Python中json模块的使用与pyecharts绘图的基本介绍
文章目录
-
- json模块
-
- json与Python数据的相互转化
- pyecharts模块
-
- pyecharts基本操作
-
- 基础折线图
- 配置选项
-
- 全局配置选项
- json模块的数据处理
- 折线图示例
-
- 示例代码
json模块
json实际上是一种数据存储格式,是一种轻量级的数据交互格式,可以把他理解成一个特定格式的字符串以文件的形式存储起来
主要是在各个编程语言中交流的数据格式
从形式上看,json数据格式类似于Python的字典,列表,元组等数据容器
他长得像这样
{"name":"summer","age":18}
[{"name":"summer","age":18},{"name":"morty","age":14}]
我们可以利用一些工具将这些数据的格式层次显示清楚一点
在线JSON格式化工具
例如

当数据量巨大时,或者嵌套层数比较深的时候,这样的工具就比较方便了
json与Python数据的相互转化
import json # 导入json模块
data = [{"name":"summer","age":18},{"name":"morty","age":14}]
data = json.dumps(data)
data = json.loads(data)
dumps方法就是将python数据转化为json数据
loads方法是将json数据转化为python数据
pyecharts模块
我们可以使用pyecharts模块进行数据可视化,这个模块的使用相对比较简单,这里只做基础的介绍
echarts是由百度开源的数据可视化的模块,交互性良好,图表也很精良,pyecharts只是他支持的一个部分
首先我们需要在命令行或者PyCharm中安装pyecharts模块
pip install pyecharts
pyecharts官方文档
pyecharts基本操作
基础折线图
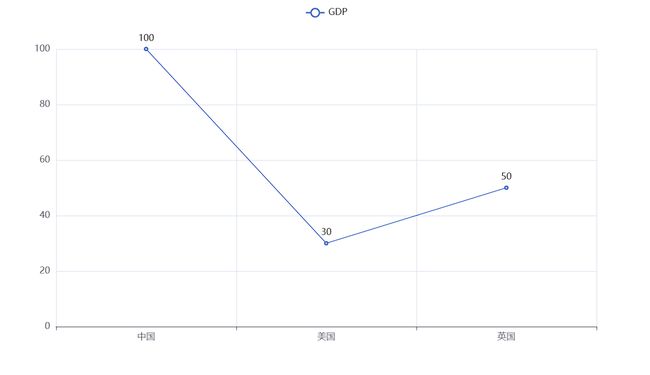
from pyecharts.charts import Line # 导入Line功能构建折现图
line = Line() # 得到折线图对象
line.add_xaxis(['中国','美国','英国']) # 构建x轴行标
line.add_yaxis('GDP',[100,30,50]) # 构建y轴列标与数据
line.render() # 生成图表
运行完成之后回生成一个render.html文件,用浏览器打开之后就是我们的图表
配置选项
在pyecharts模块中由很多的配置选项
全局配置选项
这里可以用set_global_opts可以配置许多的内容,例如标题、图例、颜色、工具箱等内容
之后我们对示例详细讲解
json模块的数据处理
这里我们有一段json数据,格式化之后如下图所示

我们发现他除了数据内容,还包含了一串字符,在数据的末尾还有一个分号(未显示)
我们在把他转化成使用的元组、列表、字典时就需要对这个字符串进行处理
示例如下
import json
# 将json数据已经保存到data中
data = data.replace('jsonp_1629344292311_69436(','') #用空字符替换这一串
data = data[:-2] # 去除最后的括号和分号

