【Python】—— pandas数据处理
Pandas 提供了丰富的数据处理功能,涵盖了从数据导入、清理、转换到分析和可视化的方方面面。以下是一份关于 Pandas 数据处理的主要内容:
1. 数据导入和导出
-
导入数据:
import pandas as pd # 从 CSV 文件导入 df = pd.read_csv('data.csv') # 从 Excel 文件导入 df = pd.read_excel('data.xlsx') -
导出数据:
# 导出到 CSV 文件 df.to_csv('output.csv', index=False) # 导出到 Excel 文件 df.to_excel('output.xlsx', index=False)
2. 数据清理
-
处理缺失值:
# 删除包含缺失值的行 df.dropna(inplace=True) # 填充缺失值 df.fillna(value, inplace=True) -
删除重复值:
df.drop_duplicates(inplace=True)
3. 数据选择和过滤
-
选择列:
df['Column1'] -
条件过滤:
selected_data = df[df['Column1'] > 2]
4. 数据转换
-
新增列:
df['NewColumn'] = df['Column1'] + df['Column2'] -
映射和替换:
df['Category'] = df['Category'].map({'A': 1, 'B': 2, 'C': 3}) # 替换特定值 df.replace({'old_value': 'new_value'}, inplace=True)
5. 数据分组和聚合
-
按列分组:
grouped_data = df.groupby('Category')['Value'].mean() -
多列分组和多个聚合函数:
grouped_data = df.groupby(['Category', 'SubCategory']).agg({'Value': 'mean', 'Count': 'sum'})
6. 数据合并和连接
-
合并两个 DataFrame:
merged_df = pd.merge(df1, df2, on='common_column', how='inner') -
连接操作:
concatenated_df = pd.concat([df1, df2], axis=0)
7. 时间序列处理
-
处理日期数据:
df['Date'] = pd.to_datetime(df['Date']) -
时间索引:
df.set_index('Date', inplace=True) -
滚动窗口计算:
df['RollingMean'] = df['Value'].rolling(window=3).mean()
8. 数据可视化
- 基本图表:
import matplotlib.pyplot as plt df['Column1'].plot(kind='line') df['Column2'].plot(kind='bar')
这些功能只是 Pandas 提供的众多数据处理功能的一部分。根据具体的数据和分析目标,还需要深入学习 Pandas 文档并结合其他库(如 Matplotlib、Seaborn、NumPy)进行更复杂的数据处理和分析。
第1关:将超市销售excel文件根据商品的类别筛选存储
任务描述
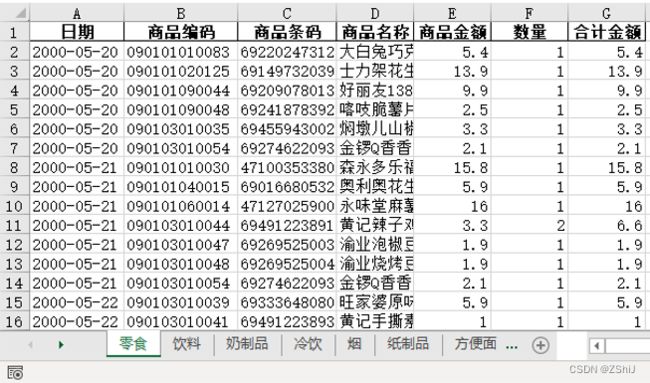
本关任务:超市销售数据如图所示

