监督学习之回归模型
1.术语解释
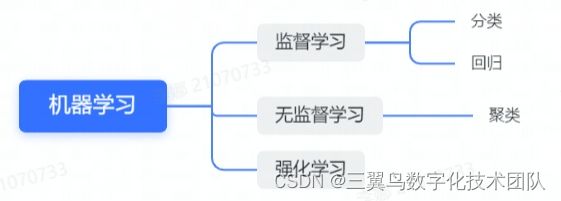
监督学习:利用一组有标签的样本数据训练和调优模型参数,使其达到所要求性能的过程。
分类模型:分类的输出为研究对象所属的类别,类别状态个数有限且离散,是一种定性分析。例如,天气晴、阴、雨三种类型,明天天气预测一定是属于这三种天气类型之一。
回归模型:回归所预测输出为连续的数值类型,属于一种定量分析。例如,回归模型用于预测明天降雨量具体是多少,是一个连续的变量。
2.回归模型
2.1 线性回归
线性回归假设因变量和自变量之间是线性的,表征了从输入变量到输出变量之间的线性映射关系,利用回归方程对一个或多个自变量和因变量之间关系进行建模的一种分析方式,数学形式 。根据自变量的数目可划分为一元线性回归和多元线性回归。
。根据自变量的数目可划分为一元线性回归和多元线性回归。
应用场景:要求自变量和因变量是线性关系,如身高体重预测、工龄薪资预测、房价预测等。
2.1.1 一元线性回归实例
我们结合身高_体重曲线拟合案例,介绍一元线性回归的实际应用。本案例主要目的是根据身高和体重数据拟合一条最佳曲线,输入身高值就可以预测出体重。
本案例使用的数据集包括600个样本,部分数据如下

从表中可以获知该数据集包括三个标签,即“gender”,“height”,“weight”,其中“height”项作为自变量H(输入),“weight”为因变量W(输出),建立一元线性回归模型$$W=aH+b$$进行数据拟合,python实现过程如下:
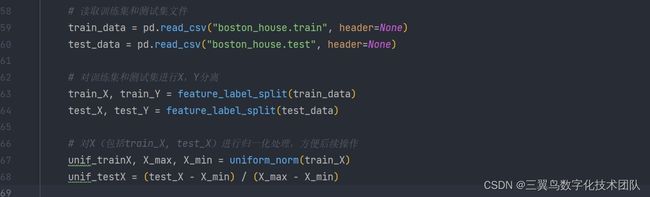
(1)首先,导入数据,500个样本作为训练集,其余100测试集用于验证
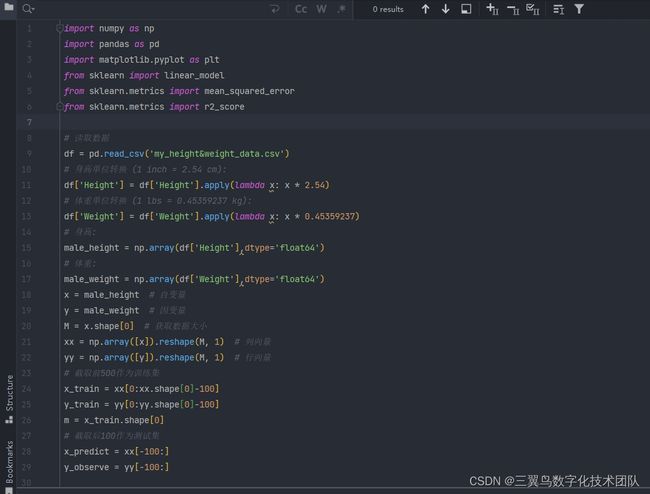
(2)使用sklearn提供的线性回归函数拟合数据,或者直接使用正规方程,求解模型参数a和b


