PointNet:基于Python和PyTorch的3D分割的实用指南
准备好探索3D分割的世界吧,我们将通过PointNet进行一次旅程,这是一种理解3D形状的超酷方法。PointNet就像计算机查看3D事物的智能工具,尤其是在空间中漂浮的点群。它与其他方法不同,因为它直接处理这些点,而不需要将它们强制放入网格或图片中。
在本文中,我们将使PointNet易于理解。我们将从大的想法开始,实际上编写Python和PyTorch的代码来进行3D分割。但在我们进入有趣的部分之前,让我们首先了解一下PointNet的内容——它如何成为解决3D事物(如对象及其部分)的重要工具。
因此,跟随我们一起看PointNet论文的摘要。我们将讨论其设计、背后的酷炫理论以及在实际实验中的表现。当我们探索随机点、特殊函数以及PointNet如何处理不同的3D任务时,我们将保持简单。准备好通过PointNet发现3D分割的威力了吗?让我们开始吧。

理解PointNet:核心概念
既然我们已经铺好了舞台,让我们将PointNet分解成一小块一小块的。PointNet就像一个特殊的工具,帮助计算机理解3D事物,尤其是那些棘手的点云。但是它为何如此酷呢?与整齐组织数据的其他方法不同,PointNet直接接受点,不需要网格或图片。这使它在3D领域脱颖而出。
点集的基础知识
想象一群点在3D空间中漂浮。这些点没有特定的顺序,它们相互作用。PointNet通过友好地对待旋转或移动等变化来处理这种随机性。当点互换位置时,它不会困惑。
对称魔法
PointNet具有一种特殊的力量,称为对称。想象一下你有一个点的袋子,无论你如何洗牌,PointNet仍然能理解里面是什么。这就像处理不遵循特定顺序的点的魔法。
收集局部和全局信息
PointNet擅长收集信息。它看大局(全局)和点的细节(局部),这有助于它执行诸如确定对象形状及其部分的任务。
对齐技巧
PointNet还擅长处理变化。如果你旋转或移动点,PointNet可以调整并理解事物。这就像一个机器人,将事物对齐以便清晰地看到它们。
理论魔法
现在,让我们谈谈PointNet背后的一些大思想。有两个特殊的定理表明PointNet不仅在实践中很酷,而且在理论上是一个明智的选择。
1. 通用逼近
— PointNet可以很好地学习理解任何3D形状。这就像说PointNet是一个超级英雄,可以处理你投给它的任何形状。
2. 瓶颈维度和稳定性
— PointNet很强大。即使添加一些额外的点或搞乱已经存在的点,它也不会困惑。它坚守岗位并保持稳定。
这些大思想使PointNet成为理解3D形状的可靠工具。请关注下一部分,我们将从理论过渡到实践,开始在Python和PyTorch中进行一些编码。
PointNet架构概述
PointNet架构由两个主要组件组成:分类网络和扩展分割网络。分类网络接受n个输入点,应用输入和特征变换,并通过最大池化汇总点特征。它为k个类别生成分类分数。分割网络是分类网络的自然扩展,结合全局和局部特征生成每个点的分数。术语“mlp”表示多层感知器,其层大小在方括号中指定。批量归一化始终应用于所有层,并伴随着ReLU激活。此外,在分类网络的最终mlp中巧妙地引入了dropout层。
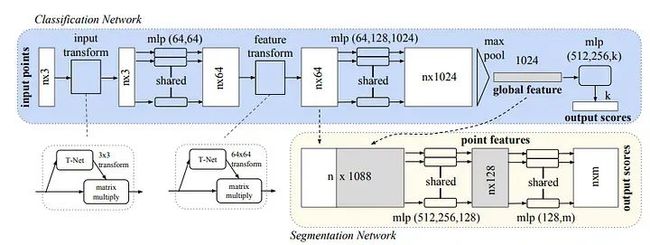
PointNet架构
在提供的代码片段中,MLP_CONV类封装了在批量归一化卷积层的输出上应用ReLU激活的过程。这反映了架构图中描述的卷积和mlp层。让我们更仔细地看一下代码:
# Multi Layer Perceptron
class MLP_CONV(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.conv = nn.Conv1d(self.input_size, self.output_size, 1)
self.bn = nn.BatchNorm1d(self.output_size)
def forward(self, input):
return F.relu(self.bn(self.conv(input)))此类定义对应于架构的构建块,其中卷积层、批量归一化和ReLU激活结合在一起,以实现所需的特征变换。此外,下面描述的FC_BN类在采用全连接层时补充了这个架构。
Fully Connected with Batch Normalizationclass FC_BN(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.lin = nn.Linear(self.input_size, self.output_size)
self.bn = nn.BatchNorm1d(self.output_size)
def forward(self, input):
return F.relu(self.bn(self.lin(input)))这个类进一步说明了如何在PointNet架构中一致应用全连接层与批量归一化和ReLU激活,强调了这些技术在PointNet架构中的一致应用。
输入和特征变换
输入变换网络,一个被标记为TNet的迷你PointNet,对处理原始点云至关重要。它旨在通过一系列操作回归到一个3 × 3矩阵。网络架构由应用于每个点的共享MLP(64, 128, 1024)定义,然后通过点之间的最大池化,以及两个输出大小为512和256的全连接层。得到的矩阵被初始化为一个单位矩阵。每一层,除了最后一层,都包含ReLU激活和批量归一化。第二个变换网络以与第一个相同的方式构建,但输出一个64 × 64矩阵,同样初始化为单位矩阵。为了促使正交性,分类损失的softmax中添加了一个权重为0.001的正则化损失。
TNet类用于根据论文中提供的规格创建变换网络:
Transformation Network (TNet) classclass TNet(nn.Module):
def __init__(self, k=3):
super().__init__()
self.k = k
self.mlp1 = MLP_CONV(self.k, 64)
self.mlp2 = MLP_CONV(64, 128)
self.mlp3 = MLP_CONV(128, 1024)
self.fc_bn1 = FC_BN(1024, 512)
self.fc_bn2 = FC_BN(512, 256)
self.fc3 = nn.Linear(256, k*k)
def forward(self, input):
# input.shape == (batch_size, n, 3)
bs = input.size(0)
