论文解读:Exploring Complementary Strengths of Invariant and Equivariant Representations
小样本学习论文解读:Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning
摘要
teach:这篇文章尽管标题带小样本学习,但是并没有设计一套小样本学习的算法,而是用一种数据增强或者数据增广的方式生成更多的样本。通过样本之间的训练或者学习来去提升这个模型的泛化能力。用积累的数据去学习一个更好的泛化能力的模型,让这个模型能够泛化到新颖的类别当中。
1.介绍
创新点1:不变性(3.2.1)与等价性(3.2.2)的设计

方法概述:形状代表不同的变换 ,颜色代表不同的类 。虽然不变特征提供了更好的辨 别 ,但等变特征帮助我 们了解数据流形的内部结 构 。 这些互补的表征帮助我们更好地泛化到只有少数训练样本的新任务。通过共同利用 等变和不变特征的优势,我们的方法在基线(下 一行)上实现了显著的改进。
效果展示(如果论文效果比较好可以把效果对比图直接放在摘要):

创新点2:多头知识蒸馏(参考3.2.3)
2.Related Works(略)
3.Our Approach
总体框架图
每个Ti都是一种变换,论文给出的为16种(包括旋转变换,按一定比例的图像变换的融合),每一种变换都给上一个标签,这个标签是人为设定的,比如说16种变换,对应的标签为0-15;因此除了图片本身含有的标签外,还有人为给予的标签。这16种变换为网络输入的数据。
LCE为标准分类器的监督,这是利用每一个样本对真实标签的监督,即不管一张图片经过如何的选择变换,都用它本身真实的标签(比如说这张图为一只猫,不管如何旋转或者裁剪,这种图片的真实标签还是一只猫)
LEQ(Enforcing Equivariance)就是"等价性",这里用到了对于每一种变换,人为所给定的标签
LINV(Enforcing Invariance)为"不变性",这里构建一个Memory Bank,即一个非常大的负样本,来进行对比学习。在这里一张图片i有M个变换,这是属于正样本,其他图像相对这张图片i来说就是负样本,可以用来构建Memory Bank,这个Memory Bank量可以很大。
其中对比学习的方式就是:不同变换的同一张图片"拉近",不同图片就"拉远"。
总的来说就是引入了两种损失函数:一种就是等价性的损失,一种就是不变形的损失。等价性的损失就是把图像进行不同的几何变换来进行监督;不变性损失就是构建了大的Memory Ban,即大的负样本,通过与正样本的对比学习,使得模型的泛化能力或者类的边界更有效。


3.1. Problem Formulation
标准的图像分类模型

LCE为标准分类器的监督,这是利用每一个样本对真实标签的监督,即不管一张图片经过如何的选择变换,都用它本身真实的标签(比如说这张图为一只猫,不管如何旋转或者裁剪,这种图片的真实标签还是一只猫)
LCE与LEQ两个损失函数的比较
LCE与LEQ这两个损失函数其实都是一样的,都是标准监督的损失函数,只不过预测结果与标签不同
LCE的预测结果是由网络![]() 得到,而LEQ的预测结果是由网络
得到,而LEQ的预测结果是由网络![]() 得到;
得到;
LCE的标签是图片原本的标签(比如说这张图片不管经过怎么样的变换,还是一只猫),而LEQ的标签是人为设定的(见3.2中Equivariance人为设定的标签)
损失函数解读:

结果为:对每个类别分别预测的概率
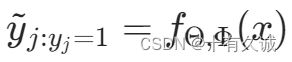
为:这种图片的实际类别(即标签)所预测的概率
交叉熵损失函数中包含了一个最基础的部分:![]()
参考资料:
在线:
【pytorch】交叉熵损失函数 nn.CrossEntropyLoss()-CSDN博客
离线:【pytorch】交叉熵损失函数 nn.CrossEntropyLoss()-CSDN博客 (2023_12_14 15_34_02).html
3.2. Injecting Inductive Biases through SSL
3.2.1 Enforcing Equivariance等价性
me:训练的是模型学习数据是哪种数据变化(为哪个Ti)的能力
Equivariance人为设定的标签
标签为a M dimensional one-hot encoded vector u属于{0,1}M
补充:
一个M维的one-hot编码向量是一个长度为M的向量,其中只有一个元素为1,其余元素都为0。这个1的位置表示该向量对应的类别。例如,对于3个类别(A、B、C),one-hot编码向量可以表示为:
A: [1, 0, 0]
B: [0, 1, 0]
C: [0, 0, 1]
这篇文章代码里面应该是16种数据变化,所以人为给定的标签为
T1变换的数据标签为:[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0](16维向量)
T2变换的数据标签为:[0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0](16维向量)
...
T16变换的数据标签为:[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1](16维向量)
Equivariance的损失函数

