MYSQL优化汇总——学习入口
mysql优化的方式总的有以下几种方式
1.msql服务器硬件的优化;单核CPU变成多核,加内存,这一般是运维干的事情。
2.mysql服务的配置参数的优化;
3.sql语句本身的优化;
4.数据库设计时的范式设计;
5.索引优化;
以上五点我们今天主要说说后面的四种,请听我慢慢碎碎
1 mysql服务的配置参数优化
1.1 max_connections最大连接数
MySQL的最大连接数
如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,MySql会为每个连接提供连接缓冲区,就会开销越多的内存,连接数太大,服务器消耗的内存越多,以至于影响服务器性能,所以要根据服务器的配置适当调整该值,不能盲目提高设值。可以过’conn%'通配符查看当前状态的连接数量,以定夺该值的大小。下面给大家一个公式参考设置,但是mysql最大连接数不能超过1000,超过了操作系统不支持了
max_used_connections / max_connections * 100%(理想值≈ 85%),如果max_used_connections跟max_connections相同,那么就是max_connections设置过低或者超过服务器负载上限了,低于10%则设置过大
mysql> show status like 'max_used_connections'; #响应的连接数
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 609 |
+----------------------+-------+
1 row in set (0.02 sec)
mysql> show variables like 'max_connections'; #最大连接数
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 800 |
+-----------------+-------+
1 row in set (0.02 sec)
1.2 back_log MySQL能暂存的连接数量
当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用。如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
back_log值指出在MySQL暂时停止回答新请求之前的短时间内有多少个请求可以被存在堆栈中。只有如果期望在一个短时间内有很多连接,你需要增加它,换句话说,这值对到来的TCP/IP连接的侦听队列的大小。
mysql中back_log的设置取决于操作系统,在Linux下这个参数的值不能大于系统参数tcp_max_syn_backlog的值。通过以下命令可以查看tcp_max_syn_backlog的当前值 cat /proc/sys/net/ipv4/tcp_max_syn_backlog。 >默认数值是50,可调优为128。
mysql> show variables like 'back_log%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| back_log | 211 |
+---------------+-------+
1 row in set (0.02 sec)
1.3 thread_cache_size 线程池大小
可以复用的保存在内存中的线程的数量。如果有,新的线程从缓存中取得,当断开连接的时候如果有空间,客户的线置将保存在缓存中。如果有很多新的线程,为了提高性能可以增加这个变量值。通过比较 Connections和Threads_created状态的变量,可以看到这个变量的作用,如下:
mysql> show global status like ‘Thread%’;
+——————-+———-+
| Variable_name | Value |
+——————-+———-+
| Threads_cached | 26 |
| Threads_connected | 510 |
| Threads_created | 35168165 |
| Threads_running | 459 |
+——————-+———-+
4 rows in set (0.01 sec)Threads_cached :代表当前此时此刻线程缓存中有多少空闲线程。
Threads_connected :代表当前已建立连接的数量,因为一个连接就需要一个线程,所以也可以看成当前被使用的线程数。 Threads_created :代表从最近一次服务启动,已创建线程的数量。
Threads_running :代表当前激活的(非睡眠状态)线程数。并不是代表正在使用的线程数,有时候连接已建立,但是连接处于sleep状态,这里相对应的线程也是sleep状态。 >默认值为110,可调优为80。
1.4 wait_timeout 指定一个请求的最大连接时间
对于4GB左右内存的服务器可以设置为5-10。
1.5 innodb_thread_concurrency 线程并发数
推荐设置为 2*(NumCPUs+NumDisks),默认一般为8。
1.6 缓存参数
缓存参数主要有key_buffer_size索引缓冲区大小,query_cache_size 总查询缓冲大小,query_cache_limit单个查询缓冲区大小 默认1M,query_cache_type指定是否使用查询缓冲,可以设置为0、1、2是否使用查询缓冲区;等等这里参数比较多不一一解释,大家可以参考该博文
https://blog.csdn.net/LNView/article/details/80325648?ops_request_misc=%7B%22request%5Fid%22%3A%22158159859319724845027301%22%2C%22scm%22%3A%2220140713.130056874..%22%7D&request_id=158159859319724845027301&biz_id=0&utm_source=distribute.pc_search_result.none-task
1.7 开启慢查询日志 方便mysql语句的优化
具体操作参考我的开启慢查询一文
mysql语句本身的优化——sql优化十策略
mysql语句优化我总结了十策略;
1.尽量全值匹配
2.最佳左前缀法制
3.不在索引列上做计算
4.范围条件字段放索引最后
5.覆盖索引尽量用
6.不等于用慎用
7.null/not有影响
8.like要担心
9.字符类型要加引号
10.or 改union
点我看详细信息
数据库范式的学习——设计数据库时参考
第一范式(1NF):每个字段列不可分割的原子数据项
第二范式(2NF):非主键属性必须完全依赖于主键
第三范式(3NF):任何非主属性不依赖于其它非主属性
巴斯-科德范式(BCNF):在3NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)
索引的优化
在说索引优化之前我们得知道几点mysql储存引擎知识,索引的种类有
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索(经常使用专业的搜索服务器,如lucene, es,solr他们利用分词器,分词过滤器 构建倒排索引)
ps.