建立excel 文件“类别销售”,根据不同类别建立多个工作表,将相同类别的销售信息存放在相应的工作表中。
相关知识
为了完成本关任务,你需要掌握:1.读取 excel 文件;2.筛选 dataframe 数据;3.将数据写入工作簿和工作表。
从 excel 文件读入数据
pd.read_excel(filename,sheet_name=0,header=0,index_col=None,names=None,dtype=None)
filename:指定电子表格的具体路径
sheet_name:指定需要读取电子表格中的第几个 sheet,既可以传递整数也可以传递具体的 Sheet 名称
header:是否需要将数据集的第一行用作表头,默认为是需要的
index_col:指定哪些列用作数据框的行索引(标签)
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头
dtypes:通过字典的形式,指定某些列需要转换的形式
向 excel 文件写入数据
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='',
float_format=None, columns=None, header=True, index=True,
index_label=None, encoding=None)
excel_writer: 文件路径或现有的 ExcelWriter。
sheet_name:字符串,表的名称。默认“Sheet1”。
na_rep: 字符串,默认‘ ’,缺失数据表示方式。
float_format: 字符串,默认None,格式化浮点数的字符串。
columns: 列表,要写入的列。
header: 布尔或字符串列表,默认为Ture。如果给定字符串列表,则它是列名。
index:布尔,默认的Ture,行名(索引)。
index_label: 字符串或序列,默认为None。
注意:通过 ExcelWriter 写入后要同执行save()保存。
DataFrame
-
唯一值函数
unique()是以数组形式返回列的所有唯一值 -
筛选数据
Pandas 的.loc参数可以对多列数据进行筛选,并且支持不同筛选条件逻辑组合。
常用的筛选条件包括等于(==),不等于(!),大于(>),小于(<),大于等于(>=) ,小于等于(<=)等等。逻辑组合包括与(&)和或(|)。
list1=[["张三",'男'],["李四",'女'],["王五",'男'],["赵六",'女']]
import panda as pd
df=pd.DataFrame(list1,columns=["姓名","性别"])
则 df
姓名 性别
0 张三 男
1 李四 女
2 王五 男
3 赵六 女
df["性别"].unique()
“男”,"女"
df.loc[df["性别"]=="男"]
姓名 性别
0 张三 男
2 王五 男
编程要求
根据提示,在右侧编辑器补充代码,建立 excel 文件“类别销售”,根据不同类别建立多个工作表,将相同类别的销售信息存放在相应的工作表中。
测试说明
平台会对你编写的代码进行测试:
输入类别,系统将显示该类别工作表的日期,商品编码,商品名称和合计金额四列信息
测试输入:调料;
预期输出:
日期 商品编码 商品名称 合计金额
0 2000-05-30 \t090202010048 \t裕荣虾味先虾条(原味)80g 7.7
1 2000-06-22 \t090202010071 \t四季宝颗粒花生酱340g 13.3
2 2000-06-24 \t090202010035 \t牛头牌鸡汤块66g 7.7
3 2000-07-18 \t090202010024 \t金兰拌面拌饭酱370g 20.4
测试输入:电池;
预期输出:
日期 商品编码 商品名称 合计金额
0 2000-06-14 \t010105010002 \t金霸王7号2粒 5.2
1 2000-06-14 \t010105010005 \t金霸王超能量(m3)7号2粒 6.2
2 2000-07-16 \t010105010007 \t南孚电池7号5粒装 8.9
运行代码
import pandas as pd
df=pd.read_excel("xlscl/step1/超市销售数据.xlsx",dtype={"商品编码":str,"商品条码":str})
writer = pd.ExcelWriter("xlscl/step1/类别销售.xlsx")
#代码开始
x=df["类别"].unique() #获取商品类别
for i in x:
leibie=df.loc[df["类别"]==i]
leibie.to_excel(writer,sheet_name=i,index=False)
writer.save()
#代码结束
第2关:将银行信息excel文件按地区筛选
任务描述
本关任务:编写一个将银行信息的 excel 文件筛选存储的小程序
银行分布 excel 文件如图所示

请编写程序,在 test 文件夹下建立 excel 文件银行一线城市,将北京市、上海市、广州市、深圳市的银行编号、名称按银行编号从小到大的顺序放置到不同的excel 工作表中

