专注于业务编排的工作流引擎Temporal框架技术Java实践(SpringBoot)
目录
Temporal
业务系统结构
心跳以及重试机制
长耗时复杂业务工作流设计
场景
选项1
选项 2
选项 3
Activity持久化问题
写在最后
Temporal
Temporal 是一个微服务编排平台,使开发人员能够在不牺牲生产力或可靠性的情况下构建可扩展的应用程序。临时服务器以弹性方式执行应用程序逻辑单元工作流,自动处理间歇性故障并重试失败的操作。
Temporal 是一项成熟的技术,是 Uber 的 Cadence 的一个分支。Temporal由 Cadence 的创建者初创公司Temporal Technologies开发。
若你还不了解Temporal基础结构,点此跳转。本文专为实践受众,以提供实践思路为目的书写。
想象下,你的业务系统存在数十种算法服务,足够复杂,比如面部3D识别、局部投影、五官单部位识别,动作识别等等。处理请求量大频繁,处理过程采用算法先后不尽相同,并且这些算法处理时间不一,而你需要对这些算法进行编排,来实现具体的业务。
为此你可能需要选择一款框架来帮助你,解决因不同算法服务的不确定性带来的麻烦,比如网络不确定性问题,业务复杂度问题等。
也许你跟我一样,曾在RabbitMq和Temporal中徘徊过,看完下文但愿你有所得,我对两者区别分析如下:
| RabbitMq | Temporal | |
| 平台 | 跨平台,多语言,分布式集群 | 跨平台,多语言,时空集群 |
| 关注点 | 关注消息本身,不关心消息被谁消费,关注的是消息是否送达。 | 关注任务执行进度和结果,是否需要重试等等。让程序员专注于业务的编排。 |
| 性能 | 基于内存的设计,性能出众。 | 支持多种存储方式,性能各有差异。MySQL存储100w级轻松应对。 |
| 复杂度 | 上手快,基于AMQP模型。 | 难度较大,有独特的并发编程规范,会与基础语言有所冲突。 |
| Web-UI | 人性化的web-ui提供高效资源监控。 | web-ui仍有较大优化空间。 |
| 部署 | 单机、集群、云环境部署简单。 | 支持单机、时空集群、支持多种云环境部署。 |
| 对Spring支持 | 原生提供对Spring的多种支持实例模型。 | 原生框架暂未提供对Spring的集成方案,因此你可能需要考虑进行代码层次的兼容。 |
依据上表,你应该可以做出合理的架构计数技术选型。很荣幸选择Temporal的你可以从下文获取实践经验。
业务系统结构
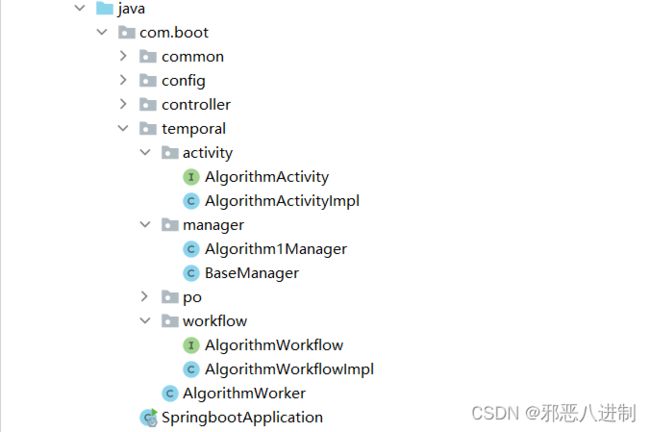
可以看出,Temporal仍有较大优化空间,但不妨碍它成为一款优秀框架的潜质。编程时会遇到不少问题,为此我根据经验总结出如下代码分层结构:
| 关键层级 | 定义 |
AlgorithmWorker |
封装后的工人客户端,负责启动Workflow,以及向队列投递消息。 |
| Workflow | 每个Workflow代表一种特定的工作流程,代表着对算法的一种特定编排逻辑。 |
| Activity | 每个Activity代表一种特定执行逻辑,比如3D识别算法逻辑、面部识别算法逻辑、所有涉及IO或第三方服务调用逻辑等。每个Activity之间是松耦合的,应当仅包含一种特定行为。 |
| Manager | 业务逻辑层,用于解耦Workflow和Activity业务代码。 |
使用确定的层级关系,这意味着你的代码执行逻辑应当是:
- 使用守护线程启动一个的Workflow客户端,作为消费队列消息的主体。
- 提供同步/异步的消息投递接口,异步接口你可能会需要使用到父子Workflow,通过父Workflow管理子Workflow的并发执行,以及进度监听等。
- 在WorkflowImpl进行具体的业务逻辑编排,你可以将它看成Service,不同的是,你必须遵循Temporal相关约束,否则将面临代码健壮性问题,相信我你会为此头疼不已。
- 将所有不确定性代码抽象成Activity。IO、RPC调用、DB、Redis等等第三方或服务调用代码。
- 遵循工作流约束。
- WorkflowImpl中单行代码执行时间不应该超过1s,Activity调用除外。否则,因事件超时导致Workflow进入执行逻辑问题,异常显示如下:
2022-02-21 18:20:11.036 ERROR 26416 --- [ce="default": 1] i.t.i.replay.ReplayWorkflowTaskHandler : Workflow task failure. startedEventId=3, WorkflowId=2feb44c0-54e0-4028-8a2b-e6679fe4d392_0, RunId=d3fa3df3-e6c8-4e36-8c5f-e399f067b624. If seen continuously the workflow might be stuck.
