python学习(字符串)
接下来的是新的数据类型字符串啦,字符串内容还是很重要的,所以会有点长,要耐心看完哦
一、什么是字符串
1、字符串是容器型数据类型,可以同时保存多个文字符号;将’’、””、‘’‘’‘’、“”“”“”作为容器的标志,里面的每个符号就是字符串的元素
2、字符串不可变(不支持增删改);字符串是有序的(顺序影响结果;支持下标操作)
3、元素:引号中的每一个符号都是字符串的元素,字符串的元素又叫字符。任何文字符号都可以作为字符串的元素
注意:多行注释只有放在特定的位置才是注释(文件开头、函数的开头和类的开头)
def func1():
"""注释!"""
"""字符串"""
class A:
"""注释!"""
'''字符串'''4、三个引号的字符串和一个引号的字符串的区别:字符串内容中如果需要换行,一个引号的字符串只能使用转义字符‘\n’,三个引号的字符串可以使用回车键
str1 = 'abc\n123'
str2 = "abc\n123"
str3 = '''abc
123'''
str4 = """abc
123"""
print(str1, str2, str3, str4)
print(type(str1), type(str2), type(str3), type(str4))5、写在字符串引号中的每个符号都是他的元素
print('a,b,cMN三科23&**♣')6、空字符串(引号中没有任何符号,空格也不行)
str1 = ''
str2 = ""
str3 = ''''''
str4 = """"""7、字符串有序
print('abc' == 'cba') # False
str5 = '[10, 20, 30]'二、字符
1、字符 → 长度为1的字符串(字符串众中的元素)
字符分为两种:普通字符和转义字符
2、普通字符
在字符串中表示符号本身的字符就是普通字符(除了转义字符以外的字符)
3、转义字符:在特定符号前加\来表示特殊功能或者特殊意义的字符
\n → 换行
\b → 退格
\t → 水平制表符(相当于按一个tab键)
\’ → 表示一个普通的单引号
\” → 表示一个普通的双引号
\\ → 表示一个普通的反斜杠
注意:不管转义字符的功能是什么,统计字符长度的时候转义字符的长度是1
print('\tabc\n123')
print('it\'s me')
print("it's me")
print("i say:\"good good study, day day up!\"")
print('i say:"good good study, day day up!"')
print('abc\\n123')
print('C:\\names\\yuting\\test\\a.txt')4、编码字符:\u4\位的16进制数(\u字符编码值)
print('a一\u0061\u4e00')5、r字符串
表示一个字符串的时候可以在字符串的最前面(引号的前面)加r/R,让字符串中所有的转义字符串功能消失(让字符串中所有的字符都是普通字符)
str1 = r'\tabc\n123\u4e00'
print(str1)
path = R'C:\names\yuting\test\a.txt'
print(path)三、字符编码
1、字符编码
计算机存储数据只能存数字(存的数字的补码),为了能够让计算机保存文字符号(字 符)让每一个符号对应的固定的数据,每次在需要存储这个符号的时候,就去保存这个符号 对应的数字。
每个字符对应的固定数字,就是字符的编码值
2、字符编码表
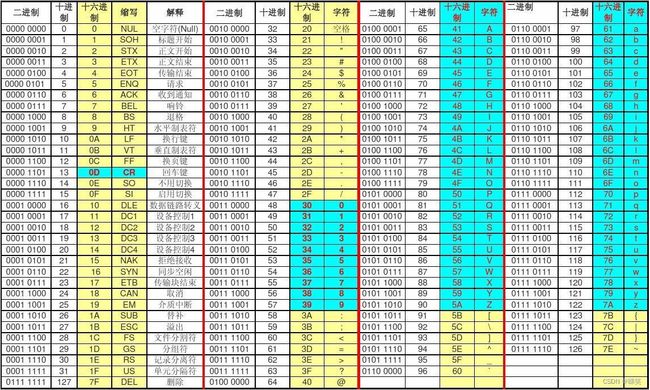
(1)ASCII码表
a.总共有128个字符(不够用)
b.数字字符从‘0’0~‘9’编码值不断加1
c.数字在字母的前面
d.大写字母在小写字母前面,他们之间有其他字符存在
(2)Unicode编码表(python)
a.Unicode编码表是ASCII编码表的扩展,里面包含了ASCII码表
b.统一码、万国码 → 它包含了数据上所有的国家、民族的所有的语言的符号
c.中文范围:4e00~9fa5