说到索引种类还的说说,数据的储存方式 聚簇索引 与 非聚簇索引;每种储存引擎储存索引的数据结构不同,这里我介绍下InnoDB的聚簇索引实际上在同一个结构中保存了B+Tree索引和数据行。当表中有聚簇索引时,它的数据实际上存储在索引的叶子页中(叶子页中包含了行的全部数据)。而没有聚簇索引时B+Tree叶子页存放的是指向数据的指针,查询时会有二次查询。
索引的优化需要借助俩个工具 一个慢查询日志的分析工具mysqldumpshow.pl 该工具mysql安装时已经安装好了,只是它是perl语言开发的,需要安装运行环境;安装好了就可以用了
mysqldumpshow -s t -t 10 slow.log
mysqldumpslow -s c -t 20 slow.log
mysqldumpslow -s r -t 20 slow.log
主要功能是, 统计不同慢sql的
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
通过以上命令我们定位到想要优化的sql ,再通过explain sql执行计划看看如何优化索引;explain执行计划的参数即使用 可以查看我的 这篇博文sql优化;通过执行计划我们知道自己的sql是否使用了索引,以及索引使用的key-len是否全部覆盖;下面就要学习下 mysql 索引key-len的算法了
key_length的计算方式
当索引字段为定长数据类型,比如char,int,datetime,如果有是否为NULL的标记,这个标记需要占用1个字节。对于变长数据类型,比如:varchar,除了是否为NULL的标记外,还需要有长度信息,需要占用2个字节。(当字段定义为NOT NULL的时候,是否为NULL的标记将不占用字节)。
不同的字符集,latin1编码一个字符一个字节,gbk编码的为一个字符2个字节,utf8编码的一个字符3个字节。
创建索引的时候可以指定索引的长度,例如:
alter table test add index uri(uri(30));
长度30指的是字符的个数,如果为utf8编码varchar(255),key_length=30*3+2=92个字节
还有一个知识就是索引的数据结构了
图解几种数据结构:
二叉树:如果数据是单边增长的情况 那么出现的就是和链表一样的数据结构了,树高度大
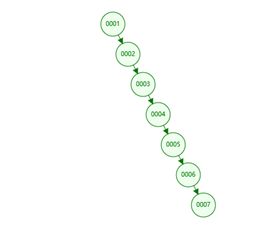
红黑树:在二叉树的基础上多了树平衡,也叫二叉平衡树,不像二叉树那样极端的情况会往一个方向发展。
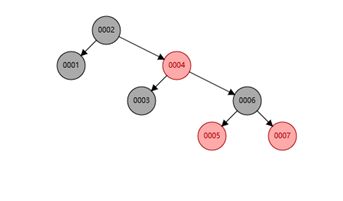
同样我们查找6,在二叉树中我们需要经过6个节点才能找到(1-2-3-4-5-6),红黑树中我们只需要3个节点(2-4-6),但是mysql索引的数据结构并不是红黑树,因为如果数据量大了之后,树的高度就会很大。
B树:在红黑树的基础上,每个节点可以存放多个数据
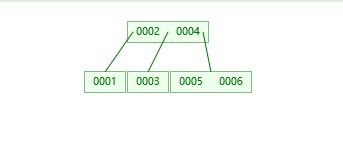
这个时候我们查找6 只需要2个节点就可以了,而且树的高度也比红黑树矮。
B+树:B树的变种
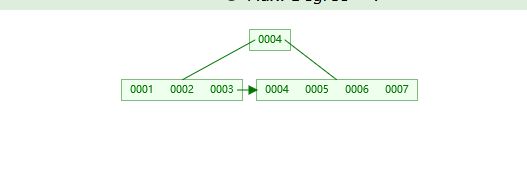
你会发现非叶子节点是会重复的,就像上面4,在叶子节点上面也出现了4,这是为什么呢?因为它需要在叶子上面存放数据。那又是怎么存放数据的呢?
