ICLR 2023 | Self-Consistency: Google超简单方法改善大模型推理能力
大家好,我是HxShine。
今天分享一篇Google Research, Brain Team的一篇文章,SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS[1]:利用自洽性提高语言模型中的思维链推理效果
这篇文章方法非常简单但是效果非常好,OpenAI的Andrej Karpathy(前Tesla AI高级总监、自动驾驶Autopilot负责人)也在state of gpt[2]中也分享了这篇文章,其仅仅使用单个模型采样多个结果,然后根据答案做融合就可以大幅地提升CoT(chain of thought)的推理效果。
建了一个公众号,会定时分享相关文章,欢迎大家关注~
公众号名称:NLP PaperWeekly
公众号内容:论文学习,主要关注nlp,对话系统,大模型,多模态等领域的论文

一、概述
Title:SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
论文地址:https://arxiv.org/abs/2203.11171
1 Motivation
假设每个复杂的问题都可以有多种思路来推到出最终的答案,这篇文章就是探索是否可以用这种思想来提高大模型复杂问题的推理能力。
对人类来说,不同人思考问题的方式不一样,同样的问题,可以利用多种思路来解决。而当前大语言模型来解决复杂推理问题时,例如COT + LLM的方法主要采用一种贪婪解码(Greedy Decoding)【在每个时间步选择概率最高的词作为输出】的方式来实现。
2 Methods
本文提出的方法非常简单,提出了了一种新的decoding解码策略【self-consistency(自一致性)】,以替代思想链(COT)+ LLM使用的贪婪解码(Greedy Decoding)方法。总结成一句话就是首先利用COT生成多个推理路径和答案,最终选择答案出现最多的作为最终答案输出,效果出奇的好。

方法:自一致性方法包括三个步骤:1)使用思维链(CoT)提示语言模型;2)从语言模型的解码器中采样,取代CoT提示中的“贪婪解码”,生成一组不同的推理路径;3)通过在最终答案集中选择最一致的答案拿到聚合结果。
特点:1)只用了一个模型,没有用多个模型集成。2)根据答案做投票,而不是根据推理路径,这里假设每个复杂的问题存在多种解决方案。
3 Conclusion
1. 在一系列流行的算术和常识性benchmarks上推理有惊人的优势,GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%) and ARC-challenge (+3.9%).
2. 除了提高准确性之外,self-consistency(自一致性)还可以在使用语言模型执行推理任务时收集基本原理,以及提供不确定性估计和对语言模型输出的改进校准。

3. 其他应用:可以使用本文提出的self-consistency(自一致性)来生成更好的监督数据,来对模型进行微调,这样模型就可以在微调后的单个推理运行中给出更准确的预测。
4 Limitation
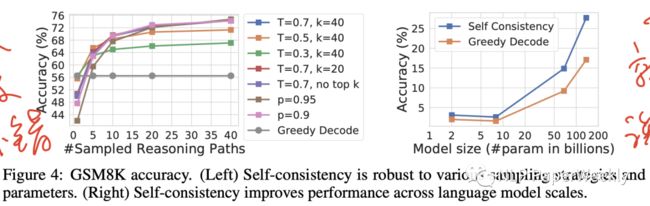
需要更多计算资源,在实践中,人们可以尝试少量的路径(例如,5条或10条推理路径)作为起点来实现大部分的收益,同时不会产生太多的成本,因为在大多数情况下,性能很快饱和,如下图:

二、详细内容
1 不同融合策略的比较:多数投票融合效果最好

这里比较了多种融合策略,有两个因素,一个是是否对每个(r_i, a_i)结果进行加权,二个是是否对输出的长度进行normalized,例如给定prompt和question,normalized Weighted sum的加权系数计算方式为:
其中K为生成的token的长度,P(t_k|prompt, question, t1, ..., t_k-1)为生成第k个token的概率(k-1限制条件下),P(r_i, a_i | prompt, question)为最终的加权系数,各种加权方案说明如下:
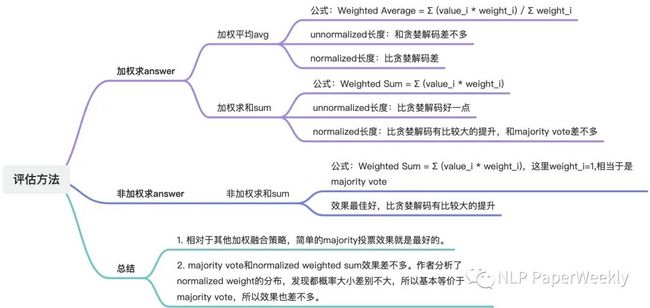
结论:1)Unweighted sum(majority vote)> Weighted sum(normalized) > Weighted sum(unnormalized) > Weighted avg(unnormalized) > Weighted avg(normalized)
2 主要实验结论1:相对于CoT(chain-of-thought),其数学推理、常识推理、符号推理能力在在不同大小的模型上都有比较大的提升。
数学推理数据集:

常识和符号推理数据集:

结论1:相对于CoT(chain-of-thought)其数学推理、常识推理和符号推理能力提升都不错,previous sota是GPT-3 finetuned的模型。
结论2:在各种不同大小的模型上,都有稳定的提升
3 主要实验结论2:随着采样的推理路径个数的增加,精度越来越高

数据集类型:数学和常识推理,模型:LaMDA-137B
4 提升CoT在一些常规NLP任务上(CoT表现差)的Performance

背景:相对于标准的few-shot in-context learning,CoT在一些常规NLP任务上效果可能还会变差,例如1)Closed-book question answer。2)NLI自然语言推理任务。3)RTE关系抽取任务。
-
"Closed-book question answer"(闭卷问题回答)是一种考试或测试的形式,其中考生在回答问题时不能使用任何参考资料,也不能查阅书籍或笔记。在这种形式的考试中,考生必须凭借自己之前掌握的知识来回答问题,没有任何外部资源的帮助。
结论:利用self-consistency还能带来比较大的提升,ANLI任务从69.1->78.5,提升比较大。
5 示例:多数投票的答案修正CoT贪婪解码推理结果

