【论文笔记】Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Application
Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
原文链接:https://arxiv.org/abs/2311.17663
I. 引言
现有的基于相机的占用估计方法仅估计当前和过去的占用状态,但自动驾驶汽车需要未来的环境条件。本文提出首个相机4D占用预测基准Cam4DOcc,包含数据集的新格式、各种基准方案,以及标准化的评估协议。数据集包含序列的语义和实例标签以及占用网格的反向向心流;基准方案包括静态世界占用模型、点云体素预测、2D-3D基于实例的预测,已经端到端4D占用预测网络。
III. Cam4DOcc基准
A. 任务定义
给定 N p N_p Np帧过去的和当前的连续相机图像 I = { I t } t = − N p 0 \mathcal{I}=\{I_t\}_{t=-N_p}^0 I={It}t=−Np0,4D占用预测的目标是输出当前占用 O c ∈ R 1 × H × W × L O_c\in\mathbb{R}^{1\times H\times W\times L} Oc∈R1×H×W×L和未来 N f N_f Nf帧的占用 O f ∈ R N f × H × W × L O_f\in\mathbb{R}^{N_f\times H\times W\times L} Of∈RNf×H×W×L。其中 H , W , L H,W,L H,W,L为当前帧坐标系下的坐标范围。 O f O_f Of的每个体素有 N f N_f Nf个连续状态 S = { S t } t = 1 N f \mathcal{S}=\{S_t\}_{t=1}^{N_f} S={St}t=1Nf,以表达在每一帧是否被占用。
基于运动情况,Cam4DOcc考虑两种物体类别,可运动的物体(GMO)和静态物体(GSO)。注意本文关注可运动物体的体素状态变化情况,故没有考虑更细分的语义类别(实际上物体的运动情况比起类别也更加重要)。
B. 新格式下的数据集
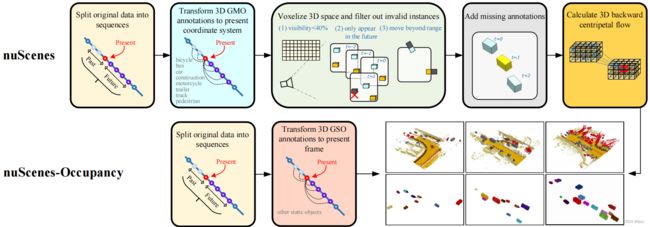
首先将原始nuScenes数据集分割为时间长度为 N = N p + N f + 1 N=N_p+N_f+1 N=Np+Nf+1的序列,并将其语义和实例标签收集到GMO类别中,并转换到当前帧坐标系下。然后体素化当前帧3D空间,使用边界框标注为体素分配标签。当一个实例满足下列条件之一时,会被丢弃不予考虑:(1)在 N p N_p Np个过去帧中新出现,在6个图像中可见性在40%以下(可见性通过该实例在图像中,像素的可视比例来量化);(2)首先在 N f N_f Nf帧未来帧中出现;(3)超出了当前帧下预定义的范围 ( H , W , L ) (H,W,L) (H,W,L)。对于缺失的中间帧实例(非关键帧),使用恒定速度假设得到序列标注。最后,使用实例关联标注生成3D反向向心流(从时间 t t t的体素指向 t − 1 t-1 t−1时刻相应的实例中心)。
为得到GSO的标注,将nuScenes的序列实例标签与nuScenes-Occupancy的序列占用标签(转换到当前帧下)合并。
C. 评估协议
多任务:提出4级占用预测任务:(1)预测膨胀的GMO:原始数据集边界框内的体素均视为GMO,其余体素视为“其它”类别;(2)预测细粒度的GMO:GMO标签来自nuScenes-Occupancy的细粒度标签,其余体素视为“其它”类别;(3)预测膨胀的GMO、细粒度的GSO和空体素;(4)预测细粒度的GMO和GSO、空体素。
指标:使用IoU衡量,并将当前帧和未来帧分开:
I o U c ( O ^ c , O c ) = ∑ H , W , L S ^ c ⋅ S c ∑ H , W , L S ^ c + S c − S ^ c ⋅ S c I o U f ( O ^ f , O f ) = 1 N f ∑ t = 1 N f ∑ H , W , L S ^ t ⋅ S t ∑ H , W , L S ^ t + S t − S ^ t ⋅ S t IoU_c(\hat{O}_c,O_c)=\frac{\sum_{H,W,L}\hat{S}_c\cdot S_c}{\sum_{H,W,L}\hat{S}_c+S_c-\hat{S}_c\cdot S_c}\\ IoU_f(\hat{O}_f,O_f)=\frac{1}{N_f}\sum_{t=1}^{N_f}\frac{\sum_{H,W,L}\hat{S}_t\cdot S_t}{\sum_{H,W,L}\hat{S}_t+S_t-\hat{S}_t\cdot S_t} IoUc(O^c,Oc)=∑H,W,LS^c+Sc−S^c⋅Sc∑H,W,LS^c⋅ScIoUf(O^f,Of)=Nf1t=1∑Nf∑H,W,LS^t+St−S^t⋅St∑H,W,LS^t⋅St
其中 S ^ t \hat{S}_t S^t与 S t S_t St分别为 t t t时刻预测的和真实的占用状态。
此外,还使用单一定量指标衡量整个时间段的预测性能:
I o U ~ f ( O ^ f , O f ) = 1 N f ∑ t = 1 N f 1 t ∑ k = 1 t ∑ H , W , L S ^ k ⋅ S k ∑ H , W , L S ^ k + S k − S ^ k ⋅ S k \tilde{IoU}_f(\hat{O}_f,O_f)=\frac{1}{N_f}\sum_{t=1}^{N_f}\frac{1}{t}\sum_{k=1}^t\frac{\sum_{H,W,L}\hat{S}_k\cdot S_k}{\sum_{H,W,L}\hat{S}_k+S_k-\hat{S}_k\cdot S_k} IoU~f(O^f,Of)=Nf1t=1∑Nft1k=1∑t∑H,W,LS^k+Sk−S^k⋅Sk∑H,W,LS^k⋅Sk
这样,离当前帧越近的占用预测在该指标中会占比越大,因为时间近的预测对运动规划更加重要。
D. 基准方案

如上图所示,本文提出了4种基准方案。
静态世界占用模型:由于现有的占用预测方法只能基于当前帧的观测估计当前帧的占用网格,因此本文引入静态世界假设,以当前帧的占用预测结果作为未来一段时间内的预测。
体素化点云预测:现有的点云预测方法预测的点云可以体素化得到占用。本文首先估计环视图深度,然后进行射线投射操作预测点云。然后使用语义分割模型将体素分类为可运动物体和静态物体。
2D-3D基于实例的预测:现有的基于BEV的实例预测方法可以预测一段时间内的语义。本文将预测的GMO提升到3D空间(假设地面平整且各实例高度相同)。评估时,不进行GSO的评估。
端到端占用预测网络:上述方法均需要基于某些假设进行额外的后处理。本文提出端到端预测方法,详见第IV节。
IV. 端到端4D占用预测
本文提出端到端时空网络OCFNet,如下图所示。该网络使用多帧特征聚合模块提取体素特征,并使用未来状态预测模块预测未来占用和3D反向向心流。
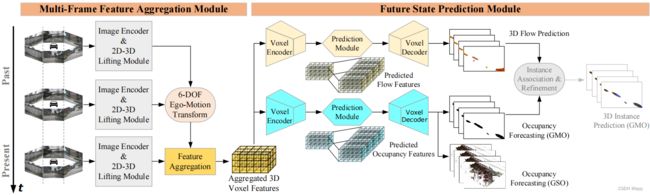
A. 多帧特征聚合模块
使用图像编码主干提取环视图图像序列的2D特征,并通过2D-3D提升模块提升和整合为3D体素特征。通过应用自车当前帧的6自由度姿态,将各帧的体素与相邻帧的自车相对姿态(6自由度)拼接,再聚合得到 F p m ∈ R ( N p + 1 ) ( c + 6 ) × h × w × l F_{pm}\in\mathbb{R}^{(N_p+1)(c+6)\times h\times w\times l} Fpm∈R(Np+1)(c+6)×h×w×l。后续会使用3D时空卷积处理 F p m F_{pm} Fpm。
B. 未来状态预测模块
