云原生消息流系统 Apache Pulsar 在腾讯云的大规模生产实践
导语
由 InfoQ 主办的 Qcon 全球软件开发者大会北京站上周已精彩落幕,腾讯云中间件团队的冉小龙参与了《云原生机构设计与音视频技术应用》专题,带来了以《云原生消息流系统 Apache Pulsar 在腾讯云的大规模生产实践》为主题的精彩演讲,在本篇内容中,将重点围绕腾讯云近期在 Apache Pulsar 稳定性和性能方面优化的工作展开介绍,为开发者提供参考。
作者简介
冉小龙
腾讯云高级研发工程师
Apache Pulsar committer
RoP maintainer
Apache Pulsar Go Client、Pulsarctl 与 Go Functions 作者与主要维护者
Apache Pulsar 作为云原生时代消息流系统,采用存储计算分离架构,支持大集群、多租户、百万级 Topic、跨地域数据复制、持久化存储、分层存储、高可扩展性等企业级和金融级功能。Apache Pulsar 提供了统一的消费模型,支持消息队列和流两种场景,既能为队列场景提供企业级读写服务质量和强一致性保障,又能为流场景提供高吞吐、低延迟。
Apache Pulsar 在腾讯云中已经得到大规模的生产实践,在过去一年中承接了诸多行业生态中不同的使用场景。在实际的生产实践中,腾讯云针对 Apache Pulsar 做了一系列的性能优化和稳定性功能方面的工作,来保障用户在不同的场景下系统的稳定高效的运行。本文围绕腾讯云近一年在 Pulsar 稳定性和性能方面优化最佳实践。
Pulsar 在腾讯云百万级 Topic 上的应用
为什么选择在生产环境中使用 Pulsar?
此前该用户使用 Kafka 集群来承载业务,由于业务的特定场景,集群的整体流量相对不大,但是需要使用的 Topic 较多。此前使用 Kafka 集群时,由于 Kafka 自身架构的限定,用户不能在一套集群中创建较多的 Topic,所以为了满足业务多 Topic 的使用场景,需要部署多套 Kafka 集群来满足业务的使用,导致业务使用的成本较大。
Pulsar 本身除了具备 Pub-Sub 的传统 MQ 功能外,其底层架构计算存储分离,在存储层分层分片,可以很容易地把 BookKeeper 中的数据 offload 到廉价存储上。Pulsar Functions 是 Serverless 的轻量化计算框架,为用户提供了 Topic 之间中转的能力。在开源之前,Pulsar 已在 Yahoo! 的生产环境中经历 5 年的打磨,并且可以轻松扩缩容,支撑多 Topic 场景。为了降低使用的成本,同时满足多 Topic 的业务场景,该用户切换到了 Pulsar 的集群上。
当前该用户的一套 Pulsar 集群可以承载 60W 左右的 Topic,在很好地满足了业务使用的场景的同时降低了使用成本。
Apache Pulsar 稳定性优化实践
实践 1:消息空洞的影响及规避措施
使用 Shared 订阅模式或单条 Ack 消息模型时,用户经常会遇到 Ack 空洞的情况。Pulsar 中单独抽象出了 individuallyDeletedMessages 集合来记录空洞消息的情况。该集合是开闭区间集合,开区间表明消息是空洞消息,闭区间表明消息已被处理。早期 Pulsar 支持单条 Ack 和批量 Ack 两种模型,后者对标 Kafka 的 Ack Offset。引入单条 Ack 模型主要针对在线业务场景,但也因此带来了 Ack 空洞问题。Ack 空洞即下图中 `individuallyDeletedMessage` 所展示的集合。
如何理解 individuallyDeletedMessage?以下图为例:

该记录中第一个 Ledger id 是 5:1280,该集合是闭区间,说明消息已经被 Ack;之后的 5:1281 是开区间,说明消息没有被 Ack。这里就用开闭区间的形式来区分消息是否被 Ack。
Ack 空洞的出现原因可能因为 Broker 处理失败,源于早期版本的设计缺陷,Ack 处理没有返回值。在 2.8.0 及以上版本中,对事务消息支持上引入了 AckResponse 概念,支持返回值。因此在早期版本中,调用 Ack 后无法确保 Broker 可以正确处理 Ack 请求。第二个原因可能因为客户端出于各种原因没有调用 Ack,在生产实践中出现较多。
