Python字符串
字符串的含义
字符串 就是 一串字符,是编程语言中表示文本的数据类型;
字符串的定义
- 一对双引号 " "
- 一对单引号 ' '
- 三对双引号""" """
- 三对单引号''' '''
例:
a = 'tom'
b = "tom"
c = '''tom'''
d = """tom"""
print(a,b,c,d)
# \是折行标记,说明两个单词是在同一行的意思
s1 = "hello" \
"world"
# 单引号和双引号都不能直接换行,必须在中间添加\n来表示换行
s = 'hello\nworld'
# 对于三引号来说是可以换行的
s = '''hello
world'''
s1 = """hello
world"""
# 怎样把\n原样打印?
# 1、在\前面再加一个\,
# 2、使用原始字符串r,表示后面的每个字符都是普通字符
s2 = 'hello\\nworld'
s3 = r'hello\nworld'
# 问题:如果字符串中需要使用引号怎么办?
# 创建⼀个字符串 I'm Tom
# 单双引号交叉使用
c = "I'm Tom"
# 使用转义字符
d = 'I\'m Tom'
注:
虽然可以使用
\"或者\'做字符串的转义,但是在实际开发中:
- 如果字符串内部需要使用
",可以使用'定义字符串- 如果字符串内部需要使用
',可以使用"定义字符串- 大多数编程语言都是用
"来定义字符串
字符串[索引]
索引 (index)/下标,从0开始计算,-1代表最后一个
s = 'IlovePython'
print('s[3]=', s[3])
逆向索引
s = 'IlovePython'
print('s[-1]', s[-1])字符串的切片
定义
- 切片是指对操作的对象截取其中一部分的操作
- 字符串切片是从一个大的 字符串中切出小的字符串;
- 切片 方法适用于 字符串、列表、元组;
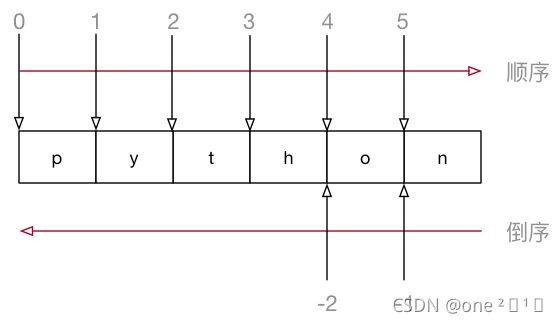
语法
字符串名[开始索引:结束索引:步长]
指定的区间属于 左闭右开 型,类似于range函数,从 起始 位开始,到 结束位的前一位 结束
开始索引: 数字可以省略,正负数均可
结束索引:数字可以省略,正负数均可
步长:步长是选取间隔,正负数均可,默认为
1冒号:第一个不能省略,第二个如果连续切片,可以省略
倒序索引,是 从右向左 计算索引,最右边的索引值是 -1,依次递减
s = 'IlovePython'
# 分片,类似于range函数,从起始位置,到后面索引位置的前一个字符
# s = [start, end, step]
print('s[0: 2]', s[0: 2])
# 当冒号左边空的时候,表示从最左边的位置,到索引的前一个位置
print('s[:5]=',s[:5])
# 当冒号右边空的时候,表示从冒号左边的位置到右边的最后一个位置
print('s[1:]=',s[1:])
# 两边都空的时候表示整个字符串范围
print('s[:]=',s[:])
# 步长默认为1
print('s[::2]=', s[::2])
print('s[::-1]=', s[::-1])切片练习
um_str = "0123456789"
# 1. 截取从 2 ~ 5 位置 的字符串
print(num_str[2:6])
# 2. 截取从 2 ~ `末尾` 的字符串
print(num_str[2:])
# 3. 截取从 `开始` ~ 5 位置 的字符串
print(num_str[:6])
# 4. 截取完整的字符串
print(num_str[:])
# 5. 从开始位置,每隔一个字符截取字符串
print(num_str[::2])
# 6. 从索引 1 开始,每隔一个取一个
print(num_str[1::2])
# 倒序切片
# -1 表示倒数第一个字符
print(num_str[-1])
# 7. 截取从 2 ~ `末尾 - 1` 的字符串
print(num_str[2:-1])
# 8. 截取字符串末尾两个字符
print(num_str[-2:])
# 9. 字符串的逆序(面试题)
print(num_str[::-1])字符串支持的运算符
+、*
- 相加表示拼接
- 字符串相乘只能乘以整数,相当于把原字符串重复了多少次
s1 = 'hello'
s2 = 'world'
r = s1 + s2
s = s1 * 3
print(r)
>>>helloworld
print(s)
>>>hellohellohello
字符串函数
统计字符串长度len()
对于字符串来说是字符的数目,对于序列来说是元素的个数
hello_str = "hello hello"
print(len(hello_str))统计某一个子字符串出现的次数count()
print(hello_str.count("llo"))
print(hello_str.count("abc"))判断类型 - 9
| 方法 | 说明 |
|---|---|
| string.isspace() | 如果 string 中只包含空格,则返回 True |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| string.isdecimal() | 如果 string 只包含数字则返回 True,全角数字 |
| string.isdigit() | 如果 string 只包含数字则返回 True,全角数字、⑴、\u00b2 |
| string.isnumeric() | 如果 string 只包含数字则返回 True,全角数字,汉字数字 |
| string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
# 判断空白字符
space_str = " \t\n\r"
print(space_str.isspace())# 1> 小数
# num_str = "1.1"
# 2> unicode 字符串
# num_str = "\u00b2"
# 3> 中文数字
num_str = "一千零一"
print(num_str)
# 判断单纯的数字
print(num_str.isdecimal())
# 数字+unicode 字符串
print(num_str.isdigit())
# 数字+unicode 字符串+中文数字
print(num_str.isnumeric())
# 判断一个字符串是否是全部以大小写字母构成
print('dasdf'.isalpha())判断开头结尾
startswith()
检查字符串是否是以指定⼦串开头,是则返回 True,否则返回 False。如果设置开 始和结束位置下标,则在指定范围内检查。
语法:
字符串序列.startswith(⼦串, 开始位置下标, 结束位置下标)
endswith()
检查字符串是否是以指定⼦串结尾,是则返回 True,否则返回 False。如果设置开 始和结束位置下标,则在指定范围内检查。
语法:
字符串序列.endswith(⼦串, 开始位置下标, 结束位置下标)
查找和替换 - 7
| 方法 | 说明 |
|---|---|
| string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
| string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1 |
| string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.replace(old_str, new_str, num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
hello_str = "hello world"
# 1. 判断是否以指定字符串开始
print(hello_str.startswith("Hello"))
# 2. 判断是否以指定字符串结束
print(hello_str.endswith("world"))
# 3. 查找指定字符串
# index同样可以查找指定的字符串在大字符串中的索引
print(hello_str.find("llo"))
# index如果指定的字符串不存在,会报错
# find如果指定的字符串不存在,会返回-1
print(hello_str.find("abc"))
print(hello_str.index("llo"))
