要有美国国防部成立的FERET项目、麻省理工大学的AI实验室等,因这些项目比较涉密与特殊,此类研究美国政府、军警方及大型企业投入了大量关注与支持还受到金额资助。众多集体共同努力下,此技术领域不断进步,并结出丰硕的果实,才涌现出一些应用到解决人脸检测的实际方法。
1.3 主要研究内容与方法
人像识别技术就是在给定数据(图像或视频)中,找到研究人员在计算机中设置的研究所需的目标特征,并在这些输入数据中将目标特征分割出来,通过计算机进行分类,确定人脸位置,实现被检测人脸的身份解释,阐述这一视觉研究。这一技术在处理图像、检测目标中发挥着巨大作用。也因此,吸引科学家们的注意,不断改变方法改进措施,为计算机视觉技术打下坚实基础。人体对于不同的姿态和不同的光照条件,所获得的感兴趣区域也是不同的,造成所需目标也存在或大或小的差异。因此,缩小差异并更加准确进行人像特征的提取,身份的识别,依然任重而道远。
人脸检测的检测方法大致可以分为以下四类。
基于知识的方法
此方法事先把脸部特征作为规则基础输入到数据库内,然后将数据中的这些区域特征用来描述和匹配与被检测区域之间的关系。因为人脸上的这些器官特征容易被描述,比如眼睛鼻子的数量,相对位置。确定好事先预备的数据库,再将被检测的特征提取出来,这样轻而易举的就能在海量图片中分类出目标图片和无效图片。这样的方法虽然快捷,但人脸变化莫测,可能因为化妆、受伤或故意遮挡等原因造成误检,错失我们所需的资料。再者,将人脸的所有情况罗列出来作为我们所需的数据库,是一项是过于理想化的工作,不仅困难而且不容易实现,无法时时刻刻捕捉并输入脸部特征的变化。这种方法过于陈旧,完成的准确率也较低。
基于特征不变性的方法
人们能在图片中轻易的分辨出人脸与物,必然是他们之间存在巨大区别,人有人的生理构造,物有物的结构特征。比如人有皮肤、有脸部的轮廓特征,鼻梁位于人脸中央,眼对称等。这些关于人脸的重要信息,才能轻而易举的与外物相互区别。而且,皮肤也是一项具体特征,利用人体不同的肤色可以在彩色照片中毫不费力地发现人脸并初步判断人种属性。通过皮肤与人脸特征的双重考验,使检测的结果初步得到很好的效果,检测人脸的成功率也大幅增长。但还有一个因素,在图片中有遮挡物或噪点等缺点时,又会影响人脸检测效果。如果在一定的约束条件下,这种方法的检测准确率还是相对比较高的。
基于模版匹配的方法
这种方法是通过很多的人脸图片和无效图片作为训练集,得到样本,在被测图片中不断检索与匹配,然后与被检测成功的图片计算它们之间的系数,与之前计算机设置好的匹配值来判断,匹配值合适确定为人脸;匹配值不合适就为无效。人脸属于柔体,在现实中确定一个具有共性的人脸模版很难,在实际中,通常使用多模板进行全面检测,但效果依然不理想。人脸表情姿态影响着检测结果,虽然这类方法检测速度快,但因为不够灵活,慢慢也被淘汰。
基于外观的方法
这类方法以统计学为基础,将人脸检测分类为人脸和非人脸。然后将匹配好的预先模版一一对应,把人脸图像看作是一个高维向量,然后把人脸识别转化为高维空间中分布信号问题,但基于外观的方法一般计算量非常庞大,现在也被淘汰。
1.4 本文主要工作及章节内容安排
本文主要研究人体敏感部位的检测问题以及相关实施算法。分别针对不良照片中的敏感器官(乳房和女性生殖器)进行训练分类器,本文是在大量的学习国内外的有关该检测技术的基础上进行的研究。本文主要从以下几个方面进行研究:
第一章:先对人脸检测技术的研究背景开始,然后对人脸检测技术在国内的一个研究现状进项阐述。对于此相关的技术进行讨论,最后提出改进。
第二章:介绍 对什么是Adaboost 算法进行讲述,同时对该算法的基本原理以及在不良照片中的应用进行一定的解释。
