DyNet论文笔记 华为动态卷积核的论文解读
文章目录
- *KeyPoint*
-
- 为什么要这么干?
- *Keywords*
- 摘要
- 引言
- 相关工作
-
-
- 高效卷积神经网络设计
- 模型的压缩
- 动态卷积核
-
- CNN中的动态卷积
-
- 动机
- 动态卷积
-
- 系数预测模块(Coefficient prediction module)
- 动态生成模块(Dynamic generation module)
- 训练算法
- 动态卷积神经网络
- 评估
-
- 实验设置及比较方法
- 实验结果与分析
- 消融研究
- 结论
- 附录
DYNET: DYNAMICCONVOLUTION FOR ACCELERATING CONVOLUTIONALNEURALNETWORKS
代码地址
KeyPoint
- 噪声的无关性,在对图像进行卷积的时候,实际上不需要对噪声进行卷积,作者通过引入动态卷积核的方法来一定程度上避免了对噪声的卷积,从而大大降低了运算量。
- 动态卷积核是基于固定卷积核的融合
- 在MobileNetV2上的实验结果表明,Dy-MobileNetV2的性能始终优于MobileNetV2,但这种优势随着通道数量的增加而减弱。
- 随着输入规模的增大,DyNet所实现的减少延迟的比率 **(latency Reduced Ratio)**也越来越大。如(Tan & Le, 2019)所示,更大的输入规模可以使网络表现得更好,因此DyNet在这种情况下更有效。
- 在训练过程中,由于每张图的卷积核都是不一致的,所以在一个batch里并行计算是困难的(在旷视DRConv中,是用将batch方向的并行计算堆叠到c方向通过group卷积实现),该论文通过在特征图上进行等效加权,这样就类似于通道上的注意力机制。
为什么要这么干?
论文观察到卷积核之间仍然存在显著的相关性,并引入了大量的冗余计算,其基本思路为降低卷积核之间的相关性。将提出了一种动态卷积方法,该方法根据图像内容学习系数,将多个核融合为一个动态核。
论文的思路是根据线性卷积公式改进而来,对于一般的线性卷积输入 x x x,从元素 x i x_i xi开始做线性卷积后,得到的输出 f i ( x ) f_i(x) fi(x)为
f i ( x ) = ⟨ x i , w ⟩ f_i(x)= \langle x_{i}, w \rangle fi(x)=⟨xi,w⟩
即
f i ( x ) = ∑ j = 0 n x i + j w j f_i(x) = \sum_{j=0}^{n}x_{i+j}w_{j} fi(x)=j=0∑nxi+jwj
对于这个输出,我们可以分为两部分
f i ( x ) = f i ( x w h i t e ) + f i ( x n o i s e ) f_i(x)=f_i(x^{white})+f_i(x^{noise}) fi(x)=fi(xwhite)+fi(xnoise)
其中 f i ( x w h i t e ) f_i(x^{white}) fi(xwhite)表示对输入 x x x中的无噪声部分进行卷积得到的输出, f i ( x n o i s e ) f_i(x^{noise}) fi(xnoise)表示对输入 x x x中的噪声部分进行卷积得到的输出。
我们可以将 x i x_i xi分解为以下三部分
x ( i ) = x ˉ i + β w k + n i x(i) = \bar{x}_i+\beta w_k + n_i x(i)=xˉi+βwk+ni
其中 x ˉ i \bar{x}_i xˉi与 w k w_k wk、 n i n_i ni(噪声项)相互正交,参数 β \beta β与输入有关,那么 f i ( x ) f_i(x) fi(x)可表示为
f i ( x ) = f i ( x w h i t e ) + f i ( x n o i s e ) = ⟨ x ˉ i + β w k , w k ⟩ + ⟨ n i , w k ⟩ = β + ⟨ n i , w k ⟩ f_i(x) = f_i(x^{white})+f_i(x^{noise}) = \langle \bar x_i + \beta w_k, w_k \rangle + \langle n_i, w_k \rangle=\beta + \langle n_i, w_k \rangle fi(x)=fi(xwhite)+fi(xnoise)=⟨xˉi+βwk,wk⟩+⟨ni,wk⟩=β+⟨ni,wk⟩
