基于深度学习的图像去雾系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
随着计算机视觉和图像处理技术的不断发展,图像去雾成为了一个备受关注的研究领域。在自然环境中,由于大气中的颗粒物和水汽的存在,图像中的目标物体往往会被雾霾所遮挡,导致图像质量下降,视觉效果模糊。因此,图像去雾技术的研究具有重要的理论和实际意义。
首先,图像去雾技术在军事和安全领域具有重要的应用价值。在军事侦察和监控中,由于恶劣的天气条件或远距离观测,图像质量常常受到雾霾的影响,使得目标物体无法清晰可见。通过研究和开发基于深度学习的图像去雾系统,可以提高图像的清晰度和细节,从而提高军事侦察和监控的效果。
其次,图像去雾技术在交通和安全领域也具有重要的应用前景。在交通监控和自动驾驶系统中,清晰的图像对于准确识别和判断道路和交通状况至关重要。然而,由于雾霾的存在,图像质量下降,给交通监控和自动驾驶系统带来了困难。通过研究和开发基于深度学习的图像去雾系统,可以提高交通监控和自动驾驶系统的可靠性和安全性。
此外,图像去雾技术在航空航天、环境监测和气象预测等领域也具有广泛的应用。在航空航天领域,由于大气层的存在,航天器拍摄的图像常常受到雾霾的影响,影响图像的质量和解译。通过研究和开发基于深度学习的图像去雾系统,可以提高航空航天图像的清晰度和解译能力。在环境监测和气象预测领域,通过去除图像中的雾霾,可以提高对环境和气象状况的准确监测和预测能力。
总之,基于深度学习的图像去雾系统具有广泛的应用前景和重要的研究意义。通过研究和开发高效准确的图像去雾算法,可以提高图像质量,改善视觉效果,进一步推动计算机视觉和图像处理技术的发展。此外,图像去雾技术的应用还可以带来许多实际的经济和社会效益,例如提高军事侦察和监控的效果,提高交通监控和自动驾驶系统的可靠性和安全性,提高航空航天图像的解译能力,提高环境监测和气象预测的准确性等。因此,基于深度学习的图像去雾系统的研究具有重要的现实意义和应用价值。
2.图片演示
3.视频演示
基于深度学习的图像去雾系统_哔哩哔哩_bilibili
4.图像去雾相关理论概述
大气散射模型
在1.2节中,提到大气散射模型被广泛地应用于传统的去雾方法,以及早期的深度学习去雾算法也基于该模型估计中间参数来实现去雾。
在理想天气下,环境中的物体反射的光线传播到图像采集设备时,没有受到空气中悬浮介质(如粉尘、水珠等)的影响,此时采集到的图像没有任何信息损失。然而在现实场景中,大气中存在着各种各类的悬浮颗粒,如雾霾颗粒,物体反射的光线在到达成像系统时,受到不透光的介质干扰,引起光线衰减或者散射的现象,导致采集的图像退化。
针对于上述问题,研究者McCartney’l在1976年提出了大气散射模型,该模型从数学角度,简易概况了恶劣天气下设备成像过程。模型数学表达式如公式:
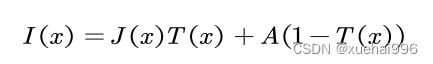
I代表观测到的雾图,J表示无雾图像,A代表大气光照强度,T(z)指的是介质传输图,x是像素位置。介质传输图可以具体表示为T(z)=e-Ba),其中3表示大气衰减系数,d指的是场景深度。根据大气散射模型,如果能准确地估计大气光照A和介质传输图T(az),就能通过公式(2-1)直接恢复无雾图像。
深度卷积神经网络
深度学习(Deep Learning,DL)作为机器学习方法的一个重要分支,古往今来,已经有几十年的发展历程。随着科技的发展,大规模数据集的逐渐可用以及高计算力的设备的普及力增强,深度学习方法迎来了爆发性的发展。在计算机视觉领域,深度神经网络在提取特征并进行识别、检测等任务的表现,展现了巨大的优越性,逐步取代了传统的手工方法。因此,本文基于现有深度学习技术的基础,开展图像去雾算法相关研究。
深度卷积神经网络(Deep Convolutional Neural Network, DCNN)最初是一种专为图像处理任务而设计的前馈深度学习模型,随着广泛应用,在自然语言处理等任务中也取得了巨大的成功。其中具有代表性的是,在1998年,LetNet-5结构的提出在手写数字识别任务中取得了不错的效果,同时奠定了卷积神经网络的发展基础。相比于传统的多元感知机,深度卷积神经网络以更深层的提取特征能力展现出更大的优势。
卷积层
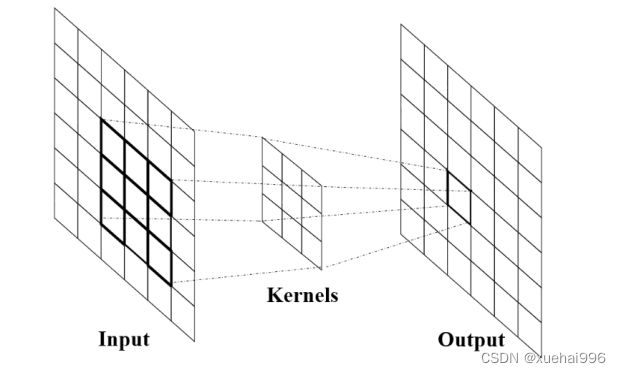
卷积层(Convolutional Layer)是深度卷积神经网络中最核心的模块层,主要包含多维度卷积核(滤波器)和偏置项。卷积层能够对输入的三维数据中提取特征并处理。在卷积操作中,卷积核的参数是共享的,这意味着所有的输入局部区域都使用相同的参数进行计算,从而大大减少了需要学习的参数数量。卷积神经网络中,每个卷积层都包含多个卷积核,用于过滤输入像素值的子集,与核的大小相同。每个像素都乘以内核中相应的值,然后将结果相加得到一个值,以表示输出通道/特征图中的单个网格单元,即像素。这些卷积操作是一种线性变换,每个卷积都可以视为一种仿射函数。卷积核是一组小的权重参数,它们与输入数据的每个局部区域进行卷积计算,从而提取出不同的特征信息。
卷积层的输入通常是一组高维数据。例如,在计算机视觉中,通常将 RGB图像作为输入,其中包含3个通道。在卷积层中,每个卷积核都与输入数据的每个局部区域进行卷积操作,产生一个对应的特征图。例如一个3 x 3卷积核来处理高维数据,水平滑动卷积核将移动到输入数字矩阵上,从第一行开始扫描并计算特征图矩阵。
下图展示了卷积核的计算过程。
池化层
在设计神经网络的过程中,很常见地会在卷积层后面添加池化层,一次或重复地堆叠。池化层能够卷积层输出的特征图进行压缩和概括,这样可以降低网络中需要学习的参数个数和计算量。池化层通过对特征图的局部区域进行某种统计运算来提取特征的概要信息。因此,模型更关注特征的存在性而不是特征的精确位置。这使得模型对输入图像中特征位置的微小变化更加鲁棒。常见的池化层类型有平均池化层(Average pooling)、最大值池化层(Max pooling)等。
如图所示,最大值池化层从过滤器所覆盖的特征图区域中挑选出最大的元素。因此,最大值池化层的输出也是一个特征图,它包含了前一个特征图中最显著的特征。平均池化可以计算过滤器所覆盖的特征图区域中所有元素的平均值。因此,与最大值池化只保留特征图某个补丁中最显著的特征有所不同,平均池化保留了Patch中所有特征的平均水平。

激活函数
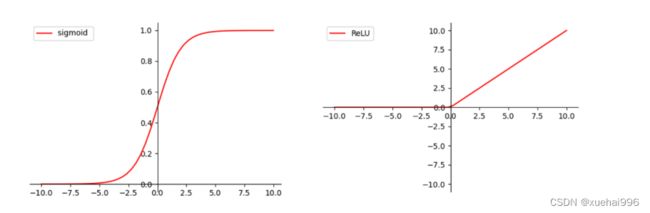
激活函数是一种数学函数,通常被用于神经网络中的每一个神经元,将输入信号转换为输出信号。激活函数的主要作用是引入非线性性质,这使得神经网络可以处理非线性的输入数据,从而提高其性能和准确性。常见的激活函数有Sigmoid、ReLU、Tanh等。图2-3展示了Sigmoid和 ReLU函数形式。
Sigmoid
Sigmoid函数,也叫 Logistic函数,是一种常见的激活函数,其定义如公式:

Sigmoid 函数的图像呈现出S形曲线,它将任意实数值映射到[0,1]的区间内,这使得它在二分类问题中非常有用。当输入值为0时,Sigmoid函数的输出值为0.5,因此,我们可以将 Sigmoid函数的输出值简单视作概率来看待。例如,在逻辑回归模型中,Sigmoid函数可以将线性模型的输出转换为一个概率值,这个概率值表示某个样本属于正类的可能性。
在神经网络中,Sigmoid函数通常被用作输出层的激活函数,也可以用作隐藏层的激活函数,但由于它存在梯度消失问题,所以在深层神经网络中往往会被其他激活函数所取代,比如ReLU函数。总的来说,Sigmoid函数是一种具有平滑性和可导性的激活函数,尤其适用于二分类问题。
5.核心代码讲解
5.1 dataset.py
class DatasetFolder(data.Dataset):
def __init__(self, root, loader, extensions, transform=None, target_transform=None):
samples = self.make_dataset(root, extensions)
if len(samples) == 0:
raise(RuntimeError("Found 0 files in subfolders of: " + root + "\n"
"Supported extensions are: " + ",".join(extensions)))
self.root = root
self.loader = loader
self.extensions = extensions
self.samples = samples
self.transform = transform
self.target_transform = target_transform
def make_dataset(self, dir, extensions):
images = []
for root, _, fnames in sorted(os.walk(dir)):
for fname in sorted(fnames):
if self.has_file_allowed_extension(fname, extensions):
path = os.path.join(root, fname)
item = (path, 0)
images.append(item)
return images
def has_file_allowed_extension(self, filename, extensions):
filename_lower = filename.lower()
return any(filename_lower.endswith(ext) for ext in extensions)
def __getitem__(self, index):
path, target = self.samples[index]
sample = self.loader(path)
if self.transform is not None:
sample = self.transform(sample)
if self.target_transform is not None:
target = self.target_transform(target)
return sample, target
def __len__(self):
return len(self.samples)
def __repr__(self):
fmt_str = 'Dataset ' + self.__class__.__name__ + '\n'
fmt_str += ' Number of datapoints: {}\n'.format(self.__len__())
fmt_str += ' Root Location: {}\n'.format(self.root)
tmp = ' Transforms (if any): '
fmt_str += '{0}{1}\n'.format(tmp, self.transform.__repr__().replace('\n', '\n' + ' ' * len(tmp)))
tmp = ' Target Transforms (if any): '
fmt_str += '{0}{1}'.format(tmp, self.target_transform.__repr__().replace('\n', '\n' + ' ' * len(tmp)))
return fmt_str
IMG_EXTENSIONS = ['.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif']
def pil_loader(path):
with open(path, 'rb') as f:
img = Image.open(f)
return img.convert('RGB')
def default_loader(path):
return pil_loader(path)
class ImageFolder(DatasetFolder):
def __init__(self, root, transform=None, target_transform=None, loader=default_loader):
super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS, transform=transform, target_transform=target_transform)
self.imgs = self.samples
该程序文件是一个用于处理数据集的工具文件,主要包含以下几个部分:
-
导入必要的库:导入了torch.utils.data和PIL.Image库,用于数据集的处理和图像的读取。
-
函数has_file_allowed_extension:用于检查文件是否是允许的扩展名。接受一个文件名和扩展名列表作为参数,返回一个布尔值。
-
函数find_classes:用于查找数据集中的类别。接受一个目录路径作为参数,返回类别列表和类别到索引的映射字典。
-
函数make_dataset:用于创建数据集。接受一个目录路径和扩展名列表作为参数,返回一个包含图像路径和类别索引的列表。
-
类DatasetFolder:继承自torch.utils.data.Dataset类,用于表示数据集。接受数据集的根目录路径、图像加载器、扩展名列表、数据变换和目标变换作为参数。实现了__getitem__和__len__方法,用于获取数据集中的样本和样本数量。
-
常量IMG_EXTENSIONS:包含了支持的图像扩展名列表。
-
函数pil_loader:用于使用PIL库加载图像。接受图像路径作为参数,返回一个RGB格式的图像。
-
函数default_loader:默认的图像加载器,调用pil_loader函数加载图像。
-
类ImageFolder:继承自DatasetFolder类,用于表示图像数据集。接受数据集的根目录路径、数据变换、目标变换和图像加载器作为参数。初始化时调用父类的构造函数,并将IMG_EXTENSIONS作为扩展名列表传递给父类。
