Clickhouse基础教程
ClickHouse
起源
ClickHouse 是由号称“俄罗斯 Google”的 Yandex 开发而来,在 2016 年开源.在计算引擎里算是一个后起之秀,在数据库领域号称是最快的.
- 数据结构的演化
是什么
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
OLAP / OLTP
OLAP,也叫联机分析处理(Online Analytical Processing)系统,有的时候也叫DSS决策支持系统,就是我们说的数据仓库。与此相对的是OLTP(on-line transaction processing)联机事务处理系统。可以看出一个侧重事务处理。一个侧重分析处理
列式 / 行式
| ID | NAME | AGE |
|---|---|---|
| 1 | a | 10 |
| 2 | b | 20 |
| ID | 1 | 2 |
|---|---|---|
| NAME | a | b |
| AGE | 10 | 20 |
| Row-store | 1 | a | 10 | 2 | b | 20 |
|---|---|---|---|---|---|---|
| Col-store | 1 | 2 | a | b | 10 | 20 |
- 行式:一行的数据存储在一起
- 列式:一列的数据存储在一起
| 行式存储 | 列式存储 | |
|---|---|---|
| 优点 | 1.数据保存在一起,对某一行数据查询效率高 2. Insert/Update比较容易 | 1.以列存储每一列都可以作为索引 2.只查询某几列只需要读取某几列的数据,避免不必要的开销。3.一列数据类型的数据便于高效的压缩 |
| 缺点 | 1.只需要某几列数据时所有数据会被抓取 | 1.INSERT/UPDATE比较麻烦 2.选择某几列需要进行重新组装 |

DBMS
是一个数据库管理系统也就是说它是一个成体系的东西,对于数据的读写、存储、查询、修改、复制、事务、效率等等方方面面都有自己的一套东西
优点
- 超高性能:
- 数据压缩空间大单服务器每秒处理几亿行,HBase,BigTable,Cassandra,等只能提供每秒数十万的吞吐能力
- 真正的列式数据库管理系统进行简单的查询单服务器每秒可达2TB
- SQL语法丰富
- 驱动丰富
- 向量化引擎:
- 写入速度快,lsm树模型数据直接顺序写入磁盘(和kafka类似),普通磁盘能到50M-200M/s
- 线性扩展
- 横向扩展,可以部署在成百上千的节点上
- 纵向扩展,单个节点可以容纳万亿行超过100TB的数据
- 功能多
- 多个表引擎适用于复杂多元的业务
- 支持数据分片数据备份
- 不依赖于Hadoop庞大的生态

不足
- 没有完整的事务支持
- 不支持高并发: 每个查询都是尽量使用全部服务器资源
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
哪些公司在使用
-
Yandex.Metrica :目前为止,该系统在ClickHouse中有超过13万亿条记录,并且每天超过200多亿个事件被处理
-
今日头条:用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右
-
腾讯:内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
-
携程:内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求
数据类型
| MYSQL | Hive | ClickHouse(区分大小写) |
|---|---|---|
| Byte | tinyint | Int8 / UInt8 |
| short | smallint | Int16 / UInt16 |
| int | int | Int32 / UInt32 |
| long | bigint | Int64 / UInt64 |
| varchar | string | String |
| timestamp | timestamp | DateTime |
| float | float | Float32 |
| double | double | Float64 |
-
Nullable:允许用特殊标记 (NULL) 表示"缺失值",可以与