我们其实想要的是第一部分的输出 f i ( x w h i t e ) f_i(x^{white}) fi(xwhite),因而噪声项的计算是冗余的,论文中通过具体证明了下式:
f i ( x w h i t e ) = ( a 00 + β k ) ⟨ w k , x i ⟩ + ∑ t ≠ k β t ⟨ w t , x i ⟩ f_i(x^{white})=(a_{00}+\beta_{k})\langle w_k, x_i \rangle + \sum_{t\ne k}\beta_t\langle w_t, x_i \rangle fi(xwhite)=(a00+βk)⟨wk,xi⟩+t=k∑βt⟨wt,xi⟩
我们可以将该式线性化为
f i ( x w h i t e ) = ⟨ w ~ , x i ⟩ w ~ = ( a 00 + β k ) w k + ∑ t ≠ k , β t ≠ 0 β t w t f_i(x^{white})=\langle \widetilde{w}, x_i \rangle \\ \widetilde{w} = (a_{00}+\beta_{k})w_k + \sum_{t\ne k, \beta_t \ne 0}\beta_t w_t fi(xwhite)=⟨w ,xi⟩w =(a00+βk)wk+t=k,βt=0∑βtwt
所以作者的思路就是通过卷积来模拟得到移除噪声项的卷积输出,从而有效避免了对输入中噪声项的卷积运算。
按照这些公式,作者的动态卷积可分为
- 系数预测模块
通过GAP+FC+Sigmoid操作,从固定卷积核生成动态卷积核的系数学习,类似于这个公式的过程
w ~ = ( a 00 + β k ) w k + ∑ t ≠ k , β t ≠ 0 β t w t \widetilde{w} = (a_{00}+\beta_{k})w_k + \sum_{t\ne k, \beta_t \ne 0}\beta_t w_t w =(a00+βk)wk+t=k,βt=0∑βtwt
- 动态生成模块
通过学习到的系数,计算具体的固定卷积核,和Google 的 CondConv,Microsoft 的 Dynamic Convolution 类似的工作,做的都是input-dependent的动态卷积核权重生成。
Keywords
摘要
卷积算子是卷积神经网络(cnn)的核心,是计算量最大的算子。为了提高网络的效率,人们提出了许多设计轻量级网络或压缩模型的方法。虽然已经提出了一些有效的网络结构,如MobileNet或ShuffleNet,但我们发现卷积核之间仍然存在冗余信息。针对这一问题,我们提出了一种新颖的基于图像内容自适应生成卷积核的动态卷积方法。为了证明其有效性,我们将动态卷积应用于多个最先进的cnn。一方面可以在保持性能的同时显著降低计算成本;对于ShuffleNetV2/MobileNetV2/ResNet18 /ResNet50, DyNet可以减少37.0/ 54.2 /67.2/71.3% FLOPs而不损失准确性。另一方面,如果保持计算成本,性能可以大大提高。基于MobileNetV3-Small/Large架构,DyNet在ImageNet上的Top-1精度达到70.3/77.1%,提高2.9/1.9%。为了验证该算法的可扩展性,我们还将DyNet应用于分割任务中,结果表明DyNet在保持 Mean IoU的情况下,可以减少69.3%的次浮点数。
引言
卷积神经网络(cnn)在许多计算机视觉任务中实现了最先进的性能(Krizhevsky等人,2012;Szegedy et al., 2013),并且cnn的神经结构在多年中不断进化(Krizhevsky et al., 2012;Simonyan & Zisserman, 2014;Szegedy等人,2015;他等人,2016;胡等人,2018;钟等,2018a;b)。然而,现代高性能cnn往往需要大量的计算资源来执行大量的卷积核操作。除了准确性之外,为了使cnn适用于移动设备,构建轻量级和高效的深度模型最近吸引了更多的关注(Howard et al., 2017;桑德勒等人,2018;霍华德等人,2019年;张等,2018;马等,2018)。