5.2 data_utils.py
class ImagePairFromFolders(Dataset):
def __init__(self, dataset_dirs, transform):
super(ImagePairFromFolders, self).__init__()
assert len(dataset_dirs) > 0
self.image_filenames = [sorted([join(root, x) for x in listdir(root) if is_image_file(x)]) for root in dataset_dirs]
# check file exists
for l in self.image_filenames:
for f in l:
assert isfile(f)
self.transform = transform
def __getitem__(self, index):
images = [Image.open(filenames[index]) for filenames in self.image_filenames]
if len(images) == 1:
return self.transform(images[0])
else:
seed = random.randint(0, 2**32)
l_image = []
for x in images:
random.seed(seed)
l_image += [self.transform(x)]
return l_image
def __len__(self):
return len(self.image_filenames[0])
class UnNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
out = tensor.new(*tensor.size())
for z in range(out.shape[1]):
out[:,z,:,:] = tensor[:,z,:,:] * self.std[z] + self.mean[z]
return out
def __repr__(self):
return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std)
unnormalize = UnNormalize(**channel_stats)
class SubsetSampler(Sampler):
def __init__(self, indices, num_samples=None, randperm=False, replacement=False, weights=None):
self.indices = indices
self.num_samples = len(indices) if num_samples is None else num_samples
self.randperm = randperm
self.replacement = replacement
if weights is None:
self.weights = torch.ones((len(self.indices),), dtype=torch.double)
else:
self.weights = torch.tensor(weights, dtype=torch.double)
def __iter__(self):
if (self.num_samples == len(self.indices)) and (not self.randperm):
# SubsetSequentialSampler
return (self.indices[i] for i in range(len(self.indices)))
elif self.randperm and (not self.replacement):
# SubsetRandomSampler
return (self.indices[i] for i in torch.randperm(len(self.indices)))
elif self.randperm and self.replacement:
return (self.indices[i] for i in torch.multinomial(self.weights, self.num_samples, self.replacement))
else:
raise NotImplementedError
def __len__(self):
return self.num_samples
class MyRandomCrop(object):
"""Crop the given PIL Image at a random location.
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made.
"""
def __init__(self, size, center_crop=False):
if isinstance(size, numbers.Number):
self.size = (int(size), int(size))
else:
self.size = size
self.center_crop = center_crop
@staticmethod
def get_params(img, output_size):
"""Get parameters for ``crop`` for a random crop.
Args:
img (PIL Image): Image to be cropped.
output_size (tuple): Expected output size of the crop.
Returns:
tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
"""
w, h = img.size
crop_ratio = min(float(h)/output_size[0], float(w)/output_size[1])
th, tw = round(crop_ratio*output_size[0]), round(crop_ratio*output_size[1])
if w == tw and h == th:
return 0, 0, h, w
i = random.randint(0, h - th)
j = random.randint(0, w - tw)
return i, j, th, tw
def __call__(self, img):
"""
Args:
img (PIL Image): Image to be cropped.
Returns:
PIL Image: Cropped image.