TypeName的正常值存放一起,官方介绍使用该类型总是会拖累性能,假设有业务需要null值的可以给它一个数据里不存在的比如都是正数的数据,可以定义-1为null值
-
FixedString(N): 不推荐使用
- 如果字符串包含的字节数少于`N’,将对字符串末尾进行空字节填充
- 如果字符串包含的字节数大于
N,将抛出Too large value for FixedString(N)异常 - 当做数据查询时,ClickHouse不会删除字符串末尾的空字节. 如果使用
WHERE子句,则须要手动添加空字节(\0)以匹配FixedString的值
-
Array(T): 还不支持多维数组
- 数组中只能有T类型元素和NULL(使用了Nullable包装)
-
Enum8/Enum16:
Enum保存'string'= integer的对应关系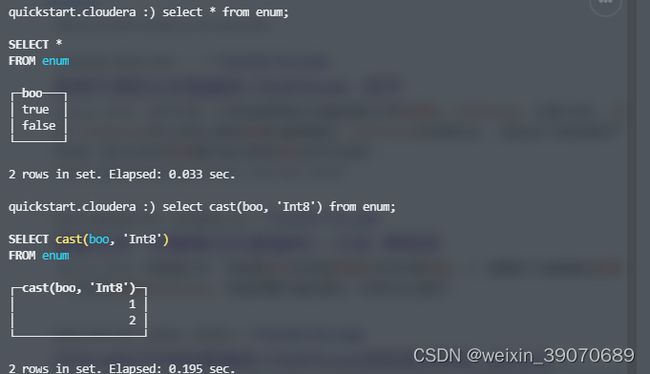
- 底层存储的数字,工作机制与它们在底层数值上的工作机制相同。如在ORDER BY
,GROUP BY,IN,DISTINCT中Enum 的行为与相应的数字相同 - 大多数具有数字和字符串的运算并不适用于Enums;例如,Enum 类型不能和一个数值相加
- 底层存储的数字,工作机制与它们在底层数值上的工作机制相同。如在ORDER BY
-
Domain类型:
- IPv4:
IPv4是与UInt32类型保持二进制兼容的Domain类型 - IPv6:
IPv6是与FixedString(16)类型保持二进制兼容的Domain类型
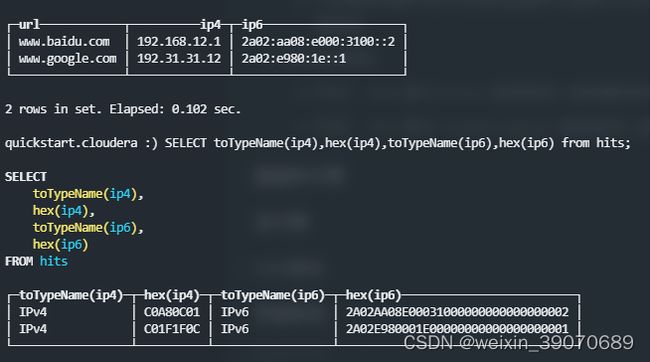
- IPv4:
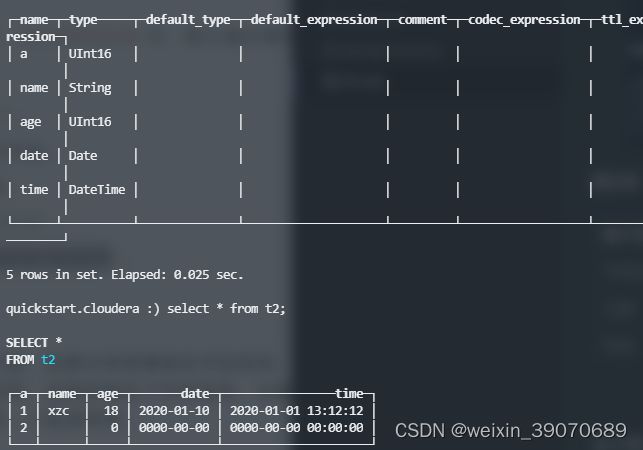
默认值
| 数字类型 | 0 |
|---|---|
| String | ‘’ |
| Date | 0000-00-00 |
| DateTime | 0000-00-00 00:00:00 |
表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
Log
具有最小功能的轻量级引擎。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的
TinyLog
1.数据存储在磁盘
2.写入数据时追加到文件末尾
3.不支持并发
CREATE TABLE tiny(`id` UInt(32), `name` String,`age` UInt16)ENGINE = TinyLog
MergeTree
适用于高负载任务的最通用和功能最强大的表引擎。这些引擎的共同特点是可以快速插入数据并进行后续的后台数据处理。 MergeTree系列引擎支持数据复制(使用Replicated* 的引擎版本),分区和一些其他引擎不支持的其他功能。
MergeTree
1.支持分区,不支持类似hive的多级目录的分区,一般都以年月日做为分区
2.存储的数据分区内按照主键和排序字段排序,类似于mysql的联合索引(稀疏索引),需要根据业务考虑字段的先后顺序
3.稀疏索引: 对分区中排序好的数据每一段数据(默认8192)存储一个索引,这样索引占用空间就少 (类似于只有一级索引的跳表,可以实现二分查找)
3.支持数据副本
ENGINE = MergeTree()
[PARTITION BY expr] // 分区
[ORDER BY expr] // 表的排序键
[PRIMARY KEY expr] // 主键,默认和排序键相同,一般不需要设置
[SETTINGS name=value, ...] // 设置索引粒度和一些其他的配置
CREATE TABLE click.mt (`id` UInt16, `name` String, `age` UInt16, `birthDay` DateTime) ENGINE = MergeTree() PARTITION BY toYYYYMM(birthDay) ORDER BY (name, age) SETTINGS index_granularity = 8192
ReplacingMergeTree
1.该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项
2.去重合并会在后台运行,不保证没有重复数据出现