第三章:介绍在原有的Adaboost算法基础上,把对人体的敏感部位的图片检测技术haar特征也纳入到其中,并对新特征采用累积分布图算法。
第四章:描述本文的实验阶段,包括两大器官图片的准备与实施阶段。
第五章:总结与展望。
参考文献。
致谢。
第2章 Adaboost人脸检测
2.1 引言
Adaboost是一种集成学习计算方法,而这个方法是归属于Boosting算法,是Boosting算法当中的一个子元素,Boosting有着可信赖的理论作为Adaboost的基础,在研究道路上得到实践应用。这种算法将弱分类器集合在叠加起来,组成一个强分类器用于检测人脸,为后续的深入学习提供新思路。在实践中得到了广泛的应用。本章将介绍这种方法的历史,分析它的算法并了解它的算法流程。
2.1.1 boosting算法
Adaboost算法就是在Boosting算法的基础上进行的深入研究。而在进行该研究之前我们应该多掌握一些与Boosting算法息息相关的建模思想。
Boosting由Kearns和Valiant最先提出的。比如我们猜测一件事情,如果它的概率大于50%,那可以认定为强学习器,如果概率小于50%,那么它将遗憾的归为弱分类器。但在学习中,与我们想象的恰好相反,强分类器不易得到,而弱分类器轻而易举地被获取,那么为什么不将弱分类器集合起来,提升成我们所需的强学习器呢?介于上述的原因,提升并强化学习器的想法就应运而生。1995年,Freund不断组合,反复训练,终于在原有的Boosting方法的基础上研究出了一种更加优化的计算方法就是——Adaboost(adaptive boost的缩写)算法。
2.1.2 Adaboost算法及其在不良照片中的应用
人工与智能技术的研究重点已然涵盖了分类器的训练及选择方式。当我们对需要研究的对象使用Adaboost算法进行层层筛选时,Adaboost会建立一个空间框架,在这个空间框架中你可以采取多种方法进行分类器的构建,向上述所说的,我们也可以将弱分类器作为子分类器进行构建。在每次训练完成后观察整个动态,根据反馈,组织调整其适应能力和权值分布,正确分类则减轻,错误则加重。但这样会更加依赖弱分类器,从而提升对错分样本的关注程度,造成训练时间过长。
实际上,现实环境中各种被检测的目标姿势千变万化,形态又迥异。干扰因素又为检测目标造成了很多麻烦,很难理想化的检测出目标。一种方法难以取得多种检测目的,色情图片因为隐蔽性和昏暗的光线原因,检测出满意的结果更是难上加难。Adaboost算法具有较好的自适应性,实时性很好,稳健的条件下速度又快,对检测人脸领域有深刻的影响力。主要做法是采用积分图的方式计算出目标特征,(也叫做Haar特征),Haar特征具有不同的模版可供与被检测目标匹配,然后输入训练数据开始进行样本的训练,每轮训练后选择出一个弱分类器,层层筛选,最后将筛选出来的m个弱分类器进行集合,通过层层叠加的方式进行组合从而形成强分类器,实现最终分类的检测。后来,Keren等科学家有把这些最终分类器结合在一起,就可以迅速检测出图像中的目标。当然,随着训练器的不断加强和对此研究的深入,此种算法仍有很大的提升空间。
2.2 Adaboost算法原理
Adaboost 算法同时也叫作自适应增强算法。这个计算方法名称的由来主要是因为:通过训练这些样本后获得有差异性的结果,前面一个分类器被多次错误分类后样本的权值会增大,然后将这些学习结果组合,需要重新调整样本权重的,接下来可以重点学习。每一轮训练后加入一个弱的分类器,直到达到计算机最后预定的最小错误率,才确认它们成为一个强分类器。为构造这个强的学习算法,选定弱学习算法后,不断训练和提升。将这些集合起来,构成我们最终需要的更强的学习算法。
2.2.1 Adaboost算法流程

