yolov5障碍物识别-雪糕筒识别(代码+教程)
简介
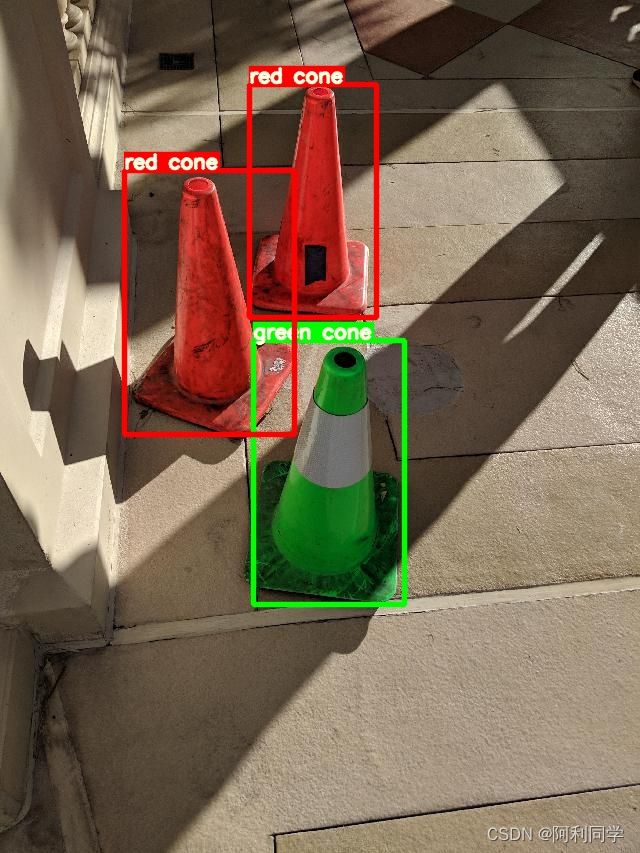
这是一个检测交通锥并识别颜色的项目。我使用 yolov5 来训练和检测视锥细胞。此外,我使用 k 均值来确定主色,以对锥体颜色进行分类。目前,支持的颜色为红色、黄色、绿色和蓝色。其他颜色被归类为未知。

数据集和注释
我使用了一个自收集的锥体数据集,其中包含 303 张锥体图像。这不是一个完美的做法,因为它是一个很小的数据集。我还需要自己注释图像。在这里,我使用了一个在线注释网站 Roboflow,它提供注释、预处理和增强等服务。但是,它对免费用户有 1,000 个源图像和 5,000 个生成图像的限制。
model
├── 锥体检测:Yolov5S
└── 颜色识别:主色(k-means)
用法
如果您有兴趣,可以尝试 colab 中的代码。

训练
# display images
from PIL import Image
import glob
for imageName in glob.glob('/content/yolov5/images/*.jpg'):
basewidth = 640
img = Image.open(imageName)
wpercent = (basewidth/float(img.size[0]))
hsize = int((float(img.size[1])*float(wpercent)))
img = img.resize((basewidth,hsize), Image.NEAREST)
img = img.convert("RGB")
img.save(imageName)
-
如果您有带注释的数据集,则可以直接使用 train.ipynb 在 Colab 中打开项目。
-
使用 Colab 进行训练和预测: Colab 是一个基于云的 Jupyter 笔记本服务,能够在云端运行代码。通过提供的 Colab
链接,你可以直接在浏览器中打开并运行代码,这对于快速尝试和理解项目非常方便。
-
项目中的注意事项: 数据集大小: 作者使用了一个包含 303
张图像的自定义数据集,但指出这并不是一个理想的实践,因为数据集规模较小。在实际应用中,使用更大规模的数据集通常会有助于提高模型的性能。 -
在线标注服务: 使用 Roboflow
进行图像标注,该服务提供了标注、预处理和增强等功能。然而,对于免费用户,有一些使用限制,包括最大处理图像数量和生成图像数量。
%%writetemplate /content/yolov5/models/custom_yolov5s.yaml
# parameters
nc: {num_classes} # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
-
颜色分类: 采用 k-means 算法确定主导颜色,并将交通锥分为红、黄、绿和蓝等颜色。其他颜色被分类为未知。

-
推荐的下一步: 如果你对该项目感兴趣,可以进一步探索以下方面:
-
数据增强: 在数据集上应用更多的数据增强技术,以提高模型的泛化能力。
-
模型调优: 尝试使用更大的 YOLOv5 模型(例如 yolov5m、yolov5l 或
yolov5x)进行训练,看看是否能够改善检测性能。 -
更大的数据集: 如果可能的话,考虑收集更大规模的数据集,以进一步提高模型的准确性。

视频预测
预测:
使用 predict.ipynb 进行锥体检测。 在 pycharm 中打开
# use the best weights!
%cd /content/yolov5/
!python detect.py --weights weights/best.pt --conf 0.6 --source videos/cone_video.mp4
注意:需要使用作者在 model 文件夹中训练的权重,并且有一些自定义的 YOLOv5 文件在 utils 文件夹中。