3.主键相同数据合并时如果ver列未指定会取最后一条,指定时取最大版本的(ver 类型为 UInt*, Date 或 DateTime)
CREATE TABLE click.rmt (`gmt` Date, `id` UInt16, `name` String, `point` UInt16) ENGINE = ReplacingMergeTree(point) PARTITION BY gmt ORDER BY name SETTINGS index_granularity = 8192
insert into t (gmt, id, name, point) values ('2017-07-11', 1, 'a', 20);
insert into t (gmt, id, name, point) values ('2017-07-11', 1, 'a', 30);
insert into t (gmt, id, name, point) values ('2017-07-11', 1, 'a', 10);
SummingMergeTree
1.具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值
2.主键相同合并时其他列会取第一个出现的
3.ck按片段合并,可能不会完整的汇总所有行
create table sumt(time Date, name String, a UInt16, b UInt16, c String)ENGINE=SummingMergeTree((a,b))
PARTITION BY time
ORDER BY (time,name);
insert into sumt values ('2019-07-10','a',1,2,'x'),
('2019-07-10','a',2,1,'x1'),
('2019-07-11','b',3,8,'x2'),
('2019-07-11','b',3,8,'x3'),
('2019-07-11','a',3,1,'x4'),
('2019-07-12','c',1,3,'x5');
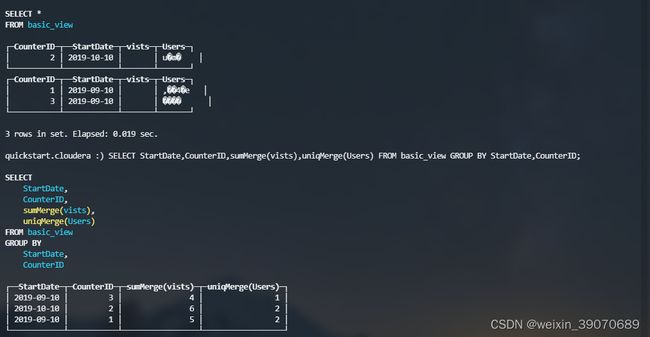
AggregatingMergeTree
1.会将相同主键的所有行(在一个数据片段内)替换为单个存储一系列聚合函数状态的行。
2.不能直接插入数据,可以通过INSERT SELECT 或者创建物化视图
// 创建普通表
CREATE TABLE basic(StartDate Date,CounterID UInt16,Sign UInt16,UserID UInt16)ENGINE=MergeTree
PARTITION BY StartDate
ORDER BY (CounterID,StartDate);
INSERT INTO basic values('2019-09-10',1,2,1),('2019-09-10',1,3,2),('2019-10-10',2,2,4),('2019-10-10',2,4,8),('2019-09-10',3,4,9);
// 创建物化视图
CREATE MATERIALIZED VIEW basic_view
ENGINE=AggregatingMergeTree() PARTITION BY toYYYYMM(StartDate) ORDER BY (CounterID, StartDate)
AS SELECT
CounterID,StartDate,sumState(Sign) AS vists,uniqState(UserID) AS Users
FROM basic
GROUP BY CounterID,StartDate;
外部表引擎
用于与其他的数据存储与处理系统集成的引擎。 该类型的引擎
MySQL: 会将mysql表映射过来但是不会存数据相当于一个代理,查询的时候ck会去连接mysql获取数据然后返回
CREATE TABLE mysql(id UInt16,username String,password String,gender String,createAt DateTime)
ENGINE=MySQL('127.0.0.1:3306','test','user','root','cloudera');
MaterializedMySQL: 通过binglog日志将数据都同步到ck中,没有mysql引擎的网络IO传输并且使用ck的表引擎进行计算性能比MySQL引擎高
