python基础----Day06
内容概要:
- 列表数据的介绍
- 列表数据的相关操作
- enumerate()内置函数
一.列表类型数据的介绍
1. 列表的创建:
列表需要使用中括号[ ],元素之间使用英文的逗号进行分隔

2. 为什么需要列表?
列表是一种统一的整体类型,列表中能储存N个元素
#以下定义的变量在内存中是分散独立的,不便于整体的统一操作
name1 = '张三'
name2 = '李四'
name3 = '王五'
name4 = '赵六'
#列表类型便于统一操作
names = ['张三','李四','王五','赵六']
3. 列表的特点:
二.列表的相关操作
1.列表的切片
列表的切片与字符串的切片操作相同,详情请见Day05
2.列表元素的索引
names = ['张三', '李四', '王五', '赵六', '田七', '麻瓜']
#需求一:在names中取出'赵六'
name = names[3]
print(name)
#需求二:查询'王五'在列表中的下标
result = names.index('王五')
print(result)
#需求三:判断'张九'是否在列表names中----in
result_1 = '张九'in names
print(result_1) #输出结果为False,说明不存在
result_2 = '张九' not in names
print(result_2) #输出结果为True
#需求四:查找元素是否在列表中
name = input('请输入要查找的姓名:') #定义变量接收用户输入
if name in names: #条件判断
index = names.index(name) #若列表中存在则输出其下标
print(index)
else:
print('列表中不存在该姓名')
3.列表元素的遍历:

names = ['张三', '李四', '王五', '赵六', '田七', '麻瓜']
for i in names: #从names中依次取出各个元素
print(i)
ps:目前所知,字符串、列表都是序列,可以直接遍历
4.列表元素的增加操作
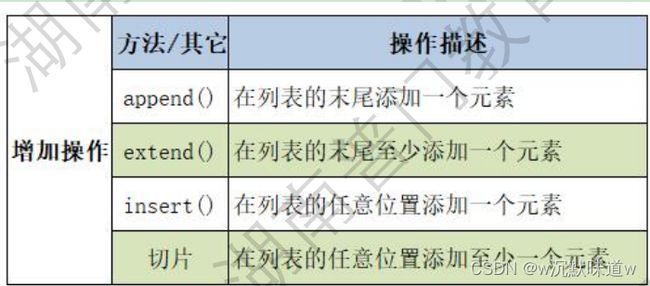
names = ['张三', '李四', '王五', '赵六']
#需求一:在names列表后添加'田七' --> append
names.append('田七') #直接操作就ok了,无需定义变量接收
print(names)
#需求二:在names列表末尾添加'田七', '麻瓜' --> extend
names.extend(['田七', '麻瓜'])
print(names)
#需求三:在names列表中第二个位置插入'陆小果'
names.insert(1, '陆小果')
5.列表元素的删除操作
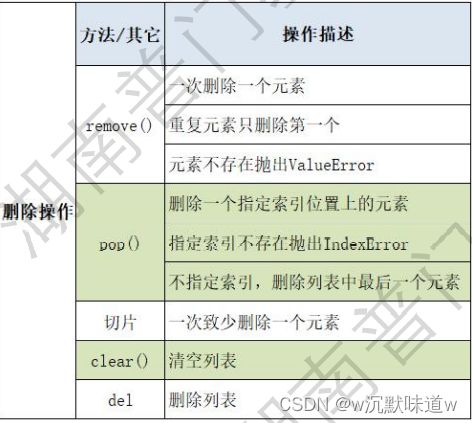
names = ['张三', '李四', '王五', '赵六']
#需求一:删除'王五' --> remove()
names.remove('王五'
print(names)
#需求二:根据下标删除元素'李四' --> pop() 若不指定下标则删除最后一个元素
names.pop(1)
print(names)
names.pop() #删除'赵六'
#需求三:清空列表 --> 该列表就成为一个空列表 --> clear()
names.clear()
print(names)
#python内置方法 del
#将整个 names 列表从内存中删除了, 也就意味着这个 names 列表不能再使用了
del names
print(names) #NameError: name 'names' is not defined names这个列表的名称没有被定义
6.列表元素的修改操作(CRUD----增删改查)
1.列表元素的更改
names = ['张三', '李四', '王五', '赵六']
#需求:将'王五'改为'麻瓜',列表元素的也是通过下标来实现
names[2] = '麻瓜'
print(names)
2.排序
常见的两种方法:
①调用 sort()方法,列有中的所有元素默认按照从小到大的顺序进行排序,可以 指定
reverse=True,进行降序 排序
②调用内置函数 sorted(),可以指定 reverse=True,进行降序排序,原列表不发生改变
数字
num_list = [33, 55, 44, 11, 77, 66, 22]
#正向排序 sort()
num_list.sort() #直接操作,无需定义变量来接收
print(num_list)
#逆向排序 sort(reverse=True)
num_list.sort(reverse=True)
print(num_list)
字符串:
字符串的排序规则 : 先比较首字符, 如果首字符直接由结果了, 后续字母就不会再比较了.
country_list = ['China', 'America', 'Russia', 'India', 'Canada', 'Japan', 'South Korea', 'North
Korea', 'France', 'German'] #不能换行的奥
country_list.sort()
print(country_list)
7.列表生成式
1.列表生成式:生成列表的公式
2.语法格式:
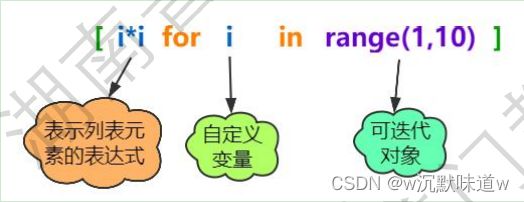
3.举例:
#从右往左看:先遍历1-9 并把值赋给i 然后i再变平方
result = [i**2 for i in range(1, 10)]
print(result)
#首先遍历1-100并把值赋给i 然后如果i满足:i%3==0,再把符合该条件的i的值赋给result
result = [i for i in range(1, 101) if i%3==0] #判断条件放后面
print(result)
8.补充(不知道怎么起名字了)