这些方法大致可以分为两类: 高效网络设计和模型压缩。前一类的代表性方法是MobileNet (Howard et al., 2017;桑德勒等人,2018;Howard等人,2019)和ShuffleNet (Ma等人,2018;Zhang等人,2018),该方法使用深度可分离卷积和通道打乱技术(channel-level shuffle techniques )来降低计算成本。**另一方面,基于模型压缩的方法倾向于通过剪枝、因子分解、模拟和量化来压缩较大的网络,从而获得较小的网络(**Chen et al., 2015;韩等人,2015a;Jaderberg等人,2014;列别捷夫等人,2014;Ba & Caruana, 2014;朱等人,2016)。
虽然已经设计了一些手工制作的高效网络结构,**但我们观察到卷积核之间仍然存在显著的相关性,并引入了大量的冗余计算。**此外,这些小型网络很难压缩。例如,Liu等人(2019)将MobileNetV2压缩到124M,但与MobileNetV2(1.0)相比,ImageNet上的准确率下降了5.4%。这意味着传统的压缩方法不能很好地解决cnn固有的冗余问题。我们对这一现象进行了理论分析,**发现这是由传统卷积的本质造成的,即利用相关核提取与噪声无关的特征。**因此,很难在压缩传统卷积核的同时不丢失信息。我们还发现,如果我们将几个固定的卷积核线性融合生成一个基于输入的动态核,我们可以在不需要多个核协同的情况下获得与噪声无关的特征。

图1:动态卷积的总体框架。
基于上述观察和分析,我们提出了动态卷积来解决这个问题,它根据图像内容自适应地生成卷积核。动态卷积的总体框架如图1所示,由系数预测模块和动态生成模块组成***(coefficient prediction moduleand a dynamic generation module.)。系数预测模块是可训练的,用于预测固定卷积核的系数。然后,动态生成模块根据预测的系数进一步生成动态卷积核。我们提出的方法很容易实现,可以作为任何卷积层的插入 drop-in 插件来减少冗余。我们在最先进的网络上评估提出的动态卷积。一方面可以在保持性能的同时显著降低计算成本;对于ShuffleNetV2(1.0)、MobileNetV2(1.0)、ResNet18和ResNet50, DyNet分别减少37.0%、54.7%、67.2%和71.3% flops,而在ImageNet上Top-1准确率的变化为+1.0%、−0.27%、−0.6%和−0.08%。另一方面,如果保持计算成本,性能可以大大提高。对于MobileNetV3-Small(1.0)和MobileNetV3-Large(1.0)*, DyNet在ImageNet上提高了2.9%和1.9%的Top-1精度,而FLOPs提高了+4.1%和+5.3%。同时,动态卷积进一步提高了MobileNetV2(1.0)、ResNet18和ResNet50的推理速度,分别提高了1.87×、1.32×and 1.48×on CPU平台。
相关工作
本文从高效卷积神经网络设计、模型压缩和动态卷积核三个方面综述了相关工作。
高效卷积神经网络设计
在许多计算机视觉任务中(Krizhevsky等人,2012;Szegedy et al., 2013),模型设计起着关键作用。移动/嵌入式设备对高质量网络的需求日益增长,推动了高效网络设计的研究(He & Sun, 2015)。例如,GoogleNet (Szegedy et al., 2015)相比简单叠加卷积层,增加了网络的深度,降低了复杂性;SqueezeNet (Iandola等人,2016)采用瓶颈方法设计一个非常小的网络;Xception (Chollet, 2017), MobileNet (Howard et al., 2017;Sandler等人,2018)使用深度可分离卷积来减少计算和模型大小。ShuffleNet (Zhang et al., 2018;Ma et al., 2018) 随机打乱通道来减少1×1convolution内核的计算量,提高准确率。Howard等人(2019)是基于互补搜索技术的组合设计的。尽管这些努力取得了一定的进展,但我们发现卷积核之间仍然存在冗余,造成了冗余计算。动态卷积可以减少冗余计算,从而对高效网络进行补充。