该函数为标准监督的损失函数,与LCE格式相同
![]() 为网络
为网络![]() 输出的结果,即对这张图片对每个变换分别预测的概率
输出的结果,即对这张图片对每个变换分别预测的概率
![]() :这种图片的实际属于那种数据变换(即属于哪个Ti)所预测的概率
:这种图片的实际属于那种数据变换(即属于哪个Ti)所预测的概率
3.2.2 Enforcing Invariance不变性(对比学习)
me:应该是学习一个图片经过变化之后,模型还能认出来是这张图片的原来图片的能力;这里应该来自同一张原图才属于一类,而不是按标签来看是否为一类。
对比学习损失函数

V0是没有经过变换的原始图片
Vr为原始的样本(me:Vr为参照物,Vm为要对比的数据)
Vm经过第m次变换之后的样本(m是变化的下指标,本篇文章解读为从0-15,公式中为0-(M-1)),目标就是要这两者尽可能接近;
如果Vm(m≠0)不是原图,那就拿原图Vr=V0跟Vm比较
如果Vm(m=0)是原图(即没有经过任何图片变化),那就拿原图V0 的 past representation![]()
(不懂这个past representation,应该是对这张原图V0 进行的一些分析)跟原图V0比较
s表示一个相似度度量,可以是一个余炫距离,可以是一个欧式里得距离,也可以是一个内积。
Dn是从负样本Memory Bank中抽取的小批量batch。
V'为负样本;
补充:温度的概念以及作业
 是温度,me:应该跟知识蒸馏那里温度作用是相同的
是温度,me:应该跟知识蒸馏那里温度作用是相同的
温度的选择还是要根据实际情况来

3.2.3 Multi-head Distillation(多头知识蒸馏)
teach:增加工作量
补充:基于logits的知识蒸馏
参考资料:
【经典简读】知识蒸馏(Knowledge Distillation) 经典之作
Knowledge Distillation - Neural Network Distiller

高温蒸馏过程的目标函数由distill loss(对应Soft-target)和Student loss(对应Hard-target)加权得到![]()
第二部分Loss![]() 的必要性其实很好理解: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是老师仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
的必要性其实很好理解: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是老师仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
本篇文章多头知识蒸馏的损失函数
![]() 和
和![]() 输出都是分布,所以teacher与student的损失函数为KL散度
输出都是分布,所以teacher与student的损失函数为KL散度
![]() 的输出不是一个分布(me应该是:是否为这张变换后的图1与图2,它们的原图是否相同,即Yes/No),所以teacher与student的损失函数为L2
的输出不是一个分布(me应该是:是否为这张变换后的图1与图2,它们的原图是否相同,即Yes/No),所以teacher与student的损失函数为L2
(但是这篇论文我没有看到介绍损失函数L2的地方!!!)

Overall Objective总体目标
The overall loss is simply a combination of inductive andbaseline objectives
![]()
4.Experimental Evaluation
teach:这篇文章一个引用量上不去的其中一个原因就是性能太高了,其他文章不好超过这篇文章,所以直接不引用;另外没有给这篇文章的方法一个缩写,不好被别人引用,所以写文章时最好将自己取一个简称,比如说首字母的缩写,方便别人引用、记住。
在两个常用数据集miniImageNet and tieredImageNet以及CIFAR100的子集CIFAR-FSand FC100 进行实验
CIFAR-FS dataset

