《sql学习指南》笔记1-10章
文章目录
- 简单概述
- 几个简单的sql例子
- 2. 创建和填充数据库
-
- 2.1 使用命令行工具myql
-
- 2.1.1 登录数据库
- 2.1.2 查看所有可用的数据库
- 2.1.3 使用指定的数据库
- 2.1.4 查询当前日期和时间
- 2.1.5 退出
- 2.2 MySQL数据类型
-
- 2.2.1 字符型数据
- 2.2.2 字符集
- 2.2.3 文本数据
- 2.2.4 数值型数据
- 2.2.5 时间型数据
- 2.3 构建SQL模式语句
-
- 2.3.1 查看数据库中所有的表格
- 2.3.2 数据表的约束类型
- 2.3.3 查看表定义
- 2.3.4 设置是否允许null
- 2.4 填充和修改数据表
-
- 2.4.1 主键自增
- 2.4.2 insert语句
- 2.4.3 更新数据
- 2.4.4 删除数据
- 2.4.5 删除数据库表
- 2.5 常见错误及响应
-
- 2.5.1 非唯一的主键
- 2.5.2 不存在的外键
- 2.5.3 列值违规
- 2.5.4 无效的日期转换
- 2.6 Sakila数据库
- 3. 查询入门
-
- 3.1 查询子句
- 3.2 select子句
-
- 3.2.1 列的别名
- 3.2.2 移除重复数据
- 3.3 from子句
-
- 3.3.1 数据表
- 3.3.2 数据表链接
- 3.3.3 定义数据表别名
- 3.4 where子句
- 3.5 group by和having子句
- 3.6 order by子句
-
- 3.6.1 升序排序和降序排序
- 3.6.2 通过数字占位符进行排序
- 4. 过滤
-
- 4.1 条件评估
-
- 4.1.1 使用括号
- 4.1.2 使用not运算符
- 4.2 构建条件
- 4.3 条件类型
-
- 4.3.1 相等条件
- 4.3.2 范围条件
- 4.3.3 成员条件
- 4.3.4 匹配条件
- 4.4 null:4个字母的单词
- 5. 多数据表查询
-
-
- 5.1.1 笛卡儿积
- 5.1.2 内连接
- 5.1.3 ANSI连接语法
- 5.2 连接3个或以上的数据表
-
- 5.2.1 使用子查询作为数据表
- 5.2.2 使用同一数据表两次
- 5.3 自连接
-
- 6.使用集合
-
- 6.1集合论入门
- 6.2 集合论实践
- 6.3集合运算符
-
-
- 6.3.1 union运算符
- 6.3.2 intersect运算符
- 6.3.3 except运算符
- 6.4.1 对符合查询结果排序
- 6.4.2 集合运算的优先级
-
- 7. 数据生成、操作和转换
-
- 7.1 处理字符串数据
-
- 7.1.1 生成字符串
-
- 1.包含单引号
- 2.包含特殊字符
- 7.1.2 操作字符串
-
- 1.返回数值的字符串函数
- 2.返回字符串的字符串函数
- 7.2 处理数值型数据
-
- 7.2.1 执行算术函数
- 7.2.2 控制数值精度
- 7.2.3 使用有符号数
- 7.3 处理时间型数据
-
- 7.3.1 处理时区
- 7.3.2 生成时间型数据
-
- 1.时间型数据的字符串表示
- 3.日期生成函数
- 7.3.3 操作时间型数据
-
- 1.返回日期的时间型函数
- 2.返回字符串的时间型函数
- 3.返回数值的时间型函数
- 7.4 转换函数
- 8. 分组和聚合
-
- 8.1 分组的概念
- 8.2 聚合函数
-
- 8.2.1 隐式分组与显式分组
- 8.2.2 统计不同的值
- 8.2.3 使用表达式
- 8.2.4 处理null
- 8.3 生成分组
-
- 8.3.1 单列分组
- 8.3.2 多列分组
- 8.3.3 通过表达式分组
- 8.3.4 生成汇总
- 8.4 分组过滤条件
- 9.子查询
-
- 9.1 什么是子查询
- 9.2 子查询类型
- 9.3 非关联子查询
-
- 9.3.1 多行单列子查询
-
- 1.in和not in运算符
- 2.all运算符
- 3.any运算符
- 9.3.2 多列子查询
- 9.4 关联子查询
-
- 9.4.1 exists运算符
- 9.4.2 使用关联子查询操作数据
- 9.5 何时使用子查询
-
- 9.5.1 子查询作为数据源
-
- 1.数据加工
- 2.面向任务的子查询
- 3.公用表表达式
- 9.5.2 子查询作为表达式生成器
- 9.6 子查询小结
- 10. 再谈连接
-
- 10.1 外连接
-
- 10.1.1 左外连接与右外连接
- 10.1.2 三路外连接
- 10.2 交叉连接
- 10.3 自然连接
简单概述
商业化的关系型数据库已经有30多年的历史了。其中一些比较成熟且流行的商业产品包括:
- Oracle公司的Oracle Database;
- Microsoft公司的SQL Server;
- IBM公司的DB2 Universal Database。
这些数据库服务器的功能都差不多,尽管其中有些长于处理海量或超大吞吐量的数据库,而有些更适合处理对象、大文件或XML文档等。所有这些服务器都很好地遵从了最新的ANSI SQL标准。这是一件好事,本书将展示如何编写无须进行任何修改(或仅需要极少量的修改)就能够在这些平台上运行的SQL语句。
除了商业数据库服务器,开源社区以创建出能够与之抗衡的竞品为目标,在过去的20年中也开展了大量的活动,其中最常用的两个开源数据库服务器是PostgreSQL和MySQL。MySQL是免费的,其下载和安装过程都非常简单。因此,本书的所有示例均在MySQL(8.0版)上运行,并使用命令行工具格式化查询结果。即使你已经使用了其他数据库服务器,而且根本不打算使用MySQL,我也强烈建议你安装最新版的MySQL服务器,加载样本模式和数据,用本书中的数据和示例进行实验。
然而,请牢记以下注意事项:
本书并不是一本关于MySQL如何实现SQL的书。
确切地说,本书旨在教授编写不加修改或稍作修改就能运行在MySQL以及Oracle Database、DB2、SQL Server新近版本上的SQL语句。
几个简单的sql例子
几个简单的增删改查sql例子
创建表
create table 表名
(列名 列类型,列名 列类型....
constraint 主键约束名 primary key 主键名)
例子
CREATE TABLE corporation
(corp_id SMALLINT,
name VARCHAR(30),
CONSTRAINT pk_corporation PRIMARY KEY (corp_id)
);
向表中插入数据
insert into 表名 (列名,列名....)
values (列值,列值...)
例子
INSERT INTO corporation (corp_id, name)
VALUES (27, 'Acme Paper Corporation');
查询表中的数据
select 列名,...
from 表名
where 条件语句
例子
SELECT name
FROM corporation
WHERE corp_id = 27;
+------------------------+
| name |
+------------------------+
| Acme Paper Corporation |
+------------------------+
多表查询 内联语句 inner join
多表查询用到了起别名的方式,让查询语句更清晰
select 表别名1.列名 .....
from 表名1 别名1
inner join 表名2 别名2 on 条件语句(别名1.列名 = 别名2.列名)
inner join 表名3 别名3 on 条件语句(别名3.列名 = 别名2.列名)
inner join 表名4 别名4 on 条件语句(别名4.列名 = 别名2.列名)
where 条件语句(别名1.列名 = 值 ) and 条件语句(别名1.列名 = 值)
and 条件语句(别名3.列名 = 值)
例子
SELECT t.txn_id, t.txn_type_cd, t.txn_date, t.amount
FROM individual i
INNER JOIN account a ON i.cust_id = a.cust_id
INNER JOIN product p ON p.product_cd = a.product_cd
INNER JOIN transaction t ON t.account_id = a.account_id
WHERE i.fname = 'George' AND i.lname = 'Blake'
AND p.name = 'checking account';
+--------+-------------+---------------------+--------+
| txn_id | txn_type_cd | txn_date | amount |
+--------+-------------+---------------------+--------+
| 11 | DBT | 2008-01-05 00:00:00 | 100.00 |
+--------+-------------+---------------------+--------+
1 row in set (0.00 sec)
sql中的注释
大多数SQL实现将位于“/”和“/”之间的文本视为注释
SELECT /* 一个或多个东西 */ ...