1.+
# + 可以将两个列表拼接为一个列表
num_list1 = [10, 20, 30]
num_list2 = [60, 70, 80]
result = num_list1+num_list2
print(result)
运行得到:
[10, 20, 30, 60, 70, 80]
2.*
# 可以将列表重复指定的次数
num_list = [10, 20]
result = num_list * 3
print(result)
运行得到:
[10, 20, 10, 20, 10, 20]
3.min() max()
# min() 获取列表中的最小元素 max() 获取列表中的最大元素
num_list = [12, 43, 54, 23, 31]
result1 = min(num_list)
result2 = max(num_list)
print(result1,result2)
4.count() 查找元素的个数
num_list = [1, 2, 1, 4, 4, 6, 7, 5]
num = num_list.count(1)
print(num)
三.enumerate()内置函数
1.enumerate()函数的介绍与使用
enumerate()函数用于将一个可遍历的数据对象,如列表,组合为一个索引序列, 同时列出数据和数据
下标. 一般用在 for 循环当中
举个例子:
'''
enumerate 迭代器, 如果传入一个列表, 则将列表中的每一个元素与其对应的下标实现组合.
'''
country_list = ['China', 'America', 'Russia', 'India', 'Canada', 'Japan', 'South Korea']
for i in enumerate(country_list):
print(i)
运行得到:
每个元素前是它的下标,这就是enumerate()函数的作用哦
同时发现输出结果为:(0, ‘China’) 这是元组类型,元组中的数据是不可变的
2.其他方法实现:下标+元素
方法一:len()函数
names = ['张三', '李四', '王五', '赵六', '田七', '麻瓜']
for i in range(len(names)): #
print(i,names[i])
方法二:
enumerate()函数输出为元组,元组中有两个元素,因此可以在for循环中定义两个变量
names = ['张三', '李四', '王五', '赵六', '田七', '麻瓜']
for index,name in enumerate(names):
print(index,name)
那就到这里了吧,
再写下去就不礼貌了…