第一章:马尔科夫决策过程(不可能看不懂)
目录
一、预备知识
二、马尔可夫决策过程
三、马尔可夫性质
四、回报
五、状态转移矩阵
六、小结
一、预备知识
本节主要介绍强化学习最基本的问题模型,马尔科夫决策过程(Markov decision process,MDP),通过数学方程的形式表达序列的决策过程。涉及部分理论知识以及公式,但是难度并不大,需要回顾一下简单的概率论知识,例如条件概率等。
二、马尔可夫决策过程
马尔科夫决策过程是强化学习的基本问题之一,其涉及的对象主要包括智能体和环境。所谓智能体就是做出动作并在与环境交互的过程中不断学习的角色,环境就是与智能体进行交互的外界事物。相关概念还有状态State,奖励(反馈)Reward等等,都在下方的例子详细解释。
例如,我在学习钢琴,在这个过程中我就是智能体,而钢琴就是环境,当我按下某个琴键会获得一些信息,如琴键的位置以及我的手的位置等等,这些构成了一个状态,同时我能听到该琴键的声音,这就是奖励(反馈),我通过这个琴键发出的声音判断我是否弹的好然后进行纠正。也可以参考下图(马尔科夫决策过程中智能体与环境的交互过程)来理解这个过程。

智能体与环境在一系列离散的时间戳交互,一般用t表示,t = 0,1,2 ···。在每个时间戳t,智能体会观测当前环境下的状态 ,根据这个状态做出一个决策
,根据这个状态做出一个决策 ,执行完该决策之后会获得一个奖励
,执行完该决策之后会获得一个奖励![]() ,同时环境收到智能体做出的这个决策后会被影响变成新的状态
,同时环境收到智能体做出的这个决策后会被影响变成新的状态![]() ,并且在下一个时间戳t+1被智能体观测到,如此循环下去。
,并且在下一个时间戳t+1被智能体观测到,如此循环下去。
其中奖励![]() 就相当于弹钢琴时听到的声音,调子弹对了就表示正奖励,否则就是负奖励。此外,在强化学习中我们通常考虑的是有限马尔科夫决策过程,即t是有限的,上限一般用T表示,也就是当前交互过程的最后一个时间戳,从t=0到t=T这一段时间我们称为一个回合(episode),比如我们玩金铲铲,每一次英雄的更换或者装备的合成等等都是动作,但是一局的总轮数还是有限的,因此一整局就是一个回合episode。
就相当于弹钢琴时听到的声音,调子弹对了就表示正奖励,否则就是负奖励。此外,在强化学习中我们通常考虑的是有限马尔科夫决策过程,即t是有限的,上限一般用T表示,也就是当前交互过程的最后一个时间戳,从t=0到t=T这一段时间我们称为一个回合(episode),比如我们玩金铲铲,每一次英雄的更换或者装备的合成等等都是动作,但是一局的总轮数还是有限的,因此一整局就是一个回合episode。
- 这里的时间戳t=0和t=1与现实时间并无关系,取决于智能体每次交互获得反馈需要的时间。比如弹钢琴一旦按下去就马上能得到回馈(此时一个时间戳的间隔可能是0.1s),但是我们在锻炼肌肉的过程中并不会很快得到反馈(此时一个时间戳的间隔可能就是一个月)。
- 上述中的奖励表示为
,而不是
,原因是做出当前决策后才能获得奖励,因此更强调在下一个时间戳获得的奖励。
三、马尔可夫性质
马尔科夫性质如下方公式:
![]()
这个公式的意思是,给定历史状态,但是当前状态的下一个状态![]() 只与当前状态有关,与历史的状态都无关。该性质具有重要意义,允许我们在没有考虑系统完整历史的情况下预测和控制行为。
只与当前状态有关,与历史的状态都无关。该性质具有重要意义,允许我们在没有考虑系统完整历史的情况下预测和控制行为。
但是实际问题中还是有些许例子不符合马尔可夫性质,比如棋类游戏,我们在决策的过程中当然是要考虑历史过程所有棋子的摆放才能有更正确的分析。
四、回报
马尔可夫决策过程中智能体的目标是最大化累积的奖励,通常吧这个累积的奖励称为回报(Return),用 表示,最简单的回报可以用如下公式表示:
表示,最简单的回报可以用如下公式表示:
![]()
T前面已经提过了,表示最后一个时间戳,也就是每回合(episode)的最大步数。上述公式适用于有限步数的情况,比如玩铲铲,无论输赢,每回合总是会在有限的步数以某种状态结束,这种状态称为终止状态。但也有一些情况无终止状态,也就是说智能体与环境会持续交互,比如人造卫星发射后会一直在太空作业直到报废后回收,这样的任务称为持续性任务,上述公式不适用于持续性任务,此时T等于无穷。
为了解决这个问题,此时就要引入一个关键概念折扣因子(discount factor)![]() ,并可以将回报表示为下式:
,并可以将回报表示为下式:
![]()
其中 的取值范围为0到1,它表示了我们在考虑未来奖励的重要程度,权衡当前奖励和未来奖励。换句话说,它体现了我们对长远目的重视程度。当=0时,我们只关心当前的奖励,而不在乎未来的奖励。而当接近1时,表示我们对未来的奖励也给予较高的重视程度。
的取值范围为0到1,它表示了我们在考虑未来奖励的重要程度,权衡当前奖励和未来奖励。换句话说,它体现了我们对长远目的重视程度。当=0时,我们只关心当前的奖励,而不在乎未来的奖励。而当接近1时,表示我们对未来的奖励也给予较高的重视程度。
这样做的好处是让当前时间戳的回报与下一个时间戳的回报![]() 有所关联,如下方公式的推导:
有所关联,如下方公式的推导:
五、状态转移矩阵
目前,我们讲的都是有限状态的马尔可夫决策过程,指的是状态的数量有限(无论是离散的还是连续的),如果状态数是无限的,则通常采用泊松过程来建模,这个过程又被称作连续时间,马尔可夫过程,允许发生无限次事件,对每个事件发生的机会相对较小,但当时间趋于无穷的时候,这些时间以极快的速度发生。泊松过程在某些场景下十分有用,但是大多数强化学习场景,还是采用马尔可夫决策过程。
状态数有限,那么就可以用状态流图来表示智能体与环境交互过程的走向。假设一个学生在上课,那么状态不外乎三种,认真听讲,玩手机和睡觉,分别用 ,
, ,
,![]() 表示。这里我把老师当成智能体,老师和学生组成环境,但如果把学生作为智能体,那么认真听讲,玩手机和睡觉则是智能体的决策而不是状态。在实际问题中是很常见的,毕竟交互式相互的,强化学习的环境并不是严格的静止环境,它也可以是其他智能体。有时候智能体和环境的角色是可以互相对调的,只要能各自建模成马尔可夫决策过程即可。
表示。这里我把老师当成智能体,老师和学生组成环境,但如果把学生作为智能体,那么认真听讲,玩手机和睡觉则是智能体的决策而不是状态。在实际问题中是很常见的,毕竟交互式相互的,强化学习的环境并不是严格的静止环境,它也可以是其他智能体。有时候智能体和环境的角色是可以互相对调的,只要能各自建模成马尔可夫决策过程即可。

