【腾讯云 HAI域探秘】使用腾讯云HAI低成本搭建AI模型,高效制作漫画解说视频
前言
本文将介绍如何利用腾讯云高性能服务HAI一键部署云端StableDiffusion和ChatGLM2-6B模型,从0到1带大家学习如何高效制作漫画解说视频。通过ChatGLM2-6B模型生成需要的AI绘画提示词和小说内容,并根据内容进行场景描述生成英文提示词。然后,使用StableDiffusion模型将场景描述提示词转化为我们需要的图片。最后,我会教大家如何快速将StableDiffusion生成的图片与音频进行整合,制作出大家喜欢的漫画解说视频。
大家可以先看看视频效果,点击即可播放
接下来我会一步一步带着兄弟们去实操,如果不想错过官方活动可以先点击报名参与体验
一、腾讯云HAI
1、腾讯云HAI是什么

腾讯云高性能应用服务(Hyper Application lnventor,HAI),是一款面向 Al、科学计算的 GPU 应用服务产品,为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的GPU云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的 GPU 算力资源,以确保您在数据科学、LLM、A 作画等高性能应用中获得最佳性价比此外,HAI 的一键部署特性让您可以在短短几分钟内构建如 StableDifusion、ChatGLM 等热门模型的应用环境。而对于 Al 研究者,我们的直观图形界面大大降低了调试的复杂度,支持jupyterlab、webui 等多种连接方式,助您轻松探索与创新。现在,只需打开浏览器,HAI便为您打开了一片无限可能的高性能应用领域。
2、产品特性

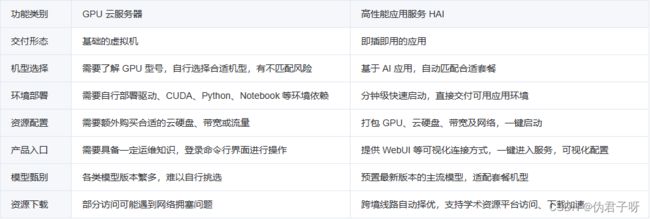
3、产品对比
高性能应用服务 HAI 相比传统 GPU 云服务器的主要区别和优势请参考下表:
4、产品优势
简单易用
通过简化计算、网络和存储等基础设施的配置流程,大幅降低了云服务操作和管理的复杂度。
应用环境快速部署
支持多种 AI 环境快速部署,如 ChatGLM-6B、StableDiffusion 等,使用户可专注业务及应用场景创新。
高灵活性
支持用户登录实例,对 AI 模型及实例环境进行灵活配置。可进行内部开发、业务测试,或对外提供业务服务。
多种登录方式
除传统连接方式外,支持通过 jupyterlab、WebUI 等方式一键启动,提供更贴合使用场景的登录方式。
算力种类丰富
提供多种算力套餐选择,未来还将加入更多种类供用户选择。
二、一键部署AI模型
1、申请资格
(1) 点击链接进入 高性能应用服务 HAI 申请体验资格