FROM /* 一处或多处 */ ...
WHERE /* 一个或多个条件 */ ...
修改表数据
update 表名
set 列名 = '修改的值'
where 条件语句
例子
UPDATE product
SET name = 'Certificate of Deposit'
WHERE product_cd = 'CD';
delete 语句忘记加where子句,会把整个数据表的行全部清空
2. 创建和填充数据库
2.1 使用命令行工具myql
2.1.1 登录数据库
mysql -u root -p 密码
2.1.2 查看所有可用的数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
+--------------------+
5 rows in set (0.01 sec)
2.1.3 使用指定的数据库
mysql> use sakila;
Database changed
启动命令行工具mysql的时候,可以同时指定要使用的用户名和数据库
mysql -u root -p sakila;
2.1.4 查询当前日期和时间
mysql> SELECT now();
+---------------------+
| now() |
+---------------------+
| 2019-04-04 20:44:26 |
+---------------------+
1 row in set (0.01 sec)
oracle中需要添加一个from子句,mysql中可加可不加
mysql> SELECT now()
FROM dual;
+---------------------+
| now() |
+---------------------+
| 2019-04-04 20:44:26 |
+---------------------+
1 row in set (0.01 sec)
2.1.5 退出
quit;
或
exit;
2.2 MySQL数据类型
2.2.1 字符型数据
在定义字符型的列时,必须指定该列所能存储字符串的最大长度。例如,如果希望存储最大长度为20个字符的字符串,可以使用下面的定义方式:
char(20) /* 定长 */
varchar(20) /* 变长 */`
char允许的最大长度为255字节,varchar最大长度则为65,535字节。如果需要存储更长的字符串(比如电子邮件、XML文档等),则要使用某种文本类型(mediumtex和longtext)。
2.2.2 字符集
查看数据库服务器所支持的字符集:
SHOW CHARACTER SET;
结果:


如果第4列maxlen的值大于1,则该字符集为多字节字符集。
在之前版本的MySQL服务器中,默认字符集是latin1,但在版本8中改为了utf8mb4。你可以为数据库中每个字符型的列选择不同的字符集,甚至可以在同一个数据表内存储不同的字符集数据。如果为数据列指定非默认字符集,只需要在类型定义后加上系统支持的字符集名称,例如:
varchar(20) character set latin1
在MySQL中,还可以设置整个数据库的默认字符集:
create database european_sales character set latin1;
2.2.3 文本数据
MySQL文本类型及其最大长度
| 文本类型 | 最大长度/字节 |
|---|---|
| tinytext | 255 |
| txt | 65535 |
| mediumtext | 16777215 |
| longtext | 4294 967 295 |
2.2.4 数值型数据
MySQL的整数类型
| 类型 | signed的取值范围 | unsigned的取值范围 |
|---|---|---|
| tinyint | -128~127 | 0-255 |
| smallint | -32768 ~ 32768 | 0 ~ 65535 |
| mediumint | -8388608 ~ 8388607 | 0 ~ 16777215 |
| int | -2147 483 648 ~ 2147 483 647 | 0 ~ 4294 967 295 |
| bigint | -2^63 ~ 2^63-1 | 0 ~ 2^64-1 |
MySQL的浮点数类型
| 类型 | 取值范围 |
|---|---|
| float(p,s) | -3.402823466E+38 ~ -1.175494351E-38 和1.175494351E-38 ~ 3.402823466E+38 |
| double(p,s) | -1.7976931348623157E+308~ -2.2250738585072014E-38和2.2250738585072014E-38~1.7976931348623157E+308 |
2.2.5 时间型数据
MySQL的时间数据类型
| 类型 | 默认格式 | 取值范围 |
|---|---|---|