提示:可以将城市的名字放入列表
运行代码
import pandas
writer = pandas.ExcelWriter('test/银行一线城市.xlsx')
data=pandas.read_excel("test/银行信息.xlsx",dtype={"银行编号":str})
#代码开始
list1 = ["北京市","上海市","广州市","深圳市"]
for i in list1:
ans = data.loc[data["城市"]==i,["银行编号","名称"]]
ans = ans.sort_values("银行编号")
ans.to_excel(writer,sheet_name=i,index=False)
#代码结束
writer.save()
第3关:将gdpecxcel文件按年份筛选存储
任务描述
本关任务:编写一个将 GDP 信息的 excel 文件筛选存储的小程序
各省 GDPexcel 文件如图所示

请编写程序,在 test 文件夹下建立 excel 文件 GDP 分年份,将2000-2016年每年建一个工作表,将该年各省的省份、GDP 称按 GDP 从大到小的顺序放置
注意:工作表的名称为字符形

DataFrame 类型的排序数据
pandas 中的sort_values()函数,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
DataFrame.sort_values(by=”列名”,axis=0,ascending=True,inplace=False)
by:axis轴上的某个索引或索引列表。
axis=0按列排序 axis=1按行排序 默认按列。
ascending是否按指定列的数组升序排列,默认为True,即升序排列。
inplace是否用排序后的数据集替换原来的数据,默认为False,即不替换。
运行代码
import pandas
writer = pandas.ExcelWriter('test/GDP分年份.xlsx')
data=pandas.read_excel("test/各省GDP.xlsx",dtype={"年份":str},)
#代码开始
for i in range(2000,2017):
ans = data.loc[data["年份"] == str(i), ["省份","GDP"]]
ans = ans.sort_values("GDP", ascending = False)
ans.to_excel(writer, sheet_name = str(i), index = False)
#代码结束
writer.save()
第4关:统计超市销售excel文件各类别和各日的数据,并将统计结果存入新的工作簿
任务描述
本关任务:打开超市销售数据工作簿

使用 excel 建立一个统计数据工作簿,建立一个工作表类别统计,按合计金额降序显示不同类别销售金额的和。

建立一个工作表日期统计,按日期升序显示不同日期销售金额的和

相关知识
为了完成本关任务,你需要掌握:1.DataFrame 如何汇总数据;2.DataFrame 如何排序数据。
DataFrame 类型的汇总数据
Groupby 可以根据一个或多个键对 DataFrame 计算分组摘要统计,
如计数、求和、平均值、标准差,或用户自定义函数。
例如
list1=[["张三",'男'],["李四",'女'],["王五",'男'],["赵六",'女']]
import pandas as pd
df=pd.DataFrame(list1,columns=["姓名","性别"])
则df
姓名 性别
0 张三 男
1 李四 女
2 王五 男
3 赵六 女
df.groupby(["性别"])["姓名"].count()
性别
女 2
男 2
DataFrame.groupby(by=None, axis=0, as_index=True)
by :标签或标签列表;用于确定分类的列。
axis: 接收 0/1;用于表示沿行(0)或列(1)分割。
as_index:默认Ture,汇总后会建立一个序列存放汇总的结果。汇总的列是序列的index 索引,统计值的列是序列的数值。
指定为 False 则汇总结果是一个数据集,汇总列和统计值都是列。
序列类型的排序
序列的sort_values() 函数,可以将序列依照数据进行排序。
series1.sort_values(ascending=True,inplace=False)
ascending是否按指定列的数组升序排列,默认为 True,即升序排列。
inplace 是否用排序后的数据集替换原来的数据,默认为 False,即不替换。
序列的 sort_index() 函数,可以将序列依照索引列进行排序。
编程要求
根据提示,在右侧编辑器补充代码,使用 excel 建立一个统计数据工作簿,建立一个工作表类别统计,按合计金额降序显示不同类别销售金额的和;
建立一个工作表日期统计,按日期升序显示不同日期销售金额的和。
测试说明
平台会对你编写的代码进行测试:
输出两个工作类别统计工作表和日期统计工作表的数据
运行代码
import pandas as pd
df=pd.read_excel("xlscl/step1/超市销售数据.xlsx")
writer = pd.ExcelWriter('xlscl/step2/统计数据.xlsx')
#代码开始
excel1 = df.groupby("类别")["合计金额"].sum()
excel1.sort_values(ascending = False, inplace = True)
excel1.to_excel(writer, sheet_name= "类别统计")
excel2 = df.groupby("日期")["合计金额"].sum()
excel2.sort_index(inplace = True)
excel2.to_excel(writer, sheet_name = "日期统计")
writer.save()
#代码结束
第5关:将超市销售excel文件分别存放在多个日期工作簿的不同类别工作表中
任务描述
本关任务:
超市销售数据如图所示
在 xlscl/step3/rq 文件夹下根据销售的日期建立不同的 excel 文件,
将同一类别的销售信息存放在 excel 文件的不同工作表中。

