yolo yolov2
重点 (Top highlight)
PP-YOLO evaluation metrics show improved performance over YOLOv4, the incumbent state of the art object detection model. Yet, the Baidu authors write:
PP-YOLO评估指标显示,其性能优于现有的最新对象检测模型YOLOv4 。 但是,百度作者写道:
This paper is not intended to introduce a novel object detector. It is more like a recipe, which tell you how to build a better detector step by step.
本文无意介绍一种新颖的物体检测器。 它更像一个食谱,它告诉您如何逐步构建更好的检测器。
Let’s unpack that.
让我们打开包装。
YOLO发展历程 (YOLO Development History)
YOLO was originally authored by Joseph Redmon to detect objects. Object detection is a computer vision technique that localizes and tags objects by drawing a bounding box around them and identifying the class label that a given box belongs too. Unlike massive NLP transformers, YOLO is designed to be tiny, enabling realtime inference speeds for deployment on device.
YOLO最初是由Joseph Redmon创作的,用于检测物体。 对象检测是一种计算机视觉技术,它通过在对象周围绘制边框并标识给定框也属于的类标签来对对象进行定位和标记。 与大型NLP变压器不同,YOLO的体积很小,可为设备上的部署提供实时推理速度。
YOLO-9000 was the second “YOLOv2” object detector published by Joseph Redmon, improving the detector and emphasizing the detectors ability to generalize to any object in the world.
YOLO-9000是约瑟夫·雷德蒙(Joseph Redmon)发布的第二个“ YOLOv2”物体检测器,它改进了检测器并强调了该检测器能够推广到世界上任何物体的能力。
YOLOv3 made further improvements to the detection network and began to mainstream the object detection process. We began to publish tutorials on how to train YOLOv3 in PyTorch, how to train YOLOv3 in Keras, and compared YOLOv3 performance to EfficientDet (another state of the art detector).
YOLOv3进一步完善了检测网络,并开始将物体检测过程纳入主流。 我们开始发布有关如何在PyTorch中训练YOLOv3 , 如何 在Keras中训练YOLOv3的教程,并将YOLOv3的性能与EfficientDet (另一种先进的检测器)进行了比较。
Then Joseph Redmon stepped out of the object detection game due to ethical concerns.
然后,出于道德考虑,约瑟夫·雷德蒙(Joseph Redmon)退出了物体检测游戏。
Naturally, the open source community picked up the baton and continues to move YOLO technology forward.
自然,开源社区接力棒,并继续推动YOLO技术向前发展。
YOLOv4 was published recently this spring by Alexey AB in his for of the YOLO Darknet repository. YOLOv4 was primarily an ensemble of other known computer vision technologies, combined and validated through the research process. See here for a deep dive on YOLOv4. The YOLOv4 paper reads similarly to the PP-YOLO paper, as we will see below. We put together some great training tutorials on how to train YOLOv4 in Darknet.
YOLOv4于今年春天由Alexey AB在YOLO Darknet存储库中发布。 YOLOv4主要是其他已知计算机视觉技术的集合,并通过研究过程进行了组合和验证。 请参阅此处, 深入了解YOLOv4 。 YOLOv4纸的读取方式与PP-YOLO纸类似,如下所示。 我们整理了一些很棒的培训教程, 介绍如何在Darknet中训练YOLOv4 。
Then, just a few months ago YOLOv5 was released. YOLOv5 took the Darknet (C based) training environment and converted the network to PyTorch. Improved training techniques pushed performance of the model even further and created a great, easy to use, out of the box object detection model. Ever since, we have been encouraging developers using Roboflow to direct their attention to YOLOv5 for the formation of their custom object detectors via this YOLOv5 training tutorial.
然后,就在几个月前,发布了YOLOv5 。 YOLOv5采用了Darknet(基于C)的培训环境,并将网络转换为PyTorch。 改进的训练技术进一步提高了模型的性能,并创建了一个出色的,易于使用的现成的对象检测模型。 从那时起,我们一直在鼓励使用Roboflow的开发人员通过此YOLOv5培训教程将注意力转移到YOLOv5上,以形成他们的自定义对象检测器。
Enter PP-YOLO.
输入PP-YOLO。
PP代表什么? (What Does PP Stand For?)
PP is short for PaddlePaddle, a deep learning framework written by Baidu.