| date | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 |
| datetime | YYYY-MM-DD HH:mm:ss | 1000-01-01 00:00:00.000000~9999-12-31 23:59:59.999999 |
| timestamp | YYYY-MM-DD HH:mm:ss | 1970-01-01 00:00:00.000000~2038-01-18 22:14:07.999999 |
| year | YYYY | 1901~2155 |
| time | HHH:mm:ss | -838:59:59.000000 ~ 838:59:59.999999 |
每种数据库服务器所允许的时间类型列的日期范围各不相同。Oracle Datebase接受的日期范围是公元前4712年至公元9999年,SQL Server则只能处理公元1753年至公元9999年(除非使用SQL Server 2008的datetime2数据类型,其日期范围从公元1年至公元9999年)。MySQL位于Oracle和SQL Server之间,其时间范围是公元1000年至公元9999年。对于大多数跟踪当前和未来事件的系统来说,这并没有什么不同,但是如果存储的是历史日期,就需要注意了。
当行被添加到数据表或被修改时,MySQL服务器会自动为timestamp类型的列填充当前的日期/时间。
2.3 构建SQL模式语句
现在创建一个数据库表
CREATE TABLE person
(person_id SMALLINT UNSIGNED,
fname VARCHAR(20),
lname VARCHAR(20),
eye_color CHAR(2),
birth_date DATE,
street VARCHAR(30),
city VARCHAR(20),
state VARCHAR(20),
country VARCHAR(20),
postal_code VARCHAR(20),
CONSTRAINT pk_person PRIMARY KEY (person_id)
);
2.3.1 查看数据库中所有的表格
show tables;
2.3.2 数据表的约束类型
- 主键约束(primary key constraint)
- 外键约束(foreign key constraint)
- 检查约束(check)
MySQL允许在定义列时关联检查约束,如下所示:
eye_color CHAR(2) CHECK (eye_color IN ('BR','BL','GR')),
检查约束在大多数数据库服务器中都能够如所期望的那样工作,然而,MySQL虽然允许定义检查约束,但并不强制使用。实际上,MySQL提供了另一种名为enum的字符数据类型,将检查约束并入了数据类型定义:
eye_color ENUM('BR','BL','GR'),
下面是person数据表的定义,其中包含数据类型为enum的eye_color列:
CREATE TABLE person
(person_id SMALLINT UNSIGNED,
fname VARCHAR(20),
lname VARCHAR(20),
eye_color ENUM('BR','BL','GR'),
birth_date DATE,
street VARCHAR(30),
city VARCHAR(20),
state VARCHAR(20),
country VARCHAR(20),
postal_code VARCHAR(20),
CONSTRAINT pk_person PRIMARY KEY (person_id)
);
2.3.3 查看表定义
使用 describe 或 desc简写,查看表定义。
describe person;
或
desc person;
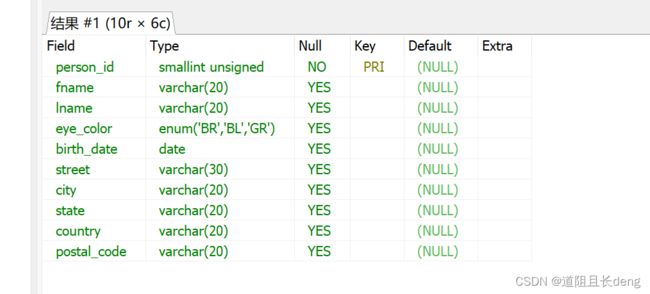
2.3.4 设置是否允许null
在创建数据表时,可以指定哪些列允许为null(默认),哪些列不允许为null(在类型定义后添加关键字not null)
创建favorite_food数据表
CREATE TABLE favorite_food(
person_id SMALLINT UNSIGNED,
food VARCHAR(20),
CONSTRAINT pk_favorite_food PRIMARY KEY (person_id,food),
CONSTRAINT fk_fav_food_person_id FOREIGN KEY (person_id) REFERENCES person(person_id)
);
- 由于一个人可能有多种喜爱的食物(这也是创建本表的首要原因),仅靠person_id列不能保证数据的唯一性,因此本表的主键包含两列:person_id和food。
- favorite_food数据表包含了另一种约束,即外键约束(foreign key constraint),它限制了favorite_food数据表中person_id列的值只能够来自person数据表。通过这种约束,当person数据表中没有person_id为27的记录时,不可以向favorite_food数据表中添加person_id为27、喜爱食物为比萨饼的数据行。