xb = self.mlp1(input)
xb = self.mlp2(xb)
xb = self.mlp3(xb)
pool = nn.MaxPool1d(xb.size(-1))(xb)
flat = nn.Flatten(1)(pool)
xb = self.fc_bn1(flat)
xb = self.fc_bn2(xb)
# initialize as identity
init = torch.eye(self.k, requires_grad=True).repeat(bs, 1, 1)
if xb.is_cuda:
init = init.cuda()
matrix = self.fc3(xb).view(-1, self.k, self.k) + init
return matrix这个TNet类封装了将输入点云转换为3×3或64×64矩阵的过程,利用了共享的MLP、最大池化和带有批量归一化的全连接层。
PointNet网络
PointNet网络,封装在PointNet类中,遵循PointNet架构图中提出的设计原则:
class PointNet(nn.Module):
def __init__(self):
super().__init__()
self.input_transform = TNet(k=3)
self.feature_transform = TNet(k=64)
self.mlp1 = MLP_CONV(3, 64)
self.mlp2 = MLP_CONV(64, 128)
# 1D convolutional layer with kernel size 1
self.conv = nn.Conv1d(128, 1024, 1)
# Batch normalization for stability and faster training
self.bn = nn.BatchNorm1d(1024)
def forward(self, input):
n_pts = input.size()[2]
matrix3x3 = self.input_transform(input)
input_transform_output = torch.bmm(torch.transpose(input, 1, 2), matrix3x3).transpose(1, 2)
x = self.mlp1(input_transform_output)
matrix64x64 = self.feature_transform(x)
feature_transform_output = torch.bmm(torch.transpose(x, 1, 2), matrix64x64).transpose(1, 2)
x = self.mlp2(feature_transform_output)
x = self.bn(self.conv(x))
global_feature = nn.MaxPool1d(x.size(-1))(x)
global_feature_repeated = nn.Flatten(1)(global_feature).repeat(n_pts, 1, 1).transpose(0, 2).transpose(0, 1)
return [feature_transform_output, global_feature_repeated], matrix3x3, matrix64x64这个PointNet实现无缝地集成了TNet变换网络、多层感知器(MLP_CONV)和带有批量归一化的一维卷积层。前向传递处理输入和特征变换,然后提取全局特征。生成的张量与变换矩阵一起作为输出返回。
PointNet分割网络
分割网络扩展了分类PointNet。来自第二个变换网络的局部点特征和来自最大池化的全局特征被连接到每个点。在分割网络中不使用dropout,并且训练参数与分类网络保持一致。
对于形状部分分割,修改包括添加指示输入类别的独热向量,与最大池化层的输出连接。某些层中的神经元增加,添加跳过连接以收集不同层中的局部点特征,然后将它们连接以形成分割网络的点特征输入。
class PointNetSeg(nn.Module):
def __init__(self, classes=3):
super().__init__()
self.pointnet = PointNet()
self.mlp1 = MLP_CONV(1088, 512)
self.mlp2 = MLP_CONV(512, 256)
self.mlp3 = MLP_CONV(256, 128)
self.conv = nn.Conv1d(128, classes, 1)
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, input):
inputs, matrix3x3, matrix64x64 = self.pointnet(input)
stack = torch.cat(inputs, 1)
x = self.mlp1(stack)
x = self.mlp2(x)
x = self.mlp3(x)
output = self.conv(x)
return self.logsoftmax(output), matrix3x3, matrix64x64在PointNetSeg类中,前向传递包括从PointNet获得的特征,将它们连接,然后通过一系列的多层感知器(MLP_CONV)和一个卷积层。最终输出在应用LogSoftmax激活后获得。
训练和测试PointNet模型
在我们的模型训练过程中,我们利用了PointNet的强大能力,使用了著名的Semantic-Kitti数据集中的点云。这个有影响力的数据集捕捉了各种城市场景,最初包含约30个标签。然而,为了我们的目的,我们明智地将它们重新映射为三个类别:
Traversable:包括道路、停车场、人行道等。
Not-Traversable:包括汽车、卡车、栅栏、树木、人和各种物体。
Unknown:保留给异常值。
重新映射过程涉及使用键值字典将原始标签转换为它们的简化对应物。为了可视化彩色点云,我们使用了Open3D Python包。左侧图展示了Semantic-Kitti的原始颜色方案,而右侧展示了重新映射的颜色方案。

数据转换
准备数据的关键步骤之一是通过自定义转换进行规范化和张量转换。使用了两个主要的转换:
1. Normalize:这个操作通过减去点云的均值并缩放以确保最大范数为1,将点云居中。
class Normalize(object):