如上图所示,图中的曲线箭头指向自己,数字表示状态切换的概率。比如学生在认真听讲时的状态为,会有0.2的概率依旧是认真听讲,当然也会有0.4和0.4的概率转向睡觉或者玩手机。无向箭头表示两个不同状态间的切换,当然也可以用两条有向箭头表示,为了简介我就只使用了一个无向线段连接。
上图表示了马尔可夫决策过程的状态流向,其实跟数字电路中有限状态机的概念一样。严格来说,这张图并没有完整地描述马尔可夫决策过程,因为没有包含动作、奖励等因素,所以我们称之为马尔可夫链,同样也需要满足马尔可夫性质。我们用一个概率来表示状态间的切换,比如![]() ,表示从当前认真听讲的状态切换到玩手机的状态的概率,我们把这个概率称为状态转移概率(State Transition Probability)。由于状态数是有限的,我们可以用下表来描述:
,表示从当前认真听讲的状态切换到玩手机的状态的概率,我们把这个概率称为状态转移概率(State Transition Probability)。由于状态数是有限的,我们可以用下表来描述:
| 0.2 | 0.4 | 0.4 | |
| 0.2 | 0.5 | 0.3 | |
| 0.1 | 0.3 | 0.6 |
也可以用数学的矩阵来表示:

这个矩阵就叫做状态转移矩阵(State Transition Matrix),拓展到所有状态可以表示为:

- 其中n表示状态数量,注意对于同一个状态而言,其所有状态转移概率之和是1。
- 状态转移矩阵是环境的一部分,和智能体无关,只是说智能体会根据状态转移矩阵来做出决策。比如老师是智能体,但是学生的状态不是老师可以决定的,但是老师看到学生在睡觉可以做出提醒等决策。
在马尔可夫链的基础上加上奖励元素就会形成马尔可夫奖励过程,在马尔可夫奖励过程的基础上增加动作元素就会形成后马尔可夫决策过程,主要就是这么个逻辑过程。马尔可夫链和马尔可夫奖励过程在金融分析领域用的多,强化学习则侧重决策过程。
到这里我们可以把马尔科夫决策过程用一个五元组表示,即![]() 。其中
。其中 表示状态空间(所有状态的集合),
表示状态空间(所有状态的集合), 表示动作空间,
表示动作空间, 表示奖励函数,
表示奖励函数,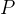 表示状态转移矩阵,
表示状态转移矩阵,![]() 表示折扣因子。
表示折扣因子。
六、小结
本章介绍了马尔可夫决策过程的概念,是强化学习基本问题模型之一,因此需要牢牢掌握。此外还包括回报,状态转移矩阵,回合等概念,这些我们会在后面频繁使用,请务必牢记于心。