【MYSQL】MYSQL 的学习教程(一) 之 MYSQL 的逻辑架构解析
MySQL 安装后,包含一个 “mysqld” 服务器进程、客户端应用程序用于本地或远程连接,及一些本地安装的 mysql 非客户端程序。用户通过 mysql 客户端应用程序连接 MySQL 服务器发起数据请求
当 MySQL 的客户端与服务器进行通信时,客户端和服务器可以使用不同的操作系统,例如,客户端使用 Windows,服务器使用 Linux,客户端通过 TCP/IP 协议连接至服务器
MySQL 是一个单进程多线程的服务器,MySQL 进程的名称为 “mysqld” ,它负责管理数据库在磁盘和内存中的访问,支持多个存储引擎、支持事务和非事务的表,并且能够优化内存的使用
1. MySQL逻辑体系架构
MYSQL 的组成部分有以下内容:
- 连接池组件
- 管理服务和工具组件
- SQL接口组件
- 查询分析器组件
- 查询优化器组件
- 缓冲(Cache)组件
- 插件式存储引擎
- 物理文件
Mysql 的存储:基于表的,而不是数据库。
Mysql 的特点:插件式的表存储引擎
其结构图如下:

MySQL 内部结构分为四层:
- 连接层:完成客户端连接(连接处理、授权认证)
- 服务层:进行 SQL 分析、优化
- 引擎层:负责数据的提取、存储
- 存储层:将数据存储在设备的文件系统上,并完成与数据引擎交互
2. 连接层
2.1 概述
连接层为每个连接分配一个线程,该线程用来控制查询的执行。当连接通过用户名/密码的认证后,该连接可以发送 SQL 查询。
连接层接受通过 TCP/IP、Unix socket、shared memory、Named pipes 协议的应用程序连接。连接协议通过客户端的库及驱动实施,连接协议的速度因本地设置而异。上述协议中,MySQL 可以通过 TCP/IP 协议在网络间传送消息,其他的协议仅支持在本地使用(客户端和服务器必须在同一台主机上)
TCP/IP协议除了用于网络间的远程连接,也可以用于本地连接。使用TCP/IP协议时需要使用IP地址或者DNS名称标识主机,并使用端口号标识服务。MySQL的默认端口号为3306。当主机名使用“localhost”时,MySQL将认为用户使用Unix的socket进行通信,使用“127.0.0.1”IP地址时,将使用TCP/IP协议进行通信
Unix socket 通信是进程间通信的一种形式,用于在同一机器上的两个进程之间形成的双向通信链路的一端,要求服务器创建一个 socket 文件,客户端通过该文件进行连接。例如:
mysql -S var/lib/mysql/mysql.sock -uroot -P
当用户使用 window 时,可以通过 shared memory 和 Named pipes 进行连接。使用 shared memory 时,服务器将创建一个共享的内存块,客户端进程将使用该内存块与服务器进行通信。
Named pipes 在 window 上的工作方式与 Unix 的 socket 比较相像,服务器创建一个 named pipe,客户端通过该 named pipe与服务器建立连接
连接线程
服务器为每个活动的客户端连接创建一个连接线程,通过该客户端执行的全部语句将使用该线程,当客户端断开时,服务器将销毁该线程。服务器创建和销毁线程时,它必须事先分配一个专用的内存构造用于客户端的连接,当频繁建立销毁连接时,会为系统带来性能上的影响。MySQL在企业版中提供了线程池插件,该插件可以将线程进行分组管理,每组线程在任意时间点上只允许一个运行时间短的语句,线程组可以为运行时间长的语句额外创建一个线程,并且能够根据事务关系区分语句的优先级
2.2 通信方式
常见的通信机制:
- 全双工:能同时发送和接收数据,例如平时打电话
- 半双工:指的某一时刻,要么发送数据,要么接收数据,不能同时。例如早期对讲机
- 单工:只能发送数据或只能接收数据。例如单行道
MySQL 客户端/服务端通信协议是“半双工”的:
- 在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生
- 一旦一端开始发送消息,另一端要接收完整个消息才能响应它,所以我们无法也无须将一个消息切成小块独立发送,也没有办法进行流量控制
传送过程:
- 客户端 ==> 服务器:客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置
max_allowed_packet参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常 - 服务器 ==> 客户端:服务器响应给用户的数据通常会很多,由多个数据包组成;但是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送
- 在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯
- 这也是查询中尽量避免使用 SELECT * 以及加上 LIMIT 限制的原因之一
2.3 权限验证
mysql 中存在 4 个控制权限的表,分别为:user 表,db 表,tables_priv 表,columns_priv 表
mysql权限表的验证过程为:

MySQL 的权限分级
全局性的管理权限: 作用于整个 MySQL 实例级别
数据库级别的权限: 作用于某个指定的数据库上或者所有的数据库上
数据库对象级别的权限:作用于指定的数据库对象上(表、视图等)或者所有的数据库对象上