(2)等待审核通过后,进入 高性能应用服务 HAI

(3) 点击前往体验HAI,登录 高性能应用服务 HAI 控制台

(4)点击 新建 选择 AI模型,参照下图进行配置

(5) 等待实例创建完成,一般3-8分钟左右就能完成 ,等待时间不计费
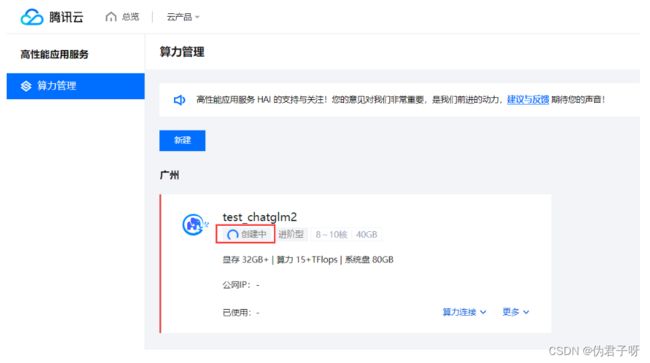
(6)创建完成,查看实例信息
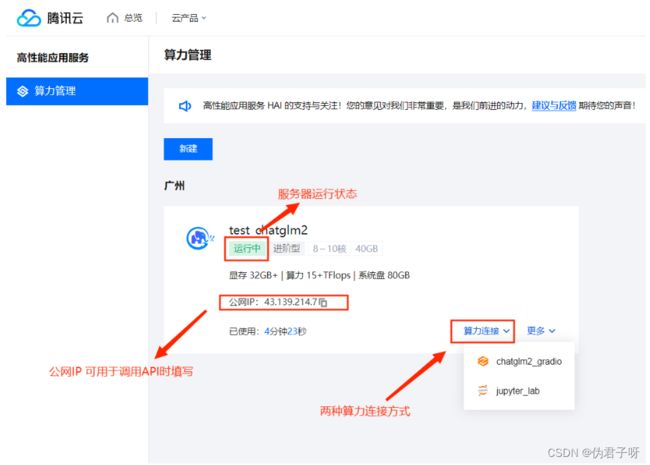
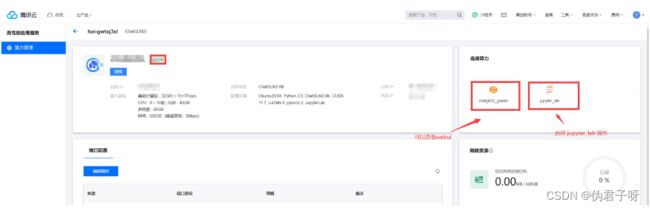
(7) 查看详细的配置信息
2、ChatGLM2-6B模型搭建
(1)进入 ChatGLM2-6B WebUI ,以下可选择两种方式进入

或者从服务器详情页进入
(2)ChatGLM2-6B WebUI操作界面
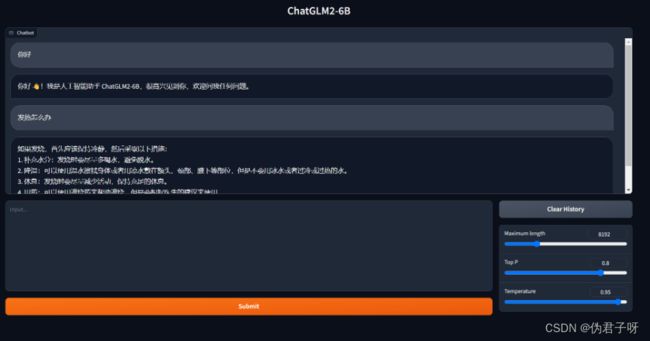
到此,属于你的gpt就部署完成,接下来我会告诉大家如何一键部署云端SD
3、StableDiffusion模型搭建
(1) 登录 高性能应用服务 HAI 控制台
(2)点击 新建 选择 AI模型,参照下图进行配置

(3) 等待创建完成

(4)创建完成,查看实例状态

(5) 查看详细的配置信息

(6)进入 StableDiffusionWebUI ,以下可选择两种方式进入

或者从服务器详情页进入

(7)StableDiffusionWebUI操作界面简介
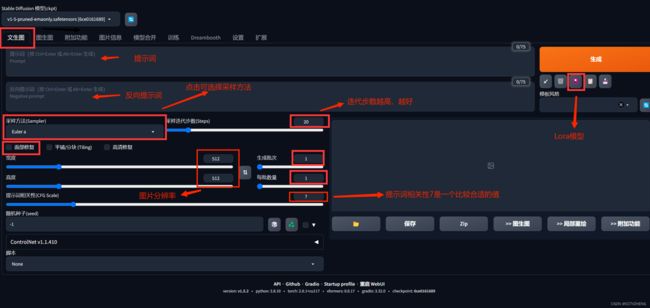
StableDiffusion部署完成(默认界面是英文版的,兄弟们有需要可以下载汉化插件,把界面汉化一下),接下来就可以在StableDiffusionWebUI界面来生成漫画解说所需要的图片素材了
三、SD模型和插件上传
1、Checkpoint大模型
大模型是SD的核心,用来控制生成图片的整个画面风格走势。出图前要选择合适的大模型比如有些擅长写实照片,有些擅长游戏原画,有些擅长室内设计等等。所以兄弟们可以选择自己喜欢的大模型进行下载使用。
模型存放路径【 ~/stable-diffusion-webui/models/stable-diffusion 】
如下图所示,我们将自己在网上下载好的Checkpoint大模型通过jupyterlab可视化上传到SD服务器中模型指定的存放路径
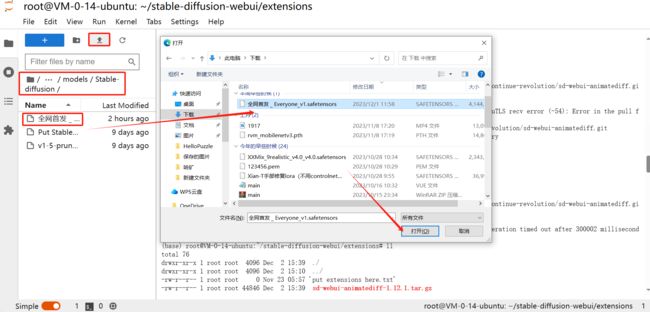
2、AnimatDIFF插件
现在SD支持一键生成动图效果,需要用到animatdiff插件和mm_sd_v15_v2.ckpt大模型(大模型上传方法和上面一样)
如下图所示,我们将github上下载的tar包通过jupyterlab可视化上传到【 ~/stable-diffusion-webui/extensions 】路径下