图2.1 Adaboost算法流程
2.2.2 算法的计算步骤
首先对样本集进行选定:(),i=1,2,…n。其中X=(),是预测需要研究的样本量,={-1,1}表示的是两个不同的类的划分。
然后进行初始化设置:让每一个数值在进行测量计算之前在权重方面都不会有差异。即:,同时弱分类器进行选定,将进行了初始化设置的样本权重进行测试选定,然后再返回过去对样本进行测试。对进行错误检测的样本进行权重的叠加,在将该错误样本用于下一轮的测试。
接下来我们需要对样本的权重进行一定的更新:设t设置为要迭代的轮数,t=1,2,…T。算法然后再选取一个参数值a用于对弱分类器进行评估的一个实数,对于后面的一种分类结果来看,起初Freund和Schapire对定义为:
样本权重的更新:
公式中的是表示的是正则化因子,
预测公式
根据上述预测公式的正负值区分实现对第i个检测样本的归类。
2.3 特征与特征值的计算
Adaboost算法主要是通过积分图的图像对特征值进行提取,而这个提取特征的积分图又称之为Haar特征,Haar特征主要用于反映图像的灰度变化。如果想要通过Haar特征对Adaboost分类器进行进一步的分析,首先我们就需要对haar的特征做进一步的了解和深入。Haar特征中黑白区域面积比始终保持不变。又因为Haar特征具有优秀的适应性能,所以通过提取被测目标后与Haar分类器进行训练,选出最适合的Haar特征来构建训练集中的弱分类器,不断优化后用来检测人脸。