模型的压缩
获得小网络的另一个趋势是模型压缩。基于因子分解(Factorization based)的方法(Jaderberg et al., 2014;Lebedev等人,2014)试图通过使用张量分解来近似原始卷积运算来加速卷积运算。基于知识蒸馏(Knowledge distillation)的方法(Ba & Caruana, 2014;罗梅罗等人,2014;Hinton et al., 2015)学习一个小网络来模仿一个更大的教师网络( teacher network)。基于剪枝的方法(Han et al., 2015a;温等人,2016;Liu等人,2019)试图通过剪枝冗余连接或卷积通道来减少计算。与这些方法相比,DyNet更加有效,特别是在目标网络已经足够高效的情况下。例如,在(Liu et al., 2019)中,他们通过剪枝MobileNetV2得到了一个较小的124M次浮点数的模型,然而,与291M次浮点数的模型相比,它在ImageNet上的准确率下降了5.4%。此外,经过修剪的137M FLOPS的MobileNetV2 (Y e等人,2020年)将精度降低3.2%,经过修剪的2120M FLOP的ResNet50 (Wang等人,2019年)将精度降低5.1%。而在DyNet中,我们可以将MobileNetV2(1.0)的FLOPs从298M减少到129M,准确率仅下降0.27%,ResNet50的FLOPs从3980M减少到1119M,准确率仅下降0.08%。
动态卷积核
生成动态卷积核出现在计算机视觉和自然语言处理(NLP)任务中。在计算机视觉领域,Klein et al. (Klein et al., 2015)和Brabandere et al. (Jia et al., 2016)等人基于前一层的特征映射,通过线性层直接生成卷积核。由于卷积核具有大量的参数,线性层在硬件上的效率很低。我们提出的方法仅通过预测线性组合固定核的系数就解决了这一问题,并在硬件上实现了CNN的真正加速。该技术已于2019年初在华为部署,并于2019年5月申请专利。学术界的关注(yang et al., 2019;陈等人,2019;2020年)显示了这一方向的巨大潜力。在本文中,我们从“噪声无关特征”的角度对动态卷积进行了深入的理解,并进行了相关实验来证明在DyNet中卷积核之间的相关性可以大大降低。在自然语言处理领域,一些研究(Shen et al., 2018;吴等人,2019;Gong et al., 2018)结合上下文信息生成具有输入感知能力的卷积滤波器,该滤波器可以根据不同长度的输入句子进行改变。这些方法也通过线性层直接生成卷积核等。由于NLP中CNN的尺寸较小,卷积核的维数为1,缓解了线性层的低效问题。此外,Wu et al. (Wu et al., 2019)利用深度卷积和跨层共享权重的策略缓解了这一问题。这些方法旨在提高语言建模的适应性和灵活性,而我们的方法旨在减少冗余计算成本。
CNN中的动态卷积
在本节中,我们首先描述动态卷积的动机。然后我们详细解释了所提出的动态卷积。最后,我们举例说明我们所提议的DyNet的架构。
动机
如前期作品所示(Han et al., 2015a;b;温等人,2016;Liu等人,2019),卷积核在深度模型中自然相关。对于一些知名的网络,我们在图2中绘制了特征映射之间的皮尔逊积矩相关系数( Pearson product-moment correlation coefficient)的分布。大多数现有的工作都试图通过压缩来减少相关性,然而,对于像MobileNets这样的高效小型网络来说,这很难实现,即使相关性是显著的。我们认为这些相关性对于保持性能是至关重要的,因为它们被合作以获得与噪声无关的特征。我们以人脸识别为例,姿势或光照都不会改变分类结果。因此,当特征图深入时,会逐渐变得与噪声无关。根据附录A中的理论分析,我们发现这个过程需要多个相关核的合作,而如果我们动态融合多个内核,我们可以得到噪声无关的特征而无需这种合作。本文提出了一种动态卷积方法,该方法根据图像内容学习系数,将多个核融合为一个动态核。我们在附录a中对我们的动机进行了更深入的分析。
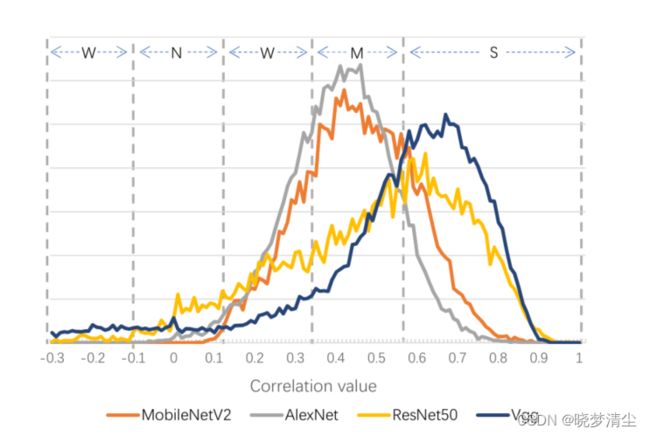
