【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 概述
【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 概述
- 模型简介
-
- 基于CNN的判断每张人脸是否是说话人的模型
- 基于Transformer-Encoder的判断同一段对话中不同轮次的说话人关系的模型
- 说话人识别求解器
- 文件结构
- 如何运行代码(以5 turns为例)
模型简介
本基线模型共分为三个部分:
- 基于CNN的判断每张人脸是否是说话人的模型;
- 基于Transformer-Encoder的判断同一段对话中不同轮次的说话人关系的模型;
- 和使用上述两个预测结果求解二次型优化问题的说话人识别求解器。
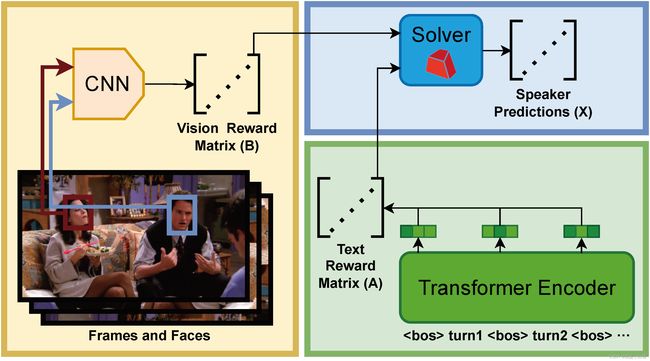
基于CNN的判断每张人脸是否是说话人的模型
我们微调 CNN 模型 M 1 M_1 M1 以预测每帧中每张人脸是说话人的概率:$p_{face} = M_1(face) \in (0,1) $ ,其中 f a c e face face 是通过使用bounding box b b b 裁剪图像 i m g img img 获得的图像区域。如果此人脸的角色名称与说话人姓名相同,则此人脸 y f a c e y_{face} yface 的说话标签设置为 1 1 1,否则设置为 0 0 0: y f a c e = m a t h b f 1 [ c = y ] y_{face} = mathbf{1}[c = y] yface=mathbf1[c=y]。使用交叉熵分类损失作为训练目标。
基于Transformer-Encoder的判断同一段对话中不同轮次的说话人关系的模型
我们微调一个Transformer-Encoder模型作为 M 2 M_2 M2,以预测对话中的每 2 个轮次是否由同一说话人说出。给定一个由 m m m 语句组成的示例,我们使用
L M 2 = M S E ( p s i m , y s i m ) + M S E ( p s i m , p s i m T ) \mathcal{L}_{M_2} = MSE(p_{sim}, y_{sim}) + MSE(p_{sim}, p_{sim}^T) LM2=MSE(psim,ysim)+MSE(psim,psimT)
其中 y s i m ∈ { 0 , 1 } m × m y_{sim} \in \{0, 1\}^{m \times m} ysim∈{0,1}m×m 是两个轮次的对话是否是同一个人说的的正确标签。
说话人识别求解器
为了利用视觉信息和上下文信息,我们需要结合上述两个模型的输出来进行说话人识别。
对于数据集中的每个条数据,我们首先通过记录每帧中出现的所有面孔来获得候选说话人集: m a t h b f C = c 1 , c d o t s , c l mathbf{C} = {c_1, cdots, c_{l}} mathbfC=c1,cdots,cl。
我们构造一个奖励矩阵 m a t h b f B ∈ R l × m mathbf{B} \in \mathbb{R}^{l \times m} mathbfB∈Rl×m ,表示选择一个角色 c i c_i ci 作为轮次 u j u_j uj 的说话人的奖励。如果 c i c_i ci 的人脸出现在帧 v j v_j vj 中,则 b i j b_{ij} bij 为 M 1 M_1 M1 预测出的概率,否则 b i j = 0 b_{ij} = 0 bij=0。
随后我们构建另一个奖励矩阵 A ∈ R m × m \mathbf{A} \in \mathbb{R}^{m \times m} A∈Rm×m,以表示将相同的说话者分配给两个轮次 u i u_i ui、 u j u_j uj的奖励。如前文所述,我们首先将整个对话传递到模型 M 2 M_2 M2 中以获取相似性矩阵 $p_{sim} \in \mathbb{R}^{m \times m} $。然而,如果我们直接使用相似性矩阵 p s i m p_{sim} psim 作为奖励矩阵 A \mathbf{A} A,因为 p s i m p_{sim} psim 中的所有元素都大于 0,优化求解器倾向于将相同的说话者分配给每个轮次,以获取所有奖励。为了避免这种情况,我们将相似性矩阵减去其元素的平均值, A = p s i m − mean ( p s i m ) \mathbf{A} = p_{sim} - \text{mean}(p_{sim}) A=psim−mean(psim)。
有了 A \mathbf{A} A 和 B \mathbf{B} B,多模态多轮次说话人识别任务就可以用二次二进制优化问题来表示了:
Maximize f ( X ) = ( 1 − α ) X T A X + α X B s.t. X ∈ { 0 , 1 } m × l , ∑ j = 1 l X i j = 1 , i = 1 , 2 , … , m \begin{align} \text{Maximize} \quad & f(X) = (1-\alpha)X^TAX + \alpha XB \\ \text{s.t.} \quad & X \in \{0, 1\}^{m \times l}, \\ \quad & \sum_{j=1}^{l} X_{ij} = 1, \quad i = 1, 2, \ldots, m \end{align} Maximizes.t.f(X)=(1−α)XTAX+αXBX∈{0,1}m×l,j=1∑lXij=1,i=1,2,…,m