# python代码中使用16进制数必须在前面加 0x
print(0x4e00)(3)python对编码值的使用
a.chr(编码值)→ 获取指定编码值对应的字符
print(chr(97))
print(chr(0x9fa5))
print(chr(0x4e00))
# for x in range(0x4e00, 0x9fa5 + 1):
# print(chr(x), end=' ')
for x in range(0x2800, 0x28AF + 1):
print(chr(x), end=' ')
print()b.ord(字符)→ 获取指定字符对应的编码值
# 注意:字符一定是长度为1的字符串
print(ord('a'))
print(ord('一'))
print(ord('余'), ord('婷'))
# 练习:写程序将变量ch中保存大写字母转换成对应的小写字母
# A - 65 a - 97 差:32
# B - 66 b - 98
ch = 'A'
result = chr(ord(ch) + 32)
print(result)c.编码字符:\u4位16进制编码值
x = '了'
print('一' <= x <= '\u9fa5')四、字符串相关操作
1、查 → 获取字符串的字符
字符串获取字符的方法和列表获取元素的方法一样
str1 = 'hello python!'
print(str1[0], str1[-1], str1[2])
print(str1[1:-1]) # 'ello python'
print('--------------------------------华丽的分割线-------------------------------------')
for x in str1:
print(x)
print('--------------------------------华丽的分割线-------------------------------------')
for x in range(len(str1)):
print(x, str1[x])
print('--------------------------------华丽的分割线-------------------------------------')
for x1, x2 in enumerate(str1):
print(x1, x2)2、数学运算
(1)字符串1 + 字符串2 → 将两个字符串拼接成一个新的字符串
str1 = 'abc'
str2 = 'hello'
result = str2 + ' ' + str1
print(result)(2)字符串 * N → 将字符串中的元素重复N次产生一个新的字符串
print(str1 * 3) # 'abcabcabc'3、比较运算符
(1)两个字符串比较大小,比较的是第一对不是相等的字符的编码值的大小
(2)两个字符比较大小,比的是编码值的大小
print('a' > 'M')
print('hello' > '你好')
# 判断指定的字符是否是小写字母
x = 'k'
print('a' <= x <= 'z')
# 判断指定的字符是否是大写字母
x = 'P'
print('A' <= x <= 'Z')
# 判断指定的字符是否是字母
x = 'k'
print('a' <= x <= 'z' or 'A' <= x <= 'Z')
# 判断指定的字符是否是数字
x = '9'
print('0' <= x <= '9')4、in 和not in
字符串1 in 字符串2 → 判断字符串2中是否包含字符串1
print(10 in [10, 20, 30]) # True
print([10, 20] in [10, 20, 30]) # False
print('a' in 'abc') # True
print('ab' in 'abc') # True
print('ac' in 'abc') # False
# 案例:写代码提取字符串中所有的大写字母
str1 = 'shKL223=sjsj KOSL-34M地方'
# 'KLKOSLM'
new_str1 = ''