# 注意:如果使用index方法传递的子字符串不存在,程序会报错!
print(hello_str.index("abc"))
# 4. 替换字符串
# replace方法执行完成之后,会返回一个新的字符串
# 注意:不会修改原有字符串的内容
print(hello_str.replace("world", "python"))
print(hello_str)大小写转换 - 5
| 方法 | 说明 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.title() | 把字符串的每个单词首字母大写 |
| string.lower() | 转换 string 中所有大写字符为小写 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.swapcase() | 翻转 string 中的大小写 |
s = 'i lovep ython'
# 返回字符大写格式的字符串,不改变原字符串
print(s.upper())
print(s)
# 返回字符小写格式的字符串,不改变原字符串
print(s.lower())
# 首字母大写
print(s.capitalize())
# 每个单词首字母大写
print(s.title())
# 大小写格式反转
print(s.swapcase())文本对齐 - 3
| 方法 | 说明 |
|---|---|
| string.ljust(width,填充字符) | 返回一个原字符串左对齐,并使用填充字符填充至长度 width 的新字符串,默认为空格 |
| string.rjust(width,填充字符) | 返回一个原字符串右对齐,并使用填充字符填充至长度 width 的新字符串,默认为空格 |
| string.center(width,填充字符) | 返回一个原字符串居中,并使用填充字符填充至长度 width 的新字符串,默认为空格 |
去除空白字符 - 3
| 方法 | 说明 |
|---|---|
| string.lstrip() | 截掉 string 左边(开始)的空白字符 |
| string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| string.strip() | 截掉 string 左右两边的空白字符 |
# 假设:以下内容是从网络上抓取的
# 要求:顺序并且居中对齐输出以下内容
poem = ["\t\n登鹳雀楼",
"王之涣",
"白日依山尽\t\n",
"黄河入海流",
"欲穷千里目",
"更上一层楼"]
for poem_str in poem:
# 先使用strip方法去除字符串中的空白字符
# 再使用center方法居中显示文本
print("|%s|" % poem_str.strip().center(10, " "))
s = '====helloworld==='
# 剔除字符串两端的指定字符
print(s.strip('='))
# 剔除字符串左边的指定字符
print(s.lstrip('='))
# 剔除字符串右边的指定字符
print(s.rstrip('='))拆分和连接 - 5
| 方法 | 说明 |
|---|---|
| string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| string.split(str="", num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 '\r', '\t', '\n' 和空格 |
| string.splitlines() | 按照行('\r', '\n', '\r\n')分隔,返回一个包含各行作为元素的列表 |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
# 假设:以下内容是从网络上抓取的
# 要求:
# 1. 将字符串中的空白字符全部去掉
# 2. 再使用 " " 作为分隔符,拼接成一个整齐的字符串
poem_str = "登鹳雀楼\t 王之涣 \t 白日依山尽 \t \n 黄河入海流 \t\t 欲穷千里目 \t\t\n更上一层楼"
print(poem_str)
# 1. 拆分字符串
poem_list = poem_str.split()
print(poem_list)
# 2. 合并字符串
result = " ".join(poem_list)
print(result)
# 把字符分割成3部分,返回元组
s = 'holle==world'
print(s.partition('='))合并字符串
join():⽤⼀个字符或⼦串合并字符串,即是将多个字符串合并为⼀个新的字符串。
语法:
字符或⼦串.join(多字符串组成的序列)
list1 = ['chuan', 'zhi', 'bo', 'ke']
t1 = ('aa', 'b', 'cc', 'ddd')
# 结果:chuan_zhi_bo_ke
print('_'.join(list1))
# 结果:aa...b...cc...ddd
print('...'.join(t1))编码解码
# 把字符串编码乘字节序列
s = 'hello哈哈哈哈'
a = s.encode()
print(type(a))
print(a)
# 把字节序列解码乘字符串
b = a.decode()
print(type(b))
print(b)
字符串中字符获取
- 使用 索引 获取一个字符串中 指定位置的字符,索引计数从 0 开始;
- 使用
for循环遍历 字符串中每一个字符
string = "Hello Python"
str2 = '我的外号是"大西瓜"'
#打印字母p
print(string[6])
#循环遍历打印子字符
for c in string:
print(c)