(3) 输出结果:
所得线性回归方程为:
W=1.07H-102.10


2.1.2 多元线性回归实例
波士顿房地产市场竞争激烈,而你想成为该地区最好的房地产经纪人。为了更好地与同行竞争,你决定运用机器学习的一些基本概念,帮助客户为自己的房产定下最佳售价。幸运的是,你找到了波士顿房价的数据集,里面聚合了波士顿包含多个特征维度的房价数据。你的任务是用可用的工具进行统计分析,并基于分析建立优化模型,这个模型将用来为你的客户评估房产的最佳售价。
数据集如下图所示,本数据集共包含381条样本,每个样本包含13个特征维度,309个作为训练集,72个测试集

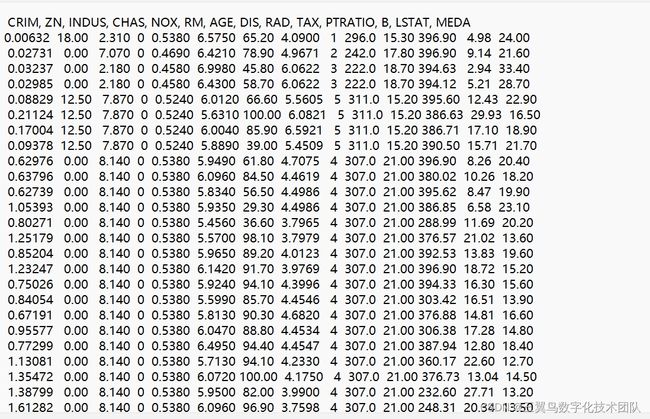
(1)利用多元线性回归模型对数据进行学习,并预测测试集数据。将CRIM, ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO, B, LSTAT这13个特征作为训练输入,MEDA特征看作输出,建立以下线性回归方程
![]()
其中 ![]() 为待学习的14个系数,这样波士顿房价问题就转化为一个多元线性回归问题。
为待学习的14个系数,这样波士顿房价问题就转化为一个多元线性回归问题。
(2)老规矩,先上代码,导入数据集
(3)LinearRegression()进行模型训练,求解参考式(2.1.8)正规方程

