GoDance分布式搜索引擎项目
目录
-
- 前言
- 一、布尔模型
- 二、 实用评分函数
-
- 1. 查询归一化因子
- 2. 协调因子
- 3. TF-IDF
-
- 3.1 TF
- 3.2 IDF
- 3.3 字段长度归一值BOOST
- 4. 向量空间模型
-
-
- 具体方案
-
- 三、按受欢迎度提升权重
- 四、实时搜索与相关搜索
- 五、具体实现方案
-
- 1. 布尔模型
- 2. 评分函数
- 3. 实时相关搜索
前言
5月6日参加了字节跳动青训营,做的一个GoDance分布式搜索引擎项目,到今天5月7日该交大项目了。从刚开始不知道从哪里入手到后面一直开会一直看资料才基本完成了这个项目,所以总结了一下自己负责的相关度搜索算法模块。
资料:控制相关度 | Elasticsearch: 权威指南 | Elastic
Lucene 实用评分函数:
Lucene(或 Elasticsearch)使用 布尔模型(Boolean model) 查找匹配文档,并用一个名为 实用评分函数(practical scoring function) 的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率(term frequency/inverse document frequency) 和 向量空间模型(vector space model),同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
一、布尔模型
not > and > or
在查询中使用 AND 、 OR 和 NOT (与、或和非)这样的条件来查找匹配的文档
full AND text AND search AND (elasticsearch OR lucene)
会将所有包括词 full 、 text 和 search ,以及 elasticsearch 或 lucene 的文档作为结果集。
二、 实用评分函数
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
score(q,d)是文档d与查询q的相关度评分.queryNorm(q)是 查询归一化 因子 (新)。coord(q,d)是 协调 因子 (新)。- 查询
q中每个词t对于文档d的权重和。 tf(t in d)是词t在文档d中的 词频 。idf(t)是词t的 逆向文档频率 。t.getBoost()是查询中使用的 boost(新),查询时权重提升。norm(t,d)是 字段长度归一值 ,与 索引时字段层 boost (如果存在)的和(新)。
1. 查询归一化因子
查询归一因子 ( queryNorm )试图将查询 归一化 ,这样就能将两个不同的查询结果相比较。
这个因子是在查询过程的最前面计算的,具体的计算依赖于具体查询,一个典型的实现如下:
queryNorm = 1 / √sumOfSquaredWeights
sumOfSquaredWeights 是查询里每个词的 IDF 的平方和。
相同查询归一化因子会被应用到每个文档,不能被更改,总而言之,可以被忽略。
尽管查询归一值的目的是为了使查询结果之间能够相互比较,但是它并不十分有效,因为相关度评分
_score的目的是为了将当前查询的结果进行排序,比较不同查询结果的相关度评分没有太大意义
2. 协调因子
协调因子 coord )可以为那些查询词包含度高的文档提供奖励,文档里出现的查询词越多,它越有机会成为好的匹配结果。
设想查询 quick brown fox ,每个词的权重都是 1.5 。如果没有协调因子,最终评分会是文档里所有词权重的总和。例如:
- 文档里有
fox→ 评分: 1.5 - 文档里有
quick fox→ 评分: 3.0 - 文档里有
quick brown fox→ 评分: 4.5
协调因子将评分与文档里匹配词的数量相乘,然后除以查询里所有词的数量,如果使用协调因子,评分会变成:
- 文档里有
fox→ 评分:1.5 * 1 / 3= 0.5 - 文档里有
quick fox→ 评分:3.0 * 2 / 3= 2.0 - 文档里有
quick brown fox→ 评分:4.5 * 3 / 3= 4.5
协调因子能使包含所有三个词的文档比只包含两个词的文档评分要高出很多。
禁用: 暂不考虑这个功能
在某些高级应用中,将协调功能关闭可能更好。设想正在查找同义词 jump 、 leap 和 hop 时,并不关心会出现多少个同义词,因为它们都表示相同的意思,实际上,只有其中一个同义词会出现。