io.temporal.internal.replay.InternalWorkflowTaskException: Failure handling event 3 of 'EVENT_TYPE_WORKFLOW_TASK_STARTED' type. IsReplaying=false, PreviousStartedEventId=3, workflowTaskStartedEventId=3, Currently Processing StartedEventId=3
at io.temporal.internal.statemachines.WorkflowStateMachines.createEventProcessingException(WorkflowStateMachines.java:221) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.statemachines.WorkflowStateMachines.handleEventsBatch(WorkflowStateMachines.java:201) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.statemachines.WorkflowStateMachines.handleEvent(WorkflowStateMachines.java:175) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.replay.ReplayWorkflowRunTaskHandler.handleWorkflowTaskImpl(ReplayWorkflowRunTaskHandler.java:177) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.replay.ReplayWorkflowRunTaskHandler.handleWorkflowTask(ReplayWorkflowRunTaskHandler.java:146) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.replay.ReplayWorkflowTaskHandler.handleWorkflowTaskWithEmbeddedQuery(ReplayWorkflowTaskHandler.java:201) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.replay.ReplayWorkflowTaskHandler.handleWorkflowTask(ReplayWorkflowTaskHandler.java:114) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.worker.WorkflowWorker$TaskHandlerImpl.handle(WorkflowWorker.java:319) [temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.worker.WorkflowWorker$TaskHandlerImpl.handle(WorkflowWorker.java:279) [temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.worker.PollTaskExecutor.lambda$process$0(PollTaskExecutor.java:73) [temporal-sdk-1.5.0.jar:na]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[na:1.8.0_302]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[na:1.8.0_302]
at java.lang.Thread.run(Thread.java:748) ~[na:1.8.0_302]
Caused by: java.lang.RuntimeException: WorkflowTask: failure executing SCHEDULED->WORKFLOW_TASK_STARTED, transition history is [CREATED->WORKFLOW_TASK_SCHEDULED]
at io.temporal.internal.statemachines.StateMachine.executeTransition(StateMachine.java:151) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.statemachines.StateMachine.handleHistoryEvent(StateMachine.java:101) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.statemachines.EntityStateMachineBase.handleEvent(EntityStateMachineBase.java:67) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.statemachines.WorkflowStateMachines.handleSingleEvent(WorkflowStateMachines.java:233) ~[temporal-sdk-1.5.0.jar:na]
at io.temporal.internal.statemachines.WorkflowStateMachines.handleEventsBatch(WorkflowStateMachines.java:199) ~[temporal-sdk-1.5.0.jar:na]
... 11 common frames omitted
