数据挖掘体系介绍
数据挖掘是什么?
简而言之,对数据进行挖掘,从中提取出有效的信息。一般我们会把这种信息通过概念、规则、规律、模式等有组织的方式展示出来,形成所谓的知识。特别是在这个大数据时代,当数据多到一定程度,统计学原理会让一些内在的、不易察觉的规律慢慢放大、展示出来,而数据挖掘,就是希望在这种大数据背景下,以一种更加高效的方式,找到这些潜在的规律。
数据挖掘怎么做?
数据挖掘的基本流程可以总结为以下几个阶段:数据探索、数据预处理、数据建模、模型评估和模型部署应用。
数据探索
- 目的:了解和熟悉数据集的基本特征,包括数据的分布、类型和潜在的问题。
- 方法:使用统计分析和可视化手段,如散点图、直方图和盒图,以识别数据中的模式、异常值和相关性。
- 重点:评估数据的质量和适用性,确定是否需要额外数据。
数据预处理
- 目的:清洗和准备数据,以便于建模。
- 方法:
- 数据清洗:处理缺失值、异常值和重复数据。
- 数据转换:标准化、归一化和离散化。
- 数据降维:通过主成分分析(PCA)等方法减少数据集的维度。
- 重点:提高数据的质量,确保模型训练的准确性和效率。
数据建模
- 目的:应用统计或机器学习算法来构建预测或分类模型。
- 方法:
- 选择合适的算法,如决策树、神经网络或支持向量机。
- 使用训练数据集训练模型。
- 重点:寻找最适合数据特征和业务需求的模型。
模型评估
- 目的:验证模型的性能和准确性。
- 方法:
- 使用测试数据集对模型进行评估。
- 应用各种评估指标,如准确率、召回率、F1分数和ROC曲线。
- 重点:确保模型具有良好的泛化能力,即在新数据上的表现。
模型部署应用
- 目的:将训练好的模型应用于实际问题中。
- 方法:
- 集成模型到生产环境。
- 实施持续监控和维护,确保模型的稳定性和效能。
- 重点:实现模型的实际应用,提供持续的支持和优化。
数据预处理的多种方法
数据预处理是数据挖掘流程中至关重要的环节,其目的在于将原始数据转换成更适合分析的形式,以提高后续建模的效果和准确性。详细介绍数据预处理的各个方面如下:
数据清洗:
- 处理缺失值:缺失值的处理方法取决于缺失的原因和数据的类型。常见的处理方式包括使用均值、中位数或众数填充、使用模型预测缺失值,或者简单地删除含有缺失值的记录。在一些情况下,缺失本身也可能是一个重要的信号,可以将其编码为一个特定的值。
- 处理异常值:异常值可能是由于错误的数据输入、测量错误或其他偏差造成的。可以通过箱线图或标准差方法识别异常值。处理方法包括删除异常值、进行数据转换(如对数转换),或用统计方法(如平均值)替换。
- 消除重复数据:重复数据可能导致分析结果的偏差。通过识别和删除重复记录,可以确保数据的一致性和准确性。
数据转换:
- 规范化/标准化:这是将数据转换成通用格式的过程,例如将所有的日期格式统一,或者将温度值从摄氏度转换为华氏度。
- 标准化/归一化:特别在处理涉及多个不同规模和分布的变量的数据时非常重要。Z得分标准化(使数据具有均值为0,标准差为1)和Min-Max归一化(将数据缩放到特定的范围,如0到1)是常见的方法。
- 离散化:这是将连续变量转换成离散变量的过程。例如,年龄可以被分为不同的年龄段,如“儿童”、“青少年”、“成人”和“老年”。
数据降维:
- 特征选择:从原始数据中选择最相关和有意义的特征,以减少数据的维度和复杂性。这可以通过相关性分析、信息增益等统计方法来实现。
- 特征提取:通过数学变换从原始特征中提取新的特征集合。例如,主成分分析(PCA)是一种常用的特征提取方法,它通过正交转换将可能相关的变量转换为一组线性不相关的变量。
数据编码:
- 独热编码(One-Hot Encoding):这是一种处理类别型数据的方法,其中每个类别值被转换成一个二进制列。
- 标签编码(Label Encoding):这是将类别标签转换为一个序列的数值的方法,常用于标记具有顺序意义的类别数据。
时间序列数据处理:
对于时间序列数据,预处理可能包括平滑处理、季节性和趋势去除、时间窗口的选择等。这些步骤有助于识别和强化数据中的重要模式和结构。
文本数据处理:
对于文本数据,预处理步骤可能包括词干提取、停用词去除、词袋模型或TF-IDF转换。这些步骤将非结构化的文本数据转换为结构化的数值格式,便于进一步的分析和建模。
特征选择
特征选择的目的是从原始数据中选择出最有用的特征,以提高模型的性能和准确度。信息熵和信息增益是两种常用于特征选择的方法
信息熵(Entropy)
信息熵是衡量数据集纯度或混乱程度的指标,是所有可能事件产生的信息量的期望值。它在决策树算法中用来衡量一个系统的无序程度。信息熵越高,数据的不确定性越大。
公式
设随机变量 X X X 有 n n n 个可能的取值,每个值的概率分别为 p 1 p_1 p1, p 2 p_2 p2, … \dots …, p n p_n pn,则 X X X 的信息熵 H ( X ) H(X) H(X) 定义为:
H ( X ) = − ∑ i = 1 n p i log 2 p i H(X) = -\sum_{i=1}^{n} p_i \log_2 p_i H(X)=−i=1∑npilog2pi
信息增益(Information Gain)
信息增益衡量使用特征分割数据集前后信息熵的变化。在决策树中,它用来确定哪个特征最适合用于分割数据集。信息增益越大,意味着使用该特征分割得到的纯度提升越大。
公式
设 D 为待分割的数据集,其信息熵为 H ( D ) 。使用特征 A 分割 D 后得到 m 个子集 D 1 , D 2 , … , D m ,特征 A 对于数据集 D 的信息增益 I G ( D , A ) 定义为: 设 D 为待分割的数据集,其信息熵为 H(D) 。使用特征 A 分割 D 后得到 m 个子集D_1, D_2, \ldots, D_m,特征 A 对于数据集 D 的信息增益 IG(D, A) 定义为: 设D为待分割的数据集,其信息熵为H(D)。使用特征A分割D后得到m个子集D1,D2,…,Dm,特征A对于数据集D的信息增益IG(D,A)定义为:
I G ( D , A ) = H ( D ) − ∑ j = 1 m ( ∣ D j ∣ ∣ D ∣ ⋅ H ( D j ) ) IG(D, A) = H(D) - \sum_{j=1}^{m} \left( \frac{|D_j|}{|D|} \cdot H(D_j) \right) IG(D,A)=H(D)−j=1∑m(∣D∣∣Dj∣⋅H(Dj))
其中, ∣ D j ∣ 是子集 D j 中的样本数, ∣ D ∣ 是数据集 D 中的总样本数, H ( D j ) 是子集 D j 的信息熵。 其中, |D_j| 是子集 D_j 中的样本数, |D| 是数据集 D 中的总样本数, H(D_j) 是子集 D_j 的信息熵。 其中,∣Dj∣是子集Dj中的样本数,∣D∣是数据集D中的总样本数,H(Dj)是子集Dj的信息熵。
通过计算每个特征的信息增益,可以选择增益最大的特征进行数据分割。
属性最优子集(Feature Subset Search)
属性最优子集选择的主要任务是从所有可能的特征组合中找出最佳的一个或几个子集。这涉及到评估每个特征子集的有效性,并选择最能提高模型性能的那个。
递归特征消除(RFE)
递归特征消除(RFE)是一种包装方法,它递归地考虑越来越小的特征集来选择特征。RFE首先训练一个模型并对每个特征评分,然后去除最不重要的特征,再次训练模型,重复这个过程,直到达到指定的特征数量。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 载入数据
iris = load_iris()
X = iris.data
y = iris.target
# 创建一个逻辑回归分类器
model = LogisticRegression()
# RFE
rfe = RFE(model, n_features_to_select=3)
fit = rfe.fit(X, y)
# 输出结果
print("Num Features: %s" % (fit.n_features_))
print("Selected Features: %s" % (fit.support_))
print("Feature Ranking: %s" % (fit.ranking_))
