python grpc unary call错误_这里有一封GRPC开箱手册,请查收
背景简介
作者在网易RDS数据库部门就职,负责集团数据库的自动化高可用工作。
我们拥有若干的数据库环境,每个环境有着众多的数据库实例节点,每个环境都由管控服务器(server)来负责数据库节点的稳定,为了保持数据库节点的稳定,数据库节点与管控服务器之间的状态实时上报是最关键的一个逻辑。
管控服务器为了获取每个节点实时的心跳,目前采用proxy server转发的方式,数据库的节点本地有安装一个porxy client,数据库节点产生的心跳消息交由proxy client 进行转发给proxy server,再发给管控服务器,处理完成后,在交由proxy server,发送给proxy client,最后到达数据库节点,来回经历了多次传输。

由于proxy server是公用服务,非我方独享,所以proxy server与我方管控server的吞吐与处理量受限,现实的情况是任何一个节点发生了阻塞会影响全局的消息吞吐。
初探GRPC
GRPC是什么今年内,该架构连续发生了多次异常的场景,由于部分proxy server服务器出现了异常与proxy server sdk的低效率,导致我们环境通信服务受到影响,造成了消息积压,甚至影响了运维消息的下发。
我们也是投入了大量的人力来进行排查与定位。在抢修的进程中,我们逐渐意识到这种proxy方式不是太适合我们高强度的心跳探活方式, 于是在组内沟通中,GRPC被推上台面。
一言以蔽之:google 推出的rpc 框架,用于高性能的消息传输方案。消息的编解码默认基于protocol buffer v3。
其拓扑方案简单到一看就会。

1 点对点通信方式GRPC虽然架构简单,但是工作模式却不简单,内建了4种工作模式,完全看懂,大概需要一段时间,建议搭配官方的示例文档来看。下面简单以图文方式来表达4种工作方式。