"""
i, j, h, w = self.get_params(img, self.size)
if self.center_crop:
return F.center_crop(img, (h, w))
else:
return F.crop(img, i, j, h, w)
def __repr__(self):
return self.__class__.__name__ + '(size={0})'.format(self.size)
class AddDynamicGaussianNoise(object):
def __init__(self, std=5):
self.std = float(std)
def __call__(self, img):
np_img = np.array(img, dtype=np.float32)
np_img += np.random.normal(0., self.std, np_img.shape)
np_img = np.clip(np_img, 0., 255.).astype('uint8')
img = Image.fromarray(np_img, 'RGB')
return img
class ImageDataset:
def __init__(self, dataset_dirs, transform):
self.dataset_dirs = dataset_dirs
self.transform = transform
def get_dataset(self):
return ImagePairFromFolders(self.dataset_dirs, self.transform)
def get_loader(self, num_samples, batch_size, num_workers):
dataset = self.get_dataset()
sampler = SubsetSampler(range(len(dataset)), num_samples=num_samples, randperm=True, replacement=True)
batch_sampler = BatchSampler(sampler, batch_size, drop_last=True)
return DataLoader(dataset, batch_sampler=batch_sampler, num_workers=num_workers, pin_memory=True)
def get_test_loader(self, num_samples, batch_size, num_workers, watch_only=False):
dataset = self.get_dataset()
max_num_test_img = 50
sampler = SubsetSampler(range(len(dataset)), num_samples=num_samples, randperm=False)
batch_sampler = BatchSampler(sampler, batch_size, drop_last=False)
return DataLoader(dataset, batch_sampler=batch_sampler, num_workers=num_workers, pin_memory=True)
def is_image_file(self, filename):
return any(filename.endswith(extension) for extension in ['.png', '.jpg', '.jpeg', '.PNG', '.JPG', '.JPEG', '.jpeg', '.bmp'])
这个程序文件是一个数据处理工具文件,文件名为data_utils.py。它包含了一些用于数据集处理的函数和类。
主要函数和类的功能如下:
-
trainset(selected_datasets, output_img_size, add_noise=False): 根据选择的数据集名称,输出图像的尺寸和是否添加噪声,返回一个训练数据集。
-
testset(selected_datasets, output_img_size, concat=True): 根据选择的数据集名称和输出图像的尺寸,返回一个测试数据集。
-
trainloader(dataset, num_samples, batch_size, num_workers): 根据给定的训练数据集、样本数量、批次大小和工作线程数量,返回一个训练数据加载器。
-
testloader(dataset, num_samples, batch_size, num_workers, watch_only=False): 根据给定的测试数据集、样本数量、批次大小和工作线程数量,返回一个测试数据加载器。
-
is_image_file(filename): 判断给定的文件名是否是图像文件。
-
ImagePairFromFolders(Dataset): 一个自定义的数据集类,用于从文件夹中加载图像对。
-
UnNormalize(object): 一个用于反归一化图像的类。
-
SubsetSampler(Sampler): 一个用于子集采样的类。
-
MyRandomCrop(object): 一个用于随机裁剪图像的类。
-
AddDynamicGaussianNoise(object): 一个用于给图像添加动态高斯噪声的类。
这些函数和类可以用于加载、处理和预处理图像数据集。
5.3 detect.py
class Dehazer:
def __init__(self, model_weights_path):
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.img_size = 256
self.ch = 64
self.n_res = 4
self.transform = transforms.Compose([
transforms.Resize((self.img_size, self.img_size)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
self.genA2B = ResnetGenerator(input_nc=3, output_nc=3, ngf=self.ch, n_blocks=self.n_res, img_size=self.img_size, light=True).to(self.device)
# Load pre-trained weights
params = torch.load(model_weights_path)
self.genA2B.load_state_dict(params['genA2B'])
def dehaze_image(self, input_image_path, output_image_path):
# Read and preprocess input image
img = Image.open(input_image_path).convert('RGB')
img_width, img_height = img.size
real_A = (self.transform(img).unsqueeze(0)).to(self.device)
# Predict dehazed image
self.genA2B.eval()
with torch.no_grad():
fake_A2B, _, _ = self.genA2B(real_A)
B_fake = RGB2BGR(tensor2numpy(denorm(fake_A2B[0])))
B_fake = cv2.resize(B_fake, (img_width, img_height))
cv2.imwrite(output_image_path, B_fake * 255.0)
print(f"Dehazed image saved to {output_image_path}")
if __name__ == '__main__':
input_image_path = './images/2.png'
model_weights_path = './NH-HAZE_params_0100000.pt'
output_image_path = './result.png'
dehazer = Dehazer(model_weights_path)
dehazer.dehaze_image(input_image_path, output_image_path)
这个程序文件名为detect.py,它的功能是对输入的图像进行去雾处理。具体流程如下:
- 导入所需的库和模块:os、torch、cv2、numpy、PIL、transforms。
- 从networks模块中导入ResnetGenerator类,从utils模块中导入RGB2BGR、tensor2numpy和denorm函数。
- 定义了一个名为dehaze_image的函数,该函数接受输入图像路径、模型权重路径和输出图像路径作为参数。
- 获取设备信息,如果有可用的GPU则使用cuda,否则使用cpu。
- 定义了一些变量,包括图像大小img_size、通道数ch和残差块数n_res。
- 定义了一个图像转换的操作,包括将图像大小调整为img_size、转换为Tensor、归一化操作。
- 创建了一个ResnetGenerator的实例genA2B,用于进行去雾处理。
- 加载预训练的模型权重。
- 读取和预处理输入图像,将其转换为Tensor,并在设备上进行处理。
- 使用genA2B对输入图像进行去雾处理,得到去雾后的图像。
- 将去雾后的图像转换为BGR格式,并调整大小为原始图像的大小。
- 将去雾后的图像保存到输出图像路径。
- 在主函数中指定输入图像路径、模型权重路径和输出图像路径,并调用dehaze_image函数进行去雾处理。
- 打印去雾后的图像保存路径。
总结:这个程序文件通过加载预训练的模型权重,对输入的图像进行去雾处理,并将结果保存到指定的输出图像路径。
5.4 main_test.py
import argparse
from utils import *
class SRDefogWrapper:
def __init__(self, args):
self.args = args
def parse_args(self):
desc = "Implementation of SRDefog"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--phase', type=str, default='test', help='[train / test]')
parser.add_argument('--dataset', type=str, default='NH-HAZE', help='dataset_name')
parser.add_argument('--datasetpath', type=str, default=r'C:\Users\15690\Desktop\主\B11182\code\datasets/', help='dataset_path')
parser.add_argument('--iteration', type=int, default=1000000, help='The number of training iterations')
parser.add_argument('--batch_size', type=int, default=1, help='The size of batch size')
parser.add_argument('--print_freq', type=int, default=1000, help='The number of image print freq')
parser.add_argument('--save_freq', type=int, default=50000, help='The number of model save freq')
parser.add_argument('--lr', type=float, default=0.0001, help='The learning rate')
parser.add_argument('--weight_decay', type=float, default=0.0001, help='The weight decay')
parser.add_argument('--ch', type=int, default=64, help='base channel number per layer')
parser.add_argument('--n_res', type=int, default=4, help='The number of resblock')
parser.add_argument('--n_dis', type=int, default=6, help='The number of discriminator layer')
parser.add_argument('--img_size', type=int, default=512, help='The size of image')
parser.add_argument('--img_h', type=int, default=512, help='The org size of image')
parser.add_argument('--img_w', type=int, default=512, help='The org size of image')
parser.add_argument('--img_ch', type=int, default=3, help='The size of image channel')
parser.add_argument('--result_dir', type=str, default='./results', help='Directory name to save the results')
parser.add_argument('--device', type=str, default='cuda', choices=['cpu', 'cuda'], help='Set gpu mode; [cpu, cuda]')
parser.add_argument('--im_suf_A', type=str, default='.png', help='The suffix of test images [.png / .jpg / .JPG]')
return check_args(parser.parse_args())
def check_args(self, args):
# --result_dir
check_folder(os.path.join(args.result_dir, args.dataset, 'model'))
# --epoch
try:
assert args.epoch >= 1
except:
print('number of epochs must be larger than or equal to one')
# --batch_size
try:
assert args.batch_size >= 1
except:
print('batch size must be larger than or equal to one')
return args
def main(self):
# parse arguments
args = self.parse_args()
if args is None:
exit()
# open session
gan = SRDefog(args)
# build graph
gan.build_model()
if args.phase == 'test' :
gan.test()
print(" [*] Test finished!")
if __name__ == '__main__':
args = None
sr_defog_wrapper = SRDefogWrapper(args)
sr_defog_wrapper.main()
这个程序文件是一个用于图像超分辨率去雾的实现。它包含了一些参数的设置和一个主函数。
主要的代码逻辑如下:
- 导入了
SRDefog类和一些工具函数。 - 定义了一个
parse_args函数,用于解析命令行参数。 - 定义了一个
check_args函数,用于检查参数的合法性。 - 定义了一个
main函数,用于执行主要的逻辑。 - 在
main函数中,首先解析命令行参数,然后创建一个SRDefog对象。 - 调用
build_model方法构建模型。 - 如果参数中的
phase为’test’,则调用test方法进行测试。
整个程序的功能是根据给定的参数进行图像超分辨率去雾。
5.5 metrics.py
class ImageReconstructionError(nn.Module):
def __init__(self, metrics=['psnr', 'ssim']):
super(ImageReconstructionError, self).__init__()
for metric in metrics:
if metric.lower() == 'mse':
self.mse = nn.MSELoss()
elif metric.lower() == 'mae':
self.mae = nn.L1Loss()
elif metric.lower() == 'psnr':
self.psnr = nn.MSELoss()
elif metric.lower() == 'ssim':
self.ssim = SSIM()
elif metric.lower() == 'perc':
self.perc = PerceptualLoss()
else:
raise NotImplementedError('metric [%s] is not found' % metric)
def forward(self, tensor_eval, tensor_ref, metric):
"""
both input and reference tensors should be a minibatch, 4D tensor
Also, assuming values ranges in [0, 1]
"""
assert len(tensor_eval.shape) == 4
assert len(tensor_ref.shape) == 4
assert (0. <= tensor_eval).all() and (tensor_eval <= 1.).all()
assert (0. <= tensor_ref).all() and (tensor_ref <= 1.).all()
assert tensor_eval.shape[0] == tensor_ref.shape[0]
metric_layer = getattr(self, metric.lower())
batch_size = tensor_eval.shape[0]
out = 0.
for bid in range(batch_size):
val = metric_layer(tensor_eval[bid:bid+1], tensor_ref[bid:bid+1]).item()
if metric.lower() == 'psnr':
out += 10 * log10(1. / val)
else:
out += val
return out / float(batch_size)
class SSIM(nn.Module):
def __init__(self, window_size=11, size_average=True, auto_downsample=True):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.auto_downsample = auto_downsample
self.channel = 1
self.window = create_window(window_size, self.channel)
def forward(self, img1, img2):
(_, channel, height, weight) = img1.size()
f = max(1., round(min(height, weight)/256.))
