关于MQ,你了解多少?(干货分享之一)
导语
本文梳理笔者 MQ 知识,从消息中间件的基础知识讲起,在有了基础知识后,对市面上各主流的消息中间件进行详细的解析,包括 RabbitMQ、RocketMQ、Kafka、Pulsar,最后再横向对比这几款主流的消息中间件。
消息中间件历史
介绍 MQ 的文章网上千千万,最好的学习途径还是官方文档,文中介绍的这几款 MQ 都在努力推广自己,所以文档在权威性、全面性、专业性、时效性都是无人能及其左右,现在的官网文档甚至自己做竞品比对,比如 RocketMQ 就自己放了比对表格在首页。所以要学好哪一款MQ,就去看它的官网吧,地址放在文末参考资料中了。
最好的学习方法是带着问题去寻找答案,以费曼学习法为标准,产出可教学的资料,所以本文多是个人的所学梳理和所想记录,个人知识有限,难免有所疏漏,文中有错误和疏漏请不吝赐教,感谢!
消息中间件的发展已经有近40年历史,早在上个世纪80年代就诞生了第一款消息队列 The Information Bus。
到90年代 IBM、Oracle、Microsoft 纷纷推出自家的MQ,但都是收费且闭源的产品,主要面向高端的企业用户,这些MQ一般都采用高端硬件,软硬件一体机交付,需要采购专门的维护服务,MQ本身的架构是单机的架构,用户的自主性较差。
进入新世纪后,随着技术成熟,人们开始讨论MQ的协议,诞生了JMS、AMPQ 两大协议标准,随之分别有 ActiveMQ、RabbitMQ的具体实现,并且是开源共建的,这使得这两款MQ在当时迅速流行开来,MQ的使用门槛也随之降低,越来越多系统融入了MQ作为基础能力。
再后来PC互联网、移动互联网的爆发式发展,由于传统的消息队列无法承受亿级用户的访问流量和海量数据传输,诞生了互联网消息中间件,核心能力是全面采用分布式架构、具备很强的横向扩展能力,开源典型代表有 Kafka、RocketMQ、Pulsar。Kafka 的诞生还将消息中间件从Messaging领域延伸到了 Streaming 领域,从分布式应用的异步解耦场景延伸到大数据领域的流存储和流计算场景。Pulsar 更是在 Kafka 之后集大家之成,在企业级应用上做得更好,存储和计算分离的设计使得拓展更加轻松。
如今,IoT、云计算、云原生引领了新的技术趋势。面向IoT的场景,消息队列开始从云内服务端应用通信,延伸到边缘机房和物联网终端设备,支持 MQTT 等物联网标准协议也成了各大消息队列的标配,我们看到 Pulsar、Kafka、RocketMQ 都在努力跟随时代步伐,拓展自己在各种使用场景下的能力。

消息中间件基础定义
在早些年 MQ 一直被叫做消息队列,就可以定义为传递消息的容器,随着时代的发展,MQ 都在努力拓展出来越来越多的功能,越来越多需求加在 MQ 纸上,消息中间件的能力越来越强,应用的场景也越来越多,如果非要用一个定义来概括只能是抽象出来一些概念,概括为跨服务之间传递信息的软件。
用途
异步处理
可以把接口请求根据业务的时效性程度,将不紧急的处理逻辑生成消息、事件放到 MQ 当中,再由专门的系统处理该消息、事件;如日志上报、归档事件、数据推送、数据分析、触发策略、变更推荐、添加积分、发送通知消息等。
削峰填谷
作为系统内部的一个消息池,抵抗洪峰,对后端服务起到保护作用。流量洪峰进来的时候,会转换为消息落到 MQ 当中,后端服务可以根据自己的处理能力来,流量不会直接冲击到后端服务,特别是落库、IO 等操作。
服务解耦
减少系统、模块之间直接对接带来的耦合,交互统一按 MQ 中消息的协议,按需生产和消费,耦合程度大大降低。
发布订阅
系统产生的行为不需要通过接口等方式来通知到相关服务,只需要发布一次消息,订阅者都能消费到消息,执行服务自身的本职工作。
当然,一切收益都是有代价的,对于系统架构本身来说,会引入新组件,带来系统复杂度的提升,整体系统的可靠性也会是挑战,增加消息中间件的运维成本,还会带来整体系统一致性的问题。所以需要权衡自身系统是否有必要引入 MQ,能解决什么痛点,投入产出能否让组织满意,对于本身流量不大的系统来说,保持简单架构是皆大欢喜的事情,毕竟,越简单越稳定,越耐用。
消息模型
队列模型
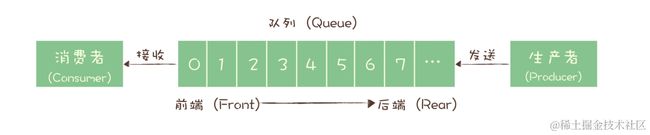
一种是消息队列,生产者往队列写消息,消费者从这个队列消费消息,当然生产者可以是多个,消费者也可以是多个,但是一条消息只能被消费一次,具体怎么做的,这就涉及到具体的使用需求和每一款消息中间件的实现了,后面第二部分的时候会涉及到。这是最早的消息模型,这也是为什么消息队列 MQ 这个名字也一直有人在用吧。
订阅模型
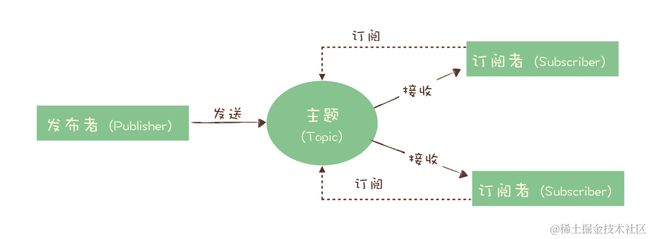
后来上个世纪80年代有人提出发布订阅模式,就是 Topic 模式,生产者发布的消息,消息中间件会把消息投递给每一个订阅者,这个投递的过程有可能是推也可能是拉,支持哪一种也要看每一款的具体实现。
消息协议
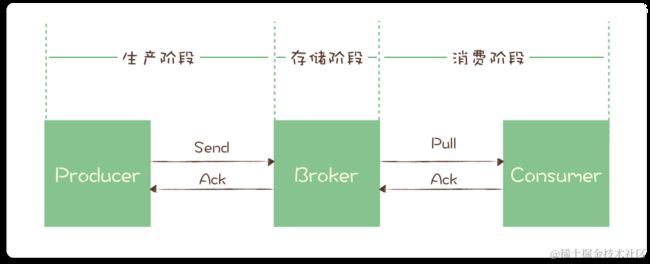
常见的消息协议:

接下来举例 AMPQ 协议的生产、消费过程标准。
AMQP 协议
高级消息队列协议(Advanced Message Queuing Protocol),一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
- 生产消息

- 消费消息

MQTT 协议
MQTT(消息队列遥测传输)是 ISO 标准(ISO/IEC PRF 20922)下基于发布/订阅范式的消息协议。它工作在 TCP/IP 协议族上,是为硬件性能低下的远程设备以及网络状况糟糕的情况下而设计的发布/订阅型消息协议。
MQTT 协议是轻量、简单、开放和易于实现的,这些特点使它适用范围非常广泛。在很多情况下,包括受限的环境中,如:机器与机器(M2M)通信和物联网(IoT)。其在,通过卫星链路通信传感器、偶尔拨号的医疗设备、智能家居、及一些小型化设备中已广泛使用。
其他协议
另外还有 STOMP、OpenMessaging 等,这里不做展开。当前市面上主流的消息中间件多是有自定义的协议发展起来的,如 Kafka 在最开始并不算是一个消息中间件,而是用于日志记录系统的一部分,所以并不是基于某种中间件消息协议来做的,而是基于 TCP/IP,根据自定义的消息格式,来传递日志消息,为满足对于消息丢失是有一定容忍度的;在后来逐步发展到可以支持正好一次(Exactly Once)语义,实际上是通过 At Least Once + 幂等性 = Exactly Once 。
将服务器的 ACK 设置为-1,可以保证 Procedure 到 Broker 不会丢失数据即 At Least Once;相对的,服务器级别设置为0,可以保证生产者发送消息只会发一次,即 At Most Once 语义但是,一些非常重要的消息,如交易数据,下游消费者要求消息不重不漏,即 Exactly Once,精准一次,在0.11版本之前,Kafka 是无能为力的,只能通过设置ACK=-1,然后业务消费者自己去重。
0.11版本之后,Kafka 引入了幂等性概念,Procedure 无论向 Broker 发送多少次消息,Broker 只会持久化一条:At Least Once + 幂等性 = Exactly Once。要启用幂等性,只需要将 Procedure 参数中的 enable.idempotence 设置为 True 即可,Kafka 的幂等性实现其实就是将原来在下游做的去重放在了数据上游。开启幂等性的 Procedure 在初始化的时候会分配一个 PID,发往同一个 Partition 的消息会带一个 Sequence Number,而 Broker 端会对做缓存,当相同主键消息提交时,Broker 只会持久化一条。
基于这个理解我们看下 Kafka 的消息报文格式定义,
协议概要:

再展开看 Message 的定义:

基于 TCP/IP 协议,通过定义消息格式,在请求和响应中做可靠性保证。且随着发展在修改协议,比如 Timestamp 是为了增加时间索引,在 0.10.0 版本后增加的,用于根据时间戳快速查找特定消息的位移值,优化 Kafka 读取历史消息缓慢的问题。
Streaming、Eventing 场景下目前还没有看到有公认消息协议的出现。
往下的篇幅将展开介绍 RabbitMQ、RocketMQ、Kafka、Pulsar 这四款主流消息中间件的基础知识。
RabbitMQ
基于 Erlang 语言开发实现,单机性能表现不错,横向拓展能力较弱,可用于吞吐量在万级的系统当中。
消息模式
RabbitMQ 支持简单模式、工作队列模式、发布/订阅模式、路由模式、主题模式和 RPC 模式。

简单模式

队列模式

发布订阅模式

路由模式

主题模式
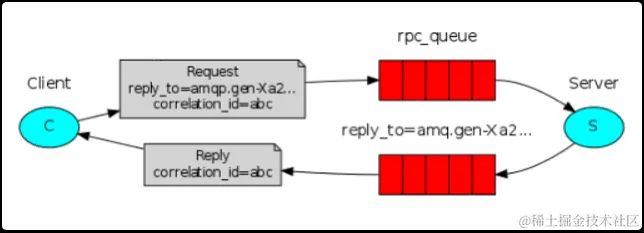
RPC模式
以上所有模式实际上都及基于消息队列来实现的,发布订阅模式和主体模式,也是通过队列来实现的,对交换器绑定后再通过路由规则来分发消息到队列中,也就是 BindingKey 和 RoutingKey,由于 RoutingKey 不能重复,也就意味着队列收到的消息不能一样,而每条消息只会发送给订阅列表里的一个消费者,从而就是没有消费者组的概念,无法做到真正的发布订阅。带着这个理解看 RabbitMQ 架构就会比较清晰了。
RabbitMQ 架构

上图是单机的架构,那么集群架构是怎么样的呢?

HA-Proxy 一款提供高可用性、负载均衡以及基于 TCP 和 HTTP 应用的代理软件,主要是做负载均衡的7层,也可以做4层负载均衡。
Keepalived 是集群管理中保证集群高可用的一个服务软件,其功能类似于 Heartbeat,用来防止单点故障。
虽然是高可用方案,但总体来说横向扩展能力较弱。
RabbitMQ 就介绍到这里,更多信息可查看官网。
未完待续
此篇是消息队列基础知识的上半部分,下半部分会对现代主流的消息队列进行介绍,包括 RocketMQ、Kafka、Pulsar,以及这几款 MQ 之间的对比。