FC100 dataset

miniImageNet dataset
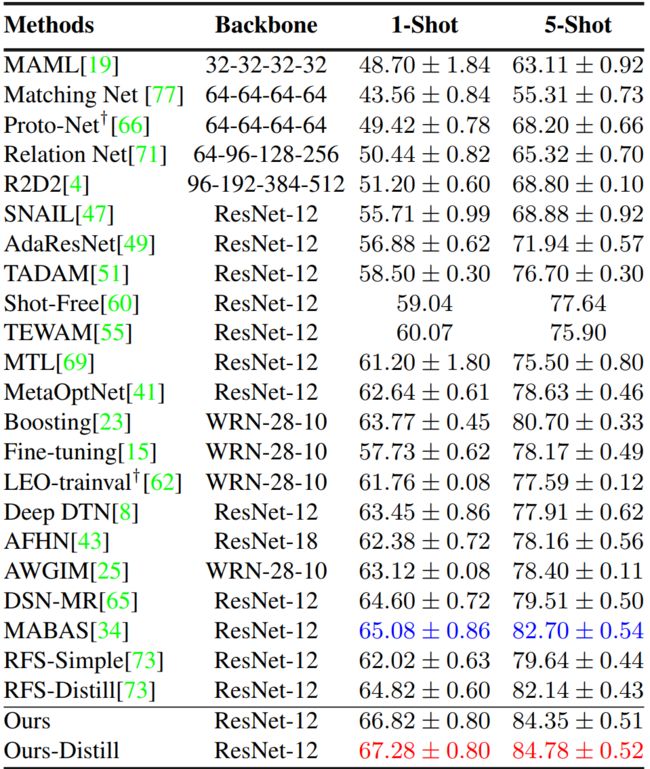
4.1. Results
tieredImageNet dataset
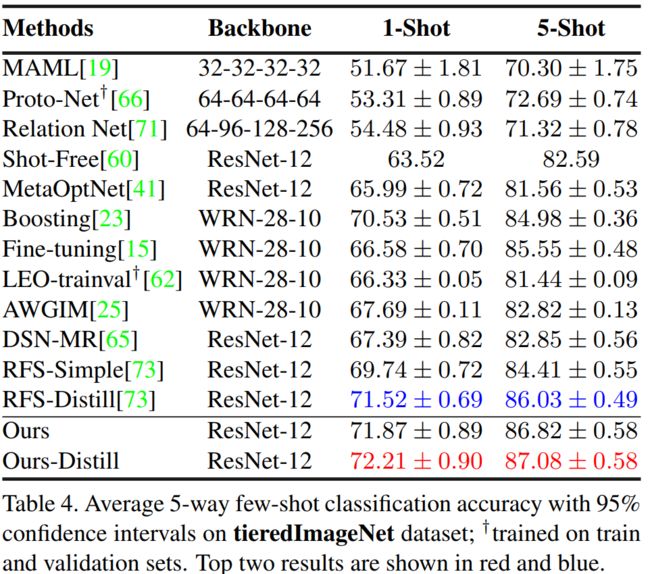
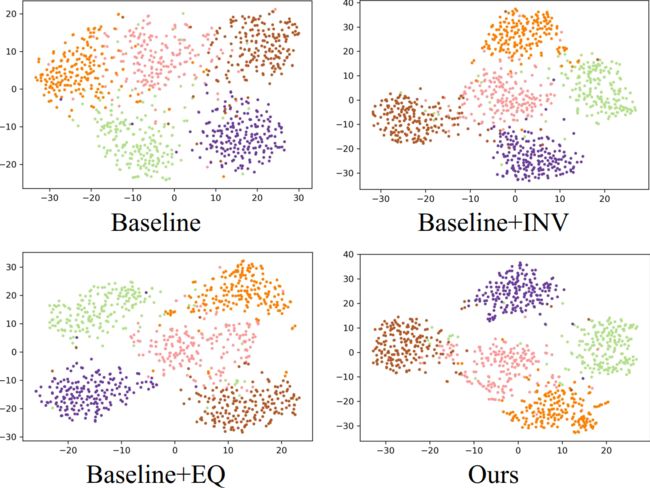
4.3. Analysis
从miniImageNet随机5个类别中分类的可视化结果
参考资料
论文下载
Exploring Complementary Strengths of Invariant and Equivariant.pdf

代码
GitHub - nayeemrizve/invariance-equivariance: "Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning" by Mamshad Nayeem Rizve, Salman Khan, Fahad Shahbaz Khan, Mubarak Shah (CVPR 2021)
参考资料
本篇文章的teach是指这个视频作者的观点
【CVPR 2021】小样本学习论文解读 | IERs:Exploring Complementary Strengths of Invariant ..._哔哩哔哩_bilibili
下面这个博客未参考上
Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning-CSDN博客
知识蒸馏相关
深度学习中的知识蒸馏技术!-CSDN博客
离线:
深度学习中的知识蒸馏技术!-CSDN博客 (2023_12_14 19_39_02).html
Knowledge Distillation - Neural Network Distiller
目标检测-定位蒸馏:logit蒸馏与feature蒸馏之争-CSDN博客