PP是百度编写的深度学习框架PaddlePaddle的缩写。

If PaddlePaddle is new to you, then we are in the same boat. Primarily written in Python, PaddlePaddle seems akin to PyTorch and TensorFlow. A deep dive into the PaddlePaddle framework is intriguing, but beyond the scope of this article.
如果PaddlePaddle对您来说是新手,那么我们在同一条船上。 PaddlePaddle主要是用Python编写的,看起来类似于PyTorch和TensorFlow。 对PaddlePaddle框架的深入研究很有趣,但超出了本文的范围。
PP-YOLO贡献 (PP-YOLO Contributions)
The PP-YOLO paper reads much like the YOLOv4 paper in that it is a compilation of techniques that are known to work in computer vision. The novel contribution is to prove that the ensemble of these technologies improves performance, and to provide an ablation study of how much each step helps the model along the way.
PP-YOLO纸的读法与YOLOv4纸非常相似,因为它是计算机视觉中已知的技术的汇总。 新颖的贡献是证明这些技术的集成可提高性能,并提供消融研究,以了解每一步对模型的帮助程度。
Before we dive into the contributions of PP-YOLO, it will be useful to review the YOLO detector architecture.
在我们深入探讨PP-YOLO的贡献之前,有必要回顾一下YOLO检测器的架构。
YOLO检测器的解剖 (Anatomy of the YOLO Detector)

The YOLO detector is broken into three main pieces.
YOLO检测器分为三个主要部分。
YOLO Backbone — The YOLO backbone is a convolutional neural network that pools image pixels to form features at different granularities. The Backbone is typically pretrained on a classification dataset, typically ImageNet.
YOLO骨干网 — YOLO骨干网是一个卷积神经网络,它将图像像素合并以形成不同粒度的特征。 骨干通常在分类数据集(通常为ImageNet)上进行预训练。
YOLO Neck — The YOLO neck (FPN is chosen above) combines and mixes the ConvNet layer representations before passing on to the prediction head.
YOLO脖子— YOLO脖子(上面选择了FPN)在传递到预测头之前对ConvNet图层表示进行组合和混合。
YOLO Head — This is the part of the network that makes the bounding box and class prediction. It is guided by the three YOLO loss functions for class, box, and objectness.
YOLO Head —这是网络中进行边界框和类预测的部分。 它由关于类,框和对象的三个YOLO损失函数指导。
现在,让我们深入了解PP YOLO贡献。 (Now let’s dive into the PP YOLO Contributions.)

更换骨干网 (Replace Backbone)
The first PP YOLO technique is to replace the YOLOv3 Darknet53 backbone with the Resnet50-vd-dcn ConvNet backbone. Resnet is a more popular backbone, more frameworks are optimized for its execution, and it has fewer parameters than Darknet53. Seeing a mAP improvement by swapping this backbone is a huge win for PP YOLO.
第一种PP YOLO技术是用Resnet50-vd-dcn ConvNet主干替换YOLOv3 Darknet53主干。 Resnet是一个更流行的主干,它的执行优化了更多的框架,并且其参数少于Darknet53。 交换此主干可以看到mAP的改进,这对PP YOLO来说是一个巨大的胜利。
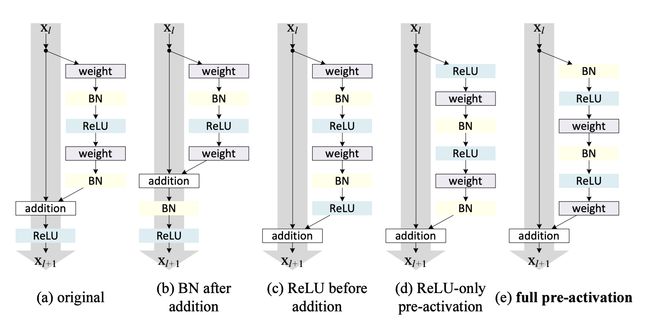
模型参数的EMA (EMA of Model Parameters)
PP YOLO tracks the Exponential Moving Average of network parameters to maintain a shadow of the models weights for prediction time. This has been shown to improve inference accuracy.
PP YOLO跟踪网络参数的指数移动平均值,以保持预测时间的模型权重的阴影。 已经证明这可以提高推理精度。
批量更大 (Larger Batch Size)
PP-YOLO bumps the batch size up from 64 to 192. Of course, this is hard to implement if you have GPU memory constraints.
PP-YOLO的批量大小从64增加到192。当然,如果您有GPU内存限制,则很难实现。
DropBlock正则化 (DropBlock Regularization)
PP YOLO implements DropBlock regularization in the FPN neck (in the past, this has usually occurred in the backbone). DropBlock randomly removes a block of the training features at a given step in the network to teach the model to not rely on key features for detection.