如果一开始创建数据表的时候忘了设置外键约束,随后可以通过alter table语句添加。
2.4 填充和修改数据表
2.4.1 主键自增
在MySQL中,只需简单地为主键列启用自增(auto-increment)特性。通常来说,应该在创建数据表时就完成此项工作,不过这也给了我们一个机会来学习另一个SQL模式语句:alter table。该语句用于修改已有的数据表定义:
ALTER TABLE person MODIFY person_id SMALLINT UNSIGNED AUTO_INCREMENT;
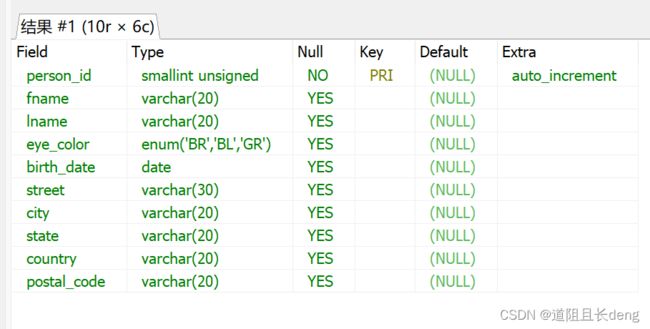
2.4.2 insert语句
添加person表
INSERT INTO person(
fname,lname,eye_color,birth_date
)
VALUES('william','turner','br','1972-05-27');
INSERT INTO person(
fname,lname,eye_color,birth_date,street,city,state,country,postal_code
) VALUES('susan','smith','BL','1975-11-02','23 maple st.','arlington','VA','USA','20020')
添加食物表
INSERT INTO favorite_food(person_id,food) VALUES(1,'pizza');
INSERT INTO favorite_food(person_id,food) VALUES(1,'cookies');
INSERT INTO favorite_food(person_id,food) VALUES(1,'nochos');
检索william喜爱的食物,并使用order by子句将食物按字母顺序排序
SELECT food FROM favorite_food WHERE person_id=1 ORDER BY food;
可以获取xml格式的数据吗
对于MySQL,可以在调用mysql工具时使用–xml选项,所有查询的输出都会自动转换成XML格式。
C:\database> mysql -u lrngsql -p --xml bank
Enter password: xxxxxx
Welcome to the MySQL Monitor...
Mysql> SELECT * FROM favorite_food;
1
cookies
1
nachos
1
pizza
3 rows in set (0.00 sec)
对于SQL Server,则无须配置命令行工具,只需要在查询末尾添加for xml子句:
SELECT * FROM favorite_food FOR XML AUTO, ELEMENTS
2.4.3 更新数据
通过update语句填充相关的列
UPDATE person
SET street = '1225 tremont st.',
city = 'Boston',
state = 'MA',
country = 'USA',
postal_code = '0138'
WHERE person_id = 1
根据where子句中给出的条件,也可以使用单个语句修改多行。
WHERE person_id < 10
如果省略where子句,update语句会修改数据表中的每一行。
2.4.4 删除数据
DELETE FROM person WHERE person_id=2;
可以根据where子句中给出的条件删除多行,如果忽略where子句,则会删除所有行。
2.4.5 删除数据库表
DROP TABLE 表名
2.5 常见错误及响应
2.5.1 非唯一的主键
主键必须是唯一的,如果在数据库中插入重复的主键会报错,下列语句忽略了person_id列的自增特性,将person数据表中另一行的person_id值设为1:
mysql> INSERT INTO person
-> (person_id, fname, lname, eye_color, birth_date)
-> VALUES (1, 'Charles','Fulton', 'GR', '1968-01-15');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
2.5.2 不存在的外键
favorite_food数据表定义包括在person_id列上创建的外键约束。该约束确保favorite_food数据表中person_id列的所有值都来自person数据表。下面展示了如果在创建行时违反这一约束的结果:
mysql> INSERT INTO favorite_food (person_id, food)
-> VALUES (999, 'lasagna');