其中 α \alpha α 是一个超参数,用于控制 2 个奖励的权重。最后这个问题就可以使用像Gurobi这样的优化问题求解软件解决。
文件结构
注意:代码仅供参考,您可能需要进行一些修改才能正确运行它们
-
finetune_cnn-multiturn.py: 微调cnn模型的代码 -
dialog_roberta-contrastive.py: 微调deberta模型的代码 -
convex_optimization.py: 将两个模型产出的结果组合在一起,并通过gurobi优化器求解出每个句子最适合的说话人
如何运行代码(以5 turns为例)
可以在百度网盘下载数据集中的图片,和我们提供的基线模型训练完成后的checkpoint:
-
下载数据集,并保存在
$base_folder/5_turns文件夹下 -
训练cnn模型
python ./finetune_cnn-multiturn.py \
--data_base_folder $base_folder/5_turns --output_path $cnn_output_path \
- 用cnn模型在测试集上生成结果
output_path=./snap/multiturn/cnn/0920-ft_cnn-8_turns-lr_${lr}
CUDA_VISIBLE_DEVICES=7 python ./finetune_cnn-multiturn.py --func test \
--data_base_folder $base_folder/5_turns \
--output_path $cnn_output_path --model_ckpt $cnn_output_path/best_model.pth
然后可以在$cnn_output_path/test_output.json,$cnn_output_path/test-hard_output.json文件中找到cnn模型的预测结果。
- 训练deberta模型
先在ijcai2019数据上预训练(大约需要1天时间)。这个数据集的预处理方式和MPC-BERT相同,详见论文 MPC-BERT: A Pre-Trained Language Model for Multi-Party Conversation Understanding 和代码
python ./dialog_roberta-contrastive.py --func train --sim_func linear \
--dataset ijcai2019 --data_base_folder $base_folder/ijcai2019 \
--model_type deberta --roberta_model microsoft/deberta-v3-base \
--output_path $deberta_output_path_pretrain \
> $output_path/train.log 2>&1 &
然后在本数据集上微调(大约需要2小时)
python ./dialog_roberta-contrastive.py --sim_func linear --weight_decay 0.02 \
--model_type deberta --roberta_model $deberta_output_path_pretrain/checkpoint-valid \
--data_base_folder $base_folder/5_turns --output_path $deberta_output_path
- 用deberta模型在测试集上生成结果。(需要自己先根据训练过程选择合适的$ckpt)
python ./dialog_roberta-contrastive.py --func test \
--model_type deberta --roberta_model $deberta_output_path/checkpoint-$ckpt \
--data_base_folder $base_folder/5_turns --output_path $deberta_output_path \
然后可以在$deberta_output_path/test_output.pkl文件中找到deberta模型的预测结果。
- 根据上述两个模型输出的reward,求解优化问题,并得到最终答案。(可以先在验证集上运行并筛选合适的alpha超参数)。注意:需要先正确安装gurobi求解器,cvxpy包才能正常运行
for split in test test-hard
do
python convex_optimization.py --alpha $alpha \
--test_metadata_fname $base_folder/5_turns/${split}-metadata.json \
--test_cnn_pred_fname $cnn_output_path/${split}_output.json \
--test_roberta_pred_fname $deberta_output_path/test_output.pkl \
--output_fname $final_output_path/${split}_output.json
done
然后可在$final_output_path中找到最最终预测结果。将test_output.json, test-hard_output.json中的内容合并在同一个list后即可提交。