HALLUSIONBENCH: An Advanced Diagnostic Suite for Entangled Language Hallucination & Visual Illusion
HALLUSIONBENCH: An Advanced Diagnostic Suite for Entangled Language Hallucination & Visual Illusion in Large Vision-Language Models
----
HALLUSIONBENCH:大型视觉语言模型中纠缠语言幻觉和视觉错觉的高级诊断套件
马里兰大学学院公园分校
Abstract
我们推出“HALLUSIONBENCH1”,这是一个专为评估图像上下文推理而设计的综合基准。该基准测试强调对视觉数据的细致入微的理解和解释,对高级大型视觉语言模型 (LVLM)(例如 GPT-4V(ision) 和 LLaVA-1.5)提出了重大挑战。该基准包括 346 张图像和 1129 个问题,全部由人类专家精心制作。我们为这些视觉问题引入了一种新颖的结构,旨在建立对照组。这种结构使我们能够对模型的响应倾向、逻辑一致性以及各种故障模式进行定量分析。在 HALLUSIONBENCH 的评估中,我们对 13 个不同的模型进行了基准测试,突出显示最先进的 GPT-4V 实现了 31.42% 的问题对准确率。值得注意的是,所有其他评估模型的准确率均低于 16%。此外,我们的分析不仅强调了观察到的故障模式,包括语言幻觉和视觉错觉,而且加深了对这些陷阱的理解。我们在 HALLUSIONBENCH 中进行的综合案例研究揭示了 LVLM 中幻觉和错觉的挑战。根据这些见解,我们提出了未来改进的潜在途径。可以通过此链接访问数据和注释。
1. Introduction
----
一、简介
近年来,大型语言模型(LLM)[8,9,25,37,42,43,56]凭借语言理解和内容生成的能力彻底改变了机器学习领域,在各个领域提供了前所未有的能力和潜力。大量的应用程序。法学硕士与计算机视觉系统的集成催生了大型视觉语言模型(LVLM)[5,7,21,26,31,37,38,45,46,51,58]。这些模型在各种应用中展示了深厚的能力,并显着提高了图像推理任务的性能[4,17,19,28,29,34,36,39]。然而,法学硕士[54]的幻觉问题被认为是一个具有挑战性且尚未解决的问题,当我们将法学硕士与视觉技术结合时,这会导致许多问题。
虽然像 GPT-4V(ision) [44] 和 LLaVA1.5 [30] 这样的 LVLM 在各种应用中表现出色,但它们受到明显的语言偏差的阻碍。这种偏见源于知识先验与视觉背景发生冲突的情况[23,27,53]。同样,无论问题的实际内容如何,LLaVA-1.5 [30] 和 mPLUG-Owl [46] 等模型都倾向于给出肯定的答案 [23]。不同 VLM 的不同故障模式凸显了特定改进的必要性。认识和理解这些局限性和失败类型对于推进这些模型并在知识先验和上下文理解之间取得微妙的平衡至关重要。
在探索这些 LVLM 时,我们观察到它们强烈的语言偏差常常掩盖了视觉信息,导致过度依赖语言先验而不是视觉上下文。为了研究这种现象,我们使用“语言幻觉”这个术语,它是指在没有视觉输入的情况下得出的结论。另一方面,LVLM 中有限能力内的视觉组件可能会产生“视觉错觉”,视觉输入可能会被误解,导致模型过于自信但错误的断言。
主要贡献:认识到需要理解 LVLM 失败的原因并解决这些问题,我们提出了 HALLUSIONBENCH,这是一个精心设计的基准,旨在深入探索图像上下文推理的复杂性,并揭示当前 LVLM 的各种问题,例如如图1所示。我们设计的视觉问题(VQ)对,格式独特,有助于对模型的失败进行定量分析,从而实现更彻底的评估。这项研究揭示了现有的局限性,并为未来的改进奠定了基础,旨在使下一代 LVLM 更加稳健、平衡和精确。我们工作的新颖之处包括:
1. 我们推出 HALLUSIONBENCH,这是第一个高级诊断套件,专门用于系统地剖析和分析 LVLM 的各种故障模式。 HALLUSIONBENCH 由大约 1129 个手工制作的视觉问答 (VQA) 对组成,其中包括 165 个原始图像和 181 个由人类专业人员专业修改的图像。我们的 VQA 对超越了传统的正确性和准确性指标,采用创新结构精心制定。这种方法使我们能够定量分析当前模型失效的具体维度和方面。
2. 我们评估了 HALLUSIONBENCH 上的 13 种最新方法。我们的基准对现有方法提出了巨大的挑战。值得注意的是,SoTA GPT-4V 仅实现了 31.42% 的问题对准确率,而所有其他方法的性能均低于 16%。
3. 我们探索 HALLUSIONBENCH 并对 SoTA LVLM(例如 GPT-4V 和 LLaVA-1.5)失败的示例进行深入分析。我们还根据 HALLUSIONBENCH 的定量分析,对现有 LVLM 面临的不同问题提供见解。在我们对 HALLUSIONBENCH 的探索中,我们对 SoTA LVLM(包括 GPT-4V 和 LLaVA-1.5)的不足之处进行了详细分析。此外,我们的调查利用 HALLUSIONBENCH 的定量功能来揭示当前挑战现有 LVLM 的各种问题。

图 1. HALLUSIONBENCH 的数据样本,其中包含不同的主题、视觉模式。人工编辑的图像为红色。
3.2.视觉、问题和注释结构
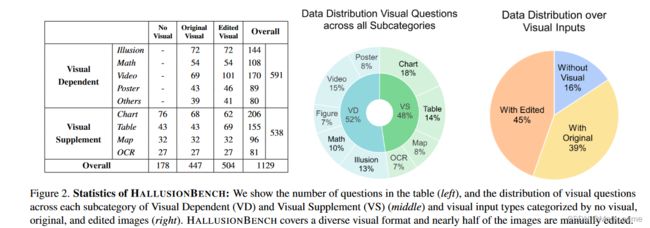
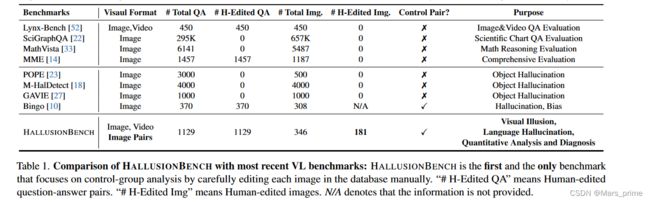
符号:令 (I, q) ∈ V ⊆ I×Q 为图像 I ∈ I 和问题 q ∈ Q 的元组,其中 V 是有效 VQ 对的集合。设N为从互联网获得的原始图像的数量,Io={I(i,0)}0 大型语言模型是一项重大进步,它带来了不仅可以理解文本,还可以理解图像等其他事物的新方法,所有这些都在一个大型系统中进行。构建这些高级大型视觉语言模型 (LVLM) 的主要方法有多种,它们可以很好地理解图像和文字,而无需针对每项任务进行特定训练。例如,Flamingo [3] 具有许多功能,将不会改变的视觉部分与具有同时理解图像和文字的特殊功能的大语言模型相结合。另一个模型 PaLM-E [12] 将视觉信息直接混合到已经很强大的 PaLM 模型中,该模型拥有 5200 亿个参数,使其在现实世界中有效使用。最近,研究人员一直在从 GPT4 和 GPT-4V [44] 创建高质量、多样化的多模态数据集,以微调开源 LVLM,包括 LLaVA [27]、MiniGPT4 [58]、Mplug-Owl [46]、 LRV-Instruction [27]、LLaVAR [55] 和其他作品 [11,24,35,48]。 幻觉通常是指生成的响应包含视觉内容中不存在的信息的情况。先前的研究主要考察两个领域:检测和评估幻觉 [23, 54],以及减少幻觉的方法 [27, 40, 49]。早期的方法包括训练分类器来识别幻觉,或者将输出与准确答案进行比较以检测不准确性。为了减轻幻觉,人们努力改进数据收集和培训程序。例如,LRV-Instruction [27] 创建平衡的正负指令来微调 LVLM。 VIGC [40] 使用迭代过程来生成简洁的答案并将其组合起来,旨在获得详细而准确的响应。类似地,Woodpecker [49] 引入了一种免训练的方法来从生成的文本中挑选并纠正幻觉。 传统的视觉语言(VL)基准旨在评估不同的技能,包括视觉识别 [16]、图像描述 [2, 26] 等。然而,随着先进 LVLM 的出现,对新基准的需求不断增加。