SQL基础:查询的基本使用
上一节我们讲述了记录的基本操作,这一节我们来单独讲一下查询。
查询基本结构
首先我们来看下查询的基本结构
SELECT
column1,
column2,
...
FROM
table_name
[WHERE
condition]
[GROUP BY
column1, column2, ...]
[HAVING
aggregate_function(column) condition]
[ORDER BY
column1 [ASC | DESC]];
其中中括号包含的部分是非必须的。接下来我们来学习下每个部分的作用。
辅助表创建
为了讲述方便,这里我们新增一张课程表,建表SQL
CREATE TABLE `courses` (
`course_id` INT NOT NULL,
`course_name` VARCHAR(100) NOT NULL,
`instructor` VARCHAR(50) NOT NULL,
`schedule` VARCHAR(50) NOT NULL,
PRIMARY KEY (`course_id`)
);插入数据的SQL如下
INSERT INTO `courses` (`course_id`, `course_name`, `instructor`, `schedule`) VALUES
(1, 'Introduction to Computer Science', 'Prof. Smith', 'Mon/Wed 10:00 AM - 11:30 AM'),
(2, 'Database Management', 'Prof. Smith', 'Tue/Thu 2:00 PM - 3:30 PM'),
(3, 'Web Development', 'Prof. Davis', 'Mon/Wed/Fri 1:00 PM - 2:30 PM'),
(4, 'Mathematics for Computer Science', 'Prof. Davis', 'Tue/Thu 10:00 AM - 11:30 AM'),
(5, 'Artificial Intelligence', 'Prof. White', 'Wed/Fri 3:00 PM - 4:30 PM');
执行完毕之后我们将拥有2张表

where关键字
where的作用,是指定查询条件,缩写返回数据的范围。
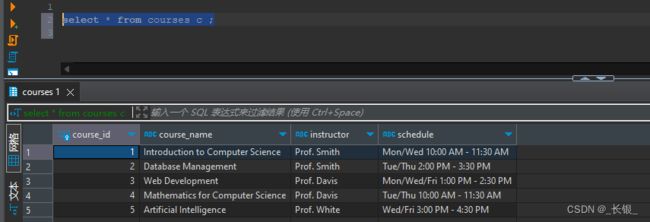
select * from courses c ;将得到
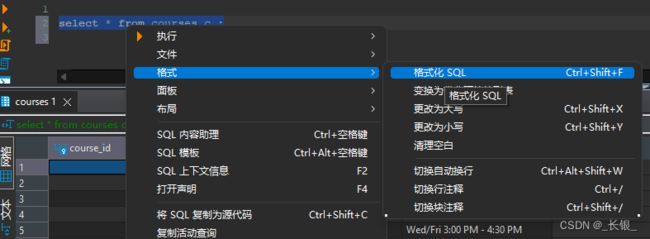
这里我们格式化下SQL,并加上筛选
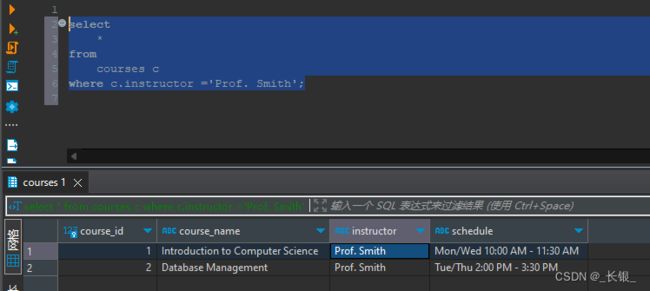
我们将得到两条符合条件的数据
group by 语句
group by 语句即分组语句,by后边跟上一列或多列,表示将数据分组。常和聚合函数配合使用。
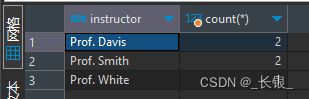
举个例子,这里我们要获取每个导师授课的课程数量,那就需要以导师名称instructor作为分组条件,使用count(*)聚合函数进行计数。
select
instructor ,count(*)
from
courses c
-- where c.instructor ='Prof. Smith'
group by instructor ;得到
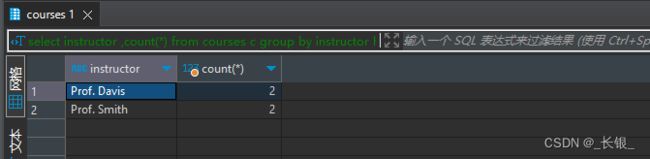
having语句
如果说where语句是第一层过滤,那么having就是第二层过滤。它是对group后的结果进行过滤。
举个例子,这里我们要在前一次查询的基础上筛选课程数量为2的导师,就可以用having
select
instructor ,count(*)
from
courses c
-- where c.instructor ='Prof. Smith'
group by instructor
having count(*)=2
;结果
order by语句
见文知意,这个语句是用来对结果集进行排序的。
直接查询课程表,可以看到是以id排序的
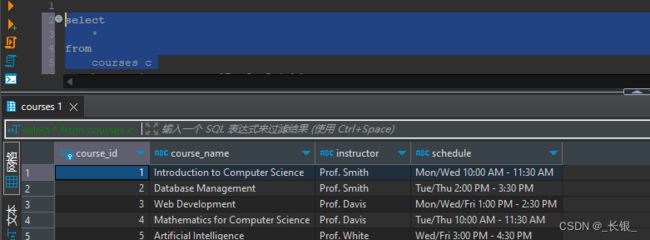
如果我们想让它根据名称排序
select
*
from
courses c
order by course_name
;可以看到,结果就根据名称进行A-Z的排序了

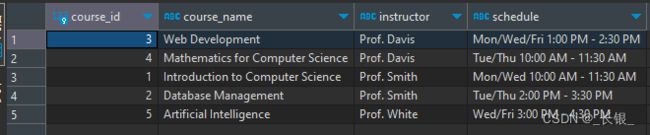
加 desc 即逆序
select
*
from
courses c
order by course_name desc
;
结果
小结
本节我们讲述了查询的基本结构和使用,下一节我们将对前面学习的所有内容进行一下小结。