if self.auto_downsample and f > 1:
img1 = F.avg_pool2d(img1, f)
img2 = F.avg_pool2d(img2, f)
if channel == self.channel and self.window.data.type() == img1.data.type():
window = self.window
else:
window = create_window(self.window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
self.window = window
self.channel = channel
return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def _ssim(img1, img2, window, window_size, channel, size_average=True):
mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel)
mu2 = F.conv2d(img2, window, padding=window_size // 2, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
sigma1_sq = F.conv2d(img1 * img1, window, padding=window_size // 2, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2 * img2, window, padding=window_size // 2, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1 * img2, window, padding=window_size // 2, groups=channel) - mu1_mu2
C1 = 0.01 ** 2
C2 = 0.03 ** 2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
return window
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
return gauss / gauss.sum()
def ssim(img1, img2, window_size=11, size_average=True):
(_, channel, _, _) = img1.size()
window = create_window(window_size, channel)
if img1.is_cuda:
window = window.cuda(img1.get_device())
window = window.type_as(img1)
return _ssim(img1, img2, window, window_size, channel, size_average)
这个程序文件名为metrics.py,它包含了一些用于图像重建误差评估的函数和类。
程序首先导入了一些必要的库,包括math、torch和torch.nn等。然后定义了一个名为ImageReconstructionError的类,该类继承自nn.Module。在该类的构造函数中,根据给定的metrics参数,初始化了一些评估指标,如均方误差(MSE)、平均绝对误差(MAE)、峰值信噪比(PSNR)、结构相似性指数(SSIM)和感知损失(PerceptualLoss)。如果给定的metrics参数不在上述指标中,则会抛出一个NotImplementedError异常。
类中的forward方法用于计算给定的评估指标。该方法接受两个输入张量tensor_eval和tensor_ref,这两个张量都应该是一个小批量的4D张量。同时,假设张量的值范围在[0, 1]之间。方法首先检查输入张量的形状和值的范围是否满足要求,然后根据给定的评估指标选择相应的评估函数。最后,将计算得到的评估值累加到out变量中,并返回平均值。
程序中还定义了一些辅助函数,如高斯函数gaussian、创建窗口函数create_window和结构相似性指数计算函数_ssim。其中,高斯函数用于生成一个高斯窗口,创建窗口函数用于生成一个二维窗口,结构相似性指数计算函数用于计算两个图像之间的结构相似性指数。
最后,程序定义了一个名为SSIM的类,该类继承自nn.Module。在该类的构造函数中,初始化了一些参数,并调用了create_window函数生成一个窗口。类中的forward方法用于计算给定图像之间的结构相似性指数。
此外,程序还定义了一个名为ssim的函数,用于计算给定图像之间的结构相似性指数。
5.6 modules.py
class GaussianBlur(nn.Module):
def __init__(self, sigma=1.6):
super(GaussianBlur, self).__init__()
weight = self.calculate_weights(sigma)
self.register_buffer('buf', weight)
return
def calculate_weights(self, sigma):
kernel = self.CircularGaussKernel(sigma=sigma, circ_zeros=False)
h,w = kernel.shape
halfSize = float(h) / 2.
self.pad = int(np.floor(halfSize))
return torch.from_numpy(kernel.astype(np.float32)).view(1, 1, h, w)
def forward(self, x):
w = Variable(self.buf)
return F.conv2d(F.pad(x, (self.pad, self.pad, self.pad, self.pad), 'replicate'),
w.repeat(x.shape[1], 1, 1, 1), padding=0, groups=x.shape[1])
def CircularGaussKernel(self, kernlen=None, circ_zeros=False, sigma=None, norm=True):
assert ((kernlen is not None) or sigma is not None)
if kernlen is None:
kernlen = int(2.0 * 3.0 * sigma + 1.0)
if kernlen % 2 == 0:
kernlen = kernlen + 1
halfSize = kernlen / 2
halfSize = kernlen / 2
r2 = float(halfSize*halfSize)
if sigma is None:
sigma2 = 0.9 * r2
sigma = np.sqrt(sigma2)
else:
sigma2 = 2.0 * sigma * sigma
x = np.linspace(-halfSize,halfSize,kernlen)
xv, yv = np.meshgrid(x, x, sparse=False, indexing='xy')
distsq = xv**2 + yv**2
kernel = np.exp(-(distsq / sigma2))
if circ_zeros:
kernel *= (distsq <= r2).astype(np.float32)
if norm:
kernel /= np.sum(kernel)
return kernel
class SimpleGray(nn.Module):
def __init__(self):
super(SimpleGray, self).__init__()
gray_vector = torch.tensor([0.2989, 0.5870, 0.1140]).view(1, 3, 1, 1)
self.register_buffer('buf', gray_vector)
return
def forward(self, x):
w = Variable(self.buf)
return F.conv2d(x, w, padding=0)
class RGB2Saturation(nn.Module):
def __init__(self):
super(RGB2Saturation, self).__init__()
def forward(self, x):
# match range
x = (x + 1.) / 2.
x_min, _ = torch.min(x, dim=1, keepdim=True)
x_max, _ = torch.max(x, dim=1, keepdim=True)
x_sat = 1. - x_min / x_max.clamp(min=1e-8)
x_sat = x_sat * 2. - 1.