特征图之间的皮尔逊积矩相关系数。S、M、W、N分别表示强、中、弱、不相关。
动态卷积
动态卷积的目的是学习一组核系数,将多个固定核融合为一个动态核。我们在图1中说明了动态卷积的总体框架。我们首先利用一个可训练系数预测模块来预测系数。然后,我们进一步提出了一个动态生成模块,将固定核融合为动态核。接下来我们将详细介绍系数预测模块和动态生成模块。
系数预测模块(Coefficient prediction module)
提出了系数预测模块,基于图像内容对系数进行预测。
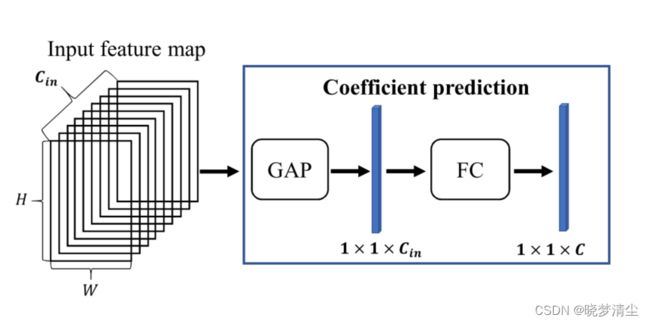
如图3所示,系数预测模块可以由一个全局平均池化层和一个以Sigmoid为激活函数的全连通层组成。全局平均池化层将输入特征映射聚合为1×1×Cin向量,作为特征提取层。然后全连通层将该特征进一步映射为一个1×1×C向量,即多个动态卷积层的固定卷积核的系数。
动态生成模块(Dynamic generation module)
对于权值为 [ C o u t × g t , C i n , k , k ] [C_{out} \times g_t,C_{in}, k, k ] [Cout×gt,Cin,k,k]的动态卷积层,对应 C o u t × g t C_{out} \times g_t Cout×gt固定核和 C o u t C_{out} Cout动态核,每个核的形状为 [ C i n , k , k ] [C_{in}, k, k] [Cin,k,k]。 g t g_t gt表示组大小,它是一个超参数。我们将固定核表示为 w t i w_t^i wti,动态核表示为 w ~ t i \widetilde{w}_t^i w ti,系数 η t i \eta_t^{i} ηti,其中t= 0,…, Cout, i= 0,…, g t g_t gt。系数得到后,我们生成动态核如下:
w ~ t = ∑ i = 1 g t η t i ⋅ w t i \widetilde{w}_t =\sum_{i=1}^{g_t}{\eta_t^i·w_t^i} w t=i=1∑gtηti⋅wti
训练算法
对于提出的动态卷积的训练,不适合使用基于批量的训练方案。这是因为在同一个小批量中,对于不同的输入图像,卷积核是不同的。因此,在训练过程中,我们基于系数而不是基于核来融合特征地图。如式2所示,它们在数学上是等价的:
O ~ t = w ~ t ⊗ x = ∑ i = 1 g t ( η t i ⋅ w t i ) ⊗ x = ∑ i = 1 g t ( η t i ⋅ w t i ⊗ x ) = ∑ i = 1 g t ( η t i ⋅ ( w t i ⊗ x ) ) = ∑ i = 1 g t ( η t i ⋅ O t i ) \widetilde{O}_t=\widetilde{w}_t \otimes x=\sum_{i=1}^{g_t}(\eta_t^i·w_t^i)\otimes x = \sum_{i=1}^{g_t}(\eta_t^i·w_t^i\otimes x)=\sum_{i=1}^{g_t}(\eta_t^i·(w_t^i \otimes x))=\sum_{i=1}^{g_t}(\eta_t^i·O_t^i) O t=w t⊗x=i=1∑gt(ηti⋅wti)⊗x=i=1∑gt(ηti⋅wti⊗x)=i=1∑gt(ηti⋅(wti⊗x))=i=1∑gt(ηti⋅Oti)
这里x表示输入, O ~ t \widetilde{O}_t O t表示动态核 w ~ t \widetilde{w}_t w t的输出, O t i O_t^i Oti表示固定核 w t i w_t^i wti的输出。

动态卷积神经网络
我们用我们提出的动态卷积装备了MobileNetV2、ShuffleNetV2和ResNets,并分别提出了Dy-mobile、Dy-shuffle、Dy-ResNet18和Dy-ResNet50。这4个网络的构建块如图4所示。基于动态卷积,每个动态核可以在不与其他核协同的情况下得到噪声无关的特征。因此,我们可以减少DyNets的通道,并保持性能。我们为它们设置超参数 g t g_t gt为6,并在下面给出这些动态CNN的详细信息。为了验证如果保持通道数量,性能也可以大幅度提高,我们简单地将MobileNetV3-Small(1.0)和MobileNetV3-Large(1.0)的卷积替换为动态卷积,从而得到Dy-MobileNetV3-Small和Dy-MobileNetV3-Large。