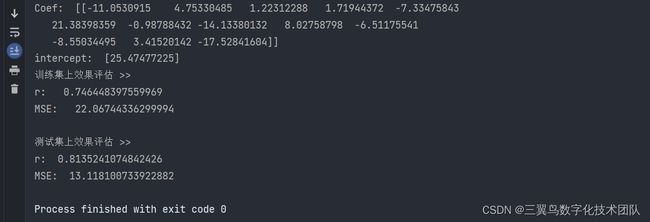
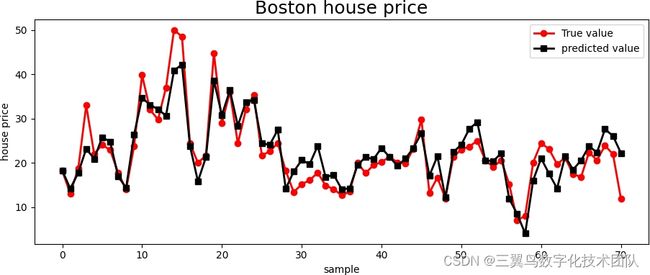
(4)结果分析
可知波士顿房价多元线性回归方程为
![]()
2.1.3 算法原理
A. 一元线性回归
给定一组由输入 和输出
和输出  构成的训练数据集
构成的训练数据集 ![]() ,
, ![]() 线性回归就是通过该训练集训练得到一个线性模型来最大限度地根据输入 拟合输出 ,使得
线性回归就是通过该训练集训练得到一个线性模型来最大限度地根据输入 拟合输出 ,使得![]() 。因此,线性回归任务的关键在于确定参数
。因此,线性回归任务的关键在于确定参数  和
和  ,使得拟合输出
,使得拟合输出 尽可能逼近真实输出 ,通常使用残差平方和函数来表示预测值与实际值之间的损失函数
尽可能逼近真实输出 ,通常使用残差平方和函数来表示预测值与实际值之间的损失函数
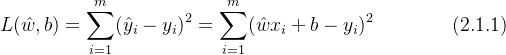
为使损失函数值![]() 最小化,分别对 和 求一阶偏导
最小化,分别对 和 求一阶偏导
令上式![]() ,
,![]() ,可得到最优解析解
,可得到最优解析解 ![]() 和
和 ![]() 代数式
代数式
B. 多元线性回归
一元线性回归研究的是目标变量和一个自变量之间的回归问题,但有时候在很多实际问题中,影响目标变量的自变量往往不止一个,而是多个,比如绵羊的产毛量这一变量同时受到绵羊体重、胸围、体长等多个变量共同影响,因此需要设计一个目标变量与多个自变量间的回归分析,即多元回归分析。
给定一组由输入 和输出 构成的多特征训练数据集![]() ,其中
,其中![]() ,
,![]() ,
, 为输入的特征数量,多元线性回归一般方程为
为输入的特征数量,多元线性回归一般方程为
![]()
将参数向量  与截距 合并为向量表达形式,
与截距 合并为向量表达形式,![]() 。此时训练集输入部分可表示为一个
。此时训练集输入部分可表示为一个 ![]() 维的矩阵
维的矩阵  :
:
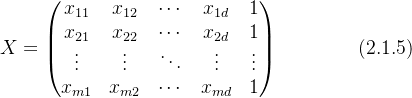
输出向量![]() ,可得损失函数矩阵形式
,可得损失函数矩阵形式
![]()
对上式求偏导可得
![]()
该多元线性回归的正规方程解为
![]()
求得多元线性回归方程点积形式为
①当数据量较小时,该方法求最优解是可行的,当数据量很大时,对矩阵求逆运算量极大,这就需要使用梯度下降方法或者牛顿迭代法逼近最优解;
②当 为非满秩矩阵时,奇异阵  的逆矩阵不存在,不能采用最小二乘法求解。
的逆矩阵不存在,不能采用最小二乘法求解。
C. 梯度下降法
首先,计算代价函数 ![]() 的一阶梯度向量
的一阶梯度向量
![]()
给定一个任意点 ![]() ,设定步长(学习率)
,设定步长(学习率) ![]() ,容差
,容差![]() ,迭代下式
,迭代下式
![]()
直至满足![]() ,此时总梯度趋近于0,说明在函数在
,此时总梯度趋近于0,说明在函数在 ![]() 处取最小值。
处取最小值。
2.2 Ridge回归
Ridge回归可以看作是线性回归的改进算法,Ridge回归通过L2正则化项来改进损失函数,以增强回归算法的鲁棒性。以房价估计为例,在影响房价的众多因素中,会存在一些对房价影响基本可以忽略不计的因素,如何从众多因素中找到关键影响因素,对无关紧要的因素进行权重压缩是一个值得考虑的问题。由式(2.1.8)可知线性回归的最优参数估计为 ![]() ,当训练样本的特征数大于样本数量时,矩阵 非满秩, 不可逆,所以
,当训练样本的特征数大于样本数量时,矩阵 非满秩, 不可逆,所以 ![]() 是不可估计的。
是不可估计的。
2.2.1 应用实例
| 序号 |
price |
bedrooms |
bathrooms |
living_sqrt |
floors |
| 0 |
545000 |
3 |
2.25 |
1670 |
1 |
| 1 |
765000 |
4 |
2.5 |
3300 |
2 |
| 2 |
720000 |
3 |
3.25 |
3190 |
2 |
以二手房房价估计问题为例,我们使用Ridge回归来解决该回归问题,本案例的输入为卧室数量(bedrooms)、卫生间数量(bathrooms)、居住面积(living_sqrt)和楼层(floors)4个特征,输出为房子的价格。
目前我们手中只有三个样本作为训练数据,此时样本数量(3)<特征数(4), 为奇异矩阵,故使用线性回归求解是不可行的。 此时我们可以使用Ridge回归算法来解决该问题,根据式(2.2.3)正规方程中的输入项,对训练数据进行整理,可得