鉴于 LVLM 强大的零样本能力,传统的评估指标通常无法提供详细的能力评估。由于它们无法准确匹配给定的答案,这个问题进一步加剧,导致严重的稳健性问题。为了应对这些挑战,研究社区引入了一系列基准,包括 MME [14]、MMBench [32]、MM-Vet [50]、SEED-Bench [20]、GAVIE [27] 和 LAMMBench [13]。这些基准系统地构建和评估复杂的多模式任务。与评估 LVLM 的物体幻觉的 POPE [23] 和 GAVIE [27] 不同,HALLUSIONBENCH 是第一个人工注释的分析基准,专注于诊断 LVLM 的视错觉和知识幻觉。 我们推出了 HALLUSIONBENCH,这是第一个旨在检查 LVLM 的视觉错觉和知识幻觉并根据每个手工制作的示例对分析潜在故障模式的基准。 HALLUSIONBENCH 由 455 个视觉问题控制对组成,包括 346 个不同的人物和总共 1129 个不同主题的问题(包括食物、数学、几何、统计、地理、体育、卡通、著名错觉、电影、模因等)和格式(包括徽标、海报、图形、图表、表格、地图、连续图像等)。在以下部分中,我们首先提供基于不同视觉问题类型的数据集构建指南。其次,我们将描述HALLUSIONBENCH的数据和注释结构。最后,我们将描述数据集的统计数据。 我们的目标是开发一个多模态图像上下文推理基准来研究 LVLM 固有的潜在语言偏差,这种偏差有时会掩盖视觉上下文。我们定义了两类视觉问题:视觉相关和视觉补充。 视觉相关问题被定义为没有视觉上下文就没有肯定答案的问题。此类问题询问的是图像本身或图像中的某些内容。例如,“右侧橙色圆圈与左侧橙色圆圈大小相同吗?”就没有明确的答案。没有图像来提供更多上下文。指南:在此设置下,我们的基准测试旨在评估视觉常识知识和视觉推理技能。我们的探索和数据集构建以以下问题为指导: 1.模型的视觉理解和推理能力有多好? 2. 模型的参数记忆如何影响其对问题的响应? 3. 该模型是否能够捕获多个图像的时间关系? 视觉补充问题是无需视觉输入即可回答的问题;视觉组件仅提供补充信息或更正。例如,一些 LVLM 可以回答“新墨西哥州比德克萨斯州大吗?”在没有美国地图的情况下使用参数记忆中的先验知识。指南:在此设置下,我们的基准测试旨在评估视觉推理能力以及参数记忆和图像上下文之间的平衡。我们在此类别下的探索和数据集构建以以下问题为指导: 1. 当模型在其语言模块的参数记忆中缺乏先验知识或答案时,模型是否(仍然)对图像产生幻觉? 2. 当模型的语言模块在其参数记忆中有足够的先验知识或直接知道答案时,它是否仍然通过从视觉补充中收集额外的信息来增强其响应(特别是当先验知识与视觉输入或参数记忆冲突时)已经过时了)? 3.模型如何很好地解释具有密集信息(即图形、图表、地图等)的视觉输入以回答问题?哪些类型的图像处理可能会阻碍或扭曲视觉信息提取? 符号:令 (I, q) ∈ V ⊆ I×Q 为图像 I ∈ I 和问题 q ∈ Q 的元组,其中 V 是有效 VQ 对的集合。设N为从互联网获得的原始图像的数量,Io={I(i,0)}0 遵循上述注释结构和指南,我们要求人类专家手动收集 346 张具有不同主题和类型的图像。如图2所示,Visual Dependent有591个问题,包括视频、错觉、数学、海报、标志、卡通等; Visual Supplement 有 538 个问题,包括图表、表格、地图和 OCR。此外,图2(右)描述了没有视觉输入(16%)、原始在线图像(39%)和由人类专家编辑的视觉输入(45%)的问题的分布。我们的图像处理策略包括图像翻转、顺序反转、遮罩、光学字符编辑、对象编辑和颜色编辑。此外,每张图像平均有 3.26 个问题。图 2(左)提供了有关每个主题和视觉输入类别中的问题数量的更多详细信息。 