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MaterializeMySQL('127.0.0.1:3306','test','user','root')
JDBC
CREATE TABLE jdbc_table(id UInt16,username String,password String,gender String,createAt DateTime)ENGINE=JDBC('jdbc:mysql://localhost:3306/?user=root&password=cloudera','test','user');
Kafka: 流式读取kafka的数据,官方建议同时建一个字段相同MergeTree引擎然后使用物化试图将kafka引擎的数据插入MergeTree中. 早期使用19版本性能很低后面官方进行持续的修复和优化建议使用的时候进行完整的测试
CREATE TABLE queue (timestamp UInt64,level String,message String)
ENGINE = Kafka('localhost:9092', 'topic', 'group1', 'JSONEachRow');
HDFS: 集成hdfs数据,类似于hive以hdfs做为存储
CREATE TABLE hdfs(id String,name String,age UInt16,star String)ENGINE=HDFS('hdfs://127.0.0.1:8020/test/person/*','CSV');
其他表引擎
用于特定功能的引擎
Memory: 一般用于测试或一些特殊业务
1.数据存储在内存中,服务器宕机数据消失
2.支持并行
3.性能非常高
create table t1(a String, b UInt16) ENGINE=Memory;
Merge: 21版本实际使用中有性能问题,建议需要使用的时候进行完整测试
1.用于将多个表链接在一起并且可以利用原表的索引
1.本身不存储如何数据
2.不支持写操作
CREATE TABLE click.m (`id` UInt16, `name` String) ENGINE = Merge(currentDatabase(), '^m')
URL引擎:直接解析接口数据,对于一些以前使用定时任务获取别的系统的数据是可以考虑使用,该引擎就是直接去访问接口然后解析成表进行查询后返回
CREATE TABLE url_engine_table (word String, value UInt64)
ENGINE=URL('http://127.0.0.1:12345/', CSV)
Distributed: 分布式引擎本身不存数据,可以理解为mysql的分表,将数据负载均衡的写到各个服务器的本地表上,
然后通过该分布式表进行查询,ck会帮你做数据合并的操作
1.在多个服务器上进行分布式查询并且可以利用原表的索引
2.本身不存储数据
3.支持逻辑表写入,异步写入,官方推荐自己路由将数据写到各个节点的本地表上
create table d(id UInt16, name String) ENGINE=TinyLog;
insert into d(id, name) values (0, 'aaa');
insert into d(id, name) values (1, 'bbb');
create table distribute(id UInt16, name String) ENGINE=Distributed(test_unavailable_shard, click, d, id);
SQL语法
SELECT [DISTINCT] expr_list
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE ]
[ARRAY JOIN ...]
[GLOBAL] ANY|ALL INNER|LEFT JOIN (subquery)|table USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr_list] [WITH TOTALS]
[HAVING expr]
[ORDER BY expr_list]
[LIMIT n BY columns]
[LIMIT [n,m]
[UNION ALL ...]