return x_sat
这个程序文件名为modules.py,它包含了几个用于图像处理的模块。
-
CircularGaussKernel函数:该函数用于生成一个圆形高斯核。它可以根据给定的参数生成一个指定大小的高斯核,并可以选择是否将核的边界以外的值设为0,以及是否对核进行归一化。
-
GaussianBlur类:该类是一个继承自nn.Module的模块,用于实现高斯模糊操作。在初始化时,它会根据给定的sigma参数计算出对应的高斯核,并将其注册为模块的缓冲区。在前向传播过程中,它会将输入图像进行边界填充,并使用卷积操作对图像进行高斯模糊。
-
SimpleGray类:该类是一个继承自nn.Module的模块,用于将彩色图像转换为灰度图像。在初始化时,它会创建一个包含RGB转灰度的权重向量,并将其注册为模块的缓冲区。在前向传播过程中,它会使用卷积操作将输入图像转换为灰度图像。
-
RGB2Saturation类:该类是一个继承自nn.Module的模块,用于将RGB图像转换为饱和度图像。在前向传播过程中,它会将输入图像的像素值范围映射到[0, 1]之间,然后计算每个像素的饱和度,并将饱和度值映射到[-1, 1]之间返回。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于深度学习的图像去雾系统,旨在对输入的雾霾图像进行去雾处理,提高图像的清晰度和质量。整个项目包含了多个文件,每个文件负责不同的功能模块,如数据集处理、数据预处理、模型构建、损失函数定义、评估指标计算等。
下面是每个文件的功能概述:
| 文件路径 | 功能概述 |
|---|---|
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\dataset.py | 包含数据集处理的工具函数和类 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\data_utils.py | 包含数据处理的工具函数和类 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\detect.py | 对输入的图像进行去雾处理 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\losses.py | 定义了一些损失函数 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\main_test.py | 实现了图像超分辨率去雾的主要逻辑 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\metrics.py | 包含图像重建误差评估的函数和类 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\modules.py | 包含用于图像处理的模块 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\networks.py | 定义了一些网络模型 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\ramps.py | 包含一些用于学习率调整的函数 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\SRDefog_test.py | 实现了图像超分辨率去雾的测试逻辑 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\test.py | 包含一些用于测试的函数 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\train.py | 包含一些用于训练的函数 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\ui.py | 实现了用户界面的逻辑 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\utils.py | 包含一些通用的工具函数 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\model_vit\contra_loss.py | 定义了对比损失函数 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\model_vit\extractor.py | 定义了特征提取器 |
| E:\视觉项目\shop\基于深度学习的图像去雾系统\code\model_vit\loss_vit.py | 定义了ViT模型的损失函数 |
7.多尺度去雾算法
参考该博客提出的一种基于高频信息融合的端到端多尺度去雾网络(HF-Net),该网络新颖地引入了高频信息作为附加先验。图3-1展示了图像及其相应高频信息的示例。正如所观察到的,高频可以特别地表示图像的细节(例如,边缘,纹理),因此可以断言高频信息可以帮助模型更好地恢复图像的边缘和纹理。本文利用拉普拉斯算子从图像中分离高频信息分量(HF)。
在深度学习领域中,多尺度机制[18][20]表现出了对特征学习的强大能力。此外,特征融合策略可以利用不同层间的特征来提高网络性能,因此在神经网络的设计中得到了广泛的应用。然而,大多数现有的特征融合策略通过密集连接[21]、特征拼接[22l等方式仅在同一尺度上重用特征。在本章节中,提出了一种多尺度特征融合主干结构,以此跨不同尺度共享有用信息和复用特征。
随着注意力机制也在上游视觉任务中取得了很大的成就[23][24],研究者也随之将其用于各类计算机视觉下游任务,包括图像恢复和超分辨率[26]。受文献[19]工作的启发,本章节进一步开发了一种频率注意模块(FAM),该模块利用雾图的HF分量和频率分支的中间特征来计算注意权重图,从而细化频率特征。
HF-Net由四个关键部分组成:主干网络(Backbone)、频率分支网络(FBN)、频率注意模块(FAM)和提升模块(RB)。Backbone是一个多尺度的特征融合架构,可以跨不同尺度共享有用的信息。在特征传播时,FBN引入高频作为额外的输入,以增强边缘信息的恢复。此外,提出了频率注意力模块(FAM),使网络能够自动学习频率特征的权重图来筛选特征,同时进一步开发了提升模块(RB),通过整合高频特征和中间层的纹理特征来生成无雾图像。该方法可以直接恢复无雾图像,无需估计介质传输图或全局大气光。
8.算法设计