代入式(2.2.3)得该Ridge回归房价数学模型为
![]()
2.2.2 算法原理
Ridge回归(岭回归)在线性回归损失函数(2.1.6)中加入一个L2正则化项来改造损失函数模型
![]()
 为正则化系数,二范数为惩罚项。 通过采用有偏估计,以舍弃一部分信息与精度为代价,从而使得函数模型更加可靠,模型与病态数据的拟合性更好。更有趣的是,相比L1范数(Lasso回归),式(2.2.1)中的L2范数正则化项是连续可微的,即可以通过函数的一阶梯度向量求得最优解
为正则化系数,二范数为惩罚项。 通过采用有偏估计,以舍弃一部分信息与精度为代价,从而使得函数模型更加可靠,模型与病态数据的拟合性更好。更有趣的是,相比L1范数(Lasso回归),式(2.2.1)中的L2范数正则化项是连续可微的,即可以通过函数的一阶梯度向量求得最优解
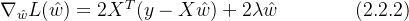
令上式 ![]() ,最优解
,最优解 ![]() 矩阵形式为
矩阵形式为
![]()
其中  为单位阵。当数据量较大时,同样也可以使用梯度下降方法求解
为单位阵。当数据量较大时,同样也可以使用梯度下降方法求解
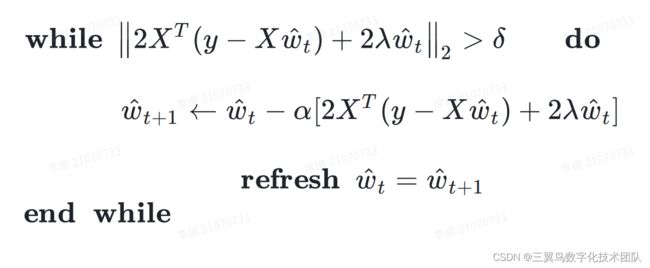
2.3 多项式回归
线性回归和Ridge回归的局限性是只能应用于存在严格线性关系的数据中,但是在实际生活中,很多数据之间是非线性关系,虽然也可以用线性回归拟合非线性回归,但是效果会变差,这时候就需要对线性回归模型进行改进,使之能够拟合非线性数据。