图2.2 特征提取的流程
本文中,人脸特征的提取采用了Haar特征来描述分布特征。Haar不仅结构简单明了,算法也十分简便,而且在训练时只需要将被测目标与选取相适应的Haar特征相互匹配,转换后即可以进行目标检测。特征图均由矩形组合而成,并采用黑白矩形块的面积和相对位置来反映人脸特征的差异。我们将用以下的(a)(b)(c)(d)(e)这五种haar图来构建了一个Adaboost分类器。

图2.3 Haar特征原型示意图
本文中随机运用了五种特征图用来描绘人脸器官中的某些特征,由下图可知,眼睛是黑色的,与皮肤颜色正好相反,选用Haar特征图中的图(b)来与之匹配;嘴巴和鼻子突出脸部平面,且嘴唇颜色和鼻梁颜色自然比脸颊皮肤颜色要深,选用Haar特征图中的图(c)来与该特征匹配。使用Haar特征图,能够清晰明了的描述特征,并且速度更快的检测目标。

图2.4 Haar特征与人脸匹配图
由于眼睛和脸颊的颜色差异我们选择了Haar特征图中的某个特征图匹配,而且眼睛部分的像素小于了脸部区域的像素,根据这一相对位置和面积关系,就可以对人脸检测进行进一步的研究。
在一个2424的检测器当中,我们如果需要将弱分类器叠加成一个可以实现矩形特征数量超过160,000个的强分类器。那么矩形特征的选择适合°将是该研究中的重点。
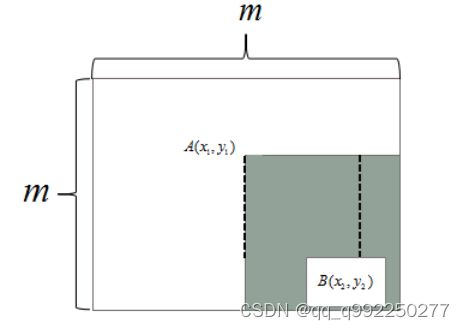
图2.5 特征值的区域和计算范围
以上图的检测器为例,边长分别是m,m。特征值计算如下:对于这个上图中的子窗口,确定矩形左上顶点A()和右下顶点B(),即可计算。
这样就定位了一个满足条件的矩形:
确定A():{1,2,m-s,m-s+1},{1,2,m-t,m-t+1};
确定A点后, B点只能在阴影内包括边缘取值,因此有:
其中p=[],q=[]。并且知道
根据上述数据得出,在mm子窗口中,能够满足(s,t)条件的矩形数量框如下所示:
=
=
=
下图显示的是特征模板与对应的条件图