在本节详细阐述了一种基于高频信息融合的多尺度去雾网络HF-Net,如图所示。该网络由四部分组成:1)多尺度主干网络 Backbone。
主干网络的输入是一个雾图,其被输送到多尺度结构中进行有效的特征提取。2)频率分支网络FBN。FBN采用原始的高频信息作为输入,融合主干网络中最精细的尺度上的特征图,促进高频信息的重构。3)频率注意力模块FAM。FAM使网络能够自动学习频率特征的注意力权重图。4)提升模块 RB。RB将主干网络和频率分支网络的输出级联处理后进行特征学习,恢复最终清晰图像。

多尺度主干网络Backbone
鉴于在计算机视觉领域中,多尺度机制已表现出强大特征学习能力。本文构建了一个多尺度网络作为主干,可以跨尺度上共享有效特征。如图所示,Backbone由粗糙到精细(1/4-scale, 1/2-scale, full-scale)三层尺度组成,每层由5个ERDB组成,其为增强的残差密集块,结构设计由 RDBl28]改进而来。ERDB的结构如图3-3所示。令F}表示第i层中第j个ERDB的输出。设DS()和 US()分别表示下采样和上采样,采样因子为2。在下采样融合阶段,有以下生成公式。

式中,A()表示带注意力的逐元素加和[18]。类似地,在上采样采用融合阶段,特征传播形式可以表述为公式:

通过这种在多尺度主干中穿插上采样和下采样块的方式实现跨尺度地共享有用信息。

9.频率注意力模块FAM
为了促进FBN有效重构无雾图像的HF,提出了一种频率注意力模块(FAM),结构如图所示。FAM的主要功能如下:1) FAM引入原始雾图的F来增强特征表示能力。2)FAM生成注意图,抑制FBN输出中不重要的特征,使有用的特征前向传播。

FAM的特征图输入是Fn(FBN中最后一个ERDB的输出)和Inr(雾图的高频特征)。F表示第n个卷积层的输出特征映射。Fm由第一个卷积层生成,然后通过逐元素加和将F和Inr融合。F。和Fs是使用第二和第三卷积层生成的。F4是将F和F与第四卷积层融合得到的。频率注意权重图Fmap是由一个sigmoid激活函数生成的。Fmap表示为公式:

式中,α表示sigmoid激活函数,Conv为卷积运算,卷积核为1×1,步长为1,表示逐元素加和。然后,将F与权重Fmap进行逐元素乘积,得到中间特征特征Fma。最后采用元素加权的方法对特征图进行加权。将加权结果与FT融合,得到模块的最终输出Fou。此时所得的F.o.能够有效地表征频率特征。生成表达式为公式:
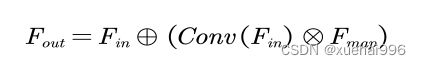
如图所示,比较了有无嵌入FAM模块时模型的效果。从图第三列的两幅图像的对比中,可以观察到FAM模块可以明显地增强边缘区域的特征表征,部分雾状噪声通过FAM被抑制在图像的背景中。这些结果进一步证明了所提出FAM的有效性。

10.提升模块RB

在本章节中,Backbone和FBN分别可以获取图像的基本语义特征和预测无雾图像的高频信息。为了进一步提升去雾效果,设计了一个提升模块RB来提高图像质量。RB的结构如图3-7所示。Foua是FBN的输出特征图,Iou是Backbone
的输出,Joa是RB的输出同时也是HF-Net的最终的无雾图像。本小节采用U-Netl3作为RB的主要单元,它由一个编码器和一个带跳连接的解码器组成。具体过程可见公式:

其中C()表示串联操作。Convk3n3s1表示核大小为3,输出通道为3,步长
为1的卷积层。Convk3n40s1表示核大小为3,输出通道为3,步长为1的卷积层。UNet(:)表示U-Net。
如图所示,可以明显地看到,没有嵌入RB的HF-Net仍然存在以下缺点:1)仍然有大量的雾霾没有去除。2)引入光晕效应。3)边缘呈现粗糙。相比之下,由于特征得到了进一步提升,本节提出的嵌入RB的方法的视觉效果更好。

11.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于深度学习的图像去雾系统》
12.参考文献
[1]杨燕,张雯波.基于雾气分布的大气光幕估计去雾算法[J].液晶与显示.2023,38(4).DOI:10.37188/CJLCD.2022-0237 .
[2]曹思颖,张弦,蒲恬,等.基于距离加权色偏估计的低质图像增强[J].数据采集与处理.2023,38(1).DOI:10.16337/j.1004-9037.2023.01.012 .
[3]高峰,汲胜昌,郭洁,等.采用对比学习的多阶段Transformer图像去雾方法[J].西安交通大学学报.2023,57(1).DOI:10.7652/xjtuxb202301019 .
[4]郑凤仙,王夏黎,何丹丹,等.单幅图像去雾算法研究综述[J].计算机工程与应用.2022,58(3).DOI:10.3778/j.issn.1002-8331.2106-0134 .
[5]吴嘉炜,余兆钗,李佐勇,等.一种基于深度学习的两阶段图像去雾网络[J].计算机应用与软件.2020,(4).DOI:10.3969/j.issn.1000-386x.2020.04.032 .
[6]Wencheng WANG,Xiaohui Yuan.Recent Advances in Image Dehazing[J].自动化学报(英文版).2017,(3).DOI:10.1109/JAS.2017.7510532 .
[7]陈凌波,朱树先,祝勇俊,等.基于结构和纹理感知的变分Retinex去雾算法[J].光学技术.2021,47(6).
[8]Fan Linwei,Zhang Fan,Fan Hui,等.Brief review of image denoising techniques[J].Visual Computing for Industry, Biomedicine, and Art.2019,2(1).DOI:10.1186/s42492-019-0016-7 .
[9]Hironobu Fujiyoshi,Tsubasa Hirakawa,Takayoshi Yamashita.Deep learning-based image recognition for autonomous driving[J].IATSS Research.2019,43(4).244-252.DOI:10.1016/j.iatssr.2019.11.008 .
[10]Boyi Li,Wenqi Ren,Dengpan Fu,等.Benchmarking Single-Image Dehazing and Beyond[J].Image Processing, IEEE Transactions on.2018,28(1).492-505.DOI:10.1109/TIP.2018.2867951 .