def __call__(self, pointcloud):
assert len(pointcloud.shape)==2
norm_pointcloud = pointcloud - np.mean(pointcloud, axis=0)
norm_pointcloud /= np.max(np.linalg.norm(norm_pointcloud, axis=1))
return norm_pointcloudToTensor:这个转换将点云转换为PyTorch张量。
class ToTensor(object):
def __call__(self, pointcloud):
assert len(pointcloud.shape)==2
return torch.from_numpy(pointcloud)这些转换的组合被封装在default_transforms()函数中。
点云数据集
然后,我们创建了一个自定义数据集PointCloudData,扩展了PyTorch的Dataset类。这个数据集代表了用于训练和测试的点云集合。结构包括:
用数据集详细信息和可选的变换函数进行初始化。
定义数据集的长度。
获取项目,并在指定的情况下应用转换。
class PointCloudData(Dataset):
def __init__(self, dataset_path, transform=default_transforms(), start=0, end=1000):
"""
INPUT
dataset_path: path to the dataset folder
transform : transform function to apply to point cloud
start : index of the first file that belongs to dataset
end : index of the first file that do not belong to dataset
"""
self.dataset_path = dataset_path
self.transforms = transform
self.pc_path = os.path.join(self.dataset_path, "sequences", "00", "velodyne")
self.lb_path = os.path.join(self.dataset_path, "sequences", "00", "labels")
self.pc_paths = os.listdir(self.pc_path)
self.lb_paths = os.listdir(self.lb_path)
assert(len(self.pc_paths) == len(self.lb_paths))
self.start = start
self.end = end
# clip paths according to the start and end ranges provided in input
self.pc_paths = self.pc_paths[start: end]
self.lb_paths = self.lb_paths[start: end]
def __len__(self):
return len(self.pc_paths)
def __getitem__(self, idx):
item_name = str(idx + self.start).zfill(6)
pcpath = os.path.join(self.pc_path, item_name + ".bin")
lbpath = os.path.join(self.lb_path, item_name + ".label")
# load points and labels
pointcloud, labels = readpc(pcpath, lbpath)
# transform
torch_pointcloud = torch.from_numpy(pointcloud)
torch_labels = torch.from_numpy(labels)
return torch_pointcloud, torch_labels
数据集的创建
有了数据集类,我们实例化了训练、验证和测试数据集。这不仅提供了结构化的组织,还为使用PyTorch的DataLoader模块高效使用提供了舞台。
train_ds = PointCloudData(dataset_path, start=0, end=100)
val_ds = PointCloudData(dataset_path, start=100, end=120)
test_ds = PointCloudData(dataset_path, start=120, end=150)DataLoader的利用
利用PyTorch的DataLoader的功能,我们解锁了批处理、洗牌和并行加载等功能。
train_loader = DataLoader(dataset=train_ds, batch_size=5, shuffle=True)
val_loader = DataLoader(dataset=val_ds, batch_size=5, shuffle=False)
test_loader = DataLoader(dataset=test_ds, batch_size=1, shuffle=False)这种对数据集创建和加载的细致方法不仅对基本问题有益,而且在数据集和训练过程的复杂性增加时变得不可或缺。它为在训练和测试期间进行高效、可扩展和并行化的数据处理奠定了基础。
损失函数
在神经网络训练领域,损失函数在引导模型参数更新方面发挥着关键作用。我们的PointNet模型采用了一个精心设计的损失函数,受到以下论文中提供的见解的影响:
"为了使矩阵接近正交,向softmax分类损失添加了一个正则化损失(权重为0.001)。"
该损失函数在代码中表示如下:
def pointNetLoss(outputs, labels, m3x3, m64x64, alpha=0.0001):
criterion = torch.nn.NLLLoss()
bs = outputs.size(0)
id3x3 = torch.eye(3, requires_grad=True).repeat(bs, 1, 1)
id64x64 = torch.eye(64, requires_grad=True).repeat(bs, 1, 1)