为了规避 Ack 空洞,一种方法是精确计算 Backlog Size。因为在 Broker 上解析 Batch 消息会浪费性能,在 Pulsar 中对 Batch 消息的解析在消费者侧,因此一个 Entry 可能是单条消息也可能是 Batch 消息的。后者情况下 Batch 内的消息数量或形态是未知的。为此要精确计算 Backlog Size,但经过调研发现这种方法的复杂性和难度较大。
另一种方法是 Broker 的主动补偿策略。因为 individuallyDeletedMessage 存储在每一个 ManagedCursor,也就是每一个订阅对象到 Broker 实际类中的映射。每一个订阅都可以拿到对应的 individuallyDeletedMessage 集合,Broker 就可以主动把集合推送到客户端,也就是主动补偿。
接下来我们了解一下 Broker 主动补偿机制,即 Backlog 策略。在了解补偿机制之前,先要了解 Topic 可能的分布与构成。
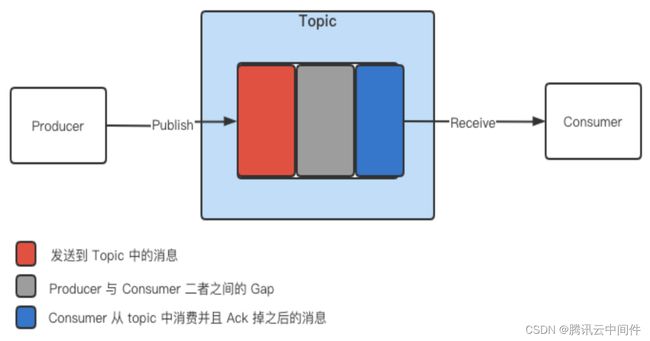
正常来说,生产者向 Topic 发布消息,消费者从 Topic 接收消息。如上图,红、灰、蓝色代表消息在 Topic 中的三种形态。Pulsar 中引入了 Backlog 策略,用来描述生产者和消费者之间的 Gap。该策略提供了三种选项,包括 Producer Exception、Producer Request Hold 和 Consumer Backlog Eviction。
其中,Producer Exception 相对用户友好,在生产环境中更加常用。当消息堆积到一定程度,消费者处理消息的能力不足时,Producer Exception 会通知生产者出现了问题。Producer Request Hold 原理相同,但是 Producer Request Hold 只是会让生产者停止发送,而不会告知其原因(即不会向业务侧返回标识),用户感知为 Producer 停止发送消息但是无异常抛出。而 Consumer Backlog Eviction 则会自动丢弃最早的消息来保证消息持续处理,可能导致丢消息的情况出现。

此外,还需要注意的是 Pulsar 计算 Backlog Size 的方式。上图可以理解为一个事件流,生产者源源不断地 append message。Pulsar 计算 Backlog Size 时,是计算从当前 MarkedDeletedPosition 的位置,到 ReadPosition 的位置之前的 Backlog Size,而后结合 Producer Exception 策略暴露出来。如果 Ack 空洞,比如 Broker 侧请求失败,或者客户代码产生异常导致 Ack 永远不会被调用,Backlog Size 会到达一定速率,就相当于限制生产者。上图中,M4 和 M2 是两条空洞消息,出现这样的空洞消息时,生产者的发送流就迟早会被打断。

Broker 主动补偿机制的实现方式如上图。由于 individuallyDeletedMessage 记录了所有消息的 Ack 成功与否的状态,就可以从中获取 MarkedDeletedPosition 位置的消息,开启一个 Executor Service 定时任务,设置监听频率,间隔一段时间将消息重新推送到客户端侧,实现 Broker 的主动补偿,避免 Ack 空洞导致 Producer Exception 被频繁触发。
实践 2:再谈 TTL、Backlog 及 Retention 策略
我们先看下这三个概念:
-
TTL:表示消息在指定时间内没有被用户 Ack 时会在 Broker 主动 Ack。
-
Backlog :表示生产者发送的消息与消费者接收消息之间的差距。
-
Retention:表示当消息被 Ack 之后,继续在 Bookie 侧保留多久的时间,以 Ledger 为最小操作单元。
如果 TTL 和 Retention 同时设置,那么一条消息的生命周期该如何计算?来看以下代码:
void updateCursor (ManagedCursor Impl cursor, PositionImpl newPosition) t