PP YOLO在FPN脖子上实现DropBlock正则化(过去,这通常发生在主干中)。 在网络的给定步骤中,DropBlock会随机删除一部分训练功能,以指示模型不依赖于关键特征进行检测。

IOU损失 (IoU Loss)
The YOLO loss function does not translate well to the mAP metric, which uses the Intersection over Union heavily in its calculation. Therefore, it is useful to edit the training loss function with this end prediction in mind. This edit was also present in YOLOv4.
YOLO损失函数不能很好地转换为mAP指标 ,该指标在计算中大量使用了Union上的Intersection。 因此,考虑到此结束预测来编辑训练损失函数很有用。 此编辑也出现在YOLOv4中。
IoU意识 (IoU Aware)
The PP-YOLO network adds a prediction branch to predict the model’s estimated IOU with a given object. Including this IoU awareness when making the decision to predict an object or not improves performance.
PP-YOLO网络添加了一个预测分支,以预测给定对象的模型估计的IOU。 在决定是否预测对象时包含此IoU意识可提高性能。
电网灵敏度 (Grid Sensitivity)
The old YOLO models do not do a good job of making predictions right around the boundaries of anchor box regions. It is useful to define box coordinates slightly differently to avoid this problem. This technique is also present in YOLOv4.
旧的YOLO模型不能很好地在锚框区域的边界附近进行预测 。 定义盒子坐标稍有不同是很有用的,以避免此问题。 YOLOv4中也存在此技术。
矩阵网管 (Matrix NMS)
Non-Maximum Suppression is a technique to remove over proposals of candidate objects for classification. Matrix NMS is a technique to sort through these candidate predictions in parallel, speeding up the calculation.
非最大抑制是一种删除候选对象的提议以进行分类的技术。 矩阵NMS是一项技术,可以对这些候选预测进行并行排序,从而加快了计算速度。
协调转换 (CoordConv)
CoordConv was motivated by the problems ConvNets were having with simply mapping (x,y) coordinates to a one-hot pixel space. The CoordConv solution gives the convolution network access to its own input coordinates. CoordConv interventions are marked with yellow diamonds above. More details are available in the CordConv paper.
ConordNet的灵感来自于ConvNets仅将(x,y)坐标映射到一个热像素空间所遇到的问题。 CoordConv解决方案使卷积网络可以访问其自己的输入坐标。 CoordConv干预措施上方标有黄色菱形。 有关更多详细信息,请参见CordConv文件 。
SPP (SPP)
Spatial Pyramid Pooling is an extra block after the backbone layer to mix and pool spatial features. Also implemented in YOLOv4 and YOLOv5.
空间金字塔池化是主干层之后的一个额外块,用于混合和合并空间特征。 也已在YOLOv4和YOLOv5中实现。
更好的预训练骨干 (Better Pretrained Backbone)
The PP YOLO authors distilled down a larger ResNet model to serve as the backbone. A better pretrained model shows to improve downstream transfer learning as well.
PP YOLO的作者提炼出更大的ResNet模型作为骨干。 更好的预训练模型显示也可以改善下游转移学习。
PP-YOLO是最先进的吗? (Is PP-YOLO State of the Art?)
PP-YOLO outperforms the results YOLOv4 published on April 23, 2020.
PP-YOLO胜过2020年4月23日发布的YOLOv4结果。
In fairness, the authors note this may be the wrong question to be asking. The authors’ intent appears to not simply “introduce a new novel detector,” rather to show the process of carefully tuning an object detector to maximize performance. Quoting the paper’s introduction here:
公平地说,作者指出这可能是一个错误的问题。 作者的意图似乎不只是“引入一种新颖的新型检测器”,而是表明仔细调整对象检测器以最大化性能的过程。 在此处引用本文的介绍:
The focus of this paper is how to stack some effective tricks that hardly affect efficiency to get better performance… This paper is not intended to introduce a novel object detector. It is more like a recipe, which tell you how to build a better detector step by step. We have found some tricks that are effective for the YOLOv3 detector, which can save developers’ time of trial and error. The final PP-YOLO model improves the mAP on COCO from 43.5% to 45.2% at a speed faster than YOLOv4
本文的重点是如何堆叠一些几乎不影响效率的有效技巧以获得更好的性能……本文无意介绍一种新颖的目标检测器。 它更像一个食谱,它告诉您如何逐步构建更好的检测器。 我们发现了一些对YOLOv3检测器有效的技巧,可以节省开发人员的反复试验时间。 最终的PP-YOLO模型以比YOLOv4更快的速度将COCO的mAP从43.5%提高到45.2%
(emphasis ours)
(强调我们的)
The PP-YOLO contributions reference above took the YOLOv3 model from 38.9 to 44.6 mAP on the COCO object detection task and increased inference FPS from 58 to 73. These metrics are shown in the paper to beat the currently published results for YOLOv4 and EfficientDet.