图 2. HALLUSIONBENCH 的统计数据:我们显示了表中的问题数量(左),以及视觉问题在视觉依赖 (VD) 和视觉补充 (VS) 每个子类别中的分布(中)以及按以下分类的视觉输入类型没有视觉、原始和编辑过的图像(右)。 HALLUSIONBENCH 涵盖了多种视觉格式,近一半的图像是手动编辑的。 HALLUSIONBENCH 与现有基准之间的主要比较如表 1 所示。 1. 如图所示,现有基准[10,18,23,27]与HALLUSIONBENCH在幻觉评估方面存在显着差距,因为现有基准主要关注对象幻觉、有限主题和视觉输入类型。因此,我们的数据集 HALLUSIONBENCH 致力于通过提供更多主题、更多图像类型和更多视觉输入方式(包括图像和视频)来弥补这一差距。此外,我们的人类专家会仔细选择每张图像并编写问答对。我们也是第一个包含人工编辑图像来评估当前 LVLM 稳健性的工作。此外,与现有基准不同,HALLUSIONBENCH 专注于评估语言幻觉和视觉错觉,超越物体幻觉的狭窄范围。 符号:设 M(I, q) ∈ {“是”, “否”, “不确定”} 是 VLM M 对图像问题对 (I, q) 的解析输出答案。 GPT-4 GP T (M(I, q), y(I, q)) 然后根据groundtruth y(I, q) ∈ {“是”, “否”来判断答案M(I, q)如果预测响应不明确,则输出不正确 (0)、正确 (1) 或不确定 (2)。 GPT-4判断的提示设计为: 想象一下你是一位聪明的老师。仔细阅读问题、参考答案和预测答案,以确保清楚地理解所提供的信息。评估预测的正确性。如果预测答案与参考答案不冲突,请生成“正确”。如果预测答案与参考答案冲突,请生成“不正确”。如果预测答案对答案不清楚,请生成“不清楚”。 对于每个样本,我们在模板中填充问题、真实情况和 LVLM 输出。通过将填写的提示输入 GPT-4,GPT-4 将为样本生成“正确”、“不正确”或“不清楚”。发现尽管温度设置为0,GPT4的输出仍然存在方差。因此,我们利用GPT-4对LLM的输出进行3次评估并报告平均分数。 与人类评估的比较:为了证明我们的 GPT4 辅助评估是有效的,我们获得了 GPT-4V [44] 和 LLaVA-1.5 [30] 的响应,并手动评估它们响应的正确性。如果答案不明确,我们将答案标记为不正确 (0)、正确 (1) 和不确定 (2)。如Tab前两行所示。 2 和选项卡。如图3所示,差异可以忽略不计,证明GPT4辅助的方法与人类的判断非常吻合。 由于我们基准的重点是幻觉和错觉,而不是知识的广度,因此当视觉补充类别下没有视觉输入时,我们认为不确定的答案是可以接受的。对于最终的准确率得分,我们将正确性转换为二进制值 bM ∈ {0, 1}: 除了准确性指标之外,我们还引入了三个分析标准来衡量和诊断 LVLM 的故障:是/否偏差测试、一致性测试和诊断测试。我们不是定性地检查和分析每个失败的案例,而是通过问题集的独特设计提出这些新颖的定量测量。这些测试按复杂程度排列,因此如果前一个基本测试失败,后一个测试就不会那么有用和有洞察力。 根据[23],一些模型[15,30,46]在大多数情况下倾向于回答“是”。如果模型有很强的偏见或倾向于以一种方式回答而不管实际问题如何,则无需进一步分析,因此我们设计了两个标准来揭示模型的这种偏好。是 百分比差异 (Pct. Diff) dy ∈ [−1, 1]: dy = P (I ,q)εV 1 M(I, q) = “是” − 1 y(I, q) = “是” |V| , (6) dy 表示问题集中“是”的预测数量与实际数量之间的差异。当 |dy| 时,模型的偏差更大。接近 1。 假阳性率 (FP Ratio) rfp ∈ [0, 1]: rfp = P (I,q)∈W 1 M(I, q) = “yes” |W| , (7) 其中 W = {(I, q) ∈ V | bM(I, q) = 0} 是一组不正确的视觉问题。