# ''+'K' -> 'K' + 'L' -> 'KL' + 'K' -> 'KLK' ....
for x in str1:
if 'A' <= x <= 'Z':
new_str1 += x
print(new_str1)五、字符串相关函数
str1 = 'mLKd文件am'
print(max(str1)) # '文'
print(min(str1)) # 'K'
print(sorted(str1)) # ['K', 'L', 'a', 'd', 'm', 'm', '件', '文']
print(list(reversed(str1))) # ['m', 'a', '件', '文', 'd', 'K', 'L', 'm']
print(len(str1)) # 81、str(数据):
任何类型的数据都可以转换成字符串,转换的时候是在数据的打印纸外面加引号
str(100) # '100'
str(1.23) # '1.23'
str(True) # 'True'
str([10,"abc",1.23]) # "[10, 'abc', 1.23]"
print([10,"abc",1.23]) # # [10, 'abc', 1.23]
str({"name":'张三','age' :18, "gender": "男"}) # "{'name': '张三', 'age': 18, 'gender': '男'}"
print({"name":'张三','age' :18, "gender": "男"}) # {'name': '张三', 'age': 18, 'gender': '男'}2、eval(数据):
去掉字符串外面引号获取里面的表达式的结果(注意:字符串引号中的表达式必须合法)
eval('100') # 100
eval('1.23') # 1.23
eval('True') # True
eval('False') # False
eval("[10, 'abc', 1.23]") # [10, 'abc', 1.23]
str1 = "[10, 'abc', 1.23]"
print(list(str1)) # ['[', '1', '0', ',', ' ', "'", 'a', 'b', 'c', "'", ',', ' ', '1', '.', '2', '3', ']']
abc = 100
print(eval('abc')) # abc print(abc)
print(eval('100 + 200')) # print(100 + 200)
list1 = [10, 20, 30]
print(eval('list1[0]')) # print(list1[0])
nums = [10, 29, 80, 30]
# '10 - 29 - 80 - 30'
code = input('输入运算表达式:')
print(eval(code))六、字符串相关方法
字符串.xxx()
1、字符串.join(序列):
将序列中的元素用指定的字符串拼接成一个新的字符串(序列中的元素必须是字符串)
names = ['张三', '小明', '李四', '小花']
result = ' and '.join(names)
print(result) # '张三 and 小明 and 李四 and 小花'
result = '*'.join('abc')
print(result) # 'a*b*c'
nums = [29, 30, 45, 60] # ['29', '30', '45', '69']
result = '+'.join([str(x) for x in nums])
print(result) # '29+30+45+60'
str1 = 'ansj223111'
str2 = 'sma012'
result = ''.join(set(str1) & set(str2))
print(result) # 'a12s'2、字符串切割
(1)字符串1.split(字符串2) → 将字符串1中所有的字符串2作为切割点对字符串1进行切割;返回值是一个列表,列表中的元素是切完后的每一段对应的字符串
(2)字符串1.split(字符串2,N) → 将字符串1中前N个字符串2作为切割点对字符串1进行切割
str1 = '123abcmnabc你好abcgogo'
result = str1.split('abc')
print(result) # ['123', 'mn', '你好', 'gogo']
str1 = '123abcmnabc你好abcgogo'
result = str1.split('abc', 2)
print(result) # ['123', 'mn', '你好abcgogo']3、字符串替换
(1)字符串1.replace(字符串2,字符串3) → 将字符串1中所有的字符串2都替换成字符串3
(2)字符串1.replace(字符串2,字符串3,N) → 将字符串1中前N个字符串2都替换成字符串
str1 = '123abcmnabc你好abcgogo'
result = str1.replace('abc', 'MN')
print(result) # '123MNmnMN你好MNgogo'
result = str1.replace('abc', 'MN', 2)
print(result) # '123MNmnMN你好abcgogo'
# 案例1:删除str1中所有的'abc'
str1 = '123abcmnabc你好abcgogo'
result = str1.replace('abc', '')
print(result) # '123mn你好gogo'
# 案例2:删除字符串中所有的空格
str1 = 'H E LL O'
result = str1.replace(' ', '')
print(result) # 'HELLO'
4、其他相关方法
(1)字符串.sprip() → 去掉字符串两边的空白字符
(2)字符串.sprip(字符) → 去掉字符串两边连续出现的指定字符