上面的PP-YOLO贡献参考将YOLOv3模型在COCO对象检测任务上从38.9 mAP提升到44.6 mAP,并将推理FPS从58增加到73。论文中显示了这些指标,胜过了YOLOv4和EfficientDet的当前发布结果。
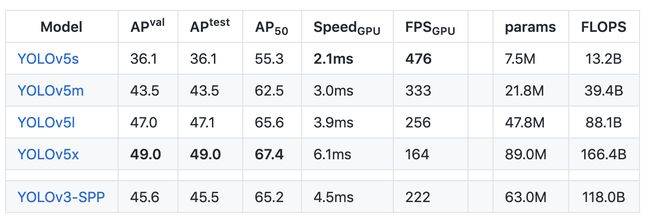
In benchmarking PP-YOLO against YOLOv5, it appears YOLOv5 still has the fastest inference time-to-accuracy performance (AP vs FPS) tradeoff on a V100. However, a YOLOv5 paper still remains to be released. Furthermore, it has been shown that training the YOLOv4 architecture on the YOLOv5 Ultralytics repository outperforms YOLOv5 and, transitively, YOLOv4 trained using YOLOv5 contributions would outperform the PP-YOLO results posted here. These results are still to be formally published but can be traced to this GitHub discussion.
在以YOLOv5为基准对PP-YOLO进行基准测试时,似乎YOLOv5在V100上仍具有最快的推理准确度(AP与FPS)折衷。 但是,YOLOv5论文仍然有待发布。 此外,已经表明,在YOLOv5 Ultralytics存储库上训练YOLOv4体系结构的性能要优于YOLOv5,并且,以可移植的方式,使用YOLOv5贡献进行训练的YOLOv4的性能将胜过此处发布的PP-YOLO结果。 这些结果仍有待正式发布,但可以追溯到GitHub上的讨论 。

It is worth noting that many of the techniques (such as architecture search and data augmentation) that were used in YOLOv4 were not used in PP YOLO. This means that there is still room for the state of the art in object detection to grow as more of these techniques are combined and integrated together.
值得注意的是,在YOLOv4中使用的许多技术(例如体系结构搜索和数据增强)在PP YOLO中并未使用。 这意味着,随着更多的这些技术被组合和集成在一起,在物体检测领域中仍存在发展的空间。
Needless to say, is an exciting time to be implementing computer vision technologies.
毋庸置疑,这是实施计算机视觉技术的激动人心的时刻。
我应该从YOLOv4或YOLOv5切换到PP-YOLO吗? (Should I Switch from YOLOv4 or YOLOv5 to PP-YOLO?)
The PP-YOLO model shows the promise of state of the art object detection, but the improvements are incremental over other object detectors and it is written in a new framework. At this stage, the best thing to do is to develop your own empirical result by training PP-YOLO on your own dataset. (To be notified when you can easily use PP-YOLO on your dataset, subscribe to our newsletter.)
PP-YOLO模型显示了最先进的对象检测技术的前景,但是与其他对象检测器相比,这些改进是递增的,并且是在一个新的框架中编写的。 在此阶段,最好的办法是通过在自己的数据集上训练PP-YOLO来开发自己的经验结果。 (要在可以轻松在数据集中使用PP-YOLO时收到通知,请订阅我们的新闻通讯 。)
In the meantime, I recommend checking out the following YOLO tutorials to get your object detector off the ground:
同时,我建议您查看以下YOLO教程,以使您的物体检测器成为现实:
How to Train YOLOv4 in Darknet
如何在Darknet中训练YOLOv4
How to Train YOLOv5 in PyTorch
如何在PyTorch中训练YOLOv5
As always — happy training!
一如既往-培训愉快!
翻译自: https://towardsdatascience.com/pp-yolo-surpasses-yolov4-object-detection-advances-1efc2692aa62
yolo yolov2