2 点对流式通信方式定义一个沟通的消息,双发一应一答,沟通就结束。双方均无需保活链接。

3 流式对点通信方式在一次沟通中,客户端向服务端分次发送数据,在客户端发送完成数据后,服务端进行一次响应,在客户端接收消息之前,客户端需要保活链接。

4 流式对流式通信方式在一次沟通中,客户端向服务器发送一次请求,服务端像客户端分次发送多组数据,服务端会保活这个连接,直到消息发送完成,期间客户端不会有响应。

学会写2手protocol buf在一次沟通中,客户端与服务端建立起连接,双方可以同时向对方发送数据,不受约束。双方的消息以流式模型传递,grpc会对双方会话进行保活,直到异常发生。
protocol buf是grpc内建的消息体承载方式,由于都是google出品,双方在跨平台上都做的还可以。核心的代码都可以一键生成。
一段简单的 protocol buf 代码如下
service AgentNotify {
rpc KeepAlive(Ping) returns (Pong){}
}
message Ping{
string ping =1;
}
message Pong{
string pong = 1;
}写一个server sdk在高强度的通讯模型下,采用双端流式是比较明智的选择,一方面,server端可以复用一个线程,避免每次来新的链接都会创建新的线程而造成性能浪费,另一方面可以在这个线程中保存一些上下文,用做一些逻辑判断,简直不能更完美。
于是开开心心开启了grpc嵌入之路。由于跨平台需求,我们这里服务端采用了java,客户端采用了python
利用maven或者gradle可以对proto文件自动编译,生成所需的java代码,你只需要定义好proto的头文件即可,剩下的就交给编译器。
syntax = "proto3";
option java_multiple_files = true;
option java_package = "com.netease.rds.core";
option java_outer_classname = "HeartBeatProto";
package core;完善你的流式处理代码在生成代码后,只需要把grpc server的启动方法、关闭方法和本地的测试代码写入到sdk中即可打包上传,在你的项目中引用这个maven包,复写消息回复的代码即可。
由于采用流式模型,在客户端与服务端,分别写完你的代码,大概2小时,就能完美的测试并且发现消息发送毫无异常。
你以为这就完了?1天做完了1个月的工作量。简直不能更棒,想想都要笑了。
进阶DEBUG
流式通道的断开重连不经意间在服务端加了个测试日志,然后重启了服务端,这时候懵逼的事情来了,服务端的重启,造成tcp意外中断,然后客户端的流式通道扑街了,起不来,GRPC本身没有提供能恢复流式通道的方法,消息中断,不得以,只能重新设计你的通信模式。
如何在服务端重启后,客户端的流式通道能够正常恢复,又是一个设计问题,好在机智的我经过无数次的失败后,发现可以使用ping pong机制来做心跳探活的探活。设计方式如下
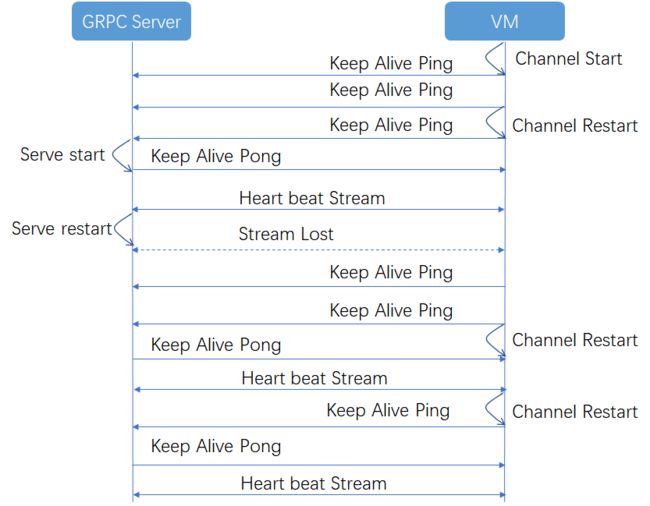
service AgentNotify {
rpc SendHeartBeat ( stream HeartBeatRequest) returns (stream HeartBeatReply) {}
rpc KeepAlive(Ping) returns (Pong){}
}上述方案的优点是,无论客户端与服务端如何重启,客户端总是能以最快的方式与服务端建立起流式通道,这对于服务端应用发布后,客户端的快速重连是有指导性的恢复战略意义。
所以一段线上生产的代码随之而来
def sendHearBeat(self):
# 心跳 发送与接收 组件
while self.run: # 发送心跳线程可以一直在后台运行
self.logger.logInfo("send heart beat running!")
if self.channel_alive: # 当通道存活时,可以进行建立流式通道
self.reset_queue()
response_iterator = self.stub.SendHeartBeat(self.gen_heartbeat()) # 这里建立了一个流式通道
self.logger.logInfo("a new iter has been set!")
try:
for response in response_iterator: # 从流式通道中不断的读取数据
response = self.format_reply(response)
self.iter_queue.put(response) # 通过消费队列,将信息回复给服务端
self.logger.logInfo("new data from iter send to heart beat thread!")
except grpc._channel._Rendezvous as err: # 当流式通道发生异常时,这里可以瞬间捕获异常
self.deactivate_channel("send heart beat iter lose") # 通知通道取消激活
self.logger.logError("tunnel down with %s " % err.details())
except Exception as eee:
self.logger.logInfo("unkonow err in send heart beat , " + eee.message)
else:
self.keepAlive() # 进行通道的探活,通道存活后,再一次进入流式通道的消息处理服务端毫无征兆的无法启动结合上述代码,其中还包括了一个观察者的设计模式,在流式通道发生异常后,异常捕获器可以快速通知ping pong机制就位,来探测服务端的通道是否好用,如果一旦服务端变好,客户端可以立马和服务端建立起流式通道,发送消息。
新项目另说,可能嵌入GRPC的大概都是改造型项目,如果是老旧项目使用了旧版zooKeeper与新版的GRPC,那么大半都会掉在这个坑里面。
没有日志,没有响应,只能在线debug,一步一步的跳转,最后,你发现你的项目在这里崩了,创建端口时,无缘无故的失败。没有错误提醒, exception毛也没有捕获到。

这时候,所有的异常全部被grpc生吞。只能手动evaluate,在不断的测试中,渐渐发现了端倪。

运行时的maven冲突又一说zookeeper 客户端curator 中的guava版本与 grpc 中guava产生了冲突,并且这个比较坑的是,没有任何提示。只能把curator升级到最新版本,故障解决。
关于参数在成功运行后,偶然还发现,有部分maven版本冲突,使用maven 检测工具对grpc的依赖做了屏蔽,后面可以正常使用。
在python客户端上,官方有引导式的希望你可以为channel加入enable_retry的参数以获得可靠的消息通道服务,但是在几次客户端的重启后我发现了问题,存在流式通道的情况下,利用supervisor启动的进程,如果没有回调关闭channel,进程则无法正常被销毁