rfp 衡量模型在所有不正确的回答中回答“是”的可能性。当rfp 接近 0.5 4.3.2 一致性测试 一致性测试的目的是测试回答的逻辑一致性,并确保问题不是基于随机猜测而回答的。许多问题 Qi 源于 Ri 4.3.3 语言幻觉和视觉错觉 在我们深入进行诊断测试之前,我们根据失败的案例将失败分为两大类: 语言幻觉是指在没有相关视觉输入的情况下形成的感知。在语言幻觉中,模型对输入和图像上下文做出错误的先验假设基于其参数记忆。模型应该根据问题的框架做出响应,而不是忽略它或对图像做出错误的假设。视觉错觉是指对准确视觉信息的误解。视觉错觉来自于无法在视觉上识别和理解输入图像。该模型无法获得准确的信息或正确地推理图像。 4.3.4 诊断测试 为了研究语言幻觉和语言错觉问题,我们分析了 VQ 控制对中两个视觉问题的回答和正确性,并将不正确的回答分为三类:语言幻觉、视觉错觉和混合/不确定。我们衡量这些失败在所有失败案例中的百分比。控制对:控制对将始终包含用于视觉相关问题的原始图像或用于视觉补充问题的空图像(无视觉)。控制对中的另一个问题可能有编辑过的图像(或者 VS 问题的原始图像)。对这个问题的回答将提供更多关于答案是否存在于参数知识中或者模型是否在训练数据中看到它的信息。此外,我们可以检查编辑原始图像后响应是否保持不变,以获得对失败的更多见解,这比单独检查单个视觉问题提供更多信息。在图 3 中,我们提供了一个决策树来确定控制对的故障类型。在分配失败类型时,我们考虑以下原则: 1. 对于视觉相关(VD)问题或具有视觉输入的视觉补充(VS)问题,如果回答不正确或不确定,则失败可能是视觉错觉,因为模型无法正确从视觉信息中提取。 2. 对于没有视觉输入的视觉补充(VS)问题,如果答案给出了确定但错误的答案,我们将其归因于语言幻觉。 3. 如果模型正确响应原始图像(或无图像)并且对编辑后的图像具有相同的响应(这与常识相反),则意味着参数知识超过了实际图像输入。因此,我们也将失败归咎于语言幻觉。我们将在补充材料中包含一些示例。 我们在 HALLUSIONBENCH 上进行了大量实验,评估了总共 13 个 LVLM,包括 GPT-4V [1]、LLaVA1.5 [30]、MiniGPT4 [58]、MiniGPT5 [57]、GiT [41]、InstructBLIP [11]、 Qwen-VL [6]、mPLUG-Owl-v1 [46]、mPLUGOwl-v2 [47]、LRV-指令 [27]、BLIP2 [21]、BLIP2-T5 [21] 和 Open-Flamingo [3]。我们还包括随机机会(即随机选择是或否)作为基线。 我们比较了几种模型的性能,包括闭源模型和开源模型。结果在表中给出。 2、选项卡。如图 3 和图 4 所示。此外,我们建立了人类专家评估来评估纯文本 GPT4 辅助评估的有效性。正确性评估。如表所示。 2、除了硬精度之外,GPT-4V 大幅优于所有开源 LVLM。硬准确度衡量模型理解来自 HALLUSIONBENCH 的人工编辑图像的能力。较差的精度表明我们对 GPT-4V 和其他开源 LVLM 进行图像处理面临着挑战。在开源模型中,我们研究扩大 LLM 主干的大小(0.8B 到 13B)是否可以减轻物体存在幻觉。如选项卡中详细说明。如图2所示,随着模型尺寸的增大,幻觉明显减少,如LLaVA-1.5和BLIP2-T5。在大小小于10B的模型中,InstructBLIP和mPLUG-Owl-v2是性能最好的。 InstructBLIP 利用 BLIP-2 架构并通过跨 26 个不同数据集的指令微调进行增强,表明更广泛和更广泛的训练集可以显着提高性能。与 mPLUG-Owl-v1 相比,mPLUG-Owl-v2 的性能提升可归因于其新颖的模块,该模块利用语言解码器作为管理不同模态的通用接口。