这个数据量其实非常大,我们只展示了其中的一部分
折线图示例
import json
from pyecharts.charts import Line
import pyecharts.options as opts
这里我们先导入相关的配置项
file_us = open('C:/Users/Downloads/资料/可视化案例数据/折线图数据/美国.txt', encoding='UTF-8')
us_data = file_us.read()
第一行我们获取了一个文件对象,利用UTF-8格式读取了
再将文件对象读取到us_data中
us_data = us_data.replace('jsonp_1629344292311_69436(','')
us_data = us_data[:-2]
这里我们将开头和结尾进行处理,获得了一个标准的json字符串,也就是我们上图所表示的结构
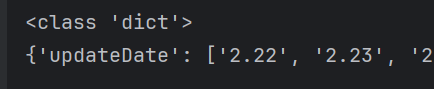
us_dict = json.loads(us_data)
print(type(us_dict))
print(us_dict)
第一行我们将json字符串加载未python数据格式,通过结构我们可以知道这个结构最外层是字典,我们通过type()和print()验证

这个json包含了某国的疫情数据,由于数据嵌套比较深,我们先取到某国trend下的数据
trend_data = us_dict['data'][0]['trend']
print(type(trend_data ))
print(trend_data )
第一行是我们一路取数据的过程,再经过输出验证一下
这里我们再看看此时的结构
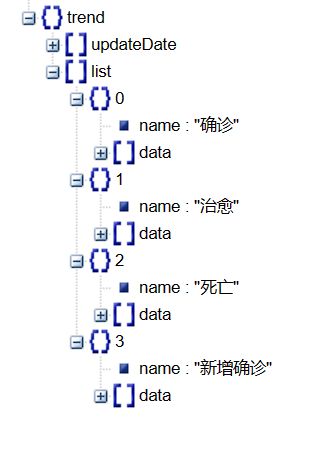
这里我们可以看到有两部分,一部分是更新日期,另一部分分别是数据,因此我们要取更新日期作x轴,为了表示简单,我们只取一列数据作为y轴
x_data = trend_data['updateDate'][:360]
y_data = trend_data['list'][0]['data'][:360]
这里我们就分别取出来了x轴和y轴的数据了,当然为了避免过多的数据挤在同一个表中,使用了切片减少数据
line = Line()
line.add_xaxis(x_data)
line.add_yaxis('确诊人数',y_data)
Line.render()
这里我们就创建了一个折线图对象,添加x轴y轴,将他生成
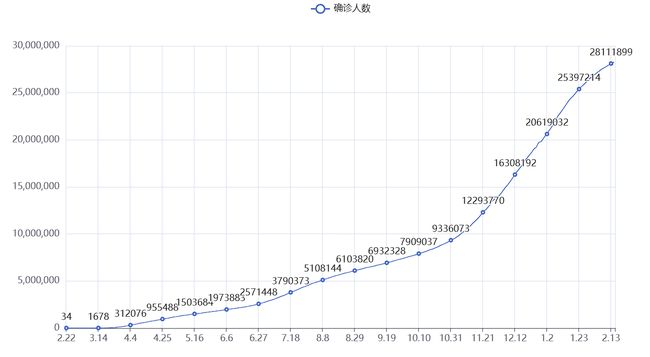
结果就像这样,如果我们有其他的y轴数据,继续添加y轴数据即可
line.set_global_opts(
title_opts=opts.TitleOpts(title='某国确诊人数折线图',pos_left='center',pos_bottom='1%')
)
这里是添加了一个标题的全局选项,只是做一个演示,具体的功能还有非常多,详情还请阅读官方文档
示例代码
import json
from pyecharts.charts import Line
import pyecharts.options as opts
file_us = open('C:/Users/Downloads/资料/可视化案例数据/折线图数据/美国.txt', encoding='UTF-8')
us_data = file_us.read()
us_data = us_data.replace('jsonp_1629344292311_69436(','')
us_data = us_data[:-2]
us_dict = json.loads(us_data)
# print(type(us_dict))
# print(us_dict)
trend_data = us_dict['data'][0]['trend']
# print(type(trend_data))
# print(trend_data)
x_data = trend_data['updateDate'][:360]
y_data = trend_data['list'][0]['data'][:360]
line = Line()
line.add_xaxis(x_data)
line.add_yaxis('确诊人数',y_data)
line.set_global_opts(
title_opts=opts.TitleOpts(title='某国确诊人数折线图',pos_left='center',pos_bottom='1%')
)
line.render()
file_us.close()