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraintfails ('sakila'.'favorite_food', CONSTRAINT 'fk_fav_food_person_id' FOREIGNKEY('person_id') REFERENCES 'person' ('person_id'))
仅当使用InnoDB存储引擎创建数据表时,外键约束才是强制的。我们会在第12章讨论MySQL的存储引擎。
2.5.3 列值违规
person数据表中的eye_color列将取值限制为’BR’(棕色)、‘BL’(蓝色)、‘GR’(绿色)。如果你试图错误地对该列设置其他值,会得到如下响应:
mysql> UPDATE person
-> SET eye_color = 'ZZ'
-> WHERE person_id = 1;
ERROR 1265 (01000): Data truncated for column 'eye_color' at row 1
2.5.4 无效的日期转换
如果用于填充日期类型列的字符串不符合要求的格式,会产生错误。下面的示例中使用的日期格式不符合默认的日期格式(YYYY-MM-DD):
mysql> UPDATE person
-> SET birth_date = 'DEC-21-1980'
-> WHERE person_id = 1;
ERROR 1292 (22007): Incorrect date value: 'DEC-21-1980' for column
'birth_date' at row 1
一般而言,最好是明确指定格式化字符串,而不是依赖默认格式。下列语句使用str_to_date函数指定了格式化字符串:
mysql> UPDATE person
-> SET birth_date = str_to_date('DEC-21-1980' , '%b-%d-%Y')
-> WHERE person_id = 1;
Query OK, 1 row affected (0.12 sec)
Rows matched: 1 Changed: 1 Warnings: 0
本章之前讨论各种各种时间数据类型时,展示过如“YYYY-MM-DD”这样的日期格式化字符串。尽管很多数据库服务器都采用这种格式化风格,但MySQL使用“%Y”来指定4位数字的年份。下面是一些在MySQL中将字符串转换为datetime类型时可能会用到的格式化字符:
%a 星期几的简写,比如Sun、Mon、…
%b 月份名称的简写,比如Jan、Feb、…
%c 月份的数字形式(0…12)
%d 月份中的天数(00…31)
%f 微秒数(000000…999999)
%H 24小时制中的小时(00…23)
%h 12小时制中的小时(01…12)
%i 小时中的分钟数(00…59)
%j 一年中的天数(001…366)
%M 月份的全称(January…December)
%m 月份的数值形式
%p AM或PM%s 秒数(00…59)
%W 星期几的全称(Sunday…Saturday)
%w 一星期中的天数(0=周日;6=周六)
%Y 4位数字表示的年份
2.6 Sakila数据库
后面的章节中用到的例子的表主要来自这个数据库。
3. 查询入门
3.1 查询子句
| 子句名称 | 作用 |
|---|---|
| select | 决定查询结果集中包含哪些列 |
| from | 指明从哪些数据表中检索数据以及数据表如何连接 |
| where | 过滤掉不需要的数据 |
| group by | 用于对具有相同列值的行进行分组 |
| having | 过滤掉不需要的分组 |
| order by | 根据一个或多个列对最终结果集中的行进行排序 |
3.2 select子句
select * from language;
*号表示表中的所有列都显示在结果集中。
除了通过星号字符指定所有的列,你也可以明确指定需要的列名:
mysql> SELECT language_id, name, last_update
-> FROM language;
因此,select子句的任务如下:
select子句决定哪些列应该包含在查询的结果集中。
如果只能包含from子句中指明的那些数据表中的列,未免太无趣了,可以加入下列内容,让select子句更丰富些。
- 字面量,比如数值或字符串。
- 表达式,比如transaction.amount * −1。
- 内建函数调用,比如ROUND(transaction.amount, 2)。
- 用户自定义函数调用。
接下来的查询演示了数据表列、字面量、表达式以及内建函数调用在针对language数据表的单个查询中的应用:
mysql> SELECT language_id,
-> 'COMMON' language_usage,
-> language_id * 3.1415927 lang_pi_value,
-> upper(name) language_name
-> FROM language;