当然,如果想直接在命令行克隆下来也行,我推荐还是直接去github上下载到本地再上传
如下图所示,我本来也是想直接克隆的,但尝试好几次都是通信断开

所以我建议兄弟们还是和我一样老老实实下载到本地之后上传到指定路径解压即可
3、AI漫画助手插件
做漫画解说其实最大的难点在于制作分镜,也就是说原本是一段小说。我们怎么把它改成一个一个针对图片画面的描述,这个是相对来说比较难的,因为小说的内容跟镜头描述的其实还是天差地别的。但是我分享的这个插件就能达到这个效果
如下图所示,我们将插件上传到【 ~/stable-diffusion-webui/scripts 】路径下即可
兄弟们如果不知道这个插件在哪里下载的可以直接找我要

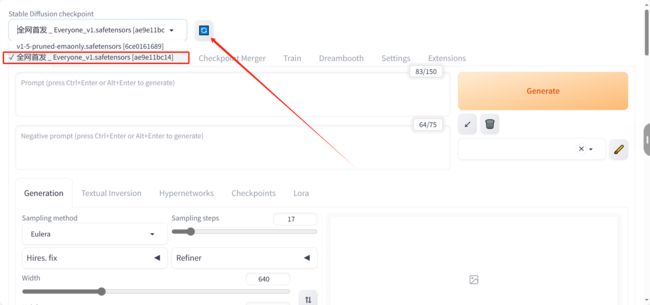
当大家都把自己喜欢的大模型和需要的插件安装好之后就可以重启webui服务了
重启之后首先更换一下大模型,因为默认的大模型是动物模型,无法满足我们的需求
我个人比较喜欢英文版本,兄弟们如果不习惯可以下载汉化插件到扩展目录下,然后重启webui
四、实操步骤
1、用gpt写小说
想必大家和我一样只会读小说,不会编写小说吧。那我们就让gpt给咱把小说写好,直接拿来用就行。
我们打开之前一键部署好的gpt,在输入框中输入你想写的小说背景、角色、情节等等
以下是我个人编写的需求,仅供参考
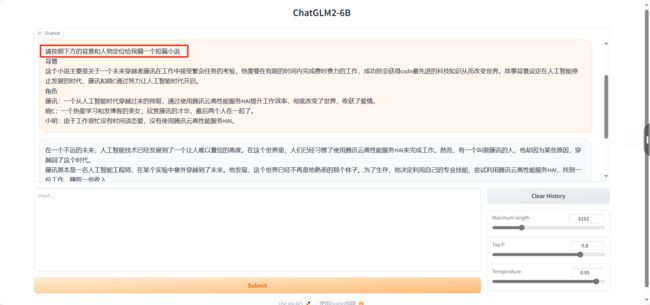
2、用gpt写AI绘画提示词
不会写AI绘画提示词没关系,直接用腾讯云HAI一键部署好的gpt帮我们写就行,真正做到解放双手
以下是我个人编写的需求,仅供参考