从上图可以看到进程都留在这个僵尸状态,在看看端口,都处于close_wait的状态

参数又一说,流式通道的存活异常取消channel的enable_retry参数后,进程重启变得正常。
参数再说,探活channel的异常如果网络存在变化的场景,比如路由会动态变化,或者接口会动态变化,造成server的地址需要重新被路由,这时候,由于网络的异常,就会造成流式通道就会变成僵尸通道,发不出消息,收不到消息。虽然最后会被异常捕获,但中间的时间不透明。
在研究了channel的参数后,可以为流式通道加入keepalive_time_ms 与keepalive_timeout_ms 组合参数以便在网络异常后,流式通道能够及时被销毁。
这里是一个python客户端的天坑。
在使用点对点的探活通道对server进行探活时,理论上可以很完美,不通就可以及时返回,以便及时获得回调。
但是由于TCP重传对冲机制的影响,可能会存在重传退避的问题。而造成一个奇怪的现象,时不时探活线程会阻塞。
经过调试和加上时间戳后,会发现阻塞的时间大致还差不多,而且在本机电脑测试、数据库节点测试所产生的阻塞时间都不一致。
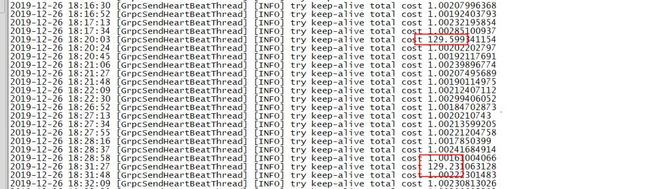
我以为又是什么参数发生故障,于是我疯狂的debug,把官方的参数只要能用的,都拿来试了试,发现最后起不了啥效果。
后面给官方提issue,由于赶上了圣诞节,大家都休假了,issue被冷,只能自己想办法。
在社区的issue上,针对重传的一些参数进行深度挖掘,经过几十个网页后,探出了大概。阻塞是由于tcp_syn的重试导致,又找到了一份系统参数tcp_syn_retries与阻塞的时间对照
tcp_syn_retries Max connection timeout
1 3s
2 7s
3 15s
4 31s
5 63s
6 127s果然,发现自己的服务器上的配置是6

但官方其实是有办法可以规避这个问题的,可以通过设置TCP_USER_TIMEOUT 来解决,但python,由于打包时对于linux kernel是否支持该无法获知导致官方对与many_linux pip包无法加入这个参数,所以这个问题在python客户端无法解决(除非自行编译)。
但对于现有网络中上万的节点不可能进行自行编译pip报,所以只能手动调整参数。
可能你有几百几千台甚至上万台服务器,这个参数而且是root级别才能修改,如果手动root改参数不是很方便,经过研究,在python运行时也可以修改,方法贴下:
import os.path
import subprocess
def started_as_root():
if subprocess.check_output('whoami').strip() == 'root':
return True
return False
def change_retries():
with open("/proc/sys/net/ipv4/tcp_syn_retries", "w") as tcp_syn_retries:
tcp_syn_retries.write("4")
tcp_syn_retries.flush()
def change():
if started_as_root():
change_retries()
else:
current_script = os.path.realpath(__file__)
os.system('sudo -S python %s' % current_script)
if __name__ == '__main__':
change()你绝对会想不到,官方在python里头还藏了一颗大彩蛋,不定时死机的炸弹,在坑了无数人之后,再度坑到我们这里了,好好的,程序就不运行了,日志不打印了,功能都停止了,查看top,程序占CPU100%。为此我花费了无数个日日夜夜,不眠不休的解决这个问题。

症状是这样的,python客户端在建立流式通道的时候,会与python系统库subprocess发生冲突进行系统资源的抢占,然后发生了死锁。
在这里必须安利一下py-spy可以说是唯一一个配置简单,且功能强大的python在线debug的库。
于是打印了火焰图,大致能看出问题。