Dy-mobile: **在我们提出的Dy-mobile中,我们将原来的MobileNetV2块替换为我们的dymobile块,**如图4 (a)所示。系数预测模块的输入就是块的输入,它生成了所有三个动态卷积层的系数。此外,我们进一步做了两个调整:
-
我们不像MobileNetV2那样在中间层扩展通道。如果我们将块的输出通道表示为 C o u t C_{out} Cout,那么所有三个卷积层的通道都将是 C o u t C_{out} Cout。
-
由于深度卷积是有效的,我们设置groups= C o u t 6 \frac{C_{out}}{6} 6Cout来进行动态深度卷积。如果需要,我们会放大 C o u t C_{out} Cout使它成为6的倍数。
经过上述调整后,第一动态卷积层将FLOPs从 6 C 2 H W 6C^2HW 6C2HW减少到 C 2 H W C^2HW C2HW。第二个动态卷积层保持FLOPS 为 6 C H W × 3 2 6CHW×3^2 6CHW×32不变,因为我们将输出通道减少了6倍,同时将卷积组数也减少了6倍。对于第三个动态卷积层,我们也很好地将浮点数从 6 C 2 H W 6C^2HW 6C2HW减少到 C 2 H W C^2HW C2HW。原始块和我们的dy-mobile块的FLOPs比率为:
6 − 135 C + 27 6−\frac{135}{C+27} 6−C+27135
在原始的ShuffleNet V2中,信道分割操作将feature map分为右分支和左分支,右分支依次进行一次逐点卷积、一次深度卷积和一次逐点卷积。如图4 (b)所示,将右侧分支的传统卷积替换为动态卷积。将右侧分支的输入输入到系数预测模块中,生成系数。在我们的dy-shuffle块中,我们将通道按比例3: 1分为左支路和右支路,从而降低了两个动态点卷积75%的计算成本。与dy-mobile类似,我们在动态深度卷积中调整参数“组”以保持FLOPs不变。
Dy-ResNet18/50:在Dy-ResNet18和DyResNet50中,我们简单地为每个剩余块的动态卷积层减少一半的输出通道。由于每个块的输入通道比dy-mobile和dy-shuffle大,我们使用如图4 ©和图4 (d)所示的两个线性层来减少参数的数量。如果输入通道为 C i n C_{in} Cin,则第一线性层的输出通道为 C i n 4 \frac{C_{in}}{4} 4Cin。
评估
对所提出的动态神经网络进行训练。每个图像都有随机裁剪和翻转的数据增强,并采用余弦学习率衰减的SGD策略进行优化。我们将批大小设为2048,初始学习速率设为0.8,重量衰减设为5e-5,动量设为0.9。我们还使用了以0.1的rate平滑标签。我们对中心点裁剪测试图像的准确性进行了评估。
实验设置及比较方法
我们在ImageNet (Russakovsky et al., 2015)上评估DyNet,其中包含128万张训练图像和50万张验证图像,这些图像来自1000个不同类别。我们在训练集中训练提出的网络,并报告验证集中的 top-1错误率。为了证明有效性,我们将提出的动态卷积与移动设置下的最先进网络进行了比较,包括MobileNetV1 (Howard等人,2017)、MobileNetV2 (Sandler等人,2018)、ShuffleNet (Zhang等人,2018)、ShuffleNet V2 (Ma等人,2018)、Xception (Chollet, 2017)、DenseNet (Huang等人,2017)、IGCV2 (Xie et al., 2018)和IGCV3 (Sun et al., 2018)。
实验结果与分析
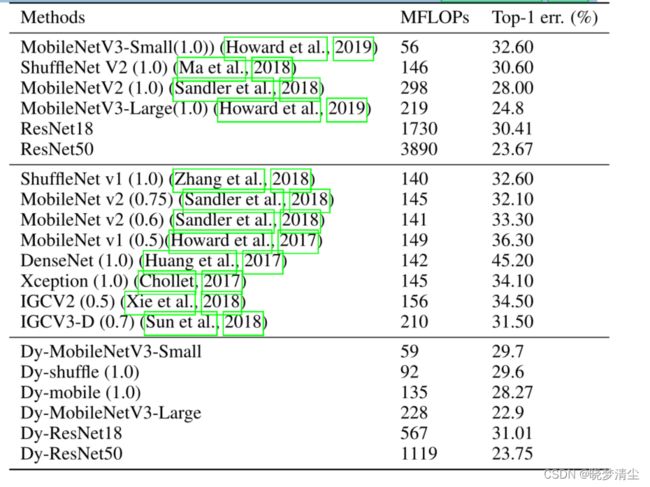