Pair pair = cursors.cursorUpdated (cursor, newPosition);
if (pair == nulL) {
Cursor has been removed in the meantime
trimConsumedLedgersInBackground();
return;
}
PositionImplpreviousSlowestReader = pair.getLeftO);
PositionImpl currentSlowestReader = pair.getRightO);
if (previousSlowestReader.compareTo(currentSlowestReader)==0){
// The slowest consumer has not changed position. Nothing to do right now
return;
}
//Only trigger a trimming when switching to the next Ledger
if (previousSlowestReader.getLedgerId() != newPosition.getLedgerId0)) f
trimConsumedLedgersInBackground();
}
-
TTL:根据设置的时间(默认五分钟)定期检查,根据触发的策略不断更新 cursor 位置,处理消息过期。
-
Retention:检查 Ledger 的创建时间(通过元数据时间戳可以了解 Ledger 的生命周期)以及 Entry 的大小两个阈值来决定是否删除某一个 Ledger。
在以上代码中的最后三行中,将之前最慢的 LedgerId 与 newPosition 的 LedgerId 对比,检查 ManagedLedger 是否发生过切换,一旦切换就调用 trimConsumedLedgersInBackground()。该函数方法的核心代码策略就是 Retention 的逻辑。
由此可知:
-
当 TTL 时间小于 Retention 时间时,消息的完整生命周期就是 TTL 时间 + Retention 时间;
-
当 TTL 时间大于等于 Retention 时间,消息的生命周期就是 TTL 时间。
这里又引出了一个新问题:TTL 策略为什么要选择在 Ledger 切换的时机来触发 Ledger 的删除操作呢?因为 Retention 删除 Ledger 时是以 Ledger 为最小操作单元。如果 Ledger 不切换,Retention 也不会触发删除。所以上述代码逻辑会选择切换时机来交给 Retention 执行删除动作。
实践 3:延迟消息与 TTL 的关系
在团队曾经遇到的场景中,某用户发送了数十万延迟消息,延迟设置为十天,但 TTL 过期时间设置为五天,五天后所有延迟消息都已被过期。我们可以从源码层面看一下 TTL 策略。
public boolean expireMessages(int messageTTLInSeconds) {
if (expirationCheckInProgressUpdater.compareAndSet( obj: this, FALSE, TRUE)) {
log.info("[{}][{}] Starting message expiry check, ttl= {} seconds", topicName, subName,
messageTTLInSeconds);
cursor.asyncFindNewestMatching(ManagedCursor.FindPositionConstraint.SearchActiveEntries, entry -> {
try {
long entryTimestamp = Commands.getEntryTimestamp(entry.getDataBuffer());
return Messaqelmpl.isEntryExpired(messageTTLInSeconds. entryTimestamp);
} catch (Exception e) {
log.error("[{}][{}] Error deserializing message for expiry check", topicName, subName, e);