同时在细节的调用争抢图中,可以看得出,channel与subprocess形成了互锁,疯狂的争抢着cpu运行时间。
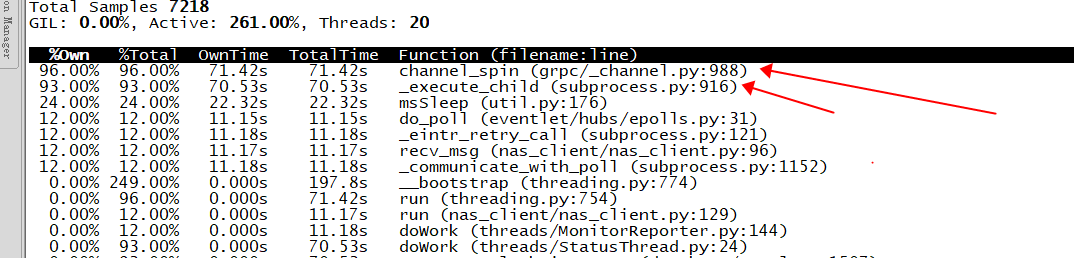
我能怎么办,我也很绝望啊,抱着试一试的态度,我给社区提了issue,令人震惊的是,社区的活跃程度远远超乎想象,甚至给我安排了一位华人工程师与我对接。
在提交完现场与导致问题的猜想后,很快就得到了官方肯定的回复,翻译如下:亲亲,这是我们的bug没错啊,由于历史的原因,我们不打算修复这个bug。但我们终于比狠,熬过了python社区,在python3.7中,官方使用了新的方式来调用系统接口,可以避免这个问题,所以建议升级到python3.7呢,如果不能升级的话建议关闭GRPC_ENABLE_FORK_SUPPORT这个环境变量试试呢。
我一脸懵逼的进来,然后又一脸懵逼的出去,我没开这个环境变量啊,但只能试试了,于是我在代码中加入了disable这个环境变量的功能,令人意想不到的事情发生了,居然成功了。

真是自己都想给自己鼓掌。我后来到社区扒了扒,被这个事情坑到的小伙伴还真不少。
上线的准备
压测grpc性能如何?链接稳不稳定?服务器能不能抗住上万的节点并发?
那么先发到测试环境试试水吧,模拟生产环境中的上万节点,大概只需要在客户端起上上万的线程就行了, 于是这样试了试,结果客户端起来后又懵逼了,无论在客户端起多少线程,始终客户端只有1个tcp链接在工作。为什么会这样?
定位了一下,我发现端倪可能在channel的参数上,于是我翻了翻官方的参数列表,终于在最后一条,我发现了这样一个参数options= [("grpc.use_local_subchannel_pool",1)]大概意思是,所有的channel各自用各自的pool。
于是代码成功运行了,我创建了30个数据库节点,每个节点上跑了400个TCP链接,在管控server上监听了12KTCP长链接。连续跑了一个星期多,流量记录见下图。

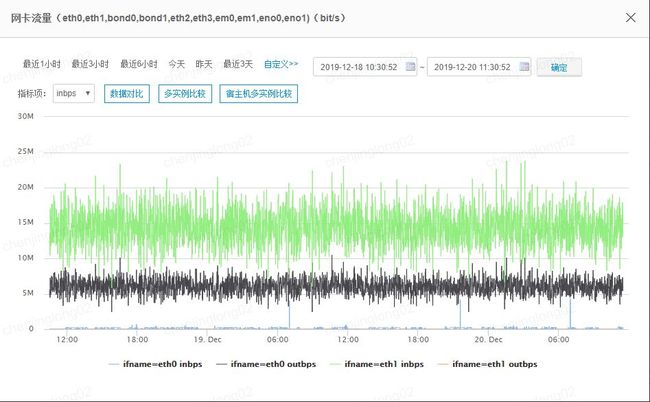
依赖包安装使用的网络流量和tcp链接数量都比较稳定。
由于python需要安装pip包,对于存量的节点,在线安装是个比较稳妥的方式,客户端主要依赖 protobuf与grpcio,部分环境可能需要eventlet.
sudo pip install protobuf -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com --ignore-installed six
sudo pip install grpcio -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com --ignore-installed six
sudo pip install eventlet -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com --ignore-installed six文末福利,全网独家
如何把protobuf一键生成所需的py文件,可以在pycharm中配置external tools
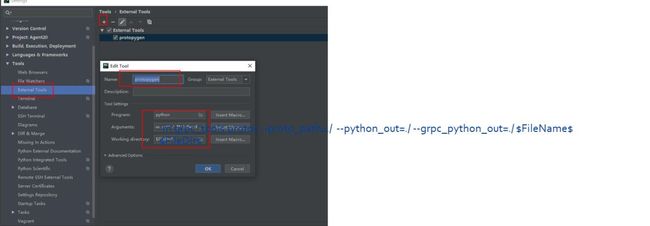
Arguments 配置成 :-m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ $FileName$
Working directory配置成: $FileDir$之后就可以很方便的在protobuf点击external tools直接生成py文件。
最后预祝大家使用GRPC开心,掉坑也能及时出坑。