我们在表1中展示了结果,其中括号中的数字表示通道编号控制器( the channel number controller )(Sandler et al., 2018)。我们将结果表划分为三部分: (1) 实现的动态网络对应的原始网络; (2) 比较移动环境下最先进的网络;(3)提出的动态网络。表1提供了一些有价值的观察结果:(1)与移动环境下的这些知名模型相比,本文提出的Dy-mobile、Dy-shuffle和Dy-MobileNetV3在计算成本最低的分类误差最好。这说明动态卷积是一种简单而有效的降低计算成本的方法。(2)与相应的基本神经结构相比,提出的Dy-shuffle(1.0)、Dy-mobile(1.0)、Dy-ResNet18和Dy-ResNet50分别降低了37.0%、54.7%、67.2%和71.3%的计算成本,但Top-1的精度几乎没有下降。这表明,虽然提出的网络显著降低了卷积计算成本,但生成的动态核仍然可以从图像内容中获取足够的信息。(3)与MobileNetV3-Small(1.0)和MobileNetV3-Large(1.0)相比,dd -MobileNetV3-Small和dd -MobileNetV3-Large分别提高了2.9%和1.9%的ImageNet Top-1精度,其FLOPs仅提高3M和9M。计算结果还表明,在保持计算成本的前提下,系统的性能有很大的提高。
表1:不同网络架构在分类误差和计算成本方面的比较。括号中的数字表示通道编号控制器(Sandler et al., 2018)。
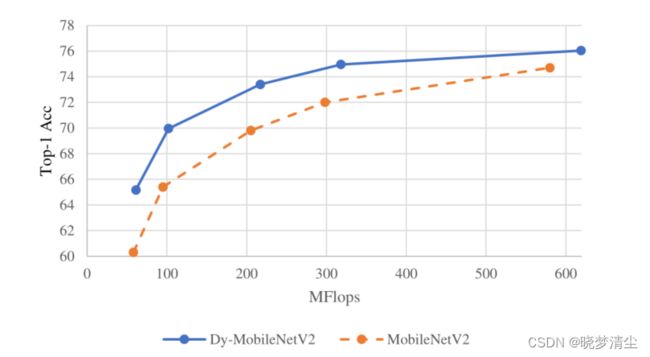
此外,我们在MobileNetV2上进行了详细的实验。我们将传统卷积替换为提出的动态卷积,得到Dy-MobileNetV2。图5显示了不同通道数量模型的分类精度
。结果表明,Dy-MobileNetV2的性能始终优于MobileNetV2,但这种优势随着通道数量的增加而减弱。
动态内核分析 除了定量分析之外,我们还在图6中演示了生成的动态内核与传统内核相比的冗余。在验证集的基础上,我们计算了原始MobileNetV2(1.0)和dy -MobileNetV2(1.0)在第七阶段输出的160个特征映射之间的相关性。请注意,Dy-MobileNetV2(1.0)与Dy-mobile(1.0)是不同的。Dy-MobileNetV2(1.0)保持每一层通道不变,用动态卷积代替传统卷积。由图6可以看出,与传统卷积核相比,动态卷积核的相关分布在−0.1和0.2之间有更多的值,说明动态卷积核之间的冗余比传统卷积核要小得多。
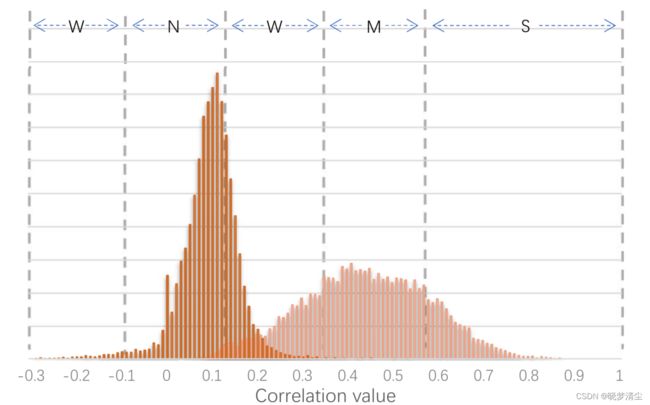
图6:特征图之间的Pearson积矩相关系数,S、M、W、N分别表示强、中、弱和不相关。我们可以观察到,与常规核相比,生成的动态核具有较小的相关值。
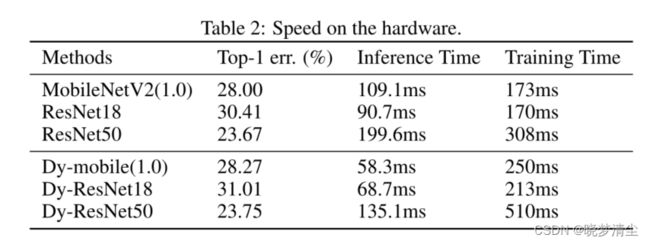
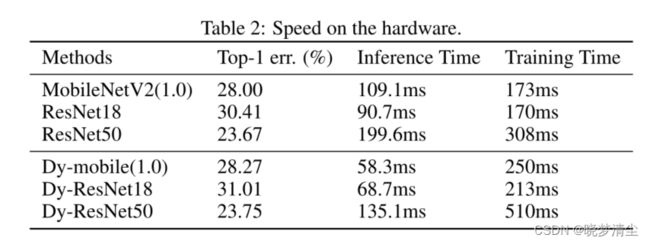
在硬件上进行了速度分析,并对动态网络的推理速度进行了分析。**我们使用Caffe在CPU平台(Intel® Core™ i7-7700 CPU @ 3.60GHz)上进行实验(Jia et al., 2014)。我们设置输入的大小为224,并报告50次迭代的平均推断时间。**我们合理设置小批大小为1,这与大多数推理场景一致。结果如表2所示。
此外,固定核的融合延迟*( the latency of fusing*)与输入大小无关,因此我们期望当网络的输入大小变大时,获得更大的加速比。我们进行实验验证这一假设,结果如图7所示。
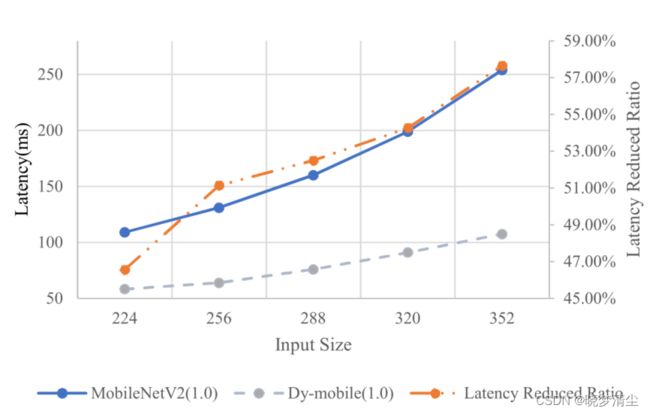
图7:不同输入大小的延迟,如果我们表示MobileNetV2(1.0),Dy-mobile为 L F i x L_{Fix} LFix和 L D y m L_{Dym} LDym,则latency Reduced Ratio定义为
100%− L F i x L D y m \frac{L_{Fix}}{L_{Dym}} LDymLFix。
我们可以观察到,随着输入规模的增大,DyNet所实现的减少延迟的比率也越来越大。如(Tan & Le, 2019)所示,更大的输入规模可以使网络表现得更好,因此DyNet在这种情况下更有效。
并对GPU平台上的训练速度进行了分析。该模型使用32个NVIDIA Tesla V100 gpu进行训练,批量大小为2048个。我们在表2中报告了一次迭代的平均训练时间。可以观察到,DyNet的训练速度较慢,这是合理的,因为我们在训练阶段融合特征图而不是根据Eq. 2融合卷积核。