+-------------+----------------+---------------+---------------+
| language_id | language_usage | lang_pi_value | language_name |
+-------------+----------------+---------------+---------------+
| 1 | COMMON | 3.1415927 | ENGLISH |
| 2 | COMMON | 6.2831854 | ITALIAN |
| 3 | COMMON | 9.4247781 | JAPANESE |
| 4 | COMMON | 12.5663708 | MANDARIN |
| 5 | COMMON | 15.7079635 | FRENCH |
| 6 | COMMON | 18.8495562 | GERMAN |
+-------------+----------------+---------------+---------------+
6 rows in set (0.04 sec)
内建函数的使用
mysql> SELECT version(),
-> user(),
-> database();
+-----------+----------------+------------+
| version() | user() | database() |
+-----------+----------------+------------+
| 8.0.15 | root@localhost | sakila |
+-----------+----------------+------------+
1 row in set (0.00 sec)
3.2.1 列的别名
select 列名 别名,列名 别名.... from 表名;
例子
mysql> SELECT language_id,
-> 'COMMON' language_usage,
-> language_id * 3.1415927 lang_pi_value,
-> upper(name) language_name
-> FROM language;
+-------------+----------------+---------------+---------------+
| language_id | language_usage | lang_pi_value | language_name |
+-------------+----------------+---------------+---------------+
| 1 | COMMON | 3.1415927 | ENGLISH |
| 2 | COMMON | 6.2831854 | ITALIAN |
| 3 | COMMON | 9.4247781 | JAPANESE |
| 4 | COMMON | 12.5663708 | MANDARIN |
| 5 | COMMON | 15.7079635 | FRENCH |
| 6 | COMMON | 18.8495562 | GERMAN |
+-------------+----------------+---------------+---------------+
6 rows in set (0.04 sec)
为了使列的别名更加清晰可见,也可以在别名前使用as关键字:
mysql> SELECT language_id,
-> 'COMMON' AS language_usage,
-> language_id * 3.1415927 AS lang_pi_value,
-> upper(name) AS language_name
-> FROM language;
3.2.2 移除重复数据
例子,检索出现在某部电影中的所有演员的ID,有些演员参演了不止一部电影,所以会多次看到相同的演员ID。
mysql> SELECT actor_id FROM film_actor ORDER BY actor_id;
+----------+
| actor_id |
+----------+
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
...
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
+----------+
5462 rows in set (0.01 sec)
通过在select后面直接添加关键字distinct来实现。
mysql> SELECT DISTINCT actor_id FROM film_actor ORDER BY actor_id;
+----------+
| actor_id |
+----------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
...