} finally {
entrypublic static boolean isEntryExpired(int messageTTLInSeconds, long entryTimestamp) {
return messageTTLInSeconds != 0
&& (System.currentTimeMillis() >
entryTimestamp + TimeUnit.SECONDS.toMillis(messageTTLInSeconds));
}
TTL 的核心逻辑是通过 cursor 传入的值决定消息是否过期,即是否能找到 Entry。TTL 只获取了消息的发布时间,却没有理会消息的延迟设置。结合上面两段代码,isEntryExpired 只关心 PublishedTime 时间戳元数据属性,FindNewestMatchingEntry 对象时可以从元数据中获取 PublishedTime。所以当延迟设置小于 TTL 时间就会导致延迟消息被过期,在用户侧就会发现消息丢失。
针对这一问题,腾讯团队向社区提供了 PR,主要逻辑是分别检查消息的发布时间和延迟时间,到达发布时间后如果延迟时间大于 TTL 时间,则 TTL 时间到达后依然不能过期消息。IsEntryExpired 会判断并检查 TTL 时间与延迟时间。这里发布时间和延迟时间要一次性从 Entry 中获取,否则每次获取的 Entry 对象是不一样的。此外,延迟时间需要发送时间点的时间戳,根据具体计算出延迟的时间长度来做判断。
实践 4:Admin API Block 的优化处理
在 Pulsar 之前的代码逻辑中:
-
如果在异步代码中频繁调用同步逻辑,那么其中的牵连关系很可能导致 Pulsar 外部的线程卡住,这时只能重启对应的 Broker 节点来恢复任务。
-
Pulsar 的 Http Lookup 服务调用的是外部端口,一旦异步调用同步导致阻塞,那么该服务外部端口的数据流也会出现阻塞。
-
Pulsar Web 服务的性能较差,主要是因为 CompletableFuture 的误用。当我们定义一个 CompletableFuture 对象后,经常调用 thenapply 或者 thencompose 来返回对象。这其实是 CompletableFuture 内对象的同步返回,是由当前线程栈执行的。如果异步任务没有返回,则由回调线程执行任务。
-
Pulsar 高版本加入了 Metadata Store 线程池的抽象。这个抽象会增大 ZooKeeper 的压力。当同一时间内的外部服务调用量增大,ZooKeeper 负载增大会导致消息延迟等指标出现退化。
腾讯团队针对上述问题,一方面剥离了 Metadata Store 线程池,另一方面通过服务监听来定位和发现 Web 服务的性能较弱的位置,去做进一步的优化处理。此外,团队还加入了超时处理逻辑,所有 Pulsar 外部线程如果在最后限定时间(30 秒)内无法处理完成就会抛出超时。虽然单个外部线程超时、重启影响不大,但这样避免了整个数据流阻塞的情况。
实践 5:zk-node 泄露
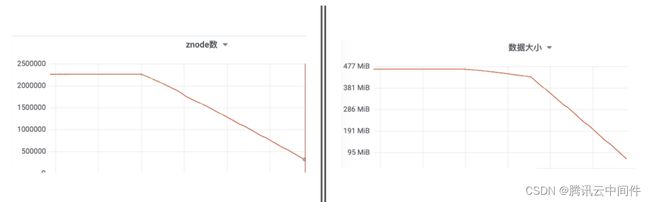
有时用户正在使用的 Topic 不多,但 zk-node 数量却很大,Pulsar 对 zk-node 的放大倍数较高。上图拐点是 zk-node 脏数据清理的时点,可以看到 zk-node 数据泄漏的情况非常严重,达到 5 倍之多。

在创建一个 Topic 时,首先要在 zk-path 的六级目录下涵盖所有 Topic 信息,在 ZooKeeper 上创建的资源量很大。此目录下涵盖了所有的 Topic,问题即出现在六个层级中。为此团队做了以下操作来处理 zk-node 脏数据:
-
首先通过 ZooKeeper client 读取 zk-path,按照指定的格式拼接所有 Topic 名字,获取 Topic 列表;
-
通过 pulsar-admin 检查集群中是否存在该 Topic;如果集群中不存在该 Topic,则相关数据一定是脏数据;(修复 zk-node 泄露问题的相关代码已 merge 进 2.8 + 的社区版本。)
-
切记在清理 ZookKeeper 脏数据之前备份 ZookKeeper 数据。