[INTO OUTFILE filename]
[FORMAT format]
ARRAY JOIN: 用于展开数组数据
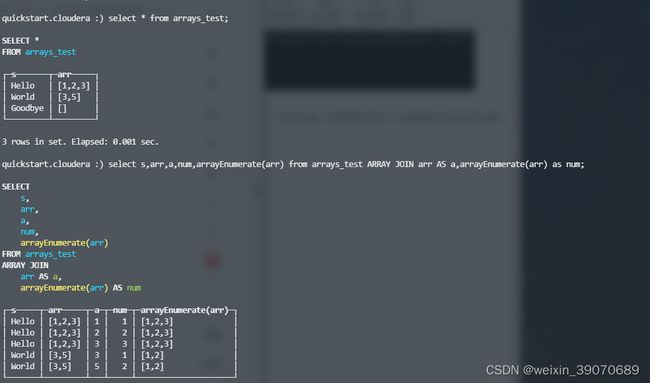
JOIN
-
ANY / ALL
- 使用ANY时如果右表中存在多个与左表关联的数据,那么系统仅返回第一个与左表匹配的结果
- 使用ALL时如果右表中存在多个与左表关联的数据,那么系统则将右表中所有可以与左表关联的数据全部返回在结果
-
GLOBAL
- 使用后会在请求服务器端计算右表并生成临时表,将临时表发送到各个服务器上进行join计算
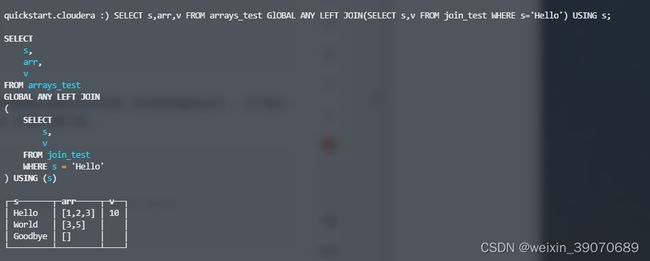
-
Group by
- 与mysql不同不能取不在聚合里的字段
- 提供函数选取其他字段
- any():取第一个
- anyheavy():取出现频率最高的
- anyLast():取最后一个
导入导出CSV数据
// 导入
cat xxx.csv | clickhouse-client --query="INSERT INTO b6logs FORMAT CSV";
// 指定分隔符
cat xxx.csv | clickhouse-client --format_csv_delimiter="|" --query="INSERT INTO b6logs FORMAT CSV";
// 导出
clickhouse-client --query="select * from user format CSV" > 9c9dc608-269b-4f02-b122-ef5dffb2669d.log
支持客户端
- CLI客户端
- HTTP客户端接口
- JDBC驱动
- 第三方客户端
- Python/PHP/JAVA/Scala/GO 等主流语言的第三方开发的库
- 可视界面
权限管理
ClickHouse作为一个分析类型(OLAP)的数据库系统,相对于MySQL数据库在用户管理方面有很大不同,它是通过修改配置文件来实现用户权限管理的。在安装好ClickHouse之后,其配置文件在/etc/clickhouse-server目录下,容器中也在此目录下,对应的配置文件为users.xml,ClickHouse使用它来定义用户相关的配置项。修改了user.xml的参数之后是即时生效的
<users>
<user_name> --配置的用户
<password>password> --明文密码
<password_sha256_hex>password_sha256_hex> --加密密码,二选一
<networks incl="networks" replace="replace"> --允许登录的地址,用于限制用户登录的客户端地址
networks>
<profile>profile_nameprofile> --指定用户的profile
<quota>defaultquota> -- 指定用户的quota,限制用户使用资源
<databases> --指定数据库
<database_name>
<table_name> --指定数据表
<filter>expressionfilter>
table_name>
database_name>
databases>
user_name>
users>
-
密码设置
-
:明文密码
-
:加密密码 -
linux下直接生成
PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-' 返回值 zRB1j7H8 -- 密码 32dbe275bb31cd65f55ebca5fb50bf4ce2e7ae2fc062dacbf73f19f54362ea14 -- 加密密码
-
-
-
:限制用户登录的客户端地址可以通过IP,主机等进行限制
<ip>:IP地址,如10.0.0.1 <host>:主机名,如example01.host.ru <host_regexp>:^example\d\d-\d\d-\d\.host\.ru$ 来自任何IP: <ip>::/0ip> 来自本机: <ip>::1ip> <ip>127.0.0.1ip> -
:指定用户的profile
-
:指定用户访问的数据库 -
:指定用户访问的表 -
:指定用户访问的过滤器,限制返回符合条件的行。如:id > 1 ,即查询表只返回id>1的行
-
查询权限管理
1.读权限:SELECT, SHOW, DESCRIBE, EXISTS 2.写权限:INSERT, OPTIMIZE. 3.设置权限:SET, USE 4.DDL权限:CREATE, ALTER, RENAME, ATTACH, DETACH, DROP TRUNCATE 5.kill QUERY 权限控制标签
- readonly
- 0:不进行任何限制(默认值)
- 1:只拥有读权限
- 2:拥有读权限和设置权限
- allow_ddl
- 0:不允许ddl查询
- 1:允许ddl查询(默认值)
<profiles> --标签在profiles里设置 <normal> --只读,不能DDL <readonly>1readonly> <allow_ddl>0allow_ddl> normal> <normal_2> --只读,即使DDL允许 <readonly>1readonly> <allow_ddl>1allow_ddl> normal_2> <normal_3> --读写,能DDL <readonly>0readonly> <allow_ddl>1allow_ddl> normal_3> profiles> <users> <test> <password>123456password> <networks incl="networks" replace="replace"> <ip>::/0ip> networks> <profile>normal_3profile> --用户引用相关profile <quota>defaultquota> test> users>模板示例