是/否偏见。另一个观察结果是,GPT-4V、BLIP2T5 和 mPLUG-Owl-v2 在问题对准确性、图形对准确性和问题级别准确性方面均优于随机选择。其他模型,例如 Qwen-VL 和 MiniGPT4,性能甚至比随机选择更差。这表明他们的视觉推理能力仍然有限。然而,LLaVA-1.5 的性能优于随机选择,但在问题对准确性和图形对准确性方面均取得较差的结果。我们将这种现象归因于 LLaVA-1.5 倾向于回答“是”这一事实。表 1 中“是/否偏倚测试”中 LLaVA-1.5 的低“是百分比差异”和“假阳性率”支持了这一假设。 3. 此外,我们发现 Open-Flamingo 和 mPLUG-Owl-v1 也倾向于回答“是”,具有较高的“是”百分比差异和误报率。受[27]的启发,一个可能的原因是这些 LVLM 在训练集中缺乏平衡的正向和负向指令。我们还将这些 LVLM 的较差性能归因于训练集中人工编辑图像的稀缺,因为大多数 LVLM 仅利用现有数据集中的原始图像。语言和视力诊断。我们在图 4 中报告了不同视觉输入的 6 个著名 LVLM 的细粒度分数。结果表明,数学、幻觉和视频是当前 LVLM(包括 GPT-4V)最具挑战性的格式。从图 5(上)中,我们发现 GPT-4V 和 LLaVA-1.5 都无法正确识别正则三角形,在问题对准确度和图形对准确度方面都取得了较差的结果。我们将这种现象归因于 LLaVA-1.5 倾向于回答“是”这一事实。表 1 中“是/否偏倚测试”中 LLaVA-1.5 的低“是百分比差异”和“假阳性率”支持了这一假设。 3. 此外,我们发现 Open-Flamingo 和 mPLUG-Owl-v1 也倾向于回答“是”,具有较高的“是”百分比差异和误报率。受[27]的启发,一个可能的原因是这些 LVLM 在训练集中缺乏平衡的正向和负向指令。我们还将这些 LVLM 的较差性能归因于训练集中人工编辑图像的稀缺,因为大多数 LVLM 仅利用现有数据集中的原始图像。语言和视力诊断。我们在图 4 中报告了不同视觉输入的 6 个著名 LVLM 的细粒度分数。结果表明,数学、幻觉和视频是当前 LVLM(包括 GPT-4V)最具挑战性的格式。从图 5(上)中,我们发现 GPT-4V 和 LLaVA-1.5 都无法正确识别正三角形,这意味着几何和数学对于 GPT-4V 来说仍然是一项具有挑战性的任务。从图 5(中)中,我们发现 GPT-4V 在识别所有错觉案例并知道它们的名称方面比 LLaVA-1.5 更有知识。然而,GPT-4V 未能根据编辑后的图像忠实地回答这个问题。这背后的原因可能是 GPT-4V 倾向于根据其参数记忆生成答案,而不是分析图像。与 GPT-4V 相比,LLaVA-1.5 在原始图像和编辑图像上的表现都很差,表明 LLaVA-1.5 的视觉感知能力有限。从图5(下)中,我们发现GPT-4V无法区分图像的正序和反序,这表明视频推理能力还有很大的提升空间。2. Related Work相关工作
2.1. Large Multi-Modal Models大型多模式模型
2.2. LVLM 中的幻觉
2.3. Benchmarks for Large VL Models
----
2.3.大型 VL 模型的基准3. HALLUSIONBENCH Construction
----
3. HALLUSIONBENCH 建造3.1.视觉问题分类
3.1.1 视觉相关问题
3.1.2 视觉补充问题
3.2.视觉、问题和注释结构
3.3.数据集统计
3.4. HALLUSIONBENCH 的独特之处
4.HALLUSIONBENCH 评估套件
4.1.纯文本 GPT4 辅助评估
4.2.正确性评估指标


4.3.分析评价标准
4.3.1 是/否偏差测试
5. 实验结果
5.1.模型
5.2.结果分析