# Check if outputs are on CUDA
if outputs.is_cuda:
id3x3 = id3x3.cuda()
id64x64 = id64x64.cuda()
# Calculate matrix differences
diff3x3 = id3x3 - torch.bmm(m3x3, m3x3.transpose(1, 2))
diff64x64 = id64x64 - torch.bmm(m64x64, m64x64.transpose(1, 2))
# Compute the loss
return criterion(outputs, labels) + alpha * (torch.norm(diff3x3) + torch.norm(diff64x64)) / float(bs)损失函数的代码表达如下
输出:模型的预测结果。
标签:实际标签的基准。
m3x3和m64x64:来自PointNet变换网络的矩阵。
alpha:正则化项的权重。
这种精心设计确保我们的PointNet模型不仅在分类精度上表现出色,而且遵循结构约束,在训练过程中提高了其稳健性和泛化性。
训练循环
训练循环是一个程序序列,它迭代地更新PointNet模型的权重。它包括一定数量的纪元,每个纪元包括一个训练阶段和一个可选的验证阶段。在这些阶段中,模型在训练和评估状态之间交替。
def train(pointnet, optimizer, train_loader, val_loader=None, epochs=15, save=True):
best_val_acc = -1.0
for epoch in range(epochs):
pointnet.train()
running_loss = 0.0
# Training phase
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs = inputs.to(device).float()
labels = labels.to(device)
optimizer.zero_grad()
outputs, m3x3, m64x64 = pointnet(inputs.transpose(1, 2))
loss = pointNetLoss(outputs, labels, m3x3, m64x64)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 10 == 9 or True:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 10))
running_loss = 0.0
# Validation phase
pointnet.eval()
correct = total = 0
with torch.no_grad():
for data in val_loader:
inputs, labels = data
inputs = inputs.to(device).float()
labels = labels.to(device)
outputs, __, __ = pointnet(inputs.transpose(1, 2))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) * labels.size(1)
correct += (predicted == labels).sum().item()
print("correct", correct, "/", total)
val_acc = 100.0 * correct / total
print('Valid accuracy: %d %%' % val_acc)
# Save the model if current validation accuracy surpasses the best
if save and val_acc > best_val_acc:
best_val_acc = val_acc
path = os.path.join('', "MyDrive", "pointnetmodel.yml")
print("best_val_acc:", val_acc, "saving model at", path)
torch.save(pointnet.state_dict(), path)
Initialize the optimizeroptimizer = torch.optim.Adam(pointnet.parameters(), lr=0.005)
Commence the trainingtrain(pointnet, optimizer, train_loader, val_loader, save=True)训练循环是一个程序性的序列,迭代地更新PointNet模型的权重。它包括一定数量的时期,每个时期包括训练阶段和一个可选的验证阶段。在这些阶段中,模型在训练和评估状态之间交替。这个循环作为一个系统性的框架,用于更新模型参数、监控损失并在多次迭代中评估性能。
测试
compute_stats函数旨在分析模型在测试阶段的性能。它计算真实标签(unk、trav、nontrav)中不同类别的出现次数,计算总预测次数,并计算正确预测的次数。结果以元组(correct, total_predictions)的形式返回。
def compute_stats(true_labels, pred_labels):
unk = np.count_nonzero(true_labels == 0)
trav = np.count_nonzero(true_labels == 1)
nontrav = np.count_nonzero(true_labels == 2)
total_predictions = labels.shape[1]*labels.shape[0]
correct = (true_labels == pred_labels).sum().item()
return correct, total_predictions结论
PointNet是一种突破性的用于3D分割的工具,克服了无序点集提出的挑战。它的理论基础、架构设计和实际实现展示了其多才多艺和可靠性。通过将理论能力与实际实现相结合,我们揭示了理解和利用PointNet进行3D分割的旅程。PyTorch和Python的整合为在实际应用中探索PointNet的潜力提供了一个实用的框架。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除