爬虫快速入门
爬虫基础入门
- 爬虫原理
-
- 1. HTTP协议与WEB开发
-
- 1.简介
- 2.请求协议与响应协议
- 3.请求方式: get与post请求
-
- 区分1
- 区分2
- 环境准备
-
- 1.安装python环境
- 2.安装requests库
-
- 安装方式
-
- 验证安装成功
- 三种反爬机制
-
- 1.UA反爬
- 2.referer反爬
- 3.cookie反爬
- 请求参数
-
- get请求以及查询参数
- post请求以及请求体参数
- 爬取图片视频
-
- (1)直接爬取媒体数据流
- (2)批量爬取数据
爬虫原理
1. HTTP协议与WEB开发
1.简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。
浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。

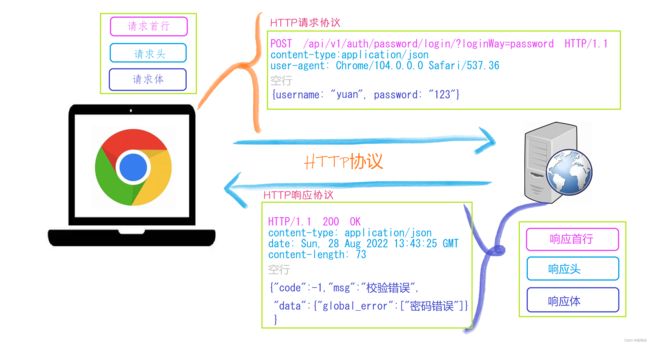
2.请求协议与响应协议
1.http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议。
2.用于HTTP协议交互的信被为HTTP报文。
3.请求端(客户端)的HTTP报文 做请求报文,响应端(服务器端)的 做响应报文。HTTP报文本身是由多行数据构成的字文本。
一个完整的URL包括:协议、ip、端口、路径、参数
URL:https :// www.baidu.com /s ? wd=alex
协议 :// 域名(端口) /路径/xxx/yyy ? 查询参数
其中https是协议,www.baidu.com 是IP,端口默认80(可以不写),/s是路径,参数是wd=alex
3.请求方式: get与post请求
区分1
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,
EditBook?name=test1&id=123456.
- POST方法是把提交的数据放在HTTP包的请求体中(通常不显示出来).
区分2
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制)
- POST方法提交的数据没有限制
响应状态码:当客户端向服务器端发送请求时, 返回的请求结果。借助状态码,用户可以知道服务器端是正常 理了请求,还是出现了 。状态码如200 OK,以3位数字和原因组成。
环境准备
1.安装python环境
通过下面的链接: 7天速成Python——第一天安装python环境
2.安装requests库
Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。
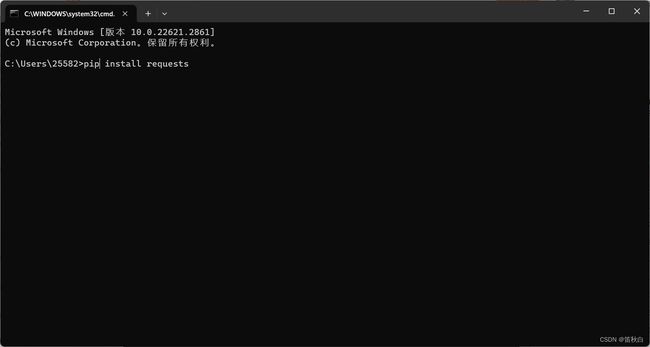
安装方式
打开终端或者cmd,在里面输入以下指令并回车
pip install requests
验证安装成功
在终端中先输入python,然后输入import requests,出现以下则安装成功。

三种反爬机制
1.UA反爬
百度热搜


首先右击空白处,选择查看网页源代码,点击1,清空当前内容,点击2(network),然后选择fetch/XHR ,然后点击3(刷新),选择下图信息
然后点击4(headers),将5(User-Agent)复制加进下面代码中。
- User-Agent为百度服务器用于反爬的凭证,将其加入headers向百度服务器发请求,并将请求结果res以"w"的形式写入baidu.html中
import requests#引入requests库
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
}
res = requests.get(
"https://www.baidu.com/",#请求百度首页
headers=headers
)
#解析数据
with open("baidu.html", "w") as f:
#在当前路径下,以写的方式打开一个名为'url.txt',如果不存在则创建
f.write(res.text)
2.referer反爬
豆瓣电影