多项式回归研究因变量与一个或多个自变量间多项式的回归分析方法。如果自变量只有一个时,称为一元多项式回归,数学定义为 ![]() ;如果自变量有多个时,称为多元多项式回归。多项式回归相对于其他的回归分析方法有一个很大的优点,它可以依次增加多项式的次数,这样一步一步地对观测点进行逼近通过观察模拟效果和误差分析以至达到最好的效果。
;如果自变量有多个时,称为多元多项式回归。多项式回归相对于其他的回归分析方法有一个很大的优点,它可以依次增加多项式的次数,这样一步一步地对观测点进行逼近通过观察模拟效果和误差分析以至达到最好的效果。
应用场景:数据存在非线性关系
2.3.1 一元二阶多项式回归实例
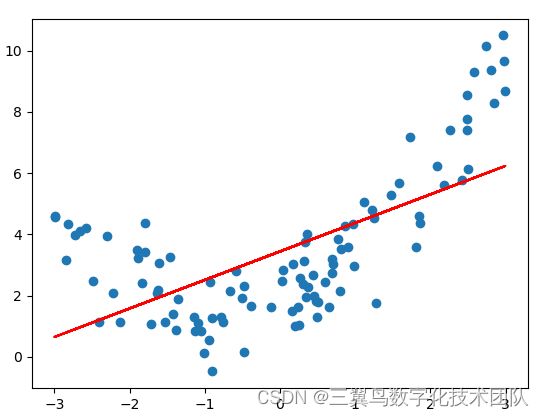
一元二阶多项式,简单说即 ![]() 。我们有一批关于房屋建筑面积和成交价格的数据集,我们需要做的是采用合适的方法拟合这些数据得到一个模型,通过该模型输入一个任意 area可以预测到 price。数据集如下表,信息包括房屋的面积 area 以及对应的成交价格 price 两个属性,由此可推断该问题是一个一元回归问题,一元回归方法包括线性回归或多项式回归,但究竟应该使用哪一种方案对房屋价格进行预测更加适合呢?
。我们有一批关于房屋建筑面积和成交价格的数据集,我们需要做的是采用合适的方法拟合这些数据得到一个模型,通过该模型输入一个任意 area可以预测到 price。数据集如下表,信息包括房屋的面积 area 以及对应的成交价格 price 两个属性,由此可推断该问题是一个一元回归问题,一元回归方法包括线性回归或多项式回归,但究竟应该使用哪一种方案对房屋价格进行预测更加适合呢?
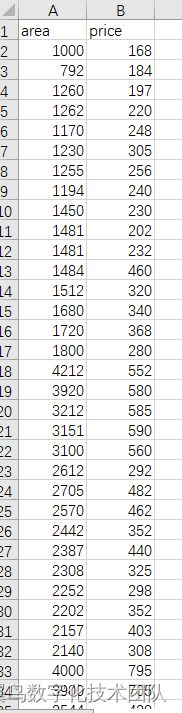
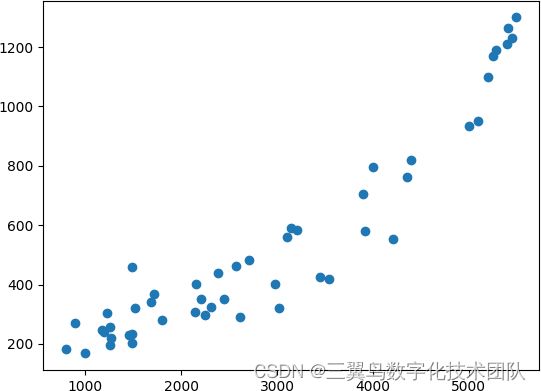
(1)首先,我们可以根据数据散点图的特点观察判断数据是线性或非线性,再选择最佳的回归方法。画出上表中数据散点分布图如下图所示,可以看出该图具有抛物线特征,故我们选取一元二次多项式拟合方法,即
![]()
其中 代表房屋面积, 为价格, 是待学习参数。从本质上看,本例中多项式回归将原本只有一个特征维度的数据集拓展成一个二维度数据集, 和
是待学习参数。从本质上看,本例中多项式回归将原本只有一个特征维度的数据集拓展成一个二维度数据集, 和  ,具有升维作用。
,具有升维作用。
(2)数据预处理,数据分割

(3)建立一元二次多项式,使用线性回归模型对参数进行训练

(4)结果显示
所求二次多项式回归方程为
![]()


2.3.2 算法原理
A. 一元多项式回归
在一元回归分析中,如果数据 ![]() 的关系为非线性的,此时使用线性回归找不到理想的线性函数对曲线进行拟合,可以采用一元多项式回归,一元 阶多项式回归方程如下
的关系为非线性的,此时使用线性回归找不到理想的线性函数对曲线进行拟合,可以采用一元多项式回归,一元 阶多项式回归方程如下
![]()
通过变量转换办法,令 ![]() ,此时可以将式(2.3.1)变形得到一个 元线性回归方程
,此时可以将式(2.3.1)变形得到一个 元线性回归方程
![]()
写成矩阵表达形式为

由2.1部分数学推导可知线性回归正规方程解为
![]()
其中
所求一元 阶多项式回归方程为
B. 多元多项式回归
当一个非线性数据集包含两个及两个以上特征变量时,该问题变成多元多项式回归问题。我们以简单的二元二阶多项式为例,考虑训练数据集 ![]() ,其中
,其中![]() ,
,![]() ,其回归方程定义如下
,其回归方程定义如下
![]()
同理,式(2.3.6)可变换为多元线性回归模型
![]()
其中 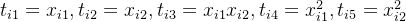 。
。
因此可知其最优解为
![]()
其中
该二元二阶多项式回归方程向量内积形式为
虽然多项式回归使用可能达到比线性回归更好的效果,但需要注意过拟合效应。
小结
| 假设形式 |
损失函数 |
适用场景 |
|
| 线性回归 |
|
|
线性数据,特征数小于数据容量 |
| Ridge回归 |
|
|
线性数据,数据特征数量大,需要压缩,数据存在多重线性关系 |
| 多项式回归 |
|
|
非线性数据 |