Caused by: io.temporal.internal.sync.PotentialDeadlockException: Potential deadlock detected: workflow thread "workflow-method" didn't yield control for over a second. Other workflow threads:当你了解Temporal基础,了解项目结构后,你应该能对简单业务进行编码,若不行也许下面这个模板会对你有些许帮助。
心跳以及重试机制
当Workflow或Activity出现异常,就会触发重试策略。Temporal通过心跳上报的方式检测Activity存活状态,面对复杂业务或网络抖动因素,同步的心跳上报无法满足需求,为此提供两种解决方案:
- 通过线程池管控全局心跳,Activity执行之初将上下文存入池中,再通过多线程方式进行上报;
- 每个Activity运行之初启动一个子线程进行心跳上报
两种方式各有优劣,在这里我们选择子线程方式。
package com.boot.common;
import io.temporal.activity.ActivityExecutionContext;
import lombok.extern.slf4j.Slf4j;
/**
* 功能描述:
*
* @program: melt-voiceai-server
* @author: 代号007
* @create: 2021-12-28 09:39
**/
@Slf4j
public class HeartbeatThread implements Runnable {
private Integer heartbeatInterval;
private ActivityExecutionContext context;
private Object value;
private volatile boolean status = true;
public HeartbeatThread(Integer heartbeatInterval, ActivityExecutionContext context, Object value) {
this.heartbeatInterval = heartbeatInterval;
this.context = context;
this.value = value;
}
@Override
public void run() {
log.info("启动【{}】心跳包发送任务", value);
while (status) {
context.heartbeat(1);
log.info("发送【{}】心跳包成功。", value);
try {
Thread.sleep(heartbeatInterval * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public synchronized void stop() {
status = false;
}
}
长耗时复杂业务工作流设计
对于复杂IO或者大批量数据任务,简单工作流可能无法满足需求。这类任务尝使用异步方式执行,这包括Workflow和Activity异步,并且会面临任务拆分问题,在这里提供一种解题思路:
我们有一个简单的工作流程,看起来与此类似:
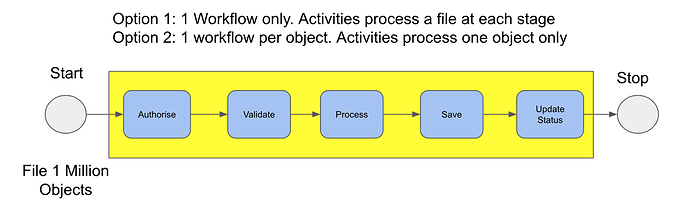
工作流从一个文件开始,其中可能有数百万条记录需要处理。我可以看到几个可用于处理此问题的选项:
- 在处理文件的每个阶段使用活动创建单个工作流。每个 Activity 都会引用一个文件,处理该文件,然后返回一个对新创建的已处理文件的引用。然后将其传递给下一个活动,依此类推。如果在处理过程中出现任何问题,每个 Activity 都可以检查心跳以从特定点恢复。
- 打开原始文件并循环处理每个对象。然后,每个 Activity 将只处理一个对象,因此该对象可能作为参数传递,而不是在文件中引用。
- 打开原始文件,并为文件中的每个对象生成一个单独的工作流。然后,每个 Activity 将只处理一个对象,因此这可能会作为参数传递,而不是在文件中引用。需要跟踪每个子工作流,以便在所有子工作流完成后完成父工作流。
选项 2 有可能在单个工作流中创建数百万个事件,因此我认为每个工作流 10 万个事件的内部限制将使该选项不可行。
选项 1 和选项 3 看起来它们都可以工作。
选项 1 优点和缺点
- 优点:不触发多个工作流程
- 缺点:无法并行处理多个对象
选项 3 优点和缺点
- 优点:可以并行处理多个对象
- 缺点:必须创建很多工作流程。
- 缺点:不能利用任何批量操作,例如批量保存对象。
在这种情况下,是否有关于应该采用哪种方法或一种方法可能比另一种方法存在的陷阱的任何建议?
选项 1 优点和缺点
- 缺点:无法并行处理多个对象
您可以为文件的不同部分运行多个并行活动。例如,对于存储在 S3 中的大文件,您可以将其中的一部分独立下载到不同的主机。
选项 3 优点和缺点
3. 缺点:不能利用任何批量操作,例如批量保存对象。有多种方法可以跨多个活动调用缓冲事件。例如,在一个工作人员上累积许多活动的结果,并在完成批量操作后异步完成所有这些活动。
场景
选项1
如果处理文件的每条记录既简单又短暂,这是最简单的方法。如果有助于加快处理速度,活动实现可以并行处理多个记录。
选项 2
如果文件的大小是有界的,这种方法仍然很有用,因为它是最简单的一种。
这种方法有一个变体,它适用于无限大小的文件,我称之为迭代器工作流。这个想法是处理文件的一部分,然后调用continue as new以继续处理。这样,处理一系列记录的工作流的每次运行都具有大小限制。如果每条记录都需要子工作流进行处理,这种方法也适用。
选项 3
如果每条记录都需要独立编排,这可能会花费不可预测的时间,则需要每个记录的子工作流选项。如果文件中的记录数量很大,则可以使用我在选项 2中描述的迭代器工作流方法或使用分层工作流。例如,具有 1000 个子级且每个子级具有 1000 个子级的父工作流允许启动 100 万个工作流,而不会达到任何工作流大小限制。
关于选项 1。您对短命的定义是什么?
