深度学习|词嵌入的演变
文本嵌入,也称为词嵌入,是文本数据的高维、密集向量表示,可以测量不同文本之间的语义和句法相似性。它们通常是通过在大量文本数据上训练 Word2Vec、GloVe 或 BERT 等机器学习模型来创建的。这些模型能够捕获单词和短语之间的复杂关系,包括语义、上下文,甚至语法的某些方面。这些嵌入可用于语义搜索等任务,其中文本片段根据含义或上下文的相似性进行排名,以及其他自然语言处理任务,如情感分析、文本分类和机器翻译。
嵌入 API 的演变和出现
在自然语言处理(NLP)领域,文本嵌入从根本上改变了我们理解和处理语言数据的方式。通过将文本信息转换为数字数据,文本嵌入促进了复杂的机器学习算法的开发,该算法能够进行语义理解、上下文识别和更多基于语言的任务。在本文[1]中,我们探讨了文本嵌入的进展并讨论了嵌入 API 的出现。
文本嵌入的起源
在NLP的早期阶段,使用了one-hot编码和词袋(BoW)等简单技术。然而,这些方法未能捕捉语言的上下文和语义的复杂性。每个单词都被视为一个孤立的单元,不了解它与其他单词的关系或其在不同上下文中的用法。
Word2Vec

2013 年 Google 推出的 Word2Vec 标志着 NLP 领域的重大飞跃。 Word2Vec 是一种使用神经网络从大型文本语料库中学习单词关联的算法。因此,它生成单词的密集向量表示或嵌入,捕获大量语义和句法信息。单词的上下文含义可以通过高维空间中向量的接近程度来确定。
GloVe:用于单词表示的全局向量
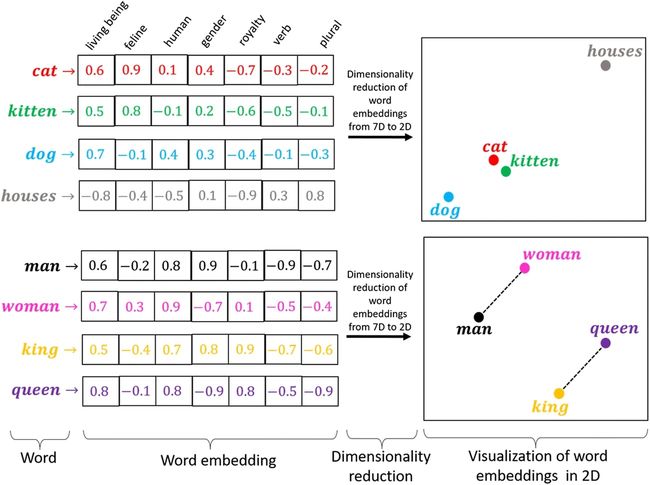
斯坦福大学的研究人员在 2014 年推出了 GloVe,进一步推进了词嵌入的概念。GloVe 通过在整个语料库中更全面地检查统计信息来创建词向量,从而在 Word2Vec 的基础上进行了改进。通过考虑本地上下文窗口和全局语料库统计数据,它可以实现更细致的语义理解。
基于 Transformer 的嵌入:BERT 及其变体
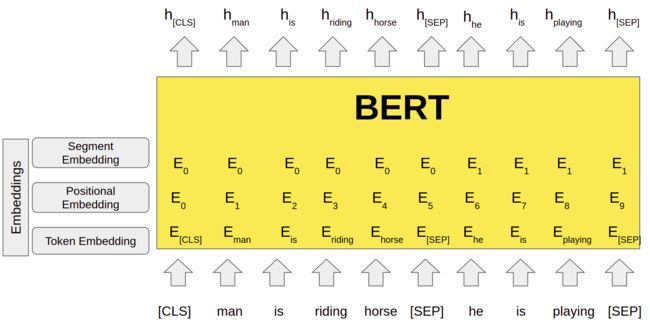
2017 年推出的 Transformer 架构通过引入注意力机制的概念,彻底改变了 NLP。随后,谷歌于 2018 年发布的 BERT(来自 Transformers 的双向编码器表示)提供了上下文相关的词嵌入。 BERT 通过查看单词前后的单词来考虑单词的完整上下文,这与上下文无关模型的 Word2Vec 和 GloVe 不同。自 BERT 发布以来,已经开发了多种变体和改进,例如 RoBERTa、GPT(生成式预训练变压器)等。
嵌入 API 的出现
最近,机器学习应用程序的增长推动了提供预训练词嵌入的 API(应用程序编程接口)的开发。这些 API 简化了获取词嵌入的任务,让开发人员能够专注于构建应用程序。
例如 Google 的 TensorFlow Hub,它提供可以生成嵌入的预训练模型。这些模型包括多种选项,从 Word2Vec 和 GloVe 到基于转换器的模型(如 BERT)。同样,Hugging Face 的 Transformers 库提供了一种获取预训练 Transformer 嵌入的简单方法。
此类 API 极大地民主化了最先进的 NLP 技术的获取。开发人员可以将这些 API 集成到他们的应用程序中,以执行语义搜索、情感分析、文本分类等任务,而不需要广泛的机器学习专业知识或训练此类模型的资源。
因此,我们可以总结说 Embedding API 是一种机器学习 API,提供对预先训练的词嵌入的访问。词嵌入是词的向量表示,捕获词的含义以及与其他词的关系。它们允许实现 (NLP) 任务,例如语义搜索、情感分析和文本分类。
嵌入 API 很重要,因为它们使开发人员可以轻松访问最先进的 NLP 技术。过去,想要使用词嵌入的开发人员必须训练自己的模型。这是一个耗时且资源密集的过程。嵌入 API 使开发人员能够快速轻松地开始 NLP 任务,而无需拥有丰富的机器学习专业知识。
有许多可用的嵌入 API,包括:
- Google’s PaLM 2, textembedding-gecko@latest
- Google’s TensorFlow Hub
- Hugging Face’s Transformers library
- Stanford’s GloVe library
- CoVe (Contextual Vectors)
- FastText
- ELMo
这些 API 提供各种预先训练的词嵌入,包括 Word2Vec、GloVe 和基于 Transformer 的模型(如 BERT)。
当开发人员使用嵌入 API 时,他们首先需要选择他们想要使用的预训练模型。然后,API 将返回输入文本中每个单词的向量表示。然后可以使用向量表示来执行 NLP 任务。
使用嵌入 API 的好处
- 易于使用:嵌入 API 使开发人员可以轻松开始 NLP 任务。他们不需要任何机器学习方面的专业知识或资源来训练自己的模型。
- 准确性:嵌入 API 为各种 NLP 任务提供高精度。这是因为他们接受了大型文本和代码数据集的训练。
- 可扩展性:嵌入 API 是可扩展的,因此它们可用于处理大量文本。
嵌入 API 是 NLP 任务的强大工具。它们使开发人员可以轻松访问最先进的 NLP 技术并执行语义搜索、情感分析和文本分类等任务。随着 NLP 领域的不断发展,嵌入 API 将变得更加重要。
总结
自 NLP 出现以来,文本嵌入经历了重大演变,每一次进步都让我们更接近于有效模仿人类对语言的理解。随着嵌入 API 的出现,这些强大的工具可供广大开发人员使用,进一步加速了 NLP 应用程序的进步。
Reference
[1]Source: https://dr-arsanjani.medium.com/the-evolution-of-text-embeddings-75431139133d
本文由 mdnice 多平台发布