这种情况下同义词出现一个与出现三个同义词应当没有差别
当使用同义词的时候(参照: 同义词 ),Lucene 内部是这样的:重写的查询会禁用同义词的协调功能。大多数禁用操作的应用场景是自动处理的,无须为此担心。
同义词 :用户搜索 “美国” 并且期望找到包含 美利坚合众国 、 美国 、 美洲 、或者 美国各州 的文档。 然而,他们不希望搜索到关于
国事或者政府机构的结果。同义词相关不应该包含在搜索这部分,应当在分词时处理完全
3. TF-IDF
3.1 TF
词在文档中出现的频度是多少?频度越高,权重 越高 。 5 次提到同一词的字段比只提到 1 次的更相关。词频的计算方式如下:
tf(t in d) = frequency / sum
frequency : 词t在文档d中出现的次数
sum : 文档d总词数
词 t 在文档 d 的词频( tf )是该词在文档中出现次数除以总词个数。
3.2 IDF
词在集合所有文档里出现的频率是多少?频次越高,权重 越低
idf(t) = log ( numDocs / (docFreq + 1))
numDocs : 文档总数
docFreq : 词t在几个文档中出现
词 t 的逆向文档频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。
3.3 字段长度归一值BOOST
title应该比content更重要,TITLEBOOST = 2 ,title是content的 TITLEBOOST倍。
在求title与content权重和的时候进行运算
4. 向量空间模型
向量空间模型(vector space model) 提供一种比较多词查询的方式,单个评分代表文档与查询的匹配程度,为了做到这点,这个模型将文档和查询都以 向量(vectors) 的形式表示:
向量实际上就是包含多个数的一维数组,例如:
[1,2,5,22,3,8]
设想如果查询 “happy hippopotamus” ,常见词 happy 的权重较低,不常见词 hippopotamus 权重较高,假设 happy 的权重是 2 , hippopotamus 的权重是 5 ,可以将这个二维向量—— [2,5] ——在坐标系下作条直线,线的起点是 (0,0) 终点是 (2,5) 。
Figure 27. 表示 “happy hippopotamus” 的二维查询向量
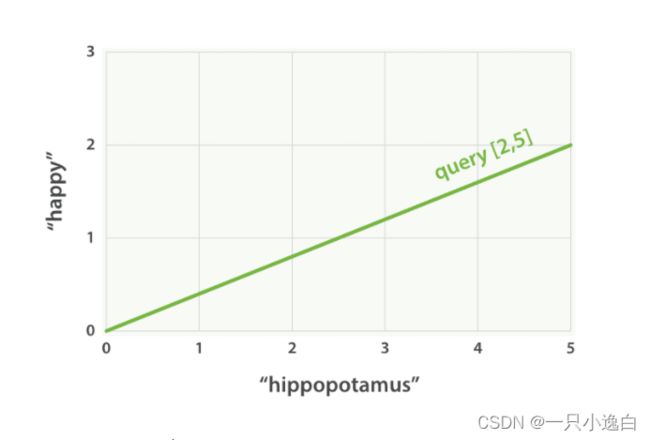
现在,设想我们有三个文档:
- I am happy in summer 。
- After Christmas I’m a hippopotamus 。
- The happy hippopotamus helped Harry 。
可以为每个文档都创建包括每个查询词—— happy 和 hippopotamus ——权重的向量,然后将这些向量置入同一个坐标系中:
- 文档 1:
(happy,____________)——[2,0] - 文档 2:
( ___ ,hippopotamus)——[0,5] - 文档 3:
(happy,hippopotamus)——[2,5]
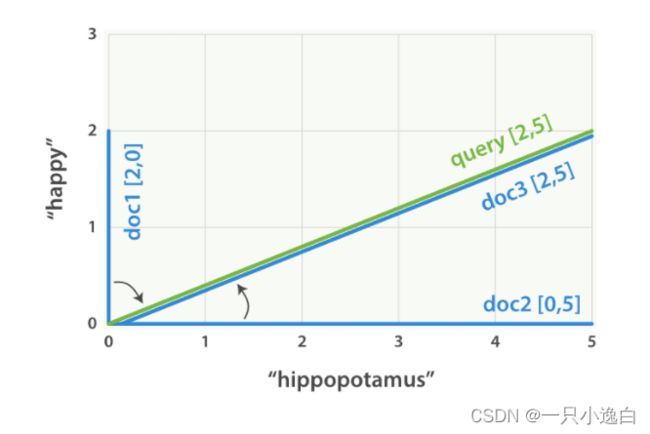
根据夹角的余弦值:文档3 > 文档2 > 文档1
具体方案
Cosine(a []float64, b []float64)
这个余弦函数可以计算两组一维数组的余弦值- 只需要计算每一个文档中文档的权重,将其带入与关键词的向量值进行余弦值比较(余弦值越大夹角越小),从大到小排序
三、按受欢迎度提升权重
资料:https://www.elastic.co/guide/cn/elasticsearch/guide/current/boosting-by-popularity.html
资料是从点赞方面考虑的,而为了搜索引擎的使用范围考虑,我们考虑他的浏览量。
与使用乘积的方式相比,使用评分 _score 与函数值求和的方式可以弱化最终效果,特别是使用一个较小 factor 因子时
new_score = old_score + log(1 + 0.1 * number_of_votes)
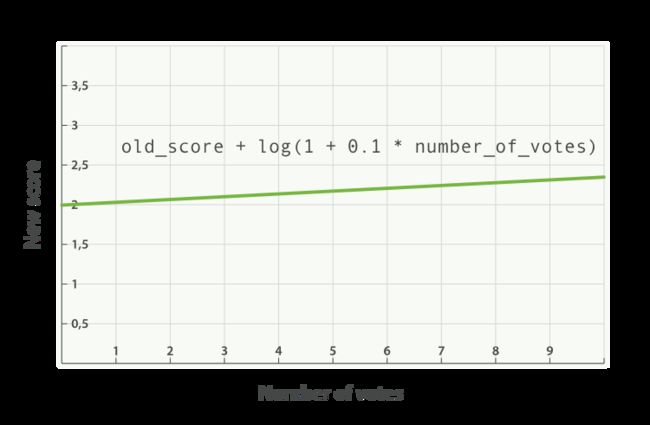
number_of_votes : 浏览量
参数0.1是根据点赞数得出的,因为浏览量比点赞数大得多,后面可以测试修改出合适的值
四、实时搜索与相关搜索
输入框的词不用进行分词处理,直接使用即可
-
存储:创建字典树存储搜索的关键词。
-