图2.6特征模版与对应条件
5种特征模版的特征总数量,即:
特别地,由于特征模版两两之间具有关联性(旋转对称),则:
具体计算其总数:


图2.7 特征模版与计算总量
在不同的子窗口大小内,特征的总数量:
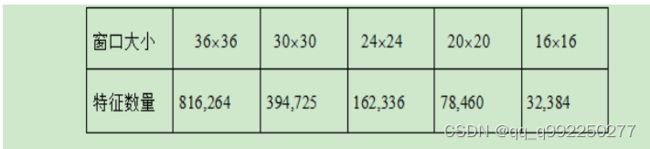
图2.8 窗口大小与特征数量的关系
2.4 积分图概念与计算特征值
积分图的概念:通过上节内容,我们已初步算出了矩形特征及特征数量,下一步需要对要矩形特征的值进行计算。积分图计算方法原理如下:
其中ii(x,y)表示的是积分图,i(x,y)表示原始图像。在下图中,A(x,y)表示点(x,y)的积分图;s(x,y)表示点(x,y)的y方向的所有原始图像之和。

图2.9 积分图求特征的值
所以,积分图也可通过下面的算法进行表示:
利用积分图计算特征值
一在区域端点积分图中,我们可以在x轴与y轴形成的区域上进行点积分图计算,如下图所示:

图2.10区域端点积分图的计算
其中,在坐标上A对应的表示区域的像素值由以ii(1)表示,在坐标上A+B对应的表示区域的像素值由以ii(2)表示,坐标上A+C对应的表示区域的像素值由以ii(3)表示,在坐标上A+B+C+D对应的表示区域的像素值由以ii(4)表示,而:
区域D的像素值= ii(4)- ii(2)- ii(3)+ ii(1)
通过计算得到区域D的像素值。那么下面的图表就用来实现对D区域的特征值的计算。如图所示:

图2.11 利用积分图计算区域的特征值
区域A的像素值=ii(5) -ii(2)-ii(4)+ ii(1)
区域B的像素值=ii(6) -ii(5)-ii(3)+ ii(2)
该矩形特征的特征值,为区域A-区域B。
ii(5)+ii(1)-ii(2)-ii(4)-[ii(6)+ii(2)-ii(5)-ii(3)]
=[ii(5)-ii(4)]+[ii(3)-ii(2)]+[ii(2)-ii(1)]+[ii(6)-ii(5)]
第三章 增加Haar特征后的Adaboost算法
3.1 引言
说到色情图片,使人们不禁想到人的肉体。肉体与其器官构成了一个人体固定状态。除非外界因素的干扰,相比于其他,人体器官具有不易改变性能,检测目标器官时,也更加稳定。因此,在本章中将人体某些涉及色情的感兴趣器官(乳房和女性生殖器)定义为人体躯干部位,提出基于器官检测的不良图片识别方法。
之前,将人体皮肤作为识别色情照片的特征,虽然能分辨出正常照片与裸露照片,但众所周知,许多内衣模特或是泳池内游泳的人也裸露出较多的皮肤区域以至于被检测成不良照片,这种方法虽然快捷,但效果并不好。根据实际情况,下一步应该将人体器官作为识别有效图片的有效特征,这种特征显著又容易被检测到。为了更容易的提取到关键特征,以及给后期的积分图计算提供方便,所以匹配的特征都是矩形的,研究人员提出了一种基于矩形特征的Haar-like特征。能否对黄色图片进行识别和检测,主要在于对特征的选取;自从Haar-like检测特征的使用后,在检测速度和识别计算上都得到了大幅度的提高。
3.2 关于新特征的简述与表达方法
人体属于非刚性体,姿态随时变化,色情照片更是如此。那么根据色情照片的特殊性,引入了基于Haar-like的四个新特征。互联网上非法不良照片上的裸体姿态各异,而引入的新特征都是表述一个局部特征的。如下:表示女性生殖器上的基于AdaBoost算法中的Haar特征