- 管理员账号:default
- 只读账号:zhoujy_ro
- 从指定ip的只读账号:zhoujy_rw
- 从指定ip的管理账号:zhoujy_admin
- 只能访问指定数据库账号:zhoujy_db
<yandex> <profiles> <default> <max_memory_usage>100000000max_memory_usage> <use_uncompressed_cache>0use_uncompressed_cache> <load_balancing>randomload_balancing> default> <readonly> <readonly>1readonly> readonly> <readwrite> <constraints> <max_memory_usage> <readonly/> max_memory_usage> <force_index_by_date> <readonly/> force_index_by_date> constraints> readwrite> profiles> <users> <default> -- 因为profiles里默认的profile是没有限制的,所以default就是默认管理员账号 <password>password> <networks incl="networks" replace="replace"> <ip>::/0ip> networks> <profile>defaultprofile> <quota>defaultquota> default> <zhoujy_ro> <password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9password_double_sha1_hex> <networks incl="networks" replace="replace"> <ip>::/0ip> networks> <profile>readonlyprofile> <quota>defaultquota> zhoujy_ro> <zhoujy_rw> <password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9password_double_sha1_hex> <networks incl="networks" replace="replace"> <ip>192.168.163.132ip> networks> <profile>readwriteprofile> <quota>defaultquota> zhoujy_rw> <zhoujy_admin> <password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9password_double_sha1_hex> <networks incl="networks" replace="replace"> <ip>192.168.163.132ip> <ip>192.168.163.133ip> networks> <profile>defaultprofile> <quota>defaultquota> zhoujy_admin> <zhoujy_db> <password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9password_double_sha1_hex> <networks incl="networks" replace="replace"> <ip>::/0ip> <ip>127.0.0.1ip> <ip>192.168.163.132ip> networks> <profile>readwriteprofile> <quota>defaultquota> <allow_databases> <database>testdatabase> allow_databases> zhoujy_db> <zhoujy_tb> <password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9password_double_sha1_hex> <networks incl="networks" replace="replace"> <ip>::/0ip> <ip>127.0.0.1ip> <ip>192.168.163.132ip> networks> <profile>readonlyprofile> <quota>defaultquota> <allow_databases> <database>testdatabase> allow_databases> <databases> <IT> <table1> <filter>id >= 500 filter> table1> IT> databases> zhoujy_tb> users> yandex> - readonly