实践 6:Bookie Ledger 泄漏
团队在实践中发现,虽然 Retention 策略设置的消息生命周期最长应不超过 30 天,但检测扫描到的一些消息已经有数百天历史,且难以从 BookKeeper 中删除。针对这一问题,团队分析如下:
-
触发 Ledger 删除的唯一路径是 Retention 策略。这些消息产生的原因只能定位到一些 Bookie CLI 命令,这些命令生成了一些 Retention 策略管控不到的 Ledger。
-
每一个 Ledger 都有对应的 LedgerInfo,记录了它的元数据信息,包括创建时间等。获取元数据后,就可以确定 Ledger 是多久前创建的,还可以确定 Ledger 具体是在哪些 Bookie 节点上。
-
一个 Ledger 唯一归属于一个 Topic,所以可以获取 Topic 中存在 Ledger 的信息,进而确定某个 Ledger 是否存在于 Topic 的 Ledger 列表中,如果不在就是脏数据,可以清理。
-
如果 Ledger 对应的元数据已经丢失,那么 Ledger 本身也可以直接删除。
-
注意 Schema,如果忽略 Schema 可能会删除用户 Schema。恢复用户 Schema 时,Schema 的 Ledger 信息是存在 Bookie 中,Schema 自身的信息存在 Broker 归属的 ZK 中。恢复时需要先把 Broker 中存在的 Schema 信息删除,再让用户尝试使用生产端重建 Schema。
注意:执行以上操作前,切记提前备份数据。
实践 7:Apache Pulsar 多级缓存优化

如上图,Pulsar 现有缓存策略会导致明显的毛刺现象,出现服务周期性的剧烈性能波动和用户端的明显感知。
try {
//We need to check all the segments, starting from the current
//backward to minimize the
//checks for recently inserted entries
int size = cacheSegments.size();
for (int i = 0; i < size; i++)
int segmentIdx = (currentSegmentIdx + (size - i)) % size;
try {
int offset = currentSegmentOffset.getAndAdd(entrySize);
if (offset + entrySize > segmentSize) {
// Rollover to next segment
currentSegmentIdx = (currentSegmentIdx + 1) % cacheSegments.size();
currentSegment0ffset. set(alignedSize);
cacheIndexes.get(currentSegmentIdx).clear();
offset = 0;
}
这里腾讯团队主要做了读取缓存的优化。在读取缓存层面,可以看到 Pulsar 在读取缓存时迭代了缓存中的所有消息,如第一段代码倒数第二行所示。同时,一旦 offset + entrySize 大于 segmentSize,就会清除全部缓存,如第二段代码所示。这也就是为什么之前会出现明显的性能波动点的原因所在。
为此团队使用了 OHC + LRU 的策略,避免了缓存情况导致的剧烈波动,效果如下图:

总结与展望
本文分享了腾讯云团队在 Apache Pulsar 稳定性上的实践经验,重点介绍了消息空洞的影响及规避措施等最佳实践,为更多开发者提供参考。同时,腾讯云团队也在参与社区贡献中,和社区讨论以下重要问题并探索相关解决方案,如客户端超时时间内的重试策略,借鉴其他 MQ 的思路进行改进,尝试在客户端加入超时重试策略,通过多次重试机制来避免发送失败的情况发生;优化 Broker 和 Bookie OOM,针对 Ack 空洞对应集合无法缩容的问题进行改进;以及优化 Bookie Auto Recover,加入超时重试逻辑,避免 BookKeeper 和 ZooKeeper 之间发生 Session 超时的情况下服务重启。