并建立类别统计工作表,显示该日各类别的合计金额的和,按合计金额的降序排列。

编程要求
根据提示,在右侧编辑器补充代码。
注意:由于文件名只能是字符形,所以需要将日期型数据转换为字符形
可以使用 str(日期时间数据).replace('-',"")[:8]
将日期时间的字符的-删除再取前8个字符
此外,文件需要保存再 xlscl 的 step3 文件夹下的 rq 文件夹下
测试说明
平台会对你编写的代码进行测试:
测试输入:
20000525
零食
预期输出:
商品编码 商品名称 合计金额
0 90101030095 \t康师傅苏打夹心香草巧克力饼干96g 4.5
1 90101030100 \t百力滋巧克力味50G 3.6
2 90101070032 \t糙米馆荞麦150g 6.9
3 90101090052 \t益民盐津杨梅180g 6.9
4 90101090054 \t益民精盐桃肉160g 6.9
5 90101090055 \t益民咸话梅110g 6.9
6 90101090057 \t益民多味山楂180g 6.9
7 90101090058 \t益达无糖口香糖蓝莓味13.5g 1.9
8 90102010035 \t黑塘麦芽饼500g 27.8
9 90103010048 \t渝业烧烤豆干80g 1.9
10 90103010053 \t金锣Q香香肠老汤味100g 2.1
类别 合计金额
0 酒 384.0
1 烟 344.5
2 零食 76.3
3 饮料 38.2
4 冷饮 22.0
5 奶制品 15.5
6 方便面 3.5
7 纸制品 2.1
测试输入:
20000530
烟
预期输出:
商品编码 商品名称 合计金额
0 90501000012 \t黄鹤楼(硬雅香) 40
1 90501000016 \t黄金叶(软大金圆) 20
2 90501000021 \t南京(红) 22
类别 合计金额
0 零食 115.1
1 烟 82.0
2 饮料 49.2
3 冷饮 22.5
4 奶制品 9.8
5 调料 7.7
6 纸制品 6.1
7 方便面 3.5
运行代码
import pandas as pd
df=pd.read_excel("xlscl/step1/超市销售数据.xlsx",dtype={"商品编码":str,"商品条码":str})
#代码开始
data =df["日期"].unique()
for i in data:
file_name = str(i).replace('-', "")[:8]
writer = pd.ExcelWriter('xlscl/step3/rq/'+file_name+'.xlsx')
excel1 = df.loc[df["日期"] == i]
Class = df["类别"].unique()
for j in Class:
excel2 = excel1.loc[df["类别"] == j]
excel2.to_excel(writer, sheet_name = j, index = False)
excel3 = excel1.groupby("类别")["合计金额"].sum()
excel3.sort_values(ascending = False, inplace = True)
excel3.to_excel(writer, sheet_name = "类别统计", index_label = "类别")
writer.save()
#代码结束