【C++】函数重载详解
C语言下的函数名弊端
#include
int Add(int a, int b)
{
return a + b;
} 我编写了一个简单的 Add 函数来执行整数相加,它既简单又能够达到我想要的效果。然而,如果我现在需要一个能够执行浮点数相加的函数怎么办呢?一种方法是重新编写一个函数,但是问题是该如何命名呢?已经有一个 Add 函数了,如果取相同的名字就会出现命名冲突,而重新选择名字又显得繁琐。为了解决这个问题,C++中引入了函数重载。
概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数或类型或类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
注意:对返回值没有要求。如果返回值不同也能构成重载的话,那么两个无参且返回值不同的同名函数时,到底是调用哪一个函数编译器并不清楚,会产生二义性。
参数类型不同
#include
using namespace std;
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
int main()
{
printf("%d\n", Add(1, 2));
printf("%lf\n", Add(3.2, 2.8));
return 0;
} 这里两个同名函数参数类型不同构成重载。
值得注意的是:在调用存在函数重载的函数时,传入的参数类型要与期望调用的函数的参数类型匹配,否则可能会导致歧义。例如,下面的代码中,调用 Add 函数时,传入的参数 3.2 和 1 的类型分别为 double 和 int,可能导致编译器无法确定应该调用哪个重载函数。在这个示例中,我们只需要屏蔽掉两个 Add 函数中的一个就不会报错了。

参数个数不同
#include
using namespace std;
void funcA()
{
cout << "funcA()" << endl;
}
void funcA(int a)
{
cout << a << endl;
}
int main()
{
funcA();
funcA(1);
return 0;
} 参数个数不同同样构成重载。
我在上一篇博客中介绍了缺省参数:给传参加上自动挡-CSDN博客
可能你会好奇,如果上面第二个 funA 函数的形参加上缺省值能不能构成重载呢?我们来试下吧。

我们看到编译器直接红温了。因为当调用无参的 funcA 函数时,编译器不知道调用的是哪个函数,可能你是真的无参,可能你是想用缺省值,这就造成了二义性。所以如果你写了这样的两个函数,当你调用时必须要传参。这里也可以发现这两个函数确实构成了重载,它们的参数个数确实是不同的。但是也只能调用带参数的那个函数,所以看似写了两个函数,实际上只有一个是可以用的。因此这种重载的形式是没意义的。
参数类型顺序不同
#include
using namespace std;
void fun(char a, int b)
{
cout << "fun(char a, int b)" << endl;
}
void fun(int a, char b)
{
cout << "fun(int a, char b)" << endl;
}
int main()
{
fun('a', 1);
fun(1, 'a');
return 0;
} 这里虽然两个函数的参数类型都是一个 int 一个 char,但是顺序不同,因此也构成重载。
为什么支持函数重载
到目前为止,你应该对C++中函数重载的条件和价值有了初步的了解。那么,为何C语言不支持这样的高级功能,而C++却能够做到呢?下面我们将更深入地探讨这个问题。
回顾一下,在C/C++中,程序的运行经历了四个关键步骤:
1. 预处理阶段:在这个阶段,主要完成宏替换、头文件展开、注释删除以及条件编译等操作。处理后会生成一个后缀为 .i 的文件,为后续编译过程提供了基础。
2. 编译:在 .i 文件的基础上进行语法检查,包括语法分析、词法分析、语义分析和符号汇总等操作。最终生成符号表,符号表记录了程序中使用的各种符号(如变量、函数名、常量等)以及它们在内存中的地址或其他相关信息。这个阶段的输出是一个汇编代码文件(.s 文件)。值得强调的是,在生成汇编代码时,函数的调用会被标记为一个 call 指令,其中存储了该函数在代码段的地址。当程序执行到这个 call 指令时,会跳转到相应的函数汇编代码处,并开始创建函数栈帧以及执行具体函数的实现。需要特别注意的是,如果函数的定义和声明分离,这里的 call 指令并没有具体的地址,只是先标记个名字,具体的函数地址会在最后的链接阶段通过这个名字去查找。如果找不到函数定义,链接阶段会报错。
3. 汇编:将代码翻译成机器语言的过程,简单来说就是将 .i 文件中的汇编代码转换成二进制的机器码并生成 .o 文件。
4. 链接:将编译生成的目标文件合并为可执行文件。在链接阶段,编译器将解析符号引用,确定符号的地址,执行重定位,最终生成一个包含所有必要信息的可执行文件,以便在运行时被操作系统加载和执行。这一过程确保了程序的各个部分正确连接,并能够在内存中协同工作。编译中提到的链接不确定的函数地址就是在这一步骤中通过合并汇总后的符号表完成的。链接成功后,windows下生成后缀为 .exe的可执行文件,Linux下则是默认生成 a.out 的可执行文件。
现在你对这四个步骤已经有一定的了解了,那么我们来解决如何寻找函数地址,也就是如何为函数命名的问题。这里以Linux下的 gcc 和 g++编译器来展示C和C++在编译阶段是怎么为函数命名的。
首先来看 C++对应的 g++编译器是怎么做的:

这里我用 vim 写了一段代码,接下来我们看一下用 g++编译过后的结果:
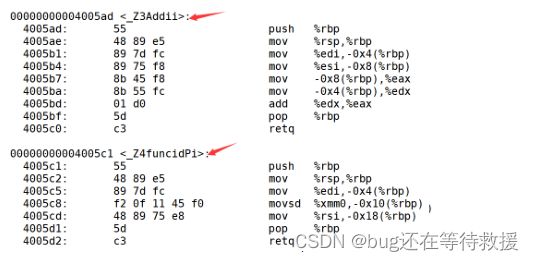
可以发现在Linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。修饰过后的名字以 _Z 开头,接着是函数名的字符个数,然后是函数名,最后是参数类型的简称。这也就解释了为什么函数重载支持参数个数、类型、类型顺序的不同,但不支持返回值的不同,因为在这个命名规则中并未包含返回值信息。
接下来用同一段代码我们来看看C语言编译器也就是Linux下的gcc编译器是怎么命名的:

注意到了吧,在Linux下使用gcc编译后,函数名并没有被修饰,仍然保持原始函数名。这也解释了为什么C语言无法支持函数重载,因为同名函数将无法被编译器区分。
windows下vs编译器对函数名字修饰规则相对复杂难懂,但道理都是类似的,这里就不做细致的研究了,感兴趣的话可以上网找一下相关资料。