图3.1 女性生殖器上新特征
能够对识别到AdaBoost算法中Haar-like的新特征

图3.2 女性生殖器上的矩形特征
3.3 梯形特征
女性的身体处于躺下或倾斜时,一般的Haar特征无法用来匹配这种姿势。由此引入梯形特征,具体到Adaboost算法中的Haar-like新特征如图

图3.3 女性生殖器上的梯形特征
3.4 T字形特征
女性站立时阴毛相似三角形,引入 T形特征描述。在Adaboost算法的Haar-like新特征如下:

图3.4 女性生殖器上的T形特征
第4章 基于增加Haar特征后实验的实现与步骤
haar训练器对样本的选取上主要需要两种样本,即正样本和负样本。在进行乳房实验过程中我们把正样本划分成是含乳房图片,把负样本划分成是不含乳房的图片。在女性生殖器测试当中,正样本为含女性生殖器图片,负样本为其他图片。
4.1 人体敏感部位检测平台
4.1.1 实验操作
我们将会使用Windows 8操作系统中的C计算机语言对人体敏感部位进行检测。在这个检测过程中我们将使用Visual C++和Open CV,通过这两个编程工具,训练出我们所需要的相应的分类器,将最终检测到的结果记录并汇总结果。
4.1.2 图片样本库的建立
乳房检测实验中,在互联网上下载关于乳房的图片,正样本上储存的主要是大概有100多张只显示女性乳房的图片;负样本则是一些和乳房相似但不是女性乳房的干扰图片;将这些图片统一尺寸为3020。负样本无其他要求,但必须要进行灰度化处理。
女性生殖器检测实验中,正样本是在互联网上提取的100张仅含女性生殖器的图片,尺寸大小统一设置为 3040;设置之后还必须实行灰度化处理。
4.1.3 关于敏感部位的检测分类器创建与训练
4.1.3.1 正样本的创建
乳房检测实验:
(归一化尺寸):首先我们可以通过p图或者魔方摄影等软件对正样本进行一定的裁剪,裁剪到指定的目标大小:
1.将数据库中含有乳房的100张照片,储存到一个叫做positive_samples的文件夹
2.重新形成一个叫做 posdata.dat的文件索引目录。

图4.1 dos命令的执行
生成文件posdata.dat。然后,用txt的将文本的形式通过 “pgm”工具全部转换成“pgm 1 0 0 30 20”。替换之后的正样本便如下面所显示的。
95.bmp 1 1 1 30 20
96.bmp 1 1 1 30 20
97.bmp 1 1 1 30 20
98.bmp 1 1 1 30 20
99.bmp 1 1 1 30 20
将显示的文件直接放在正样本 posdata路径(即正样本路径)下,可以减少工作流程,这样就不用在前面加上相对路径。按照相同的处理模式我们对负样本也可以采取相同的处理模式,用txt的将文本的形式通过 “bgm”工具全部转换成“bgm 1 0 0 30 20”因计算机的特征值储存路径不同使得正样本需要用vec文件。
女性生殖器检测实验:在互联网上寻找一些含有女性生殖器的色情照片和正常的图片,作为实验的样本。通过被训练得出的分类器,分别选择本文中提到的基于Adaboost算法的新特征、梯形特征、T形特征、和Haar-like特征对待测图片进行检测,方法与乳房训练一样,为了作出对比,每个实验都要将样本数目保持一致,大小一致,一定程度上满足检测要求后进行四组对比性实验。
4.1.3.2 负样本的创建
在PASCAL VOC库里的图片数据集,选取了100张正常图片作为负样本。将这些数据放在\negitive_samples文件夹下。具体操作流程首先先点击Dos命令控制符然后进入到图片目录,然后将图片放在“D:\铁道警察学院毕业论文\样本\乳房\初次负样本训练”下,然后返回电脑的显示屏上点击开始菜单打开运行程序。然后运行程序输入框中输入cmd点击确定,然后再 打开 DOS 窗口,输入 d:然后再回车,再输入 cd D:\铁道警察学院毕业论文\样本\乳房\初次负样本训练,进入图片路径。之后再输入 dir /b > negdata.dat,则会在图片路径下生成新的文件,将文件打开之后进入可读模式并将最后一行的 negdata.dat 删除,这样负样本文件就产生了。