在示例工作流程图中,我认为大多数活动将在几分钟内完成文件处理,有些可能需要长达 30 分钟。“保存”活动会将对象写入 Elastic 之类的东西,因此需要更长的时间,具体取决于文件的大小。我假设“保存”活动也可以并行处理批次以加快速度。
如果我们确实采用更多的流式方法,我喜欢迭代器工作流程的想法。我在一些示例中看到了 ContinueAsNew 选项。如果我们确实想利用批量保存,这些步骤是否类似于:
- 有一个循环来处理一批x对象。跟踪当前批次计数
- 创建x 个异步子工作流,其中子工作流类似于工作流程图,除了删除“保存”和“更新状态”活动。
- 等待所有子工作流完成。
- 从x子工作流中取回结果,然后传递给“保存”活动
- 基于循环调用“Continue As New”的迭代次数
- 一旦处理完所有对象,就会调用“更新状态”活动。
这个会:
- 避免事件或历史限制的任何问题
- 允许并行处理对象
- 允许批量保存对象
关于选项 1。您对短命的定义是什么?
短暂的我的意思是文件可以逐行顺序处理。如果每行处理需要很长时间或需要某种状态机,那么简单的扫描解决方案将无法正常工作。从时间的角度来看,活动可以根据需要运行。对于此类长时间运行的活动,心跳对于及时检测故障非常重要。
提议的设计对我来说看起来不错。确保“批量保存”活动输入的大小合理。
以上出自官方社区,也许对你会很有帮助,具体参考此处。
不论哪种方案都会牵引出子工作处理流,引入子工作处理流可以帮助我们更加灵活的调配Workflow,但也会带来一系列问题,比如如何监控子工作流执行进度?子工作流异常如何批量重试?如何手动中断任务等。
使用@QueryMethod和WorkflowLocal能帮助你轻松实现监控。而后面两者则需要结合具体业务来做决策。
通过这种灵活的编排机制,你甚至能实现对算法的动态编排,达到将权利下方给用户的效果。
但,这对编码人员也有更高的要求,不仅仅是将处理流程存入Redis这么简单,不恰当的代码将会使测试都变得十分困难。
Activity持久化问题
Temporal采用grpc进行通讯,并约束通讯最大消息长度不得超过4m,对于此Temporal提供TEMPORAL_GRPC_MAX_MESSAGE_LENGTH环境变量来进行控制,但面对不可控的消息体积时,环境变量将变得并没有那么适用。
对此提供序列化存储方式,已解决此问题,具体参考。
package com.voiceai.common.temporal.manager;
import java.io.*;
/**
* Java对象序列化和反序列化的工具方法
*/
public class ObjectSerializable implements Serializable {
private static final long serialVersionUID = 1L;
/**
* Java对象序列化
*/
public void serialization(String filePath, T data) throws Exception {
// 1. 检查该路径文件是否存在,不存在则创建
File file = new File(filePath);
createFileIfNotExists(file);
// 2. 创建输出流,将数据写入文件
ObjectOutputStream out = null;
try {
// 流创建
out = new ObjectOutputStream(new FileOutputStream(file));
// 序列化对象
out.writeObject(data);
} finally {
// 关闭流
if (null != out) {
out.close();
}
}
}
// 如果文件不存在,生成一个新文件
public void createFileIfNotExists(File file) throws IOException {
// 如果文件不存在,进行创建
if (!file.exists()) {
// 如果父目录不存在,创建父目录
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
// 创建一个新的文件
file.createNewFile();
}
}
/**
* Java对象反序列化
*/
public T deserialization(String filePath) throws Exception {
// 如果文件不存在,抛个异常
File file = new File(filePath);
if (!file.exists()) {
throw new FileNotFoundException(filePath);
}
// 创建输入流,从物件中读取数据
ObjectInputStream in = null;
Object object = null;
try {
// 流创建
in = new ObjectInputStream(new FileInputStream(file));
// 对象反序列化
object = in.readObject();
} finally {
// 关闭流
if (null != in) {
in.close();
}
}
// 返回反序列化后的对象
return (T)object;
}
} 写在最后
你应该会发现,譬如异常、重试等我并没有过多阐释,我认为这是较为简单的。
尽管我所书写足够详细,但测试却仍会消耗你大量时间,这是不可避免的。
到此你应该能轻松驾驭Temporal,但愿对你会有帮助,也是我快乐之所在!
---------------------------------------2023-02-13 补上漏掉的案例链接-----------------------------------------
GitHub - LmingXie/temporal-springboot-template: Springboot集成Temporal框架样板。