分类问题与过拟合
- 分类问题与过拟合
数据分为测试集和训练集,先训练集来生成模型,再用测试集来验证模型
强调了将数据分为测试集和训练集的重要性。这种分割有助于评估模型的泛化能力和避免过拟合。
避免过拟合的策略:正则化、交叉验证和选择合适的模型复杂度。这些策略可以帮助确保模型不仅在训练数据上表现良好,而且能够有效地泛化到新的数据集。 - confusion matrix(混淆矩阵)
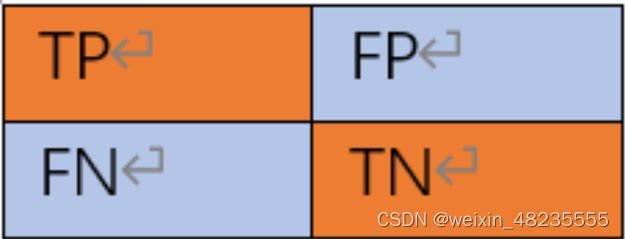
混淆矩阵被提及作为一种有效的评估工具,它可以展示模型在不同类别上的性能,包括真正例、假正例、真反例和假反例。
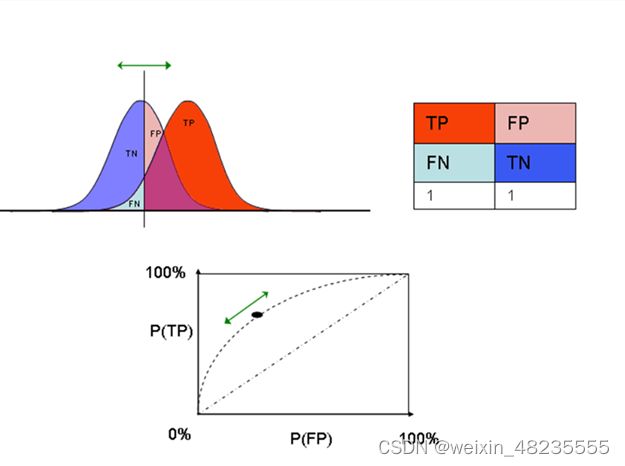
cost-sensitive learning代价敏感学习、lift analysis提升度分析
代价敏感学习和提升度分析是评估和改进模型性能的重要工具。
- 代价敏感学习侧重于识别和处理不同类型错误(如假阳性和假阴性)的代价。这意味着在训练模型时,考虑到不同错误的经济或其他成本,以优化模型的整体性能。
- 提升度分析则用于衡量模型相比于随机选择或无信息基线的改进程度。通过提升度分析,可以评估模型在实际应用中的效用,特别是在营销和风险评估等领域。
评价指标
在数据挖掘和机器学习中,评价指标用于衡量模型的性能。
-
准确性(Accuracy):模型预测正确的比例。准确性是最直观的性能指标,适用于类别分布均衡的场景。
A c c u r a c y = N u m b e r o f c o r r e c t p r e d i c t i o n s T o t a l n u m b e r o f p r e d i c t i o n s Accuracy = \frac{Number\ of\ correct\ predictions}{Total\ number\ of\ predictions} Accuracy=Total number of predictionsNumber of correct predictions
-
精确性(Precision):正确预测为正的实例占所有预测为正的实例的比例。精确性在需要最小化误报(比如垃圾邮件检测中误判为垃圾邮件的正常邮件)的场景中非常重要。
P r e c i s i o n = T r u e P o s i t i v e s T r u e P o s i t i v e s + F a l s e P o s i t i v e s Precision = \frac{True\ Positives}{True\ Positives + False\ Positives} Precision=True Positives+False PositivesTrue Positives -
召回率(Recall):正确预测为正的实例占实际正实例的比例。召回率在需要最小化漏报(如疾病筛查中漏诊病例)的情况下特别重要。
R e c a l l = T r u e P o s i t i v e s T r u e P o s i t i v e s + F a l s e N e g a t i v e s Recall = \frac{True\ Positives}{True\ Positives + False\ Negatives} Recall=True Positives+False NegativesTrue Positives -
F1分数(F1 Score):精确性和召回率的调和平均值,是一个综合考虑精确性和召回率的指标。F1分数在类别不平衡的情况下尤其有用,因为它同时考虑了误报和漏报。
F 1 S c o r e = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1\ Score = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1 Score=2×Precision+RecallPrecision×Recall