图4.2 dos命令的执行
4.2 分类器的训练
样本进行创建之后,接下来就是通过弱分类器进行层层训练,选出opencv_haartraining.exe需要的参数:

图4.3 opencv_haartraining.exe需要的参数
对样本进行创建之后,接下来就是通过弱分类器进行层层训练,而这整个过程都需要由修改后的 haartraining程序来帮助实现。该程序源码主要window系统当中的由Open CV进行修改并传递到可供执行的Open CV安装目录下的一个名称叫做bin的子目录下。文件名叫做F:\乳房训练集正样本>’’C:\Program Files\Open CV\bin\haartraining.exe’’-data data\cascade -vec data\pos.vec -bg negdata\negdata.dat -npos 100 -nneg 100 -mem 100 -sym 0 -mode ALL -w 30 -h 20。
因为在不良照片中敏感器官可能有不同的姿态,为了提高检测率,我们选用的Haar特征采用不对称性,cascade 目录下生成的强分类器:

图4.3 形成的cascade目录
其中每个文件夹里面都含有不定数量的弱分类器。经过训练后,可以得到一个 XML格式的分类器,打开之后:
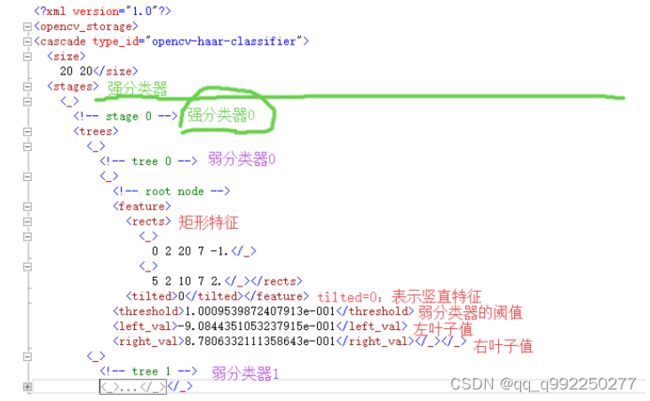
图4.4 XML格式的分类器
4.3 关于检测效果与总结
在实际工作中,这种过于理想化的效果是不存在的。为了进一步验证新添加的特征与原始特征的效果,又在网络上随机寻找一下相关图片和正常图片进行新一轮的检测。情况如下:
乳房分类器对比表
检测率 误检率
原始特征 86.5% 42.8%
新特征 90.7% 37.6%
图4.5 乳房分类器的对比图
女性生殖器训练分类器
检测率 误检率
原始特征 70.5% 52.6%
新特征 75.7% 47.2%
T形特征 78.4% 43.8%
梯形特征 76.6% 72.7%
图4.6 女性生殖器的训练分类器
4.4 检测实现过程
(1)使用VC++程序(因为可以构建分类器,导入本文中实验的两个分类器)进行检测。本程序中主要步骤如下:首先使用cv Haar Detect Objects 函数进行人体敏感部位的检测。然后使用函数cv Haar Detect Objects()针对某个目标训练的分类器在图像中寻找包含了这个目标的区域。
(2)把检测到的实验矩形框的坐标位置记录下来,并输入指定位置。
(3)使用VC++程序导入被检测结束的图片,进行检测率的分析,并对以上信息进行汇总,得出结论。
第五章 总结与展望
5.1 本文研究内容总结
在这个信息大爆炸的世界里,在明暗交错的互联网上,带来的便利不可估量,带来的危害也不容小觑。色情、黄色、暴力、赌博等新兴信息毒品悄悄蔓延,不良信息的识别检测也迫在眉睫。在今天,不良照片的监控与实时过滤技术已经成为一个重大研究方向。人类在不断的推动着科学的发展,从最初的识别人脸,身份,到如今在互联网上检测敏感照片,不断面临新的机遇和挑战。本文基于Adaboost算法在识别不良照片的研究中,为了能更加高效、高质量的检测出不良照片,提高检测目标的成功率,加入了新的识别特征,对如何有效的提取色情图片中的特征,进行深入的研究,并且在处于干扰情况下通过人体躯干识别出不良照片。但对于训练速度与时间也是一个急于解决的问题,这也是接下来的研究方向。
5.2 未来工作展望
本文中由于自身的知识能力有限,和对文献资料研究的范围受局限,导致对该算法在研究上比较粗浅,不够深入。在研究和分析算法上不能够做到全面性。而只是停留在在Adaboost算法中添加了Haar-like新特征,并修改了部分训练分类的方法,导致加进去了一下无效信息。因此希望未来能够找到一个更高效的的算法进行识别与检测,以减少外部因素的干扰。
对于在本文中出现的误检,我应该及时反思,在之后研究中寻找更加具有代表性的特征和更高效的算法来运用,思考不良照片中更能准确识别出来的课题,并进一步验证我的想法,正确提高正确率,使关于图像识别的研究一步步向前。
参考文献
[1]嵌入式人脸识别系统设计与实现[J]. 李昌湘,白创. 智能计算机与应用. 2018(03)
[2]融合YCbCr肤色模型与改进的Adaboost算法的人脸检测[J]. 崔鹏,燕天天. 哈尔滨理工大学学报. 2018(02)
[3]基于ZYNQ的Retinex实时图像去雾[J]. 董梦莎,张尤赛,王亚军. 电子技术应用. 2018(04)
[4]基于改进Adaboost特征检测的感知哈希跟踪算法[J]. 齐苏敏,隋煜舜. 通信技术. 2017(03)
[5]基于YCbCr肤色检测与AdaBoost联级算法的嘴部特征定位[J]. 田原嫄,姚萌萌,潘敏凯,郭海涛. 计算机应用研究. 2017(03)
[6]基于AdaBoost算法和色彩信息的脸部特征定位[J]. 宁娟,朱敏,戴李君. 计算机应用与软件. 2016(05)
[7]一种基于AdaBoost的人脸检测算法[J]. 刘王胜,冯瑞. 计算机工程与应用. 2016(11)
[8]一种基于改进的AdaBoost、肤色和2DPCA的人脸检测方法[J]. 裴珍,许忠仁. 电子设计工程. 2014(08)
[9]基于ZYNQ的稠密光流法软硬件协同处理[J]. 王芝斌,阳文敏,张圆蒲,柴志雷. 计算机工程与应用. 2014(18)
致谢
即将结束四年的大学生活,很是不舍,学习是需要长期积累的,什么都不能一蹴而就,正如这次毕业设计一样,需要查阅整合资料才能完成,所以无论在工作还是生活中都得不断地去积累知识,努力提高自己的知识储备和综合素质。
因为校园中所学都是理论知识,缺失实践验证,在设计过程中无可避免的出现很多难以理解的问题或者欠缺考虑的地方,若是缺少了导师的努力指导和勤加督促,则单单靠自己恐怕难以完成设计。在这里我要对陆朱卫老师表达诚挚的谢意,即便老师业务繁忙,但是在我的整个毕业的过程中,一种关注着我的工作进度,在需要的时候予以指导,在我的错误提出改进建议,这让我十分敬佩老师的专业水平,老师严谨的研究态度也积极地影响我今后的学习和工作。虽然这四年来的学习生涯很忙碌,但收获颇丰,也为大学生活画上了个完美的句号。
最后感恩来到这里,认识到一群友善的老师和同学,也感谢学院对我的大力栽培!