使用两个头预测占用状态和网格运动。首先,体素编码器将 F p m F_{pm} Fpm下采样为多尺度特征 F p m i ∈ R ( N p + 1 ) c i × h 2 i × w 2 i × l 2 i , i = 0 , 1 , 2 , 3 F_{pm}^i\in\mathbb{R}^{(N_p+1)c_i\times \frac{h}{2^i}\times \frac{w}{2^i}\times \frac{l}{2^i}},i=0,1,2,3 Fpmi∈R(Np+1)ci×2ih×2iw×2il,i=0,1,2,3。然后使用3D残差卷积块扩展通道维度,得到 F p f i ∈ R ( N f + 1 ) c i × h 2 i × w 2 i × l 2 i F_{pf}^i\in\mathbb{R}^{(N_f+1)c_i\times \frac{h}{2^i}\times \frac{w}{2^i}\times \frac{l}{2^i}} Fpfi∈R(Nf+1)ci×2ih×2iw×2il。使用体素解码器上采样各尺度特征并拼接。占用预测头使用softmax函数产生粗糙的占用特征 F f o c c ∈ R ( N f + 1 ) × c l s × h × w × l F_f^{occ}\in\mathbb{R}^{(N_f+1)\times cls\times h\times w\times l} Ffocc∈R(Nf+1)×cls×h×w×l。流预测头使用 1 × 1 1\times1 1×1卷积产生粗糙流特征 F f f l o w ∈ R ( N f + 1 ) × 3 × h × w × l F_f^{flow}\in\mathbb{R}^{(N_f+1)\times3\times h\times w\times l} Ffflow∈R(Nf+1)×3×h×w×l。最后对 F f o c c F^{occ}_f Ffocc与 F f f l o w F^{flow}_f Ffflow使用三线性插值,并对预测占用的状态维度使用argmax操作,得到最终的占用估计 O ^ t ∈ R ( N f + 1 ) × H × W × L \hat{O}_t\in\mathbb{R}^{(N_f+1)\times H\times W\times L} O^t∈R(Nf+1)×H×W×L和基于流的运动估计 M ^ t ∈ R ( N f + 1 ) × 3 × H × W × L \hat{M}_t\in\mathbb{R}^{(N_f+1)\times3\times H\times W\times L} M^t∈R(Nf+1)×3×H×W×L。
C. 损失函数
使用交叉熵损失作为占用预测损失、 l 1 l_1 l1损失作为流预测损失。显式深度损失仅用于监督当前帧的占用,以提高效率并减小存储。总损失如下:
L a l l = 1 N f + 1 ( ∑ t = 0 N f λ 1 L o c c ( O ^ t , O t ) + λ 2 L f l o w ( M ^ t , M t ) + λ 3 L d e p t h ( D ^ 0 , D 0 ) ) L_{all}=\frac{1}{N_f+1}(\sum_{t=0}^{N_f}\lambda_1L_{occ}(\hat{O}_t,O_t)+\lambda_2L_{flow}(\hat{M}_t,M_t)+\lambda_3L_{depth}(\hat{D}_0,D_0)) Lall=Nf+11(t=0∑Nfλ1Locc(O^t,Ot)+λ2Lflow(M^t,Mt)+λ3Ldepth(D^0,D0))
其中 D ^ 0 \hat{D}_0 D^0与 D 0 D_0 D0为2D-3D提升模块的深度估计结果和对应的真值(通过激光雷达点云投影获取)。
V. Cam4DOcc上的实验
B. 4D占用预测评估