查询:根据关键词从头搜索字典树,没有更多的词或者词数大于最大词数50(官方推荐)时结束,边搜索边加入小顶堆(个数为10)。
取出小顶堆的10个词按照大到小数组形式返回结果。
-
添加:搜索结束后将搜索词加入到字典树中,字典树会根据用户的搜索行为逐渐增加
实现方案:
-
实时搜索 : 输入搜索条件就会自动补全用户想要的内容,当用户多输入一个字符时就得重新查询,所以查询速度要快。
- 用户输入搜索词后进行实时查询,直接将结果返回,结果集 <= 10
-
相关搜索: 搜索后显示相关的内容在页面最下方,跟实时搜索一样的步骤,但只需要查询一次。
- 用户点击搜索按钮后进行相关查询,如果结果集 <= 10,就将搜索词进行分词,对这些分词分别进行查询添加到结果集中
五、具体实现方案
1. 布尔模型
接口函数:
func DocMergeFilter(docQueryNodes []utils.DocIdNode, docFilterIds []uint64, notDocQueryNodes []utils.DocIdNode) []uint64
作用:合并去重搜索词和范围查询的文档id,过滤掉过滤词的文档id。
-
将搜索词与范围查询词的文档id集合通过升序合并函数merge进行合并.
-
func merge(nums1 []uint64, nums2 []uint64) []uint64 //升序合并函数 -
通过map记录需要过滤的文档id(方便快速查找)
-
NOT:遍历合并后的文档id,如果id在map中存在就删除。
2. 评分函数
接口需要参数:(map[string]int,关键词分词文档, 标题分词单词文档, 内容分词单词文档, 浏览量)
-
TF-IDF
- TF() : 在创建索引时计算每一个单词的词频
- IDF() : 计算每一个单词的逆文件频率
- TwoWeightSum : 计算标题或者摘要与内容的单词权重和,BOOST控制倍数
-
Vector
- VectorCosine() : 计算两组向量余弦值
- VectorPosition() : 获取所有文档向量
- KeyVectorPosition() : 获取关键词的向量
- DocVectorWeight() : 获取所有文档的向量余弦值
-
Coord
- CoordAndVectorWeight(): 计算协调因子与向量权重的乘积
步骤:
-
遍历搜索词集
searchQueries,通过SearchKeyDocIds()方法查询倒排,因为在布尔模型过滤的时候没有修改倒排里的文档,所以此时倒排文档ids有可能包含过滤词文档,在这时候得先过滤掉过滤词文档。 -
idf : 倒排查出的ids长度就是这个单词出现的文档个数
idf := math.Log(docNum / float64(len(ids)+1)) -
遍历ids计算每一个文档单词的TFIDF
-
空间向量模型vector :
- 所有文档向量vectorAllDoc:是一个
map[uint64][]float64的类似二维数组结构,计算完TFIDF后直接添加进去 - 搜索词文档向量vectorKey : 是一个
[]float64,每一个单词权重都取这个单词在所有文档中TFIDF的最大值 - 然后通过weight.DocVectorWeight()方法算两个向量余弦值
- 所有文档向量vectorAllDoc:是一个
-
协调因子coord: 该文档中出现的搜索词数 / 总搜索词数
- 计算coord后将每一篇文档的coord与文档向量权重docVectorWeight相乘得到文档的权重,然后按照权重从大到小排序
3. 实时相关搜索
- trie:
- Insert() : 用于向字典树添加搜索词语
- Search() : 在字典树中查询搜索词语相关的词语返回
- 如果参数BOOT = true代表实时搜索,返回<=10条数据
- 如果参数BOOT = true代表相关搜索,返回10条数据,不够时用words补全
- heap:
- 小顶堆:根据词语频次大小进行排序,相等就根据词语长短进行排序,总的就是越小越长越靠近堆顶,堆大小为10,超过就弹出堆顶,保证剩下的都是频次越长单词越短的数据
- 服务于trie的一个中间容器
- queue:
- 用数组实现队列,在trie/Search()方法中使用到广搜时使用
- 结构体中除了存 []*Trie节点,还存了 [] []rune,用于存储这个节点的整体词语
- Add(): 在添加过程中除了添加Trie节点,还要添加rune的一个节点单词数据,用于记录整个词语
- Remove() : 弹出队列头:(*Trie, []rune)