title = '\n\t 肖生克的救赎 \n\n'
print([title.strip()])
str1 = '=============肖生克=的救赎============='
print(str1.strip('='))5、大小写替换
(1)字符串.upper() → 将字符串中所有的小写字母转换成对应的大写字母
(2)字符.upper() → 将小写字母转换成对应的大写字母
(3)字符串.lower() → 将字符串中所有的大写字母转换成对应的小写字母
print('a'.upper())
print('sh技术==23KMLsu923Jam'.upper())
print('M'.lower()) # m
print('sh技术==23KMLsu923Jam'.lower()) # 'sh技术==23kmlsu923jam'6、字符串字母、字符操作
(1)字符串.isupper() - 判断字符串中是否所有的字母都是大写字母
(2)字符串.islower() - 判断字符串中是否所有的字母都是小写字母
(3)字符串.isdigit() - 判断字符串中是否所有的字符都是数字字符
(4)字符.isupper() - 判断指定字符是否是大写字母
(5)字符.islower() - 判断指定字符是否是小写字母
(6)字符.isdigit() - 判断指定字符是否是数字字符
print('KSL=S'.isupper())
print('2923m3'.isdigit())
print('M'.isupper())7、count
字符串1.count(字符串2) → 统计字符串1中字符串2出现的次数
str1 = '123abcmnabc你好abcgogo'
print(str1.count('abc'))
print(str1.count('o'))8、寻找位置
(1)字符串1.find(字符串2) → 获取字符串2在字符串1中第一次出现的位置(字符串查找)返回从0开始下标值,如果字符串2不存在返回-1
(2)字符串1.index(字符串2) → 获取字符串2在字符串1中第一次出现的位置(字符串查找)返回从0开始下标值
(3)字符串1.find(字符串2,开始下标,结束下标) → 在字符串1的指定范围内查找字符串2的位置
str1 = 'how are you? i am fine, thank you! and you?'
print(str1.find('you')) # 8
print(str1.find('aaa')) # -1
print('--------------------------------华丽的分割线-------------------------------------')
print(str1.index('you')) # 8
# print(str1.index('aaa')) # 报错!
print('--------------------------------华丽的分割线-------------------------------------')
print(str1.find('you', 9)) # 30七、格式字符串
1、字符串拼接
message = name + '今年' + str(age) + '岁!'
print(message)2、格式字符串(使用格式占位符)
(1)语法:包含格式占位符的字符串 % (数据1,数据2,数据3,…)
(2)注意:后面数据的个数和位置必须和前面的格式占位符对应
(3)逻辑:写字符串的时候如果有些位置的内容是变化的,就先用占位符占位,在后面在使用数据来填充
(4)常用的格式占位符:
%s → 可以给任何类型的数据占位
%d → 整数占位符,可以给任何数字数据占位(如果提供的数据是小数,拼接的时候只拼整数部分)
%f → 浮点数占位符,可以给任何数字数据占位(拼接的时候默认保留6位小数) %.Nf → 控制保留N位小数(做四舍五入)
message = '%s今年%s岁!' % (name, age)
print(message)
num = 3.134098
str1 = 'x: %s, y: %d, z:%f, t:%.2f, %s' % ([10, 20, 30], 23.99, 2.34, 45.992, num)
print(str1)
3、f-string
在字符串中的引号面前加上一个f/F以后,就可以在字符串中通过{表达式}来给字符串提供内容
message = f'{name}今年{age}岁!'
print(message)
str1 = f'x:{10+20}, y:{name[-1]}'
print(str1)4、f-string添加参数:{表达式:参数}
(1){提供数据的表达式:Nf → 拼接数字的时候让数字保留N位小数
money = 18975.8293
str1 = f'月薪:{money:.2f}元'
print(str1)(2){提供数据的表达式:,}
money = 189705.129
str1 = f'年薪:{money*12:,}元'
print(str1) # 年薪:2,276,461.548元
str1 = f'年薪:{money*12:,.2f}元'
print(str1) # 年薪:2,276,461.55元(3){提供数据的表达式:.N%}
rate = 0.25
str1 = f'增长率:{rate:.1%}'
print(str1) # 增长率:25.0%(4){提供数据的表达式:字符>N}
{提供数据的表达式:字符 {提供数据的表达式:字符^N}num = 23
str1 = f'学号:python{num:0>4}'
print(str1)
str1 = f'学号:python{num:0<4}'
print(str1)
str1 = f'学号:python{num:0^4}'
print(str1)
num = 'a'
str1 = f'学号:python{num:+>6}'
print(str1)
num = 'a'
str1 = f'学号:python{num:>6}'
print(str1)