膨胀GMO预测的评估:所有方法使用膨胀GMO训练(基准方案2使用真实点云训练)。实验表明本文的方法能大幅超过其余方法的性能。使用少量训练数据训练本文的OCFNet也能达到较好的性能。基准方案2的效果不佳,因为其直接从细粒度的点云体素化得到结果,且损失了连续帧的物体形状一致性。基准方案1的性能比基准方案2和3的性能高,因其有一定估计当前帧占用的能力。
细粒度GMO预测的评估:与膨胀GMO预测的结果相比,除了基准方案2,所有方法均有较大的性能下降,因为细粒度的3D运动结构估计十分困难。基准方案2的性能略有提升,因为真值同样为细粒度的。然而其性能仍然是所有方法中最差的。OCFNet的方法仍最优。上述实验表明,使用相机进行膨胀GMO的预测有更高的可靠性,而细粒度GMO的预测十分困难。
膨胀GMO、细粒度GSO和空体素预测的评估:基准方案2仍然最差,且OCFNet大幅超过基准方案1的性能(因为聚合了过去帧的特征,且未使用静态场景假设)。由于nuScenes-Occpancy真值的抖动,基准方案1和OCFNet的未来帧的GSO预测比当前帧的预测精度略高。
细粒度GMO、细粒度GSO和空体素预测的评估:OCFNet的方法仍然最优。与实验2相比,基准方案1和OCFNet的GMO性能略有下降,因为细粒度的GSO引入了额外伪影。
C. 多任务学习的消融研究
实验表明,比起无流预测头的模型,完整的OCFNet在当前帧和未来帧的占用预测性能均有提升。这是因为3D流指导GMO运动的学习,帮助网络决定占用的变化。
补充材料
A. 数据集设置细节
细粒度GMO在某些情况下不能精确表示GMO的复杂形状,且可能丢失一些被遮挡的物体。
B. OCFNet模型细节
使用ResNet50+FPN作为图像编码器。使用基于LSS的2D-3D提升模块。体素解码器使用3D ResNet18和3D FPN。预测模块如下图所示。
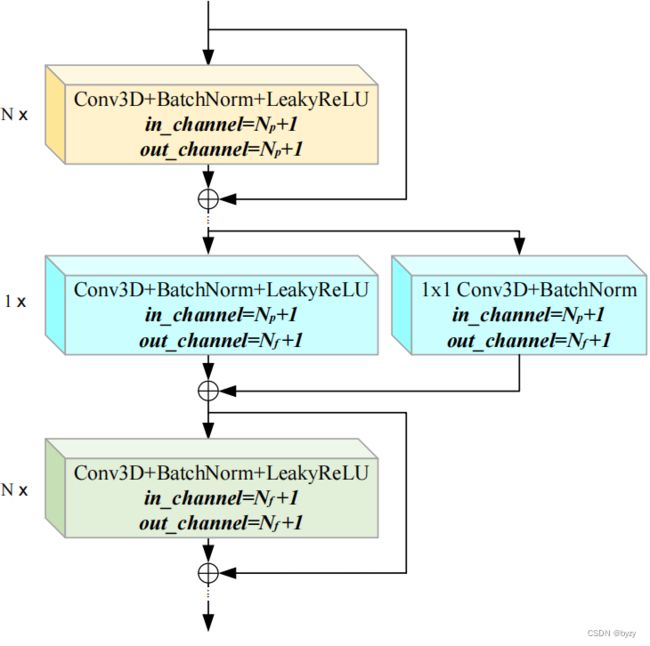
为将占用预测扩展为3D实例预测,首先从当前帧的预测占用中寻找局部极大值,确定实例中心,然后通过预测流相继关联未来帧的实例。
C. 未来时间范围的研究
改变未来预测的时间范围,OCFNet仍能有最好的性能,且对所有方法,时间范围越小,性能越好。
D. 3D流预测
可视化表明,运动物体的预测流向量大致从下一帧的体素指向上一帧相同实例的中心,从而能指导网络显式捕捉GMO的运动或实现相邻帧实例关联。
E. 3D实例预测
通过在当前时刻使用NMS提取实例中心,然后使用预测的3D反向向心流,在未来帧关联逐像素的实例ID。将2D实例预测的视频全景质量(VPQ)扩展到3D实例预测,以评估性能:
VPQ f ( O ^ f i n s t , O f i n s t ) = 1 N f ∑ t = 0 N f ∑ ( p t , q t ) ∈ T P t IoU ( p t , q t ) ∣ T P t ∣ + 1 2 ∣ F P t ∣ + 1 2 ∣ F N t ∣ \text{VPQ}_f(\hat{O}^{inst}_f,O^{inst}_f)=\frac{1}{N_f}\sum_{t=0}^{N_f}\frac{\sum_{(p_t,q_t)\in TP_t}\text{IoU}(p_t,q_t)}{|TP_t|+\frac{1}{2}|FP_t|+\frac{1}{2}|FN_t|} VPQf(O^finst,Ofinst)=Nf1t=0∑Nf∣TPt∣+21∣FPt∣+21∣FNt∣∑(pt,qt)∈TPtIoU(pt,qt)
与基准方案3相比,本文的方法性能略低,因为2D反向向心流比3D反向向心流更易估计。若OCFNet使用基准方案3估计的GMO反向向心流(若无,则使用OCFNet自己估计的结果),则性能会超过基准方案3。
F. 未来GMO占用预测的可视化
可视化表明,对于小尺度的场景,使用少量数据训练的OCFNet能精确捕捉其运动;而对于大尺度的场景,使用更多数据训练能大幅提高性能。因此,在可动障碍较少的场景下,使用少量的数据训练的模型足以预测占用情况。