3、用SD自动出图
gpt都把我们需要的AI绘画提示词写好了,现在我们直接把提示词放到SD里面自动出图即可
以下是我个人设置的出图参数,仅供参考

如果实在不会配置出图参数的话,建议直接使用AI漫画助手(支持中文提示词)
可以在scripts中选择AI漫画助手插件,按照个人喜好选择作者画风、时代背景等等
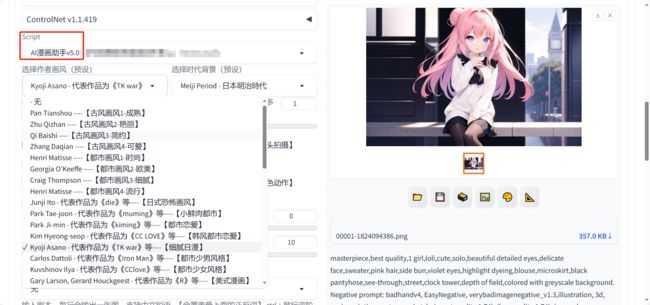
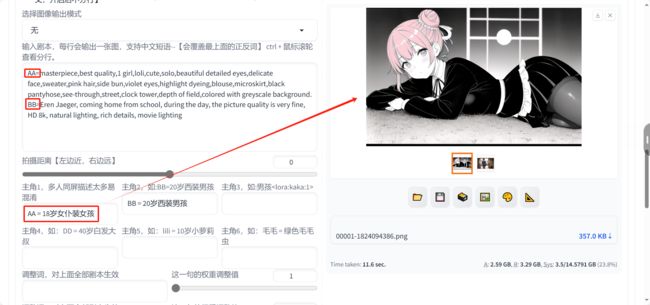
AI漫画助手完美解决了SD制作分镜图片的痛点,大家可以在剧本框输入中文提示词。
例如:一个女孩坐在凳子上
每行会输出一张图,也就是说一行一个分镜

有时候多个角色容易混淆,使用漫画助手的角色固定功能就能完美解决
例如:AA=18岁女仆装女孩 BB=20岁西装男孩

4、视频制作
本来我是打算根据gpt写的那个小说完完整整做一个漫画小说视频出来。但是我思来想去觉得我参加这次新品体验的目的是让更多的小伙伴知道腾讯云HAI,和我一起探索HAI域的更多功能。因为只有所有人都参与进来,这个生态才会越来越好,以后我们的工作才会更轻松高效。
所以我本人就原创了一个视频,希望大家能通过我的视频对腾讯云HAI产生兴趣并尝试去使用到生活和工作中。
其实大家只要学会方法就行,一味的照搬照抄AI只会限制我们的创新能力。所以我上面出图的时候一直在强调仅供参考。
现在我就把视频的制作过程分享给大家,希望对大家能有所帮助。
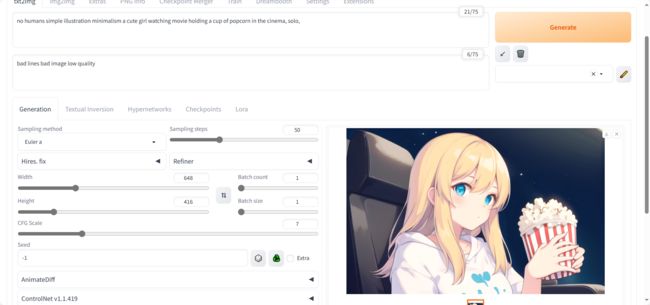
这是我自己写的提示词,针对视频中看电影那个分镜

这个是针对视频中浪漫的二人世界的分镜,其他分镜也同理,我就不罗列了。
然后我们把图片全部导入剪映中,接下来就是逐帧编辑即可

给每个分镜都编辑好文字之后直接点击朗读按钮选择自己喜欢的声音即可
然后搜索并导入一首自己喜欢的BGM,每个分镜的出场、入场和组合动画也看个人喜好设置就行,最后导出即可
五、总结
使用腾讯云HAI的StableDiffusion和ChatGLM2-6B模型的整个过程中,我感受到了它作为一款面向AI和科学计算的GPU应用服务产品所带来的种种优势。
多种预装模型环境,这大大减少了我们进行应用构建和调试的时间和精力,让我们可以更加专注于模型的设计和优化。此外,HAI提供了友好的图形界面,也就是可视化界面,使得AI调试更为简单和直观。
等大家的工作效率都提高之后就有时间去设计类似AI漫画助手一样的插件,以后HAI领域的生态就会更全面,真正做到惠及大众,改变世界。
总而言之,感谢腾讯云HAl为我们提供的便利和支持,使得大家可以有时间和精力专注于创新和研究,快速迭代和优化模型,实现更好的效果。还没有参与体验的小伙伴抓紧报名,早用早享受!