1):红颜色为CoT贪婪解码错误的推理和答案,选取多数投票的最终结果25,可以对比分析发现CoT贪婪解码的推理错误。
2):测试模型:PaLM-540B
6 Self-consistency与现有其他方法对比
6.1 与先采样然后排序方法对比

方法:该方法是先采样多个,然后排序选取一个最好的
结论:本文方法效果好非常多
6.2 对比同等规模的beam search 方法

方法:1)base:直接beam search,然后选取top beam的结果。2)self-consistency + beam search:这里指用beam search生成多个结果,这种方式可能多样性比较差。3)self-consistency + sample:这里指用采样生成多个结果,然后用self-consistency选取最佳结果。
结论:self-consistency + sample > self-consistency + beam search > beam search
原因分析:beam search采样多个结果的时候,多样性比较差,所以融合效果也比较差。
6.3 单个模型不同prompt集成对比

PaLM- 540B模型公平对比(都是40条路径):

方法:1)Ensemble(3 sets of prompts):三套不同的prompts结果来集成。2)Ensemble(40 prompt permutations):调整few-shot中样本的顺序来降低其影响来做融合。3)self-consistency(40 sampled paths):本文方法,40条推理路径选多数的答案。
结论:用了self-consistency方法效果最好,提升幅度比较大,其他集成的方法都没什么太大的效果,说明本文方法生成不同结果的多样性和互补性可能比其他方法更好。
7 其他消融实验
7.1 采样参数和模型大小的影响
-
多样性越好,融合效果越好:温度系数越高(T=0.9,T=0.7)> 温度系数越高(T=0.5,T=0.4),T越大,生成的多样性是越好的,T=0其实就是贪婪解码。
-
模型越大,融合效果越好:可能某些任务要模型到达一定规模之后,模型才有能力解决。
7.2 对prompt的鲁棒性

-
鲁棒性不错:如Table 8显示,就算CoT的prompt写的不太好,有错误,也能带来比较大的提升。
-
一致性越高,模型精度越好:如Figure 5,可以根据一致性大致得出模型的准确率。
7.3 多模型集成对比

方法:比较了LaMDA-137B、PaLM-540B,GPT-3不同模型间融合效果对比
结论:1)一个模型效果如果比较差,融合后可能还会拖累融合效果。2)本文是使用单个模型采样不同的结果进行融合,而不是使用多个不同的模型,所以叫自一致性(self-consistency)。3)本文使用self-consistency效果好,从56.6(PaLM-540B greedy)->74.4(self-consistenccy),操作简单,实验成本低(不需要调取多个模型的结果)。
疑问:为什么没拿2个大小相同的不同模型(例如LaMDA-137B+GPT-3)进行融合,来对比self-consistency(2 path)与其的提升关系,不然多个540B模型的结果融合效果肯定好。
三、总结
-
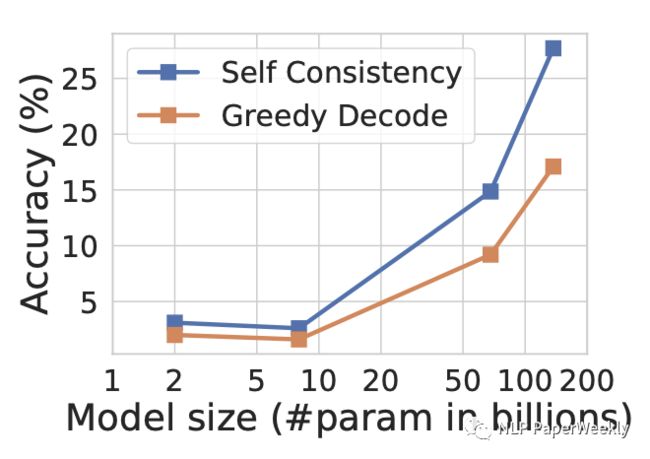
大模型(10B以上)生成结果的多样性diversity和质量比较好。本文的一大特点是没有利用不同的多个模型来集成,而是只用当个大模型采样输出不同的推理路径和结果来集成,有一个现象就是随着模型size的变大,集成的效果越来越高,说明大size的模型(一般要求要10B以上),其多样性diversity足够好,同时其生成的答案的质量也有保障,所以最终融合的效果才会比较好。
-
可以将其当作是一种生成高质量训练数据的方法。假设我们已经训练好一个大模型,利用本文self-consistency方法,可以收集比当前大模型好非常多的一个答案数据,从而可以用收集到的高质量的数据来训练准确率更高的模型。
-
可以给大模型提供不确定性估计。如下图,模型采样多个结果的一致性是和模型的准确率强相关的,可以用该性质对大模型输出结果是否可信提供参考。
四、References
[1] Wang X, Wei J, Schuurmans D, et al. Self-consistency improves chain of thought reasoning in language models[J]. arXiv preprint arXiv:2203.11171, 2022.
[2] state of gpt: https://karpathy.ai/stateofgpt.pdf
五、更多文章精读
TOT(Tree of Thought) | 让GPT-4像人类一样思考
OpenAI | Let’s Verify Step by Step详细解读
GOOGLE | COT(chain of thought)开山之作,利用思维链提升复杂问题推理能力一、概述
建了一个公众号,会定时分享相关文章,欢迎大家关注~
公众号名称:NLP PaperWeekly
公众号内容:论文学习,主要关注nlp,对话系统,大模型,多模态等领域的论文