首先右击空白处,选择查看网页源代码,点击1,清空当前内容,点击2(network),然后点击3(fetch/XHR),然后点击4(刷新),点击5(包含网页信息的文件),点击6(响应)
- Referer和User-Agent为豆瓣服务器用于反爬的凭证,将其加入headers向豆瓣服务器发请求,并将请求结果res打印出来
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Referer": "https://movie.douban.com/explore",
}
res = requests.get(
"https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags=",
headers=headers
)
#解析数据
print(res.text)
3.cookie反爬
雪球股票


首先右击空白处,选择查看网页源代码,点击1,清空当前内容,点击2(network),然后点击3(fetch/XHR),然后点击4(刷新),点击5(包含网页信息的文件),点击6(header),将7(cookie)复制
- Referer,cookie,User-Agent为雪球服务器用于反爬的凭证,将其加入headers向雪球服务器发请求,并将请求结果res打印出来
import requests url = "https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=1&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz" cookie = 'xq_a_token=a0f5e0d91bc0846f43452e89ae79e08167c42068; xqat=a0f5e0d91bc0846f43452e89ae79e08167c42068; xq_r_token=76ed99965d5bffa08531a6a47501f096f61108e8; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY5NTUxNTc5NCwiY3RtIjoxNjkzMjAzODIzMzAwLCJjaWQiOiJkOWQwbjRBWnVwIn0.MCIGGTGaSPe9nVuXkyrXQTlCthdURSnDtqm8dGttO2XYHeaMPSKmHQvsJmbw3OJTRnkf0KHZvgF0W3Rv-9uYe4P2Wizt0g2QzQonONjUmExABmZX0e3ara8BzBQ3b96H7dm0LV4pdBlnOW0A9PUmGRouWM7kVUOGPvd3X7GkB7M_th8pV8SZo9Iz4nzjrwQzxPBa0DlS7whbeNeXMnbnmAPp7z-eG75vdE2Pb3OyZ5Gv-FINhpQtAWo95lTxZVw5C5VHSzbR_-z8uqH6DD0xop4_wvKw5LIVwu6ZZ6TUnNFr3zGU9jWqAGgdzcKgO38dlL6uXNixa9mrKOd1OZnDig; cookiesu=431693203848858; u=431693203848858; Hm_lvt_1db88642e346389874251b5a1eded6e3=1693203851; device_id=7971eba10048692a91d87e3dad9eb9ca; s=bv11kb1wna; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1693203857' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36', "referer": "https://xueqiu.com/", "cookie": cookie, } res = requests.get(url, headers=headers)//get请求方式 print(res.text)
请求参数
get请求以及查询参数

import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Referer": "https://movie.douban.com/explore",
}
res = requests.get(
"https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags=",
headers=headers,
# params={ # 查询
# "count": "20",
# "tags": "悬疑"
# }
)
#解析数据
print(res.text)
post请求以及请求体参数


import requests
while 1:
wd = input("请输入翻译内容:")
res = requests.post("https://aidemo.youdao.com/trans?", params={}, headers={},
data={
"q": wd,
"from": "Auto",
"to": "Auto"
})
print(res.json().get("translation")[0])
爬取图片视频
(1)直接爬取媒体数据流
import requests
# (1)下载图片
url = "https://pic.netbian.com/uploads/allimg/230812/202108-16918428684ab5.jpg"
res = requests.get(url)
#解析数据
with open("a.jpg", "wb") as f:
f.write(res.content)
#(2)下载视频
url = "https://vd3.bdstatic.com/mda-nadbjpk0hnxwyndu/720p/h264_delogo/1642148105214867253/mda-nadbjpk0hnxwyndu.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1693223039-0-0-e2da819f15bfb93409ce23540f3b10fa&bcevod_channel=searchbox_feed&pd=1&cr=2&cd=0&pt=3&logid=2639522172&vid=5423681428712102654&klogid=2639522172&abtest=112162_5"
res = requests.get(url)
#解析数据
with open("美女.mp4", "wb") as f:
f.write(res.content)
(2)批量爬取数据
import requests
import re
import os
# (1)获取当页所有的img url
start_url = "https://pic.netbian.com/4kmeinv/"
res = requests.get(start_url)
img_url_list = re.findall("uploads/allimg/.*?.jpg", res.text)
print(img_url_list)
# (2)循环下载所有图片
for img_url in img_url_list:
res = requests.get("https://pic.netbian.com/" + img_url)
img_name = os.path.basename(img_url)
with open(img_name, "wb") as f:
f.write(res.content)