在浏览器中进行深度学习:TensorFlow.js (八)生成对抗网络 (GAN)
Generative Adversarial Network 是深度学习中非常有趣的一种方法。GAN 最早源自 Ian Goodfellow 的这篇论文。LeCun 对 GAN 给出了极高的评价:
“There are many interesting recent development in deep learning…The most important one, in my opinion, is adversarial training (also called GAN for Generative Adversarial Networks). This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.” – Yann LeCun
那么我们就看看 GAN 究竟是怎么回事吧:
GAN 包含两个互相对抗的网络:G(Generator)和 D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
- Generator 是一个生成器的网络,它接收一个随机的噪声,通过这个噪声生成图片,记做 G (z)。
- Discriminator 是一个鉴别器网络,判别一张图片或者一个输入是不是 “真实的”。它的输入 x 是数据或者图片,输出 D(x)代表 x 为真实图片的概率,如果为 1,就代表 100% 是真实的图片,而输出为 0,就代表不可能是真实的图片。
在训练过程中,生成网络 G 的目标就是尽量生成真实的图片去欺骗判别网络 D。而 D 的目标就是尽量把 G 生成的图片和真实的图片分别开来。这样,G 和 D 构成了一个动态的 “博弈过程”。在最理想的状态下,G 可以生成足以 “以假乱真” 的图片 G (z)。对于 D 来说,它难以判定 G 生成的图片究竟是不是真实的,因此 D (G (z)) = 0.5。
最后,我们就可以使用生成器和随机输入来生成不同的数据或者图片了。
上面的描述大家可能都能理解,但是把它变成数学语言,可能你就蒙 B 了。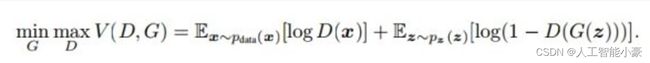
如上图所示,x 是输入,z 是随机噪声。D (x) 是鉴别器的判定数据为真的概率,D (G (z)) 是判定生成数据为真的概率。生成器希望这个 D (G (z)) 越大越好,这个时候整个表达式的值应该变小。而鉴别器的目的是能够有效区分真实数据和假数据,所以 D (x) 应该趋向于变大,D (G (z)) 趋向于变小,整个表达式就变大。也就是说训练过程,生成器和辨别器互相对抗,一个使上述表达式变小,另一个使其变大,最后训练趋向于平衡,而生成器这时候应该生成真假难辨的数据,这就是我们的最终目的。

上图是 GAN 算法训练的具体过程,这里我们不做过多的解释,直接运行一个例子。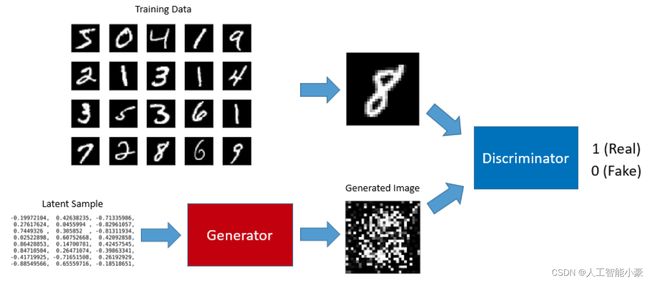
我们用 MINST 数据集来看看如何使用 TensorflowJS 来训练一个 GAN,模拟生成手写数字。
function gen(xs) {
const l1 = tf.leakyRelu(xs.matMul(G1w).add(G1b));
const l2 = tf.leakyRelu(l1.matMul(G2w).add(G2b));
const l3 = tf.tanh(l2.matMul(G3w).add(G3b));
return l3;
}
function disReal(xs) {
const l1 = tf.leakyRelu(xs.matMul(D1w).add(D1b));
const l2 = tf.leakyRelu(l1.matMul(D2w).add(D2b));
const logits = l2.matMul(D3w).add(D3b);
const output = tf.sigmoid(logits);
return [logits, output];
}
function disFake(xs) {
return disReal(gen(xs));
}GAN 的两个网络分别用 gen 和 disReal 创建。gen 是生成器网络,disReal 是辨别器的网络。disFake 是把生成数据用辨别器来辨别。这里的网络使用 leakyrelu。使得输出在 - inf 到 + inf,利用 sigmoid 映射到【0,1】,这是辨别器模型输出一个 0-1 之间的概率。
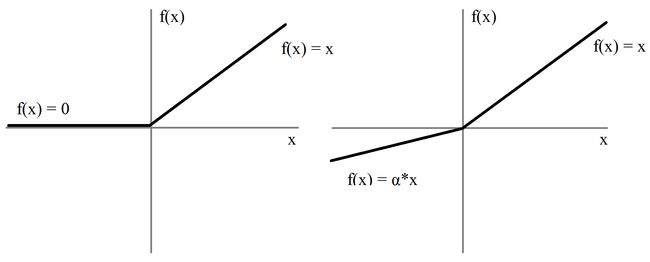
通常我们会创建一个比生成器更复杂的鉴别器网络使得鉴别器有足够的分辨能力。但在这个例子里,两个网络的复杂程度类似。
计算损失的函数使用 tf.sigmoidCrossEntropyWithLogits,值得注意的是,在最新的 0.13 版本中,这个交叉熵被移除了,你需要自己实现该方法。
训练过程如下:
async function trainBatch(realBatch, fakeBatch) {
const dcost = dOptimizer.minimize(
() => {
const [logitsReal, outputReal] = disReal(realBatch);
const [logitsFake, outputFake] = disFake(fakeBatch);
const lossReal = sigmoidCrossEntropyWithLogits(ONES_PRIME, logitsReal);
const lossFake = sigmoidCrossEntropyWithLogits(ZEROS, logitsFake);
return lossReal.add(lossFake).mean();
},
true,
[D1w, D1b, D2w, D2b, D3w, D3b]
);
await tf.nextFrame();
const gcost = gOptimizer.minimize(
() => {
const [logitsFake, outputFake] = disFake(fakeBatch);
const lossFake = sigmoidCrossEntropyWithLogits(ONES, logitsFake);
return lossFake.mean();
},
true,
[G1w, G1b, G2w, G2b, G3w, G3b]
);
await tf.nextFrame();
return [dcost, gcost];
}训练使用了两个 optimizer,
- 第一步,计算实际数据的辨别结果和 1 的交叉熵,以及生成器生成数据的辨别结果和 0 的交叉熵。也就是说,我们希望辨别器尽可能的判断出生成数据都是假的而实际数据都是真的。使得这两个交叉熵的均值最小。
- 第二步开始对抗,要让生成数据尽可能被判别为真。
下图是某个训练过程的损失:
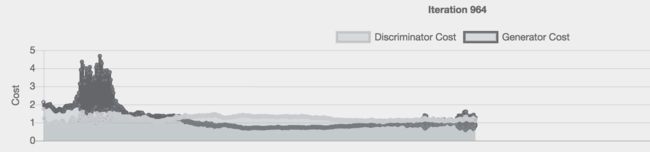
这个是经过 1000 个迭代后的生成图:
![]()
大家可以尝试调整学习率,增加网络复杂度,加大迭代次数来获得更好的生成模型。
GAN 的学习其实还是比较复杂的,参数和损失选择都不容易,好在有一些现成的工具可以使用,另外推荐大家去 https://poloclub.github.io/ganlab/,提供了很直观的 GAN 学习的过程。这个也是用 TensorflowJS 来实现的。