分割实验 为了验证DyNet在其他任务上的可扩展性,我们进行了分割实验。与以ResNet50作为主干的扩张FCN方法相比(Fu et al., 2018), DyResNet50的扩张FCN在保持城市景观验证集MIoU的同时减少了69.3%的FLOPS。结果如表3所示。

消融研究
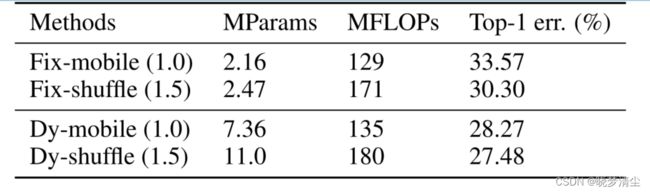
我们相应地为Dy-mobile(1.0)和Dy-shuffle(1.5)设计了两个基线网络,分别记为Fix-mobile(1.0)和Fix-shuffle(1.5)。具体来说,我们去掉了系数预测模块和动态生成模块,直接使用固定的卷积核,保持通道数不变。结果如表4所示,与基线网络Fix-mobile(1.0)和Fix-shuffle(1.5)相比,提出的day -mobile(1.0)和day -shuffle(1.5)的绝对分类改进***(absolute classification improvements)***分别为5.19%和2.82%。这说明直接减少通道数以降低计算成本对分类性能影响很大。而所提出的动态内核能够尽可能地保持其表示能力。
对于动态内核的有效性 Eq. 1中的组大小并不会改变DyNet的计算成本,但会影响网络的性能。因此,我们对 g t g_t gt进行了消融研究。我们为d -mobile(1.0)分别设置 g t g_t gt了2、4、6,结果如表5所示。daymobile(1.0)的性能随着 g t g_t gt的增大而变得更好。这是合理的,因为更大的 g t g_t gt意味着合作的核数获得一个噪声无关的特征变得更大。**当 g t g_t gt= 1时,系数预测模块可以看作仅仅是学习不同信道的注意力,也可以提高网络的性能(Hu et al., 2018)。**因此,我们提供了消融研究,比较 g t g_t gt= 1和 g t g_t gt= 6在Dy-mobile(1.0)和Dy-ResNet18。结果如表6所示。
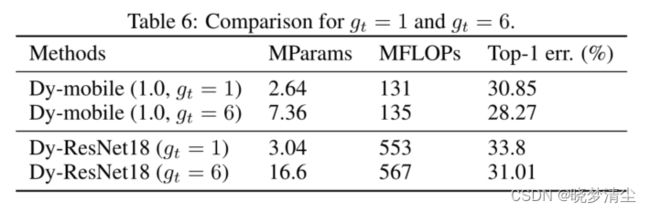
从表中可以看出,让 g t g_t gt= 1将使Dy-mobile(1.0)和Dy-ResNet18在ImageNet上Top-1的精度分别降低2.58%和2.79%。这证明了我们所提出的动态网络的改进不仅仅来自于注意机制。
结论
本文提出了一种新的基于图像内容自适应生成卷积核的动态卷积方法,降低了传统卷积核存在的冗余计算代价。在提出的动态卷积的基础上,我们设计了几种基于已知结构的动态卷积神经网络。实验结果表明,DyNet能在保持性能的同时显著减少FLOPS,或在保持计算成本的同时提高性能。作为未来的工作,我们希望进一步探索卷积核中存在的冗余现象,并寻找其他的方法来降低计算成本,例如对本文使用的不同图像而不是固定组进行动态聚合不同的核。
附录
我们通过输出f(x)的卷积来说明我们的动机,即
f ( x ) = x ⊗ w f(x)=x \otimes w f(x)=x⊗w
这里 ⊗ \otimes ⊗表示卷积操作, 第 i i i个元素的输出卷积 f ( x ) f(x) f(x)为
f i ( x ) = ⟨ x ( i ) , w ⟩ f_i(x) = \langle x_{(i)}, w \rangle fi(x)=⟨x(i),w⟩
这里 ⟨ . , . ⟩ \langle ., . \rangle ⟨.,.⟩表示内积, x ( i ) x_{(i)} x(i)表示x的循环移位i。我们定义索引i从0开始。
附录
我们通过输出f(x)的卷积来说明我们的动机,即
f ( x ) = x ⊗ w f(x)=x \otimes w f(x)=x⊗w
这里 ⊗ \otimes ⊗表示卷积操作, 第 i i i个元素的输出卷积 f ( x ) f(x) f(x)为
f i ( x ) = ⟨ x ( i ) , w ⟩ f_i(x) = \langle x_{(i)}, w \rangle fi(x)=⟨x(i),w⟩
这里 ⟨ . , . ⟩ \langle ., . \rangle ⟨.,.⟩表示内积, x ( i ) x_{(i)} x(i)表示x的循环移位i。我们定义索引i从0开始。