| 192 |
| 193 |
| 194 |
| 195 |
| 196 |
| 197 |
| 198 |
| 199 |
| 200 |
+----------+
200 rows in set (0.01 sec)
记住,生成一组不同的结果时需要对数据进行排序,这对于大型结果集会很耗时。不要陷入为了确保没有重复数据而使用distinct的陷阱,而应该花时间充分理解所处理的数据,以便了解是否可能出现重复数据。
3.3 from子句
- from子句定义了查询要用到的数据表以及连接数据表的方式。
- 该定义包含了两个独立且相关的概念,下面我们来逐一讲解。
3.3.1 数据表
宽泛定义的数据表有4种:
- 永久数据表(使用create table语句创建);
- 派生数据表(由子查询返回并保存在内存中的行);
- 临时数据表(保存在内存中的易失数据);
- 虚拟数据表(使用create view语句创建)。
1.派生(由子查询生成)数据表
子查询是包含在另一个查询中的查询。子查询由一对小括号包围,可以出现在select语句的各个部分中。在from子句中,子查询的作用在于生成其他所有查询子句中可见的派生数据表,以及与from子句中的其他数据表交互。下面来看一个简单的示例:
mysql> SELECT concat(cust.last_name, ', ', cust.first_name) full_name
-> FROM
-> (SELECT first_name, last_name, email
-> FROM customer
-> WHERE first_name = 'JESSIE'
-> ) cust;
+---------------+
| full_name |
+---------------+
| BANKS, JESSIE |
| MILAM, JESSIE |
+---------------+
2 rows in set (0.00 sec)
在本例中,customer数据表的子查询返回3列,外围查询(containing query)引用了其中的2列。子查询由外围查询通过其别名cust进行引用。cust的数据在查询期间保存在内存中,随后就被丢弃。这里在from子句中给出子查询很简单,也没太大的实用性,我们会在第9章详细讨论子查询。
- 临时数据表
关键字temporary
所有的关系型数据库都允许定义易失性(或临时)数据表。插入其中的任何数据都会在某个时候(通常在事务结束或数据库会话关闭时)消失。
mysql> CREATE TEMPORARY TABLE actors_j
-> (actor_id smallint(5),
-> first_name varchar(45),
-> last_name varchar(45)
-> );
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO actors_j
-> SELECT actor_id, first_name, last_name
-> FROM actor
-> WHERE last_name LIKE 'J%';
Query OK, 7 rows affected (0.03 sec)
Records: 7 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM actors_j;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 119 | WARREN | JACKMAN |
| 131 | JANE | JACKMAN |
| 8 | MATTHEW | JOHANSSON |
| 64 | RAY | JOHANSSON |
| 146 | ALBERT | JOHANSSON |
| 82 | WOODY | JOLIE |
| 43 | KIRK | JOVOVICH |
+----------+------------+-----------+
7 rows in set (0.00 sec)
3.视图
视图是存储在数据目录中的查询,其行为表现就像数据表,但是并没有与之关联的数据(这就是将其称为虚拟数据表的原因)。当查询视图时,该查询会与视图定义合并,以产生要执行的最终查询。
下面是一个查询employee数据表的视图定义,共包含4列:
mysql> CREATE VIEW cust_vw AS
-> SELECT customer_id, first_name, last_name, active
-> FROM customer;
Query OK, 0 rows affected (0.12 sec)
创建视图时,不会生成或存储额外的数据:服务器只是保留select语句,以备后用。有了视图,就可以向其发出查询了,如下所示:
mysql> SELECT first_name, last_name
-> FROM cust_vw
-> WHERE active = 0;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| SANDRA | MARTIN |
| JUDITH | COX |
| SHEILA | WELLS |
| ERICA | MATTHEWS |
| HEIDI | LARSON |
| PENNY | NEAL |
| KENNETH | GOODEN |
| HARRY | ARCE |
| NATHAN | RUNYON |
| THEODORE | CULP |
| MAURICE | CRAWLEY |
| BEN | EASTER |
| CHRISTIAN | JUNG |
| JIMMIE | EGGLESTON |
| TERRANCE | ROUSH |
+------------+-----------+
15 rows in set (0.00 sec)
创建视图的原因各种各样,包含对用户隐藏列、简化复杂的数据库设计。
3.3.2 数据表链接
一个简单的例子
mysql> SELECT customer.first_name, customer.last_name,
-> time(rental.rental_date) rental_time
-> FROM customer
-> INNER JOIN rental
-> ON customer.customer_id = rental.customer_id
-> WHERE date(rental.rental_date) = '2005-06-14';
+------------+-----------+-------------+
| first_name | last_name | rental_time |
+------------+-----------+-------------+
| JEFFERY | PINSON | 22:53:33 |
| ELMER | NOE | 22:55:13 |
| MINNIE | ROMERO | 23:00:34 |
| MIRIAM | MCKINNEY | 23:07:08 |
| DANIEL | CABRAL | 23:09:38 |
| TERRANCE | ROUSH | 23:12:46 |
| JOYCE | EDWARDS | 23:16:26 |
| GWENDOLYN | MAY | 23:16:27 |
| CATHERINE | CAMPBELL