---------------------------------------------------------------
mysql索引为什么用B+树
首先说一点,mysql索引的数据结构就是用到的B+树。

MyISAM存储引擎索引文件和数据文件是分离的
Usertabmyisam表使用的myisam存储引擎,表相关文件有三个,.frm是存放表结构数据,MYD是表数据。MYI是存放索引,索引树上会存储数据在MYD文件里面的位置。
InnoDB存储引擎
Usertab使用的Innodb存储引擎,表相关文件只有两个同样.frm文件是存放表结构数据,.ibd存放的数据和索引。
表数据文件本身就是按B+Tree组织的一个索引结构文件,主键索引叶节点包含了完整的数据记录
以InnoDB为例:
数据是放在主键索引上面,也就是说实际上在每个节点上还会存放所有的数据
使用B树存放数据之后实际是这样子的,会在每个对应的索引列的值上存放上对应的数据
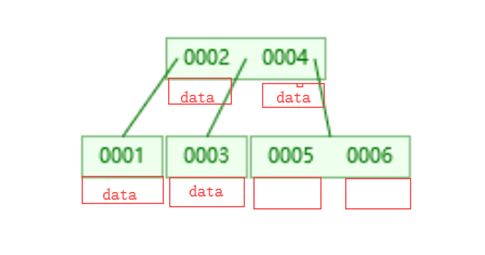
而B+树则不同,它只会在叶子节点上面挂载数据,非叶子节点不会存放数据,数据只会存在叶子节点上面,非叶子节点只存放索引列的数据
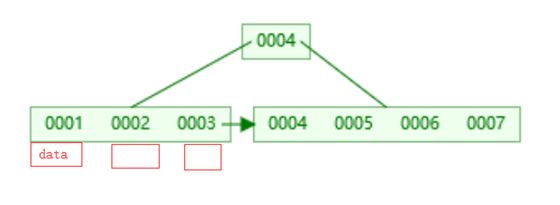
这样一个节点就可以存放很多个索引列数据,一次IO就可以拿到很多数据,mysql默认的一个节点16K的大小,可以通过show global status like "Innodb_page_size" 看到该值是16384,每次IO读取16K大小的数据,以索引列是bigInt类型为例,大小8字节,每一条数据还有一个指向下一层的指针6字节,16384/(8+6)=1170,一个节点就大约可以存1170条数据。
以一个层高为3的树为例,叶子节点存放数据之后大小1KB,那么这个树可以存放 1170 *1170 *16 =21,902,400,大约2200万条数据。所以在这种千万级的表中通过主键索引查找一条数据,最多3次IO就可以找到一条数据。而很多时候树的根节点基本都是在内存中,所以多数时候只需要2次IO。
叶子节点之间也有双向指针连接,提高区间范围性能,范围查找。
创建索引的时候,可以选择索引数据类型,一个是btree一个是hash,hash查找当然也快,但是当遇到范围查找的时候hash就尴尬了,所以根据实际业务需求来看是用btree还是hash。