2.4 查询连接状态
对于一个 MySQL 连接,或者说一个线程,任何时刻都有一个状态,该状态表示了MySQL当前正在做什么。有很多种方式能查看当前的状态,最简单的就是下面这个:
SHOW FULL PROCESSLIST
执行结果如下:

command 列就是状态:
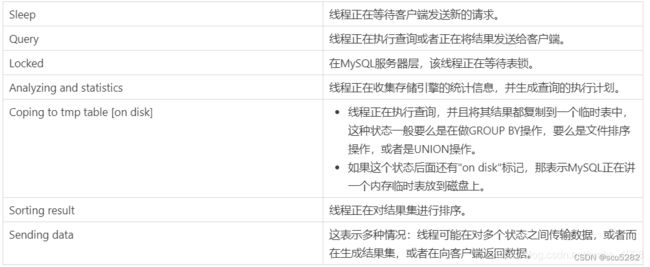
连接出现问题:对于出现问题的连接通过 kill {id} 的方式杀掉
2.5 连接类型
- 长连接:长连接是相对于短连接来说的。长连接指在一个连接上可以连续发送多个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包。
- 短连接:是指通讯双方有数据交互时,就建立一个连接,数据发送完成后,则断开此连接,即每次连接只完成一项业务的发送
长连接的问题: 使用长连接后,随着连接数不断增加,会导致内存占用升高,因为 MySQL 在操作过程中会占用内存来管理连接对象,只有等到连接断开后才会释放。如果连接一直堆积,就会导致内存占用过大,被系统强行杀掉,也就是会出现 MySQL 重启。
解决方案
1、定期断开长链接,每隔一段时间或者执行一个占用内存的大查询后断开连接,依次释放内存
2、MySQL 5.7+ 的版本中提供了 mysql_reset_connection 来重新初始化连接资源,这时不需要重新连接,就可以将连接恢复到刚刚创建完时的状态
MySQL:show processlist 详解
3. 服务层
服务层:主要完成大多数的核心服务功能
- sql接口,并完成缓存的查询(接收用户的sql命令,并且返回用户需要查询的结果。比如 select from 就是调用 SQL Interface)
- 所有跨存储引擎的功能也在这一层实现,如过程,函数等
- 在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等。最后生成相应的执行操作。如select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样就解决大量读操作的环境中能够很好的提升系统的性能
3.1 Cache&Buffer 查询缓存
mysql 的缓存主要的作用是为了提升查询的效率(mysql8.0 版本后被删除)
3.1.1 存储形式
- 缓存以key和value的哈希表形式存储,key是具体的sql语句,value是结果的集合。
- 将缓存存放在一个引用表中,通过一个哈希值引用,这个哈希值包括了以下因素,即查询本身、当前要查询的数据库、客户端协议的版本等一些其他可能影响返回结果的信息。
- 如果查询可以在缓存中找到key,那么该key对应的value会直接返回给客户端,如果没有命中则需要执行后续解析、优化和执行阶段的操作,执行后也会缓存起来。(任何字符上的不同,例如空格、注解等都会导致缓存的不命中。)
3.1.2 为什么被删除
- 针对表进行写入或更新数据时,将对应表的所有缓存都设置失效。
- 对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。
- 在查询之前必须先检查是否命中缓存,浪费计算资源。
- 如果这个查询可以被缓存,那么执行完成后,MySQL 发现查询缓存中没有这个查询,则会将结果存入查询缓存,这会带来额外的系统消耗。
- 如果查询缓存很大或者碎片很多时,这个操作可能带来很大的系统消耗
3.1.3 不会被缓存的情况
- 包含函数NOW()和CURRENT_DATE()的查询
- 包含任何用户自定义函数,存储函数,用户便令,临时表
- mysql数据库中的系统表或者包含任何列权限的表
- 对于 InnoDB 引擎来说,当一个语句在事务中修改了某个表,那么在这个事务提交之前,所有与这个表相关的查询都无法被缓存。因此长时间执行事务,会大大降低缓存命中率
- 当查询语句中设置了 SQL_NO_CACHE,则不会被缓存
- 当查询的结果大于 query_cache_limit 设置的值时,结果不会被缓存
3.1.4 查询缓存执行状态
show status like 'Qcache%'
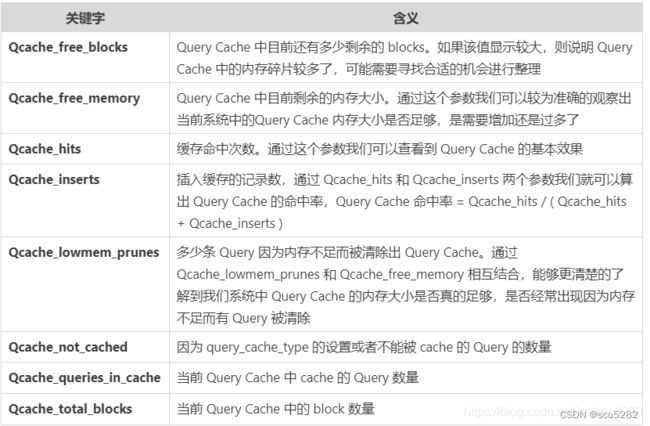
缓存执行状态图:

mysql是提供了按需使用缓存的设置,将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。
用SQL_CACHE显式指定,像下面这个语句一样:
select SQL_CACHE * from T where ID = 10;
3.2 Parser — 解析器、分析器
SQL 命令传递到解析器的时候会被解析器验证和解析。
- 将 SQL 语句进行语义和语法的分析,分解成数据结构,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后 SQL 语句的传递和处理就是基于这个结构的。
- 如果在分解构成中遇到错误,那么就说明这个 sql 语句是不合理的
分析器的执行过程:
在分析器中就通过语义规则器将 select from where 这些关键词提取和匹配出来,MySQL 会自动判断关键词和非关键词,将用户的匹配字段和自定义语句识别出来。这个阶段也会做一些校验:比如校验当前数据库是否存在 user 表,同时假如 User 表中不存在 userId 这个字段同样会报错:unknown column in field list.
3.3 Optomizer 查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。
就是优化客户端请求的 query(sql语句) ,根据客户端请求的 query 语句,和数据库中的一些统计信息,在一系列算法的基础上进行分析,得出一个最优的策略,告诉后面的程序如何取得这个 query 语句的结果。
比如表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序
进行 sql 语句的优化,根据执行计划(explain)进行最优的选择,匹配合适的索引选择最佳的执行方案
4. 引擎层
存储引擎真正的负责 MySQL 中数据的存储和提取,服务器通过 API 与存储引擎进行通信,不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需进行选取。
mysql 区别于其他数据库的最重要的特点就是插件式表存储引擎。mysql 插件式的存储引擎架构提供标准的管理和服务支持
存储引擎基于表而不是基于数据库
5. 存储层
主要是将数据存储在运行于裸设备的文件系统之上,并完成于存储引擎的交互
6. Mysql 的存储引擎
6.1 InnoDB 存储引擎
从 mysql 数据库 5.5.8 版本开始,innoDB 存储引擎是默认的存储引擎:
- 支持事务
- 行锁设计、支持外键
- innoDB 把所有的数据都放在一个逻辑的表空间的中,这个表空间就想黑盒子一样由 InnoDB 自身进行管理。
- InnoDB 通过多版本控制(MVCC)来获取高并发性,并且实现了SQL标准的4中隔离级别。
- InnoDB 提供了缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能和高可用的功能。
- 数据存储采用聚集方式,如果不指定主键,会给表生成一个 6 字节的 ROWID,作为主键
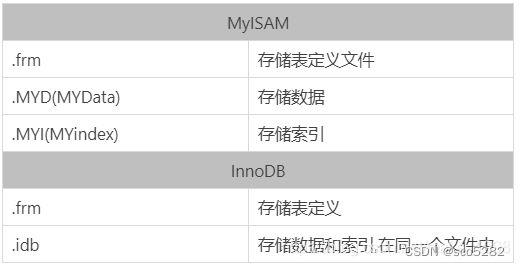
6.2 MylSAM 存储索引
是 mysql5.5.8 版本之前的默认存储引擎
- 不支持事务、表锁设计
- 支持全文索引
- 缓冲只缓存索引文件,不缓冲数据文件
- MyISAM 存储引擎是由 MYD 和 MYI 组成的,MYD 存放数据文件,MYI 存储索引文件
6.3 NDB 存储引擎
NDB 是一个集群存储引擎,特点是所有的数据都放在内存中,所以主键查找速度极快
6.4 Memory 存储引擎
Memory 存储引擎(之前称为 HEAP 存引擎)把表的数据放在内存中,如果发生数据库重启或在崩溃,表中的数据将会消失。适合用于存储临时数据的临时表,以及数据仓库中的纬度表。
只支持表锁,并发性能差,并且不支持 TEXT 和 BLOLB 类型
6.5 Federated 存储引擎

7. 总结
| 对比项 | InnoDB | MyISAM |
|---|---|---|
| 主外键 | 支持 | 不支持 |
| 事务 | 支持 | 不支持 |
| 行、表锁 | 行锁。操作时只锁一行,对其它行不影响。适合高并发 | 表锁。操作一行也会锁整个表。不适合高并发 |
| 缓存 | 缓存索引、真实数据,对内存要求较高 | 只缓存索引 |
| 表空间 | 大 | 小 |
| 关注点 | 事务 | 性能 |
存储引擎的文件后缀:
mysql的逻